
텍스트 데이터 시각화
1️⃣ 워드 클라우드
워드 클라우드(Word Cloud)
텍스트 데이터 분석에서 가장 단순하고 기본적인것으로 여러 개의 문서에서 가장 많이 사용된 단어를
파악하는 것 (시각화)
ex ) 대롱령의 연설문에서 사용된 단어들의 빈도 분석
—> 사용 라이브러리 :wordcloud, matplotlib, seaborn등

- 장점 : 글자의 크기와 색상으로 데이터를 시각화하여 데이터를 한눈에 알아보기 쉽게 전달
프레젠테이션이나 보고서에서 효과적인 시각적 요소로 자주 활용됨 주요 관심사를 빠르게 파악 가능 - 단점 : 단어의 빈도만 보여주기 때문에 해당 단어가 긍정적인 의미 인지 부정적인 의미인지 파악 불가
from wordcloud import WordCloud
from konlpy.tag import Okt
from collections import Counter # 텍스트 집계
text = open('test.txt').read()
okt = Okt()
# Okt를 통한 형태소 분석
setences_tag = okt.pos(text) # norm , stem
noun_adj_list = []
# 명사 혹은 형용사 단어들만 추출
for word, tag in setences_tag:
if tag in ['Noun', 'Adjective']:
noun_adj_list.append(word)
# 가장 많이 나온 단어부터 40개를 저장한다.
counts = Counter(noun_adj_list)
tags = counts.most_common(40)
# WordCloud 생성
wc = WordCloud(font_path=['otf 파일 위치'], # 폰트
background_color ='white', # 배경색
max_words = 30, # 최대 출력 단어수
contor_width = 3, #테두리 굵기
contor_color = 'steeblue') # 테두리색
wc.generate_from_frequencies(dict(tages)) # 워드클라우드 생성
wc.to_file('wordcloud_result.png') # 결과를 이미지로 저장 2️⃣ 텍스트 그룹핑 (Text Grouping)
텍스트간 유사한 내용끼리 묶어서 그룹으로 분류하는 방법
그룹별 언급 빈도 파악 가능, 가로 막대형 차트와 같은 그래프를 활용하여 직관적으로 시각화할 수 있음
- 장점 :
단답형 데이터를 분석할 대 유용 ex) ‘TV 브랜드 라고 하면 떠오르는 브랜드는 무엇인가요?’ 에 대한 브랜드명을 단답형으로 수집할 때 자주 활용 - 단점 : 텍스트 그룹핑은 짧은 텍스트 분석에 특화되어 있기 때문에 긴 서술형 답변에서 활용하기 매우 어려움 워드 클라우드와 유사하게
빈도 기반으로 분석하기 때문에 응답에 대한 세부적인 의미, 맥락을 파악하기 어렵다.
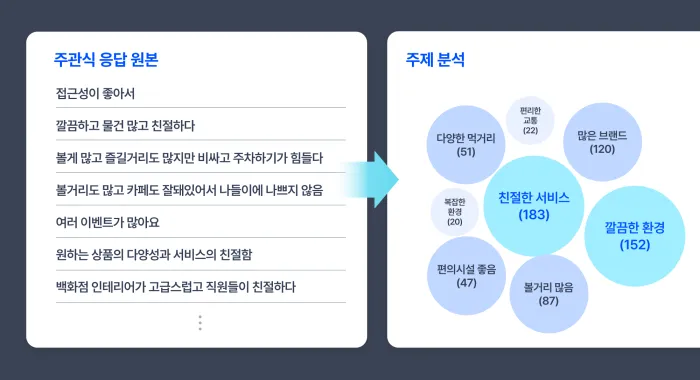
3️⃣ 주제 분석(Thematic Analysis)
주제 분석은 단어나 문장의 패턴을 분석해 공통적인 주제를 도출하는 데이터 시각화 방법
긴 문장으로 이루어진 텍스트 데이터를 분석할 떄 효과적
도출된 주제들은 시각적으로 직관적인버플차트로 표현되며, 자주 언급된 주제일수록 더 큰 버블로 표시되어중요도를 시각적으로 강조

- 장점 : 개별 단어가 어떤 맥락에서 언급되었는지 알 수 있어 텍스트 데이터의 의미를 깊게 이해하는데 도움이 된다. ex) 제품 선택 이유, 서비스 불편 사항
- 단점 : 비슷한 표현도 문맥에 따라 다른 의미를 가지기 때문에 정확하게 파악하기는 어려움 하나의 주제가 아닌 여러 주제가 혼재되어 있거나 주제 간의 관계가 복잡한 경우에는 정확하게 분류가 안됨
4️⃣ 감정 분석(Sentiment Analysis)
감정분석은 텍스트 속에 담긴 의미를
긍정,부정,중립으로 분류하고 이를 게이지 차트로 시각화 하는 방법 각 감정의 비율과 빈도를 한눈에 파악할 수있음
- 장점 : 감정 분석은 응답자의 의견을 긍정과 부정으로 분류하고, 이를 상세 분석하여 개선점을 도출하는 데 유용함 ex) ‘고객에게 브랜드나 제품에 대한 피드백을 요청 —> 응답’ 을 감정 분석을 통해 만족점 및 개선점 파악에 용이
- 단점 : 주제 분석과 마찬가지로 분석 과정에서 감정의 미묘한 차이나 뉘앙스가 왜곡 될 수 있다. 긍정, 부정, 중립으로 나누기 어려운 복잡한 감정이나 중첩된 의견은 정확하게 분류 되지 않을 수 있다.
ex) “엄복동과 같은 최고의 영화”입니다.
import pandas as pd
from google.colab import drive
drive.mount('/content/drive')
review_df = pd.read_csv("/content/drive/My Drive/Colab Notebooks/labeledTrainData.tsv", sep='\t', quoting=3)
review_df.head(3)
카운트 기반의 문서 표현
텍스트 데이터를 수치화하여 컴퓨터가 이해할 수 있는 형태로 만드는 방법
주로 문서 내 단어의 빈도를 활용하여 각 문서를벡터형태로 나타낸다
ex)Bag of Words(BOW), Document Term Matrix(DTM) 등이 있다.
1️⃣ Bag of Words (BOW)
단어들의 순서를 고려하지 않고, 단어들의
출현 빈도(frequnecy)에 만 집중하는 텍스트 데이터의
수치화 표현 방법 텍스트 문서에 있는단어(토큰)들을 가방에 전부 넣음 —> 단어를 섞는다.
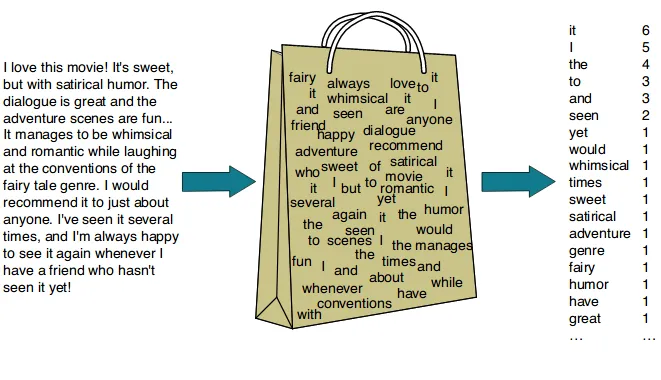
☑️ BOW 만드는 과정
⭐(1) 각 단어의 고유한 정수 인덱스를 부여 # 단어 집합 생성
(2) 각 인덱스의 위치에 단어 토큰의 등장 횟수를 기록한 벡터를 생성
from konlpy.tag import Okt
okt = Okt()
def build_bag_of_words(doc):
doc = doc.replace('.', '')
tokenized_doc = okt.morphs(doc) # 텍스트를 형태소 단위로 나눈다 options : stem, norm
word_to_index = {} # 각 단어의 고유한 정수 인덱스를 부여
bow = []
for word in tokenized_doc:
if word not in word_to_index.keys():
word_to_index[word] = len(word_to_index) # 번호 부여
# Bow에 전부 기본값 1을 넣는다.
bow.insert(len(word_to_index) -1, 1)
else:
index = word_to_index.get(word)
bow[index] = bow[index] +1
return word_to_index, bow doc1 = "정부가 발표하는 물가상승률과 소비자가 느끼는 물가상승률은 다르다."
vocab, bow = build_bag_of_words(doc1)
print('vocabulary :', vocab)
print('bag of words vector :', bow)
Output :
vocabulary : {'정부': 0, '가': 1, '발표': 2, '하는': 3, '물가상승률': 4, '과': 5, '소비자': 6, '느끼는': 7, '은': 8, '다르다': 9}
bag of words vector : [1, 2, 1, 1, 2, 1, 1, 1, 1, 1]💡 사이킷런에 CountVectorizer으로 Bow 만들 수 있음
from sklearn.feature_extraction.text import CountVectorizer
corpus = ['you know I want your love. because I love you.']
vector = CountVectorizer()
# 코퍼스로부터 각 단어의 빈도수를 기록
print('bag of words vector :', vector.fit_transform(corpus).toarray())
# 각 단어의 인덱스가 어떻게 부여되었는지를 출력
print('vocabulary :',vector.vocabulary_)
Output :
bag of words vector : [[1 1 2 1 2 1]]
vocabulary : {'you': 4, 'know': 1, 'want': 3, 'your': 5, 'love': 2, 'because': 0}2️⃣ Document-Term Matrix (DTM)
서로 다른 문서들의 BOW들을 결합한 표현 방법인 문서 단어 행렬(DTM)
다수의 문서에서 등장하는 각 단어들의 빈도를행렬로 표현한 것
ex )
문서 1 : 먹고 싶은 사과
문서 2: 먹고 싶은 바나나
문서 3: 길고 노란 바나나
문서 4: 저는 과일이 좋아요
| 과일이 | 길고 | 노란 | 먹고 | 바나나 | 사과 | 싶은 | 저는 | 좋아요 | |
|---|---|---|---|---|---|---|---|---|---|
| 문서1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 |
| 문서2 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 |
| 문서3 | 0 | 1 | 1 | 0 | 2 | 0 | 0 | 0 | 0 |
| 문서4 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
머신러닝 기반 텍스트 분류
1️⃣ 베이즈의 정리(Bayes’ theorem)
나이브 베이즈 분류기는 베이즈의 정리를 기반으로 만든 알고리즘 조건부 확률 계산은 아래와 같다.

-
예시 : 스팸 메일 필터
P(정상 메일 | 입력 텍스트) = 입력 텍스트가 있을 때 정상 메일일 확률P(스팸 메일 | 입력 텍스트) = 입력 텍스트가 있을 때 스팸 메일일 확률 -
베이즈 정리 적용
P(정상 메일 | 입력 텍스트) = (P(입력 텍스트 | 정상 메일) × P(정상 메일)) / P(입력 텍스트)P(스팸 메일 | 입력 텍스트) = (P(입력 텍스트 | 스팸 메일) × P(스팸 메일)) / P(입력 텍스트)

P(A) : 감염증 A에 걸릴 확률 0.01
P(~A) : 감영증 A에 걸리지 않을 확률 0.99
P(M) : 마스크 착용자 비율 0.9
P(~M) : 마스크 미 착용자 비율 0.1
P(~M|A) : 감염증 A에 걸린 환자 중 마스크 미 착용자 사람의 비율 : 0.4
P(M|A) : 감염증 A에 걸린 환자 중 마스크 착용자 사람의 비율 : 0.6
P(A | M) : 마스크 착용한 사람중 감염증 A에 걸린 환자 비율 ~= 0.0067
P(A | ~M) : 마스크 미 착용한 사람중 감염증 A에 걸린 사람의 비율 ~= 0.04
※ 마스크 쓸 때보다 마스크를 쓰지 않을 대 감염증 A에 걸릴 확률이 6배 높다.
☑️ 나이브 베이즈 분류
⭐데이터 특징을 가지고 각 클래스(레이블)에 속할 확률을 계산하는 조건부 확률 기반 분류 방법
데이터의 특징이 모두 상호 독립적이라는 가정 하에 확률 계산을 단순화 한다 —> 나이브 하다
데이터의 특징을 통해 클래스 전체의 확률 분포 대비 특정 클래스에 속할 확률
※ 데이터 특징이 하나 이상일 떄 나이브 베이즈 공식으로 해당 데이터가 어떤 레이블에 속할 확률이
가장 높은지 알 수 있음

⚡ 특징
- 빠르고 간단하며 성능이 준수
- 텍스트 분류(스팸 필터링, 감성 분석 등)에서 효과적
- 주요 모델 :
- Multionmial Navie Bayes : 단어의 등장 횟수를 기반(텍스트 데이터에서 주로 사용)
- Bernoulli Navie Bayes : 단어의 존재 유무 기반
- Gaussian Navie Bayes : 연속적인 실수형 변수에 사용
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB # 나이브 베이즈 분류
from sklearn.pipeline import make_pipeline
# 간단한 텍스트 데이터와 라벨 (1: 긍정, 0: 부정)
texts = [
"이 영화 정말 재미있어요", # 긍정
"최고의 영화였어요", # 긍정
"시간 낭비였어요", # 부정
"지루하고 별로였어요", # 부정
"다시 보고 싶어요", # 긍정
"형편없는 연기였어요" # 부정
]
labels = [1, 1, 0, 0, 1, 0] # 정답 라벨
# 파이프라인 생성: CountVectorizer + MultinomialNB
model = make_pipeline(CountVectorizer(), MultinomialNB())
# 학습
model.fit(texts, labels)
# 테스트
test_sentences = [
"정말 재미없었어요",
"최고였어요 또 보고 싶어요",
"연기도 좋았고 감동적이었어요",
"시간 낭비입니다"
]
# 예측
predicted = model.predict(test_sentences)
for sent, label in zip(test_sentences, predicted):
print(f"문장: {sent} → 예측 감성: {'긍정' if label == 1 else '부정'}")
Output :
문장: 정말 재미없었어요 → 예측 감성: 부정
문장: 최고였어요 또 보고 싶어요 → 예측 감성: 긍정
문장: 연기도 좋았고 감동적이었어요 → 예측 감성: 긍정
문장: 시간 낭비입니다 → 예측 감성: 부정
