Diary
오늘은 서류처리할 일이 많지 않아서 그렇게 공부를 많이하지는 못했지만 기본적으로, 트레이닝 데이터와 테스트 데이터에 대한 분산에 대해서 많이 생각해볼 수 있었다.
결국 우리의 목적은 궁극적으로 사용하려는 데이터의 성향을 반영한 모델을 만드는 것이기 때문에 항상 현재의 학습 데이터와 실제 데이터의 차이(분산적으로나, 데이터 수집적으로나)를 고민할 필요가 있을 것 같다.
Learn
- Machine Learning Yearning Book
- fastai와 파이토치가 만나 꽃피운 딥러닝 100페이지
- StableDiffusion과 ChatGPT의 기술에 대한 이해와 비즈니스 인사이트 - 정지훈(모두의연구소 CVO) I 모두의연구소 모두팝
Detail
- Machine Learning Yearning Book 보면서 도움될만한 팁들 정리(~15과까지)
앤드류응 교수님이 머신러닝 개발과 관련해서 관련 팁들을 정리해놓은 걸로 무료로 Pdf로 볼 수 있다.
- 전통적인 머신러닝 방법론은 데이터수가 늘어난다고 해도 performance가 이후에는 평탄해지지만, 신경망이 등장하면서는 더 깊은 모델일수록 데이양에 따라서 더 잘 동작하는 것이 보인다.
- 학습 당시에 배우는 데이터의 분포와 실제 적용 당시의 데이터의 분포가 달라지지 않는지 항상 유의해야한다. 우리가 만들 모델은 학습 데이터에 Fitting된 모델이 아닌 궁극적으로 사용하는 데이터의 성향을 반영한 데이터
- 이전의 머신러닝 단계에서는 100 ~ 10000개 정도의 데이터를 가지고 분석을 해왔고 그 기준으로 30% 정도를 테스트 데이터 비율로 가져왔지만, 수백만개의 데이터들을 활용하는 문제를 접하는 경우 절대적인 테스트 데이터 수는 많아도 실제로 비율은 줄어들게 된다.
- 좋은 모델을 선택하기 위해 평가지표를 사용하는데 결국 의사결정을 쉽게 하기 위해서는 단수화(하나의 지표)하는 것이 필요하다.(참고 지표는 많더라도, 의사결정을 위한 지표)
- 개발 데이터를 가지고 있다는 것은 빠르게 모델을 이터레이션하면서 실험하기에 필수적이다.
- 개발 데이터에서 나온 결과가 테스트 데이터보다 더 좋게 나온다면 개발데이터에 overfitting된것으로 볼 수 있어서 개발 데이터를 바꿔보는 것도 도움이 될 수 있다.
- 모델을 개선해나가는 과정에서 오류평가를 하는데 오류평가에서 어떤 것을 고치냐를 기준으로, 임팩트를 측정해볼 수 있다.(Ex. 고양이 감별 모델에서, 개를 잘못 판별하거나, blur 이미지를 해결 못하는 에러의 비중 보기) 오분류된 케이스를 100개 정도 뽑아보고 스프레드 시트 형태로 비중을 정리해보는게 더 우선순위를 평가한다고 한다.
- fastai와 파이토치가 만나 꽃피운 딥러닝 공부하다 메모
- CNN 관련 모델 소개인데, 소리/마우스,클릭을 시각화한 것/악성프로그램 등과 같이 비시각정보를 시각화해서 CNN으로 접근한게 인상깊었음.
- fastai에서 데이터 가져올 때, 라벨을 주로 파일명에서 뽑아내다보니, 아래와 같은 코드를 사용하게 됨.
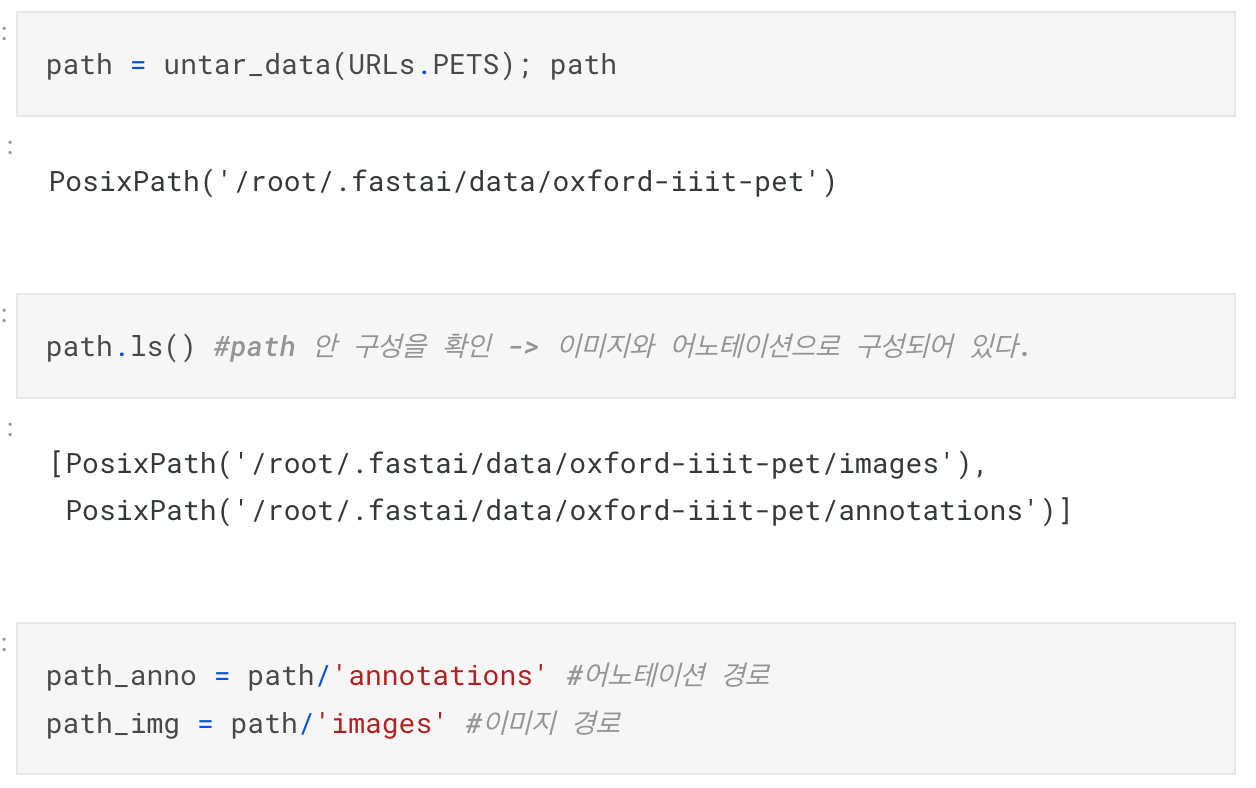
- 여기에서도 동일하게, 빠르게 반복하면서 모델을 개선해나가야한다는 것을 강조하고 있다.
- StableDiffusion과 ChatGPT의 기술에 대한 이해와 비즈니스 인사이트
- chatgpt로 발전되기까지 어떤 기술들이 핵심이 되었는지 살펴보고 정리하는데 도움되었던 유튜브.
- 비지도 학습은 기계학습에서 가장 발전되지 못한 학습 모델이다. 물론 비지도 학습은, ‘정답이 달리지 않은 자료’를 수없이 제시한 뒤 컴퓨터가 알아서 그 자료들의 특성이나 관계를 파악하도록 하는 방식으로 지금도 시행 중이다. 그러나 데이터만 많이 확보할 수 있다면, 지도학습으로 컴퓨터를 훈련시키는 방법이 비지도 학습보다 훨씬 뛰어나다고 한다. 르쿤에 따르면, 인공지능이 현재 수준을 훌쩍 뛰어넘는 방법은 미개척지인 비지도 학습을 개발하는 것 외에 없다. 그는 저명한 인공지능 학회인 ‘NIPS(신경정보처리시스템 학회) 2016’에서 이렇게 말한 바 있다. “만약 지능이 케이크라면 비지도 학습은 케이크의 본체다. 지도학습은 케이크 본체의 겉에 발린 크림(icing)이고, 강화학습은 케이크 위의 체리다. 우리는 크림과 체리를 어떻게 만드는지 안다. 그러나 케이크를 만드는 법은 모른다.”

- 이 비지도학습을 라벨링하지 않고 이용할 수 있게 해준게 self-supervised learning이다. 빈칸을 뚫어놓거나하면서 막대한 라벨링된 데이터를 만들어서 학습을 시켜준게 거대 모델을 만들 수 있게 된 배경.
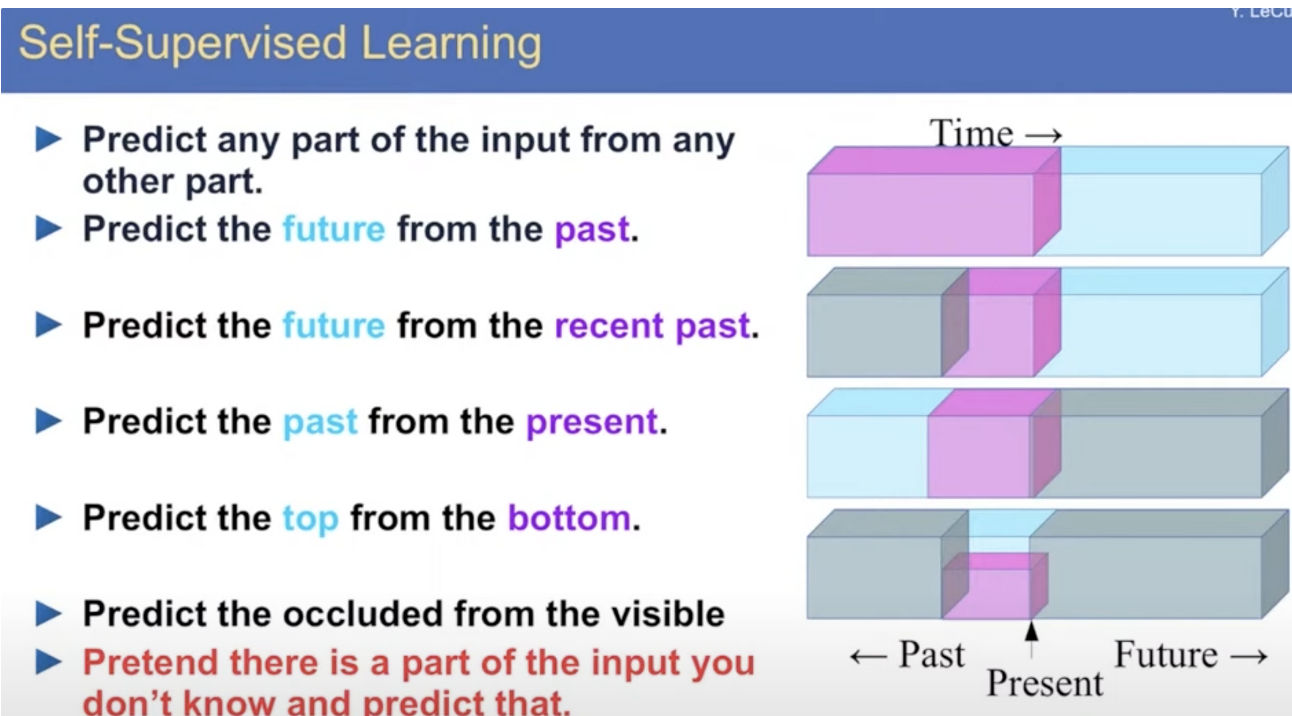
- 이렇게 큰 모델로 pre-trained 모델을 만들어서 다른 업무들을 조금씩 시켜보는 방식으로 모델 개발방식이 바뀌어짐.
Link

Lean, Learn, Lesson