*이 글은 어떤 지식을 공유하기 위함이라기 보다는 내가 공부한 것을 내가 더 잘 기억하기 위해 정리/메모 정도의 용도로 쓴 글입니다.
Summary
오늘은 트랜스포머 모델, 딥러닝 모델 전체 개괄에 대한 개념을 정리하는 시간을 가졌다.
참고 자료
- 찐코딩님의 NLP 강의 4,5강
- 서울대 데이터 사이언스 대학원에서 공개한 인터넷 강의 정리
- 서울대 데이터 사이언스 대학원 연구실 소개 영상
Learn
- RNN
- Transformer
- Viplab 소개 영상
- Contents-based Movie & Music Recommendation 분야에서 인간처럼 컨텐츠 내용을 이해하고 이 기반으로 정보를 추천해주는 작업이 필요하다는 생각이 들었다.
- 추천시스템을 전세계 사람들을 위해 추천해주는 것보다 로컬적 특성을 가진 집단별로 묶어서 추천하는게 더 효과가 있다.(실제 틱톡에서도 추천엔진은 그대로 있고, input을 컨텐츠 풀을 나라별로 다르게 제공하고 있음)
- Dream yourself to be a speaker at the most prestigious ML conferences
Details
1) Transformer 논문에서 Positional Embedding의 역할
- 트랜스포머는 자연어 처리를 위한 솔루션이고, RNN이 가지고 있는 시퀀스가 길어지는 것에 대해 Attention으로 해결함과 동시에 병렬 처리로 속도까지 늘린 솔루션이다.
- 하지만, 이 방식은 동시에 모든 것을 한꺼번에 학습시키기 때문에 input에 대한 순서가 고려되지 않은 것이 문제다. 단어 번역 특성상 단어의 위치는 매우 중요하기 때문에 (not의 위치가 어디가냐에 따라서 내용이 천차만별로 바뀜) positional embedding을 기존 input embedding에 추가한다.
- positional embedding을 공식만 보면 사실 어려운데 마치 0~1값을 가져서 시그모이드 함수를 쓴 것처럼 위치 값이 가진 특성들을 정의하고 그 특성을 가진 함수를 가져다 쓴거라고 이해하면 쉽다. (연구하는 입장에서는 이런걸 잘 떠올리는게 능력인 것 같긴 하다.)
- positional embedding이 가져야할 특징
- 값이 너무 커서 더했을 때 의미 정보보다 영향이 크면 안된다.
- 시퀀스 길이에 관계없이 같은 위치의 토큰은 항상 같은 위치 벡터값을 가지고 있어야 한다. 하지만 서로 다른 위치의 토큰은 위치 벡터값이 다 달라야한다. - 위 특징을 가지도록 몇가지 변수 조정을 한게 positional embedding 식이다.
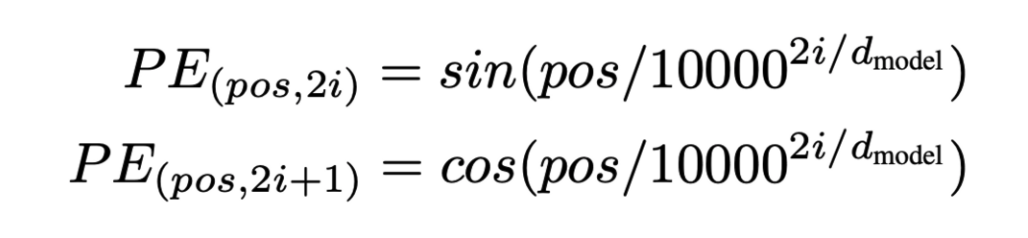
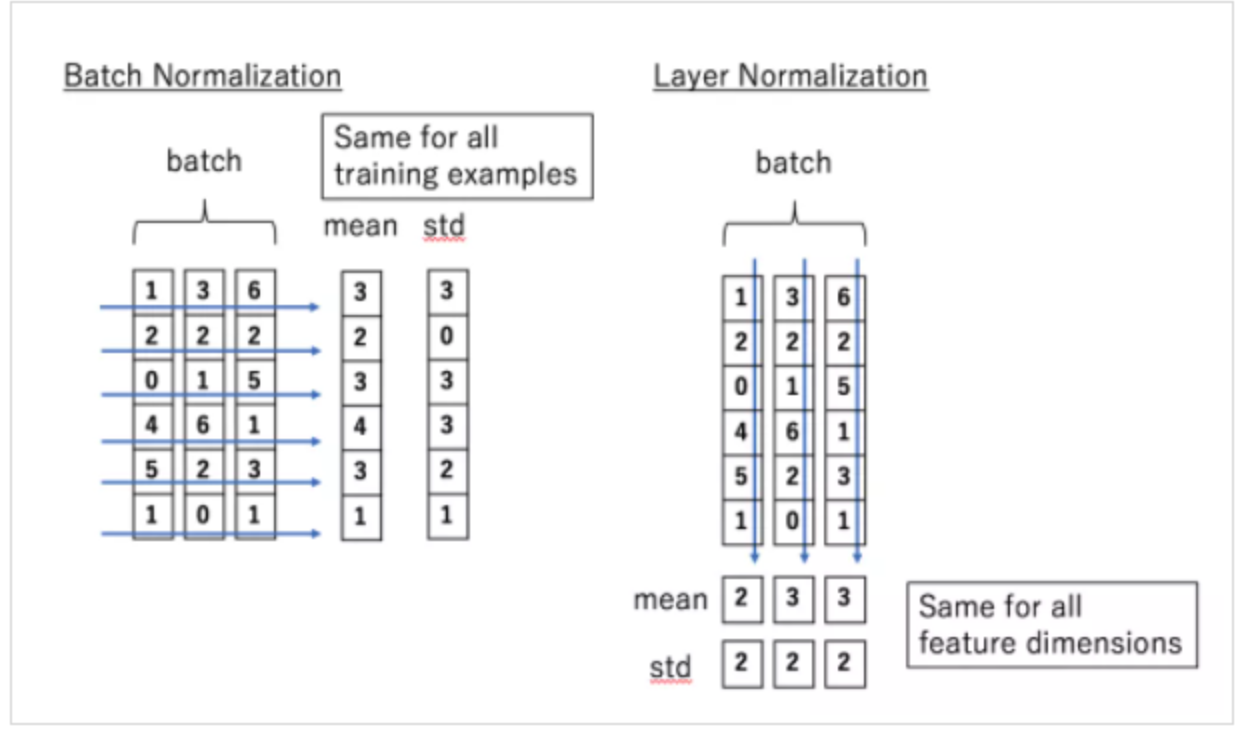
2) Batch normalization과 layer Normalization
- 배치와 레이어는 normalization을 하는 목적은 같지만, 그 대상이 다른 방식임.
트랜스포머에서는 레이어 노말라이제이션을 넣은 이유는 기본적으로 안정화를 위해서 넣은 것.
3) Masked multi-head self attention
- Encoder 단계가 아닌 Decoder 단계의 어텐션에서는 문장을 이해하는게 아니라 문장을 "생성"하는 단계다.
- 즉, 현재 생성한 토큰의 이후 토큰들에 대해서는 학습 당시에 알 수 없기 때문에 이후의 토큰들은 다 마스킹 처리한다.(auto-regressive한 특성으로 인해) -> 이 때 마스킹 처리를 매우 작은 값(마이너스 무한대)을 곱해서 Softmax 처리에서 제외시켜버린다.
참고 링크
1. 트랜스포머 시각화 : https://jalammar.github.io/illustrated-transformer/
2. 트랜스포머 positional embedding 상세하게 설명된 블로그 : https://www.blossominkyung.com/deeplearning/transfomer-positional-encoding

Lean, Learn, Lesson