✏️학습 정리
1. Historical Review
-
Deep Learning 핵심 요소
-
Data (모델 학습에 필요한)
- 해결할 문제에 따라 변한다.
-
Model (데이터를 변환할)
-
Loss (모델의 오차를 수량화하는)
- loss function → 근사치
- MSE, MLE, Cross-entropy 등..
-
Algorithm (loss를 최소화시키기 위해 parameter 조정하는)
- optimization algorithm (dropout, early stopping 등....
-
-
Historical Review
- 2012 - AlexNet (CNN, 이미지 분류 모델)
- 2013 - DQN (알파고의 근간, 강화학습)
- 2014 - Encoder / Decoder (번역 모델)
- 2014 - Adam Optimizer (결과가 잘 나온다!)
- 2015 - Generative Adversarial Network (GAN)
- 2015 - Residual Network (네트워크를 깊게 쌓을 수 있게 만들어줌)
- 2017 - Transformer (패러다임을 바꿨다)
- 2018 - BERT (fine-tuned NLP model)
- 2019 - BIG Language Models (OpenAI, GPT-3)
- 2020 - Self Supervised Learning (SimCLR, label을 모르는 data도 활용하자!)
2. Neural Networks & Multi-Layer Perceptron
-
Neural Networks
-
위키: 인간 뇌의 뉴런을 애매하게 영향을 받은 computing system
—> 뇌의 뉴런을 완벽하게 모방해야 하는가? —> 꼭 그럴필요는 없다! (비행기 사례)
-
정의: 비선형 연산과 행렬을 곱하는 연산이 반복되어있는 함수를 근사하는 모델
-
-
Linear Neural Networks (선형 회귀)
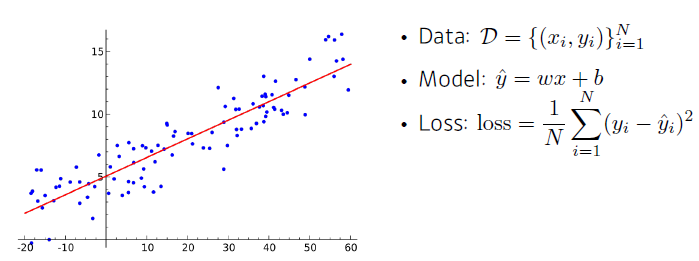
-
backpropagation
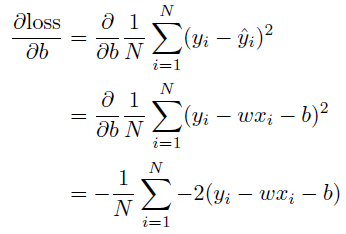
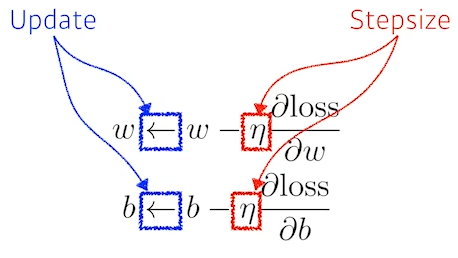
(gradient descent)
-
다 차원의 경우
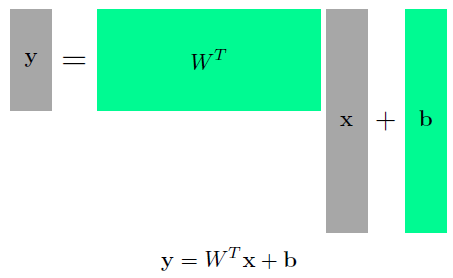
—> 두 vector space간의 변환
-
선형회귀를 쌓는다면?
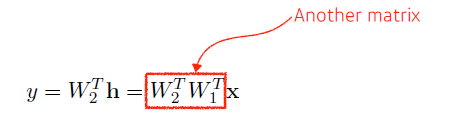
—> 결국 단층 선형회귀와 동일해진다.
-
- Multi-Layer Perceptron
-
activation function (비선형 함수)
- ReLU
- Sigmoid
- Hyperbolic Tangetn (tanh)’
-
예시
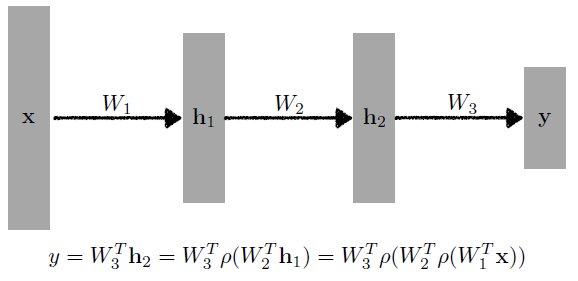
-
loss function
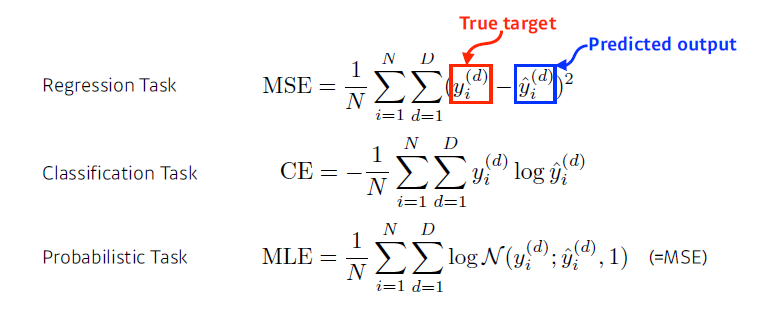
-
3. Optimization
- Generalization
-
모르는 데이터에 대해 모델이 얼마나 잘 작동하는지 (gap을 최소로)

-
-
Cross-validation (k-fold)
- 전체를 k개로 나누어 한개를 validation data로 사용 (test data와는 독립적이다)
-
Bias and Variance
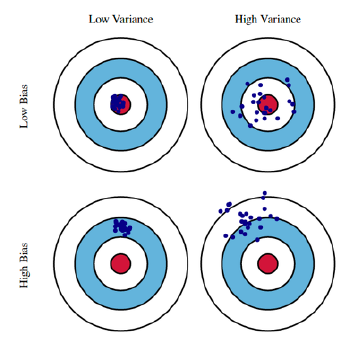
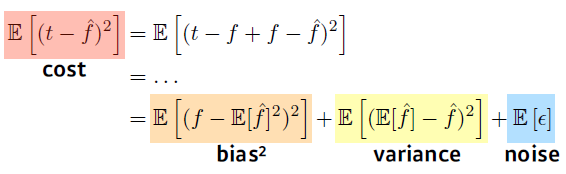
—> bias와 variance는 trade off 관계
-
Bootstrapping
- 여러모델을 생성하는 기법
-
Bagging, Boosting
-
Bagging (Bootstrapping Aggregating)
- bootstrapping으로 만든 여러 모델을 통합하여 사용
-
Boosting
- 모델을 만들고 해당 모델의 약점을 보완한 모델을 생성 (해당 과정 반복)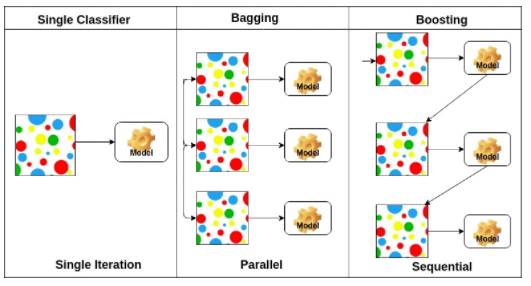
ref. https://www.datacamp.com/community/tutorials/adaboost-classifier-python
-
- Gradient Descent 종류
-
Stochastic gradient descent: single sample을 이용하여 업데이트
-
Mini-batch gradient descent: 데이터의 subset을 이용하여 업데이트
-
Batch gradient descent: 전체 데이터를 이용하여 업데이트
-
Batch-size가 왜 중요할까?
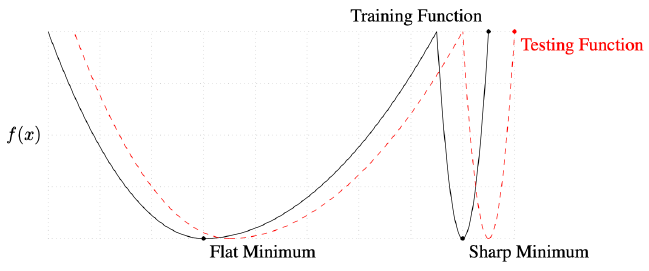
—> batch size가 커질수록 sharp minimum이 되고 test시에 오차가 커진다!
-
- 여러가지 Gradient Descent
- Momentum
-
이전 정보를 활용
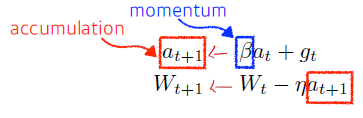
-
- Nesterov Accelerated Gradient
-
이동 후에 이전 정보를 사용
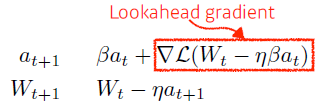
-
- Adagrad
-
많이 변한 parameter는 적게 update, 적게 변한 parameter는 많이 update
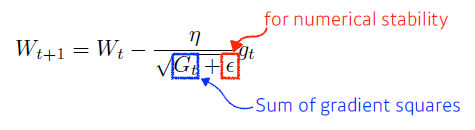
—> 분모가 무한이 되면, update X
-
- Adadelta
-
Adagrad의 분모가 계속 커지는 현상을 방지
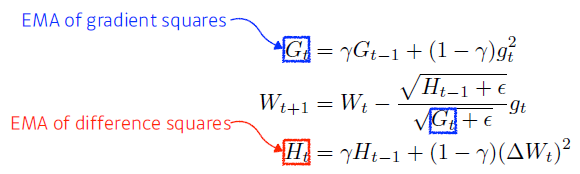
—> learning rate가 없다.
-
- RMSprop
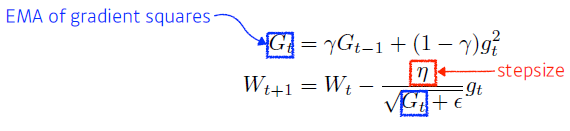
- Adam
-
과거의 gradient와 squared gradient를 합친 방법

-
- Momentum
-
Regularization
-
학습을 방해 → 다양한 데이터에 잘 작동
-
Early Stopping
-
train error와 validation error가 최소인 부분에서 stop
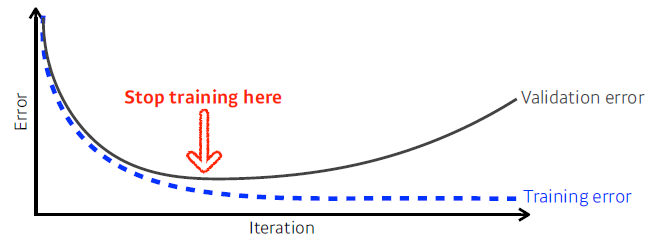
-
-
Parameter Norm Penalty
-
parmeter가 너무 커지지 않게 한다.

-
-
Data Augmentation
- 데이터를 생성 (데이터는 많을수록 좋다!)
- 이미지의 경우 회전을 통해 데이터 생성
-
Noise Robustness
- random noise를 데이터나 weight에 추가
-
Label Smoothing
-
데이터를 섞어준다.

-
-
Drop out
-
random하게 뉴런을 사용
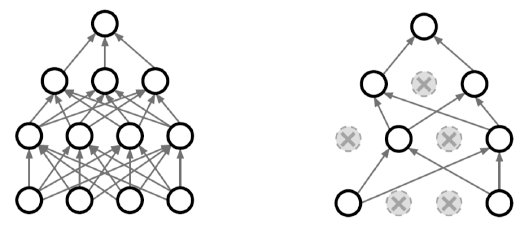
-
-
Batch Normalization
-
parameter 통계학적 정규화
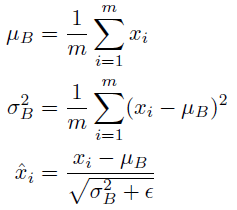
-
-
