✏️학습 정리
1. 서비스 향 AI 모델 개발하기
-
AI 모델 개발 (연구 관점)
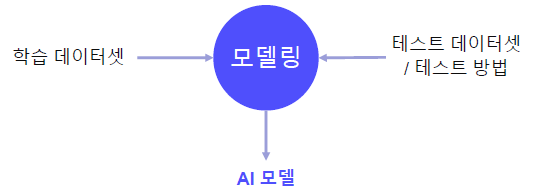
- 정해진 데이터셋, 평가 방식에서 더 좋은 모델을 찾는 일
-
AI 모델 개발 (서비스 관점)
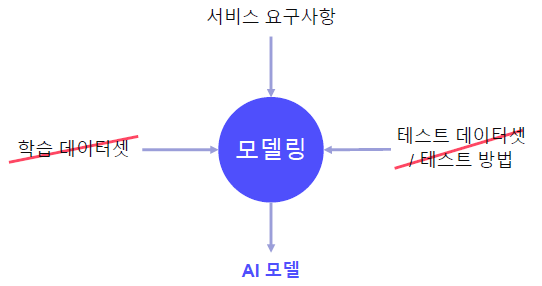
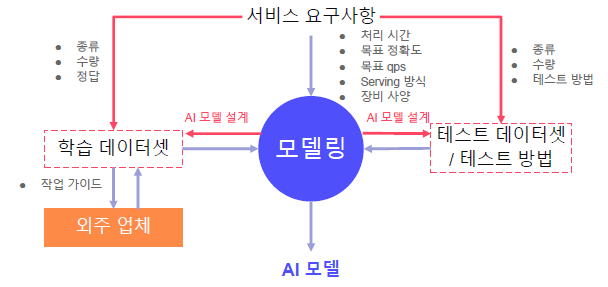
- 서비스 개발 시에는 학습 데이터셋, 테스트 데이터셋, 테스트 방법이 없다.
- 오로지, 서비스 요구 사항만 존재
-
학습 데이터셋
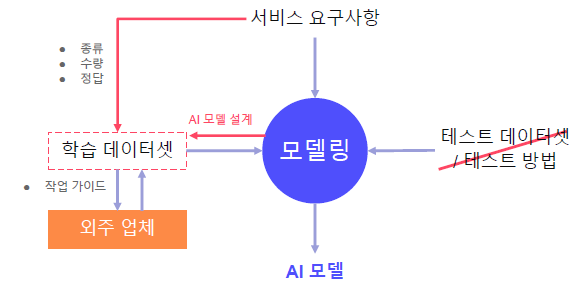
- 서비스 요구사항으로 부터 학습 데이터셋의 종류, 수량, 정답을 정함
- 학습 데이터 준비는 모델 파이프 라인 설계가 필요, 모델 파이프 라인 설계는 어느 정도 데이터 필요 (서로 반복)
- 외주 업체에 가이드를 제공하여 학습 데이터셋을 얻기도 한다.
-
테스트 데이터셋, 테스트 방법
-
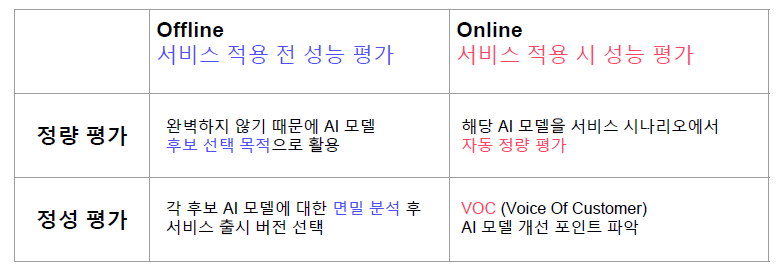
테스트 데이터셋은 학습 데이터셋의 일부를 사용
-
서비스 요구사항으로부터 테스트 방법 도출
-
- AI 모델 팀 구성

-
모델 서빙팀

-
- Tip
-
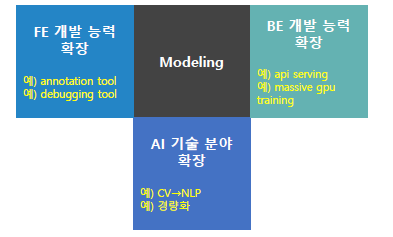
모델링에 대한 전문성도 중요하지만, 점점 자동화되고 관련 인력 수도 늘어나니 주변 역량을 늘려보자!
-
AI 기술 트렌드에 민감하자
-
어떻게 하면 효율적으로 변화에 적응할지 고민
-
2. 내가 만든 AI 모델은 합법?
-
저작권법
- 합법적이지 않은 데이터로 학습한 모델 또한 완전한 합법의 영역에 있다고 보기 어렵다.
- 새롭게 데이터를 제작할 때, 저작권을 고려하지 않으면 합법적으로 사용할 수 없다.
- 학계에서도 점점 저작권 라이센스에 주목
-
합법적으로 데이터 사용하기
- 저작권자와 협의
- 저작재산권 독점적, 비독점적 이용허락
- 저작재산권 전부, 일부에 대한 양도
- 라이센스
- 저작물에 대한 이용허락 규약
- Creative Commons License (CCL)
- BY: 저작자 표시
- ND: 변경 금지
- NC: 비영리
- SA: 동일조건 변경허락
- 저작권자와 협의
3. AI & Ethics
-
AI & 개인
- Bias (편향)
- COMPAS → 인종 issue (bias가 어디서 발생했을까?)
- 데이터에 판사의 편견이 영향을 미칠 수 있다. 사회에 존재하는 편향이 들어갈 수 있다.
- 숨겨진 패턴 때문에 소수가 불이익을 받을 수 있다.
- 알고리즘을 사용하다보면 의도하지 않았지만 bias가 나올 수 있다.
- 다양한 bias 사례
- 기준이 다르고, 편향이 있는 기준이 있다.
- 누가 labeling을 하는지에 따라 bias가 심해질 수 있다.
- data를 어떻게 어디에서 누가 수집했나에 따라 발생할 수 있다.
- 지역, 대학 등과 같은 것들이 feature가 되면 문제가 될 수 있다.
- Privacy (개인정보)
- 싱가폴 확진자 동선 파악 사례
-
AI & 사회
- 사회적 불균형
- 일자리 대체
- 잘못된 정보 제공 (Deep fake)
- 사회적 불균형
-
AI & 인류
- 질병 예측
- 환경 cost 증가 (Bert 모델은 비행기보다 많은 에너지 사용)
- 도시 배치 (이동 경로 예측하여 동선 낭비 최소화)
- 날씨 예측 등...
4. Full Stack ML Engineer
-
Full Stack ML
- ML engineer
- ML 기술을 이해하고, Product를 만드는 engineer
- 딥러닝의 폭발적 발전속도로 인해 research 영역과 engineer 영역의 경계가 모호
- Full Stack
- Front-end + Back-end 를 다루는 개발자
- 코딩 잘하고, 협업을 할 수 있고, 새로운 기술을 배우는 것을 즐기는 개발자 (Apple)
- 상태가 아니라 방향성!
- 내가 만들고 싶은 Product를 시간만 있다면 모두 혼자 만들수 있는 개발자
- Full Stack + ML
-
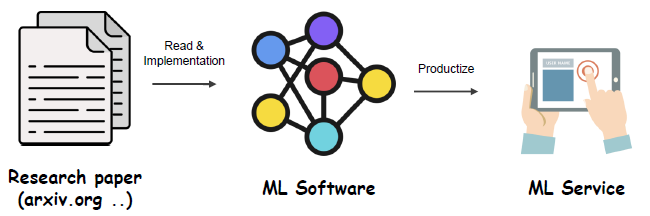
딥러닝 research를 이해하고, ML Product로 만들 수 있는 engineer
-
- 장점
- 재미있다! (가장 큰 이유가 되어야 한다고 생각)
- 빠른 프로토타이핑 가능
- 각 stack의 깊은 이해가 가능하여 팀의 불필요한 로스 줄여줌
- 서로 갈등이 생길법한 부분에서의 기술적인 이해가 매우 도움이 됨
- 모든 내용이 성장의 밑거름이 된다.
- 단점
- 깊이가 없어 질 수 도 있다. (시간을 많이 쓰면 해결 가능)
- 공부할 분야가 많다보니 절대적으로 시간이 많이 들어간다.
- ML engineer
-
ML Product
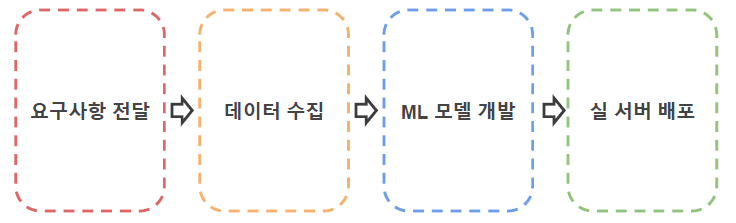
- 요구사항 전달
- B2B or B2C
- 요구사항 + 제약사항 정리
- ML Problem으로 회귀
- 데이터 수집
- Raw 데이터 수집
- Annotation Tool 기획 및 개발
- Annotation Guide 작성 및 운용
- ML 모델 개발
- 기존 연구 research 및 내재화 (baseline 확보)
- 실 데이터 적용 실험 + 평가 및 피드백
- 모델 차원 경량화 작업
- 실 서버 배포
- 엔지니어링 경량화 작업
- 연구용 코드 수정 작업
- 모델 버전 관리 및 배포 자동화
- 요구사항 전달
-
ML Team

- 한 사람이 여러 역할을 맡기도 함
-
Roadmap
- 익숙한 언어 + 가장 적은 기능 + 가장 쉬운 Framework로 시작
- 최대한 빨리 완성 (퀄리티에 신경 X)
- Full Stack 이어도 자신의 전문 분야를 정해야한다.
- 새로운 것에 대한 두려움 없애기 위해 반복적으로 접하자!
5. AI 커리어 빌딩
-
AI 회사 종류
- AI for X
- AI로 기존 비지니스를 더 잘하려는 회사
- 비용 줄이기, 품질 상승 등에 AI 활용
- AI가 보조회사
- AI centric
- AI로 새로운 비지니스를 창출하려는 회사
- 새로운 가치창출을 하는데 AI를 활용
- AI for X
-
Engineering
-
다양한 역할이 존재
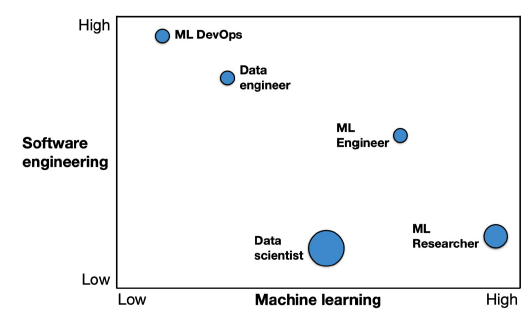
-
100% 하나의 포지션의 역할을 수행하는 경우는 드물다.
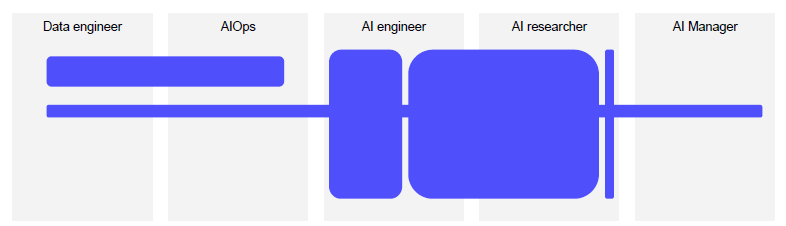
-
현실에서는 각 포지션이 세분화 되어 있지만, 사이사이를 메꾸는 일이 많다.
-
-
Career
- 나를 이해하자!
- 나는 fundamental 한 학문에 관심이 있는가?
- 나는 비지니스에 관심이 있는가?
- 내가 만든 모델이 실생활을 변화시키길 바라는가?
- 경험을 많이 하자!
- AI 관련 인턴십, 아르바이트 권장
- AI competition (캐글)
- 최신 논문 재현 (논문 구현 워크샵)
- 석사/박사 학위가 꼭 필요한 것은 아니다! (내가 많이 성장할 수 있는 환경 선택)
- 역량
- CS 지식, 소프트웨어 엔지니어링 능력
- 영어 독해 능력
- Grit (끈기 있는 자세)
- Humility, Passion, Teamwork ...
- 모든 것을 잘하려고 하기보다는 팀에 기여할 수 있는 나만의 엣지를 키워보자!
- 나를 이해하자!

함께 자라기