Fork & Join FrameWork
해당 프레임워크를 통해 작업을 작은 단위로 나누어 여러 스레드가 동시에 처리하는 것을 쉽게 할 수 있다.
수행 작업에 따라 두 클래스 중 하나를 상속받아야 한다.
RecursiveAction : 반환값이 없는 작업 구현시 사용
RecursiveTask : 반환값이 있는 작업을 구현할 때 사용
두 클래스 모두 compute()라는 추상 메서드를 가지고 있으며, 상속을 통해 이 추상 메서드를 구현하기만 하면 된다.
1.compute()에 수행할 코드 구현
2.스레드풀과 수행할 작업 생성
3.invoke()로 작업 시작
ForkJoinPool은 프레임워크에서 제공하는 스레드 풀로, 지정된 수의 스레드를 생성해서 미리 만들어 놓고 반복해서 재사용할 수 있게 해준다.
-스레드를 반복해서 생성하지 않아도 되며, 너무 많은 스레드가 생성되어 성능이 저하되는 것을 막아준다
-스레드가 수행해야하는 작업이 담긴 큐를 제공하며, 각 스레드는 자신의 작업 큐에 담긴 작업을 순서대로 처리한다.
compute()
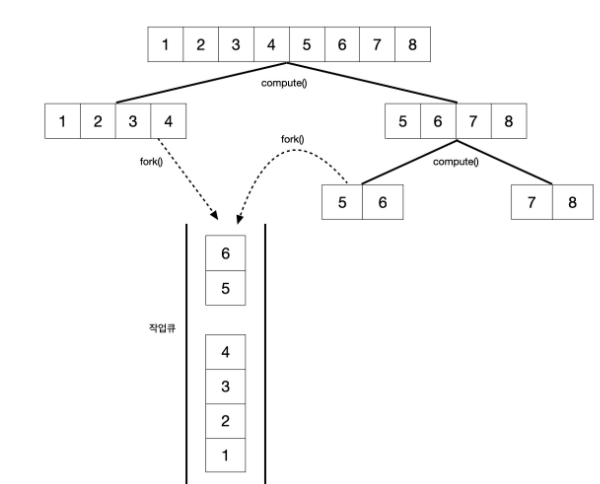
1에서 8까지의 숫자를 더하는 과정이다. Compute 구현시 수행할 작업 외에도 작업을 어떻게 나눌 것인지를 알려주어야 한다.
다른 스레드의 작업 수행 및 병합
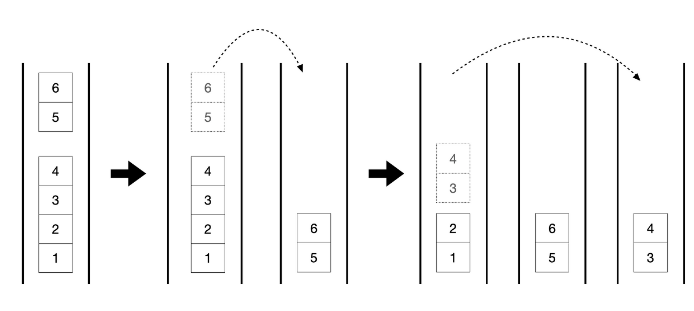
fork()가 호출되어 작업 큐에 추가된 작업은 compute()에 의해 더 이상 나눌 수 없을때까지 반복해서 나뉘고, 자신의 작업 큐가 비어있는 스레드는 다른 스레드의 작업 큐에서 작업을 가져와 수행한다. 해당 작업들은 스레드풀에 의해 자동적으로 이루어진다.
fork()와 join()
fork() : 해당 작업을 스레드 풀의 작업큐에 넣는 비동기 메소드
join() : 해당 작업의 수행이 끝날 때까지 기다렸다가, 결과를 반환하는 동기 메소드
