Summary
오늘은 사둔 책들이 좀 있어서, 그것들을 빠르게 다 읽고 토치는 그래도 앞으로 계속 사용할 거라서 기본적인 구조들을 정리하는 작업도 하려고 한다.
Learn
- 데이터 분석가가 알아야할 모든 것(40페이지 ~ 300페이지)
- EDA, 다중공산성
- 공분산 행렬
- 언더스탠딩 "한국산 인공지능 네이버 '하이퍼클로바X'는 뭐가 다를까?" 보기
Detail
- 다중공산성
- EDA를 하는 과정에서, x와 y의 관계도 중요하지만 변수들간의 관계도 중요하다. 그래서 변수간의 공분산을 계산하는데 공분산 분석에 피어슨 상관계수가 잘 활용되지만 이는 선형 관계만을 측정할 수 있기 때문에 2차 이상 혹은 비선형 관계를 측정할 수 없다. 따라서 실제로는 산점도 그래프를 그려서 함께 확인하는 것이 중요하다.
- 전체 변수간의 산점도 행렬 시각화
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
sns.set(font_scale = 1.1)
sns.set_style('ticks')
sns.pairplot(df, diag_kind = 'kde')
plt.show()
df.cov(numeric_only = True)
sns.heatmap(df.corr(method = 'pearson'), cmap = 'viridis')
mask = np.triu(np.ones_like(df.corr(numeric_only = True), dtype = np.bool))
fig, ax = plt.subplots(figsize = (15,10))
sns.heatmap(df.corr(numeric_only = True), mask = mask, vmin = -1, vmax = 1, annot = True, cmap = 'RdYlBu_r", cbar = True)
ax.set_title('Wine Quality Correlation', pad = 15)
- boxplot, groupby, 결측값 확인
df.groupby("groupby 대상 변수")["sum할 변수"].sum().reset_index()
df.groupby("groupby 대상 변수").count().reset_index()
sns.boxplot(y = {변수})
import missingno as msno
msno.matrix(df)
plt.show() #결측치가 어디에 있는지 시각적으로 표현
msno.bar(df)
plt.show() #결측값 막대그래프df.dropna(how = {all, any}, subset = [{특정컬럼}], thresh = {최소 n개 이상의 컬럼이 결측값인 행})
- 다중공선성과 더미변수의 관계
- 기본적으로 상관관계가 높은 변수가 회귀 계수 추정에 영향을 주면 정확도나 추정이 불안정해지는 것이 다중공선성인데 더미변수 갯수를 범주의 갯수와 동일하게 가져가면, D_A + D_B + D_C = 1로 모든 변수들이 나머지 변수들에 대해서 선형식으로 구성되게 됨. 그래서 실제로는 아래와 같이 drop_first = True 조건을 걸어준다.
pd.get_dummies(data = df, columns = ['ColA'], drop_first = True, dummy_na = True)- 데이터 불균형
- 모델을 학습시키기 위해서는 단순히 데이터 양이 많은게 아니라, 분류모델에서는 각 목적변수(분류하려는 대상)별로 데이터가 충분해야한다.
- 이거에 대해서는 언더샘플링, 오버샘플링 정도의 이야기만 배웠지만, SMOTE(synthetic minority oversampling technique)라고 해서 새롭게 데이터를 만들어내는 방식도 있다.
- 데이터 간의 거리 측정
- 기본적인건 유클리드 거리이지만 코사인 유사도와 마할라노비스 거리가 단순 거리가 아닌 서로 데이터간의 영향을 고려한 거리 기준이 될것 같다.
- 코사인 유사도는 벡터간의 방향에 좀 더 초점을 맞춘 것.
- 마할라노비스는 단순 점이 아닌 다른 데이터의 분포를 고려해 거리를 잰다고 보면 될 것 같다.(하지만 데이터 분포를 고려한 상대적 거리를 계산하는 것이 어렵기 때문에, 정규화를 해서 유클리디안 거리를 하는 것이 접근 방식)
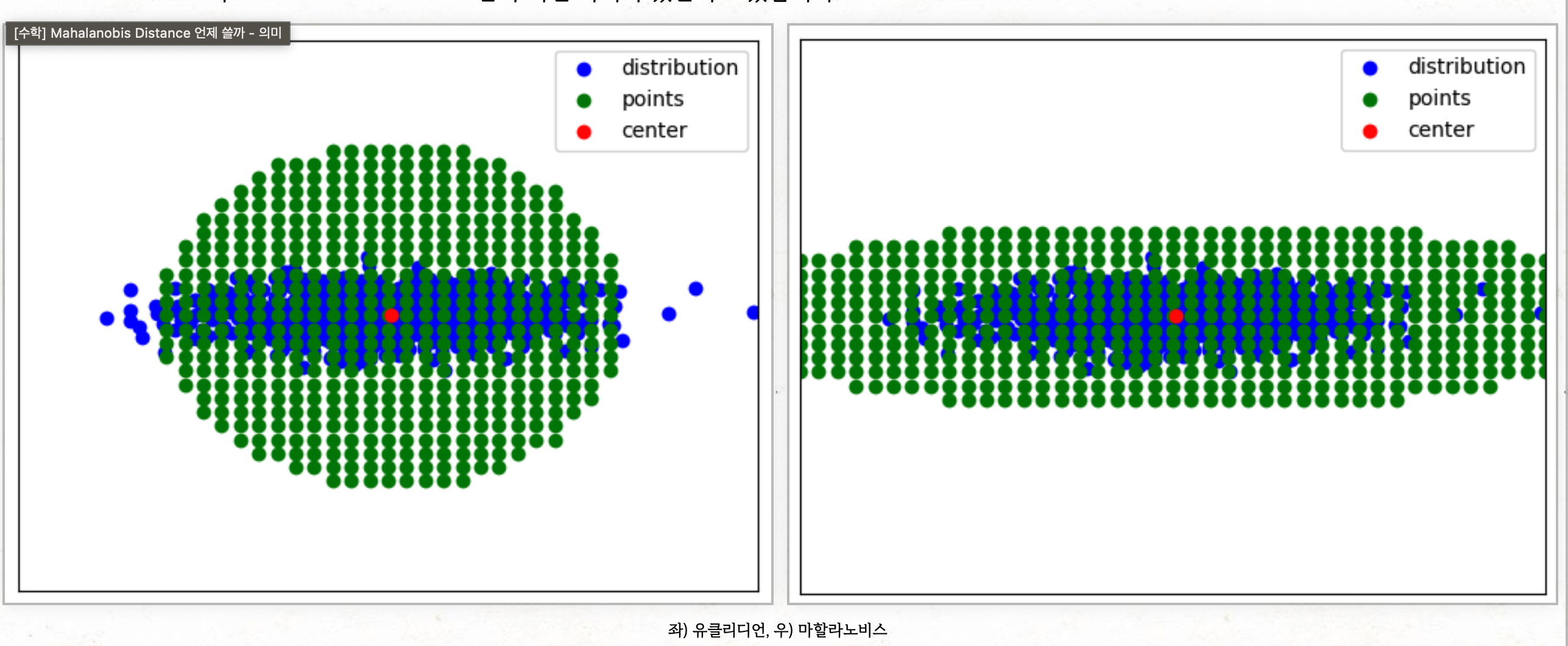
출처 : https://zeroact.tistory.com/17
세부 링크
- https://www.youtube.com/watch?v=npHeJZ_ETog&t=460s
- SMOTE 기법 설명
1) https://john-analyst.medium.com/smote%EB%A1%9C-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EB%B6%88%EA%B7%A0%ED%98%95-%ED%95%B4%EA%B2%B0%ED%95%98%EA%B8%B0-5ab674ef0b32
2) https://mkjjo.github.io/python/2019/01/04/smote_duplicate.html - 마할라노비스 거리 정리
https://zeroact.tistory.com/17 https://angeloyeo.github.io/2022/09/28/Mahalanobis_distance.html - 공분산 행렬
https://www.youtube.com/watch?v=jNwf-JUGWgg

Lean, Learn, Lesson