1. Abstract
While large language models (LLMs) have demonstrated impressive performance across tasks in language understanding and interactive decision making, their abilities for reasoning (e.g. chain-of-thought prompting) and acting (e.g. action plan generation) have primarily been studied as separate topics.
대규모 언어 모델(LLM)은 언어 이해와 상호작용 기반 의사결정 과제에서 인상적인 성능을 보여주었지만, 추론(예: 연쇄적 사고 유도)과 행동(예: 행동 계획 생성) 능력은 주로 별개의 주제로 연구되어 왔습니다.
In this paper, we explore the use of LLMs to generate both reasoning traces and task-specific actions in an interleaved manner, allowing for greater synergy between the two:
이 논문에서는 LLM이 추론 과정과 과제에 특화된 행동을 번갈아(interleaved) 생성하도록 하여, 두 요소 간의 시너지를 높이는 방법을 탐구합니다.
reasoning traces help the model induce, track, and update action plans as well as handle exceptions,
추론 과정은 모델이 행동 계획을 유도하고, 추적하며, 갱신하고, 예외 상황을 처리하는 데 도움을 줍니다.
while actions allow it to interface with and gather additional information from external sources such as knowledge bases or environments.
반면 행동은 지식 베이스나 외부 환경과 상호작용하며 추가 정보를 수집할 수 있게 합니다.
We apply our approach, named ReAct, to a diverse set of language and decision making tasks and demonstrate its effectiveness over state-of-the-art baselines in addition to improved human interpretability and trustworthiness.
우리는 이 접근 방식을 "ReAct"라 명명하고 다양한 언어 및 의사결정 과제에 적용하여, 최신 기법들과 비교해 뛰어난 성능은 물론 인간이 더 잘 이해하고 신뢰할 수 있는 결과를 생성함을 보여줍니다.
Concretely, on question answering (HotpotQA) and fact verification (Fever), ReAct overcomes prevalent issues of hallucination and error propagation in chain-of-thought reasoning by interacting with a simple Wikipedia API,
구체적으로, 질문 응답(HotpotQA)과 사실 검증(Fever) 과제에서 ReAct는 간단한 위키피디아 API와 상호작용함으로써, 연쇄적 사고 추론에서 흔히 발생하는 환각(hallucination)과 오류 전파 문제를 해결합니다.
and generating human-like task-solving trajectories that are more interpretable than baselines without reasoning traces.
또한 ReAct는 추론 과정을 포함하지 않은 기존 기법보다 더 인간적인 과제 해결 경로를 생성하여, 해석 가능성이 더 높습니다.
Furthermore, on two interactive decision making benchmarks (ALFWorld and WebShop), ReAct outperforms imitation and reinforcement learning methods by an absolute success rate of 34% and 10% respectively,
더 나아가, 두 가지 상호작용 기반 의사결정 벤치마크(ALFWorld와 WebShop)에서 ReAct는 모방 학습과 강화 학습 기법보다 각각 34%와 10%의 절대 성공률 차이로 성능이 우수합니다.
while being prompted with only one or two in-context examples.
이는 단지 하나 또는 두 개의 문맥 내 예시만을 사용한 결과입니다.
2. Introduction
A unique feature of human intelligence is the ability to seamlessly combine task-oriented actions with verbal reasoning (or inner speech, Alderson-Day & Fernyhough, 2015),
인간 지능의 독특한 특징 중 하나는 과제 중심의 행동과 언어적 추론(또는 내면적 언어)을 자연스럽게 결합할 수 있는 능력입니다 (Alderson-Day & Fernyhough, 2015).
which has been theorized to play an important role in human cognition for enabling self-regulation or strategization (Vygotsky, 1987; Luria, 1965; Fernyhough, 2010) and maintaining a working memory (Baddeley, 1992).
이는 자기 조절이나 전략 수립을 가능하게 하고, 작업 기억 유지에 핵심적인 역할을 한다고 이론적으로 제안되어 왔습니다 (Vygotsky, 1987; Luria, 1965; Fernyhough, 2010; Baddeley, 1992).
Consider the example of cooking up a dish in the kitchen.
예를 들어, 부엌에서 요리를 한다는 상황을 생각해봅시다.
Between any two specific actions, we may reason in language in order to track progress (“now that everything is cut, I should heat up the pot of water”),
개별 행동 사이에서 우리는 언어로 추론하며 진행 상황을 추적할 수 있습니다 (예: “이제 재료는 다 썰었으니, 물을 끓여야겠다”).
to handle exceptions or adjust the plan according to the situation (“I don’t have salt, so let me use soy sauce and pepper instead”),
또한 예외 상황을 처리하거나, 상황에 맞게 계획을 조정할 수도 있습니다 (예: “소금이 없으니까 간장과 후추로 대신하자”).
and to realize when external information is needed (“how do I prepare dough? Let me search on the Internet”).
또한 외부 정보가 필요함을 인식하고 그에 따라 행동할 수 있습니다 (예: “반죽은 어떻게 만들지? 인터넷에서 찾아보자”).
We may also act (open a cookbook to read the recipe, open the fridge, check ingredients) to support the reasoning and to answer questions (“What dish can I make right now?”).
우리는 추론을 지원하기 위해 행동하기도 합니다 (예: 요리책을 펴서 레시피를 확인하거나, 냉장고를 열고 재료를 확인함). 이는 “지금 어떤 요리를 만들 수 있을까?” 같은 질문에 답하기 위해서입니다.
This tight synergy between “acting” and “reasoning” allows humans to learn new tasks quickly and perform robust decision making or reasoning, even under previously unseen circumstances or facing information uncertainties.
이처럼 행동과 추론의 긴밀한 시너지는, 인간이 낯선 상황이나 정보의 불확실성 속에서도 새로운 과제를 빠르게 학습하고 탄탄한 의사결정 및 추론을 가능하게 만듭니다.
Recent results have hinted at the possibility of combining verbal reasoning with interactive decision making in autonomous systems.
최근 연구 결과는 자율 시스템에서 언어적 추론과 상호작용 기반 의사결정을 결합할 수 있는 가능성을 시사하고 있습니다.
On one hand, properly prompted large language models (LLMs) have demonstrated emergent capabilities to carry out several steps of reasoning traces to derive answers from questions in arithmetic, commonsense, and symbolic reasoning tasks (Wei et al., 2022).
한편, 적절히 프롬프트된 대형 언어 모델(LLMs)은 산술, 상식, 상징 추론 과제에서 여러 단계의 추론 경로를 생성하며 답을 유도하는 창발적 능력을 보여주었습니다 (Wei et al., 2022).
However, this “chain-of-thought” reasoning is a static black box, in that the model uses its own internal representations to generate thoughts and is not grounded in the external world,
하지만 이러한 연쇄적 사고(chain-of-thought) 추론은 정적인 블랙박스에 불과하며, 모델이 내부 표현만으로 사고를 생성하고 외부 세계와 연결되지 않기 때문에,
which limits its ability to reason reactively or update its knowledge.
반응적으로 추론하거나 지식을 갱신하는 능력이 제한됩니다.
This can lead to issues like fact hallucination and error propagation over the reasoning process (Figure 1 (1b)).
이로 인해 사실의 환각(hallucination)이나 추론 과정 전반의 오류 전파와 같은 문제가 발생할 수 있습니다 (도표 1 (1b)).

On the other hand, recent work has explored the use of pre-trained language models for planning and acting in interactive environments (Ahn et al., 2022; Nakano et al., 2021; Yao et al., 2020; Huang et al., 2022a), with a focus on predicting actions via language priors.
다른 한편으로는, 최근 연구에서는 사전학습된 언어 모델을 사용해 상호작용 환경 내에서 계획을 수립하고 행동을 수행하는 방법을 탐구하고 있으며, 언어적 사전 지식을 기반으로 행동을 예측하는 데 중점을 두고 있습니다 (Ahn et al., 2022; Nakano et al., 2021; Yao et al., 2020; Huang et al., 2022a).
These approaches usually convert multi-modal observations into text, use a language model to generate domain-specific actions or plans, and then use a controller to choose or execute them.
이러한 접근법은 보통 다중 모달 관찰 데이터를 텍스트로 변환한 후, 언어 모델이 도메인에 특화된 행동이나 계획을 생성하고, 컨트롤러가 이를 선택하거나 실행하는 방식입니다.
However, they do not employ language models to reason abstractly about high-level goals or maintain a working memory to support acting,
하지만 이들은 고차원 목표에 대한 추상적 추론을 수행하거나, 행동을 지원할 작업 기억을 유지하는 데 언어 모델을 활용하지는 않습니다.
barring Huang et al. (2022b) who perform a limited form of verbal reasoning to reiterate spatial facts about the current state.
다만 Huang et al. (2022b)는 현재 상태에 대한 공간적 사실을 반복 설명하는 제한적인 언어적 추론을 수행하긴 했습니다.
Beyond such simple embodied tasks to interact with a few blocks, there have not been studies on how reasoning and acting can be combined in a synergistic manner for general task solving,
이처럼 몇 개의 블록과 상호작용하는 단순한 체화된 과제를 넘어서, 일반적인 과제 해결을 위해 추론과 행동을 시너지 있게 결합하는 방법에 대한 연구는 거의 없었습니다.
and if such a combination can bring systematic benefits compared to reasoning or acting alone.
또한 **이러한 결합이 단독의 추론이나 행동보다 체계적인 이점을 제공할 수 있는지에 대한 연구도 부족했습니다.
In this work, we present ReAct, a general paradigm to combine reasoning and acting with language models for solving diverse language reasoning and decision making tasks (Figure 1).
이 연구에서는 ReAct라는 일반적인 패러다임을 제안합니다. 이는 언어 모델을 통해 추론과 행동을 결합함으로써 다양한 언어 추론 및 의사결정 과제를 해결할 수 있도록 합니다 (그림 1 참조).
ReAct prompts LLMs to generate both verbal reasoning traces and actions pertaining to a task in an interleaved manner,
ReAct는 대형 언어 모델(LLM)이 언어적 추론 과정과 과제 관련 행동을 번갈아(interleaved) 생성하도록 프롬프트합니다.
which allows the model to perform dynamic reasoning to create, maintain, and adjust high-level plans for acting (reason to act),
이를 통해 모델은 고차원 행동 계획을 생성, 유지, 조정할 수 있는 동적인 추론(reason to act)을 수행할 수 있습니다.
while also interact with the external environments (e.g. Wikipedia) to incorporate additional information into reasoning (act to reason).
또한 모델이 외부 환경(예: 위키피디아)과 상호작용하면서 추론에 필요한 정보를 수집하는 행동(act to reason)도 할 수 있게 됩니다.
We conduct empirical evaluations of ReAct and state-of-the-art baselines on four diverse benchmarks:
우리는 ReAct와 최신 비교 기법들을 네 가지 다양한 벤치마크에서 실증적으로 평가했습니다:
question answering (HotPotQA, Yang et al., 2018), fact verification (Fever, Thorne et al., 2018), text-based game (ALFWorld, Shridhar et al., 2020b), and webpage navigation (WebShop, Yao et al., 2022).
즉, 질문 응답(HotPotQA), 사실 검증(Fever), 텍스트 기반 게임(ALFWorld), 웹페이지 내비게이션(WebShop)입니다.
For HotPotQA and Fever, with access to a Wikipedia API that the model can interact with,
HotPotQA와 Fever에서는 모델이 위키피디아 API와 상호작용할 수 있도록 하여,
ReAct outperforms vanilla action generation models while being competitive with chain-of-thought reasoning (CoT) (Wei et al., 2022).
ReAct는 기본 행동 생성 모델보다 우수한 성능을 보였으며, 연쇄적 사고(CoT) 방식과도 경쟁력 있는 결과를 보였습니다 (Wei et al., 2022).
The best approach overall is a combination of ReAct and CoT that allows for the use of both internal knowledge and externally obtained information during reasoning.
가장 좋은 성능은 ReAct와 CoT를 결합한 방식이었으며, 이는 모델의 내적 지식과 외부 정보를 모두 활용한 추론을 가능하게 합니다.
On ALFWorld and WebShop, two or even one-shot ReAct prompting is able to outperform imitation or reinforcement learning methods trained with 10³∼10⁵ task instances,
ALFWorld와 WebShop에서는 1~2개의 예시만을 사용한 ReAct 프롬프트만으로도, 수천~수십만 개의 과제 인스턴스로 학습된 모방 학습 및 강화 학습 기법을 능가했습니다.
with an absolute improvement of 34% and 10% in success rates respectively.
각각의 과제에서 34%와 10%의 절대적인 성공률 향상이 있었습니다.
We also demonstrate the importance of sparse, versatile reasoning in decision making by showing consistent advantages over controlled baselines with actions only.
또한 행동만 사용하는 대조군보다 일관된 우위를 보여줌으로써, 희소하고 유연한 추론이 의사결정에 있어서 중요하다는 것을 입증했습니다.
Besides general applicability and performance boost, the combination of reasoning and acting also contributes to model interpretability, trustworthiness, and diagnosability across all domains,
이러한 접근 방식은 일반적 적용 가능성과 성능 향상 외에도, 모델의 해석 가능성, 신뢰도, 진단 가능성을 전반적으로 높이는 데 기여합니다.
as humans can readily distinguish information from model’s internal knowledge versus external environments,
이는 사용자가 모델의 내부 지식과 외부 환경에서 얻은 정보를 쉽게 구분할 수 있기 때문입니다.
as well as inspect reasoning traces to understand the decision basis of model actions.
또한 추론 과정을 직접 살펴봄으로써, 모델의 행동 결정 근거를 이해할 수 있게 합니다.
To summarize, our key contributions are the following:
요약하자면, 이 논문의 주요 기여점은 다음과 같습니다:
(1) we introduce ReAct, a novel prompt-based paradigm to synergize reasoning and acting in language models for general task solving;
(1) ReAct라는 새로운 프롬프트 기반 패러다임을 제안하여, 언어 모델에서 추론과 행동을 시너지 있게 결합하여 범용 과제를 해결할 수 있도록 합니다.
(2) we perform extensive experiments across diverse benchmarks to showcase the advantage of ReAct in a few-shot learning setup over prior approaches that perform either reasoning or action generation in isolation;
(2) 다양한 벤치마크에 걸쳐 소수의 예시만으로도 우수한 성능을 보임을 입증하며, 기존의 추론 또는 행동만 수행하는 접근 방식보다 ReAct의 장점을 보여줍니다.
(3) we present systematic ablations and analysis to understand the importance of acting in reasoning tasks, and reasoning in interactive tasks;
(3) 추론 과제에서의 행동의 중요성, 상호작용 과제에서의 추론의 중요성을 이해하기 위해 체계적인 구성 요소 제거 실험(ablations)과 분석을 수행합니다.
(4) we analyze the limitations of ReAct under the prompting setup (i.e. limited support of reasoning and acting behaviors),
(4) 프롬프트 기반 설정 하에서 ReAct의 한계점 (예: 제한된 추론 및 행동 수행)을 분석하고,
and perform initial finetuning experiments showing the potential of ReAct to improve with additional training data.
추가 학습 데이터로 성능 향상이 가능함을 보여주는 초기 파인튜닝 실험도 수행합니다.
Scaling up ReAct to train and operate on more tasks and combining it with complementary paradigms like reinforcement learning could further unlock the potential of large language models
ReAct를 더 많은 과제에 적용하고, 강화 학습과 같은 보완적인 패러다임과 결합한다면, 대형 언어 모델의 잠재력을 더욱 효과적으로 끌어낼 수 있을 것입니다.
3. REACT : SYNERGIZING REASONING + ACTING
Consider a general setup of an agent interacting with an environment for task solving.
과제를 해결하기 위해 에이전트가 환경과 상호작용하는 일반적인 설정을 생각해봅시다.
At time step t, an agent receives an observation ot ∈ O from the environment and takes an action at ∈ A following some policy π(at|ct),
시간 t에서 에이전트는 환경으로부터 관측값 ot ∈ O를 받고, 어떤 정책 π(at|ct)에 따라 행동 at ∈ A를 선택합니다.
where ct = (o1, a1, · · · , ot−1, at−1, ot) is the context to the agent.
여기서 ct = (o1, a1, ..., ot−1, at−1, ot) 는 에이전트가 사용하는 문맥(context) 입니다.
Learning a policy is challenging when the mapping ct → at is highly implicit and requires extensive computation.
문맥 ct를 행동 at로 매핑하는 과정이 암시적이고 계산 복잡도가 높을 때, 정책을 학습하는 것은 매우 어려워집니다.
For example, the agent shown in Figure 1(1c) is unable to generate the correct final action (Act 4) to finish the QA task as it requires complex reasoning over the trajectory context (Question, Act 1-3, Obs 1-3).
예를 들어, 그림 1(1c)에 나온 에이전트는 이전의 질문, 행동(1
3), 관측값(13) 등의 경로 문맥에 대한 복잡한 추론이 필요함에도 불구하고, QA 과제를 완료하기 위한 마지막 행동(Act 4)을 생성하지 못합니다.

Similarly, the agent shown in Figure 1(2a) fails to comprehend from the context that sinkbasin 1 does not contain peppershaker 1, thus keep producing hallucinating actions.
마찬가지로 그림 1(2a)의 에이전트는 sinkbasin 1에 peppershaker 1이 없다는 문맥 정보를 이해하지 못해, 사실과 다른 잘못된 행동(hallucination)을 반복적으로 생성합니다.
The idea of ReAct is simple: we augment the agent’s action space to ˆA = A ∪ L, where L is the space of language.
ReAct의 아이디어는 간단합니다: 에이전트의 행동 공간을 ˆA = A ∪ L로 확장하는 것입니다. 여기서 L은 언어의 공간을 의미합니다.
An action ˆat ∈ L in the language space, which we will refer to as a thought or a reasoning trace, does not affect the external environment, thus leading to no observation feedback.
언어 공간 L에 속하는 행동 ˆat은 ‘생각(thought)’ 또는 ‘추론 경로(reasoning trace)’라고 하며, 이는 외부 환경에 영향을 미치지 않기 때문에 관측 피드백이 발생하지 않습니다.
Instead, a thought ˆat aims to compose useful information by reasoning over the current context ct,
대신 이러한 생각은 현재 문맥 ct에 대해 추론을 수행하여 유용한 정보를 구성하는 데 목적이 있습니다.
and update the context ct+1 = (ct, ˆat) to support future reasoning or acting.
그리고 이를 통해 문맥을 ct+1 = (ct, ˆat)로 갱신하여 향후 추론 또는 행동을 지원합니다.
As shown in Figure 1, there could be various types of useful thoughts,
그림 1에서 보듯이, 다양한 형태의 유용한 생각들이 존재할 수 있습니다.
e.g. decomposing task goals and create action plans (2b, Act 1; 1d, Thought 1),
예: 과제 목표를 분해하고 행동 계획을 수립하는 것 (2b, Act 1; 1d, Thought 1),
injecting commonsense knowledge relevant to task solving (2b, Act 1),
과제 해결에 관련된 상식적인 지식을 삽입하는 것 (2b, Act 1),
extracting important parts from observations (1d, Thought 2, 4),
관측값에서 중요한 부분을 추출하는 것 (1d, Thought 2, 4),
track progress and transit action plans (2b, Act 8),
진행 상황을 추적하고 행동 계획을 전환하는 것 (2b, Act 8),
handle exceptions and adjust action plans (1d, Thought 3), and so on.
예외를 처리하고 계획을 조정하는 것 (1d, Thought 3) 등입니다.
However, as the language space L is unlimited, learning in this augmented action space is difficult and requires strong language priors.
하지만 언어 공간 L은 무한한 가능성을 가지므로, 이 확장된 행동 공간에서의 학습은 어렵고, 강력한 언어 기반 사전 지식(language prior)이 필요합니다.
In this paper, we mainly focus on the setup where a frozen large language model, PaLM-540B (Chowdhery et al., 2022), is prompted with few-shot in-context examples
이 논문에서는 고정된(frozen) 대형 언어 모델인 PaLM-540B (Chowdhery et al., 2022)를 대상으로, 소수의 문맥 내 예시(few-shot in-context examples)를 제공하는 설정에 중점을 둡니다.
to generate both domain-specific actions and free-form language thoughts for task solving (Figure 1 (1d), (2b)).
이 모델은 과제를 해결하기 위해 도메인 특화 행동과 자유형 언어 기반 생각을 모두 생성하게 됩니다 (그림 1 (1d), (2b)).
Each in-context example is a human trajectory of actions, thoughts, and environment observations to solve a task instance (see Appendix C).
각 문맥 내 예시는 인간이 과제를 해결하는 데 사용한 행동, 생각, 환경 관측의 경로를 포함합니다 (부록 C 참조).
For the tasks where reasoning is of primary importance (Figure 1(1)),
추론이 주요한 과제들 (그림 1(1))의 경우,
we alternate the generation of thoughts and actions so that the task-solving trajectory consists of multiple thought-action-observation steps.
생각과 행동을 번갈아 생성하여, 과제 해결 경로가 복수의 생각-행동-관측 단계로 구성되도록 합니다.
In contrast, for decision making tasks that potentially involve a large number of actions (Figure 1(2)),
반면, 많은 수의 행동이 필요한 의사결정 과제들 (그림 1(2))에서는,
thoughts only need to appear sparsely in the most relevant positions of a trajectory,
생각은 가장 관련 있는 위치에만 드문드문 등장하면 됩니다.
so we let the language model decide the asynchronous occurrence of thoughts and actions for itself.
따라서 생각과 행동이 비동기적으로 언제 발생할지는 모델이 스스로 결정하게 합니다.
Since decision making and reasoning capabilities are integrated into a large language model, ReAct enjoys several unique features:
ReAct는 대형 언어 모델에 추론과 의사결정 능력을 통합했기 때문에, 다음과 같은 독특한 특징들을 지닙니다:
A) Intuitive and easy to design:
A) 직관적이고 설계가 쉬움:
Designing ReAct prompts is straightforward as human annotators just type down their thoughts in language on top of their actions taken.
ReAct 프롬프트를 설계하는 과정은 간단하며, 사람이 수행한 행동 위에 언어로 생각을 적기만 하면 됩니다.
No ad-hoc format choice, thought design, or example selection is used in this paper.
이 논문에서는 특수한 형식, 생각 디자인, 예시 선택 없이도 가능합니다.
We detail prompt design for each task in Sections 3 and 4.
각 과제에 대한 프롬프트 설계는 섹션 3과 4에서 자세히 설명합니다.
B) General and flexible:
B) 일반적이고 유연함:
Due to the flexible thought space and thought-action occurrence format, ReAct works for diverse tasks with distinct action spaces and reasoning needs,
유연한 생각 공간과 생각-행동의 발생 방식 덕분에, ReAct는 다양한 행동 공간과 추론 요구를 가진 과제들에 적용 가능합니다.
including but not limited to QA, fact verification, text game, and web navigation.
예: 질문 응답, 사실 검증, 텍스트 게임, 웹 내비게이션 등입니다.
C) Performant and robust:
C) 성능이 뛰어나고 강건함:
ReAct shows strong generalization to new task instances while learning solely from one to six in-context examples,
ReAct는 1~6개의 문맥 내 예시만으로도 새로운 과제에 대한 일반화 성능을 강하게 보입니다.
consistently outperforming baselines with only reasoning or acting across different domains.
이는 추론이나 행동만 수행하는 기존 기법들보다 일관되게 더 나은 성능을 보여줍니다.
We also show in Section 3 additional benefits when finetuning is enabled,
섹션 3에서는 파인튜닝을 활용할 경우 추가적인 이점도 제시합니다.
and in Section 4 how ReAct performance is robust to prompt selections.
섹션 4에서는 ReAct가 프롬프트 선택에 대해 얼마나 강건한지도 분석합니다.
D) Human aligned and controllable:
D) 인간 친화적이며 제어 가능함:
ReAct promises an interpretable sequential decision making and reasoning process where humans can easily inspect reasoning and factual correctness.
ReAct는 해석 가능한 순차적 의사결정 및 추론 과정을 제공하며, 사용자가 추론 내용과 사실성의 정확성을 쉽게 검토할 수 있습니다.
Moreover, humans can also control or correct the agent behavior on the go by thought editing, as shown in Figure 5 in Section 4
또한 섹션 4의 그림 5에서 보이듯이, 사용자는 생각을 편집하여 에이전트의 행동을 실시간으로 제어하거나 수정할 수도 있습니다.

KNOWLEDGE-INTENSIVE REASONING TASKS
We begin with knowledge-intensive reasoning tasks like multi-hop question answering and fact verification.
우리는 지식 집약적인 추론 과제, 즉 멀티홉 질문 응답 및 사실 검증과 같은 과제부터 시작합니다.
As shown in Figure 1(1d), by interacting with a Wikipedia API, ReAct is able to retrieve information to support reasoning,
그림 1(1d)에서 보이듯이, ReAct는 Wikipedia API와 상호작용함으로써 추론을 지원하는 정보를 검색할 수 있습니다.
while also use reasoning to target what to retrieve next, demonstrating a synergy of reasoning and acting.
또한 다음에 어떤 정보를 검색할지를 추론을 통해 결정함으로써, 추론과 행동 간의 시너지를 보여줍니다.
3.1 SETUP
Domains We consider two datasets challenging knowledge retrieval and reasoning:
도메인(과제 분야): 우리는 지식 검색과 추론이 어려운 두 가지 데이터셋을 다룹니다:
(1) HotPotQA (Yang et al., 2018), a multi-hop question answering benchmark that requires reasoning over two or more Wikipedia passages,
(1) HotPotQA (Yang et al., 2018): 두 개 이상의 위키피디아 문서를 넘나들며 추론해야 하는 멀티홉 질문 응답 벤치마크입니다.
and (2) FEVER (Thorne et al., 2018), a fact verification benchmark where each claim is annotated SUPPORTS, REFUTES, or NOT ENOUGH INFO,
(2) FEVER (Thorne et al., 2018): 주어진 주장(claim)에 대해 SUPPORTS(지지), REFUTES(반박), NOT ENOUGH INFO(정보 부족) 중 하나로 라벨링된 사실 검증 벤치마크입니다.
based on if there exists a Wikipedia passage to verify the claim.
이는 위키피디아 문서 내에 주장을 검증할 수 있는 근거가 존재하는지 여부에 기반합니다.
In this work, we operate in a question-only setup for both tasks,
이번 연구에서는 두 과제 모두에서 "질문만 제공되는 설정(question-only setup)"으로 실험을 진행합니다.
where models only receive the question/claim as input without access to support paragraphs,
즉, 모델은 지원 문단 없이 질문 또는 주장만을 입력으로 받으며,
and have to rely on their internal knowledge or retrieve knowledge via interacting with an external environment to support reasoning.
모델 내부 지식 또는 외부 환경과의 상호작용을 통해 지식을 획득하고, 이를 바탕으로 추론을 수행해야 합니다.
Action Space
We design a simple Wikipedia web API with three types of actions to support interactive information retrieval:
우리는 상호작용 기반 정보 검색을 지원하기 위해 간단한 Wikipedia 웹 API를 설계했으며, 세 가지 행동 유형을 정의합니다:
(1) search[entity],
(1) search[엔티티]:
which returns the first 5 sentences from the corresponding entity wiki page if it exists,
존재하는 경우 해당 엔티티의 위키피디아 페이지에서 처음 5개의 문장을 반환합니다.
or else suggests top-5 similar entities from the Wikipedia search engine,
만약 존재하지 않으면 Wikipedia 검색 엔진에서 유사한 상위 5개 엔티티를 추천합니다.
(2) lookup[string],
(2) lookup[문자열]:
which would return the next sentence in the page containing string,
지정된 문자열을 포함한 문장에서 그 다음 문장을 반환합니다.
simulating Ctrl+F functionality on the browser.
이는 브라우저에서 Ctrl+F 기능을 모사한 것입니다.
(3) finish[answer],
(3) finish[답변]:
which would finish the current task with answer.
지금까지 얻은 정보로 과제를 종료하고 답변을 제출하는 행동입니다.
We note that this action space mostly can only retrieve a small part of a passage based on exact passage name,
이러한 행동 공간은 정확한 문서명에 기반해 문서의 일부분만 검색할 수 있기 때문에,
which is significantly weaker than state-of-the-art lexical or neural retrievers.
최신의 어휘 기반 또는 신경망 기반 검색 시스템보다 훨씬 제한적입니다.
The purpose is to simulate how humans would interact with Wikipedia,
이러한 제약은 인간이 Wikipedia를 사용할 때의 행동 방식을 시뮬레이션하기 위함입니다.
and force models to retrieve via explicit reasoning in language.
즉, 모델이 언어 기반의 명시적 추론을 통해 정보를 검색하도록 유도하려는 목적입니다.
3.2 METHODS
ReAct 프롬프팅
For HotpotQA and Fever, we randomly select 6 and 3 cases from the training set and manually compose ReAct-format trajectories to use as few-shot exemplars in the prompts.
HotPotQA와 FEVER에 대해, 훈련 세트에서 각각 6개와 3개의 사례를 무작위로 선택하여, ReAct 형식의 경로(trajectories)를 수동으로 작성하고 이를 few-shot 프롬프트 예시로 활용합니다.
Similar to Figure 1(d), each trajectory consists of multiple thought-action-observation steps (i.e. dense thought), where free-form thoughts are used for various purposes.
그림 1(d)와 유사하게, 각 경로는 복수의 생각(Thought)-행동(Action)-관측값(Observation) 단계를 포함하며, 이때 자유형식의 생각(free-form thoughts)은 다양한 목적으로 사용됩니다.
Specifically, we use a combination of thoughts that:
구체적으로, 우리는 다음과 같은 유형의 생각들을 조합하여 사용합니다:
decompose questions (“I need to search x, find y, then find z”),
- 질문을 분해함 (“x를 검색하고, y를 찾고, 그다음 z를 찾자”)
extract information from Wikipedia observations (“x was started in 1844”, “The paragraph does not tell x”),
- Wikipedia 관측값에서 정보 추출 (“x는 1844년에 시작되었음”, “해당 문단은 x에 대해 언급하지 않음”)
perform commonsense (“x is not y, so z must instead be...”),
- 상식적 추론 수행 (“x는 y가 아니므로, z가 대신 되어야 함”)
arithmetic reasoning (“1844 < 1989”),
- 산술 추론 수행 (“1844 < 1989”)
guide search reformulation (“maybe I can search/look up x instead”),
- 검색 방향을 재설정 (“대신 x를 검색해보는 게 좋을지도 몰라”)
synthesize the final answer (“...so the answer is x”).
- 최종 답변을 종합 (“...따라서 답은 x이다”)
See Appendix C for more details.
자세한 내용은 부록 C를 참고하세요.
Baselines
We systematically ablate ReAct trajectories to build prompts for multiple baselines (with formats as Figure 1(1a-1c)):
우리는 ReAct 경로에서 구성 요소들을 체계적으로 제거(ablations)하여 여러 기준선(baseline) 프롬프트를 구성했습니다 (형식은 그림 1(1a~1c) 참조).
(a) Standard prompting (Standard), which removes all thoughts, actions, observations in ReAct trajectories.
(a) Standard prompting: ReAct 경로에서 생각, 행동, 관측값을 모두 제거한 표준 프롬프트입니다.
(b) Chain-of-thought prompting (CoT) (Wei et al., 2022), which removes actions and observations and serve as a reasoning-only baseline.
(b) Chain-of-thought prompting (CoT) (Wei et al., 2022): 행동과 관측값을 제거하고 추론만 수행하는 기준선입니다.
We also build a self-consistency baseline (CoT-SC) (Wang et al., 2022a;b)
우리는 또한 자기 일관성(self-consistency)을 기반으로 한 CoT-SC 기준선도 구축했습니다 (Wang et al., 2022a; b).
by sampling 21 CoT trajectories with decoding temperature 0.7 during inference and adopting the majority answer,
이는 디코딩 온도 0.7로 CoT 경로를 21개 생성한 후, 다수결 답변을 채택하는 방식입니다.
which is found to consistently boost performance over CoT.
이 방식은 기존 CoT보다 일관되게 성능을 향상시키는 것으로 나타났습니다.
(c) Acting-only prompt (Act), which removes thoughts in ReAct trajectories,
(c) Acting-only prompt (Act): ReAct 경로에서 생각(Thought)을 제거한 프롬프트입니다.
loosely resembling how WebGPT (Nakano et al., 2021) interacts with the Internet to answer questions,
이는 WebGPT(Nakano et al., 2021)가 인터넷과 상호작용하며 질문에 답하는 방식과 유사합니다.
though it operates on a different task and action space, and uses imitation and reinforcement learning instead of prompting.
다만 WebGPT는 다른 과제 및 행동 공간을 사용하고, 프롬프트 대신 모방 학습 및 강화 학습을 적용한다는 차이점이 있습니다.
Combining Internal and External Knowledge
As will be detail in Section 3.3, we observe that the problem solving process demonstrated by ReAct is more factual and grounded,
섹션 3.3에서 자세히 설명하겠지만, ReAct는 더 사실 기반이고 근거 중심적인 문제 해결 경로를 생성하는 경향이 있습니다.
whereas CoT is more accurate in formulating reasoning structure but can easily suffer from hallucinated facts or thoughts.
반면 CoT는 추론 구조를 형식화하는 데는 더 정확하지만, 사실 왜곡이나 허위 추론(hallucination)이 발생하기 쉽습니다.
We therefore propose to incorporate ReAct and CoT-SC, and let the model decide when to switch to the other method based on the following heuristics:
따라서 우리는 ReAct와 CoT-SC를 통합하는 방식을 제안하며, 모델이 다음의 휴리스틱에 따라 두 방법 간 전환을 하도록 합니다:
A) ReAct → CoT-SC:
A) ReAct에서 CoT-SC로 전환:
when ReAct fails to return an answer within given steps, back off to CoT-SC.
ReAct가 지정된 단계 수 내에 답변을 반환하지 못하면, CoT-SC로 전환합니다.
We set 7 and 5 steps for HotpotQA and FEVER respectively as we find more steps will not improve ReAct performance.
HotPotQA는 7단계, FEVER는 5단계로 설정했으며, 더 많은 단계는 ReAct 성능 향상에 도움이 되지 않는 것으로 나타났습니다.
B) CoT-SC → ReAct:
B) CoT-SC에서 ReAct로 전환:
when the majority answer among n CoT-SC samples occurs less than n/2 times
CoT-SC 샘플 n개 중, 다수결 답변이 n/2 미만일 경우,
(i.e. internal knowledge might not support the task confidently), back off to ReAct.
즉, 내부 지식만으로는 신뢰도 있는 해결이 어렵다고 판단될 때, ReAct로 전환합니다.
Finetuning
Due to the challenge of manually annotating reasoning traces and actions at scale,
대규모로 추론 과정과 행동을 수동으로 주석 달기 어려운 점을 고려하여,
we consider a bootstraping approach similar to Zelikman et al. (2022),
우리는 Zelikman et al. (2022)과 유사한 부트스트래핑 방식을 채택했습니다.
using 3,000 trajectories with correct answers generated by ReAct (also for other baselines)
ReAct(및 다른 기준선들)로부터 생성된 정답이 포함된 3,000개의 경로 데이터를 활용하여,
to finetune smaller language models (PaLM-8/62B) to decode trajectories (all thoughts, actions, observations) conditioned on input questions/claims.
PaLM-8B 및 PaLM-62B와 같은 소형 언어 모델을 파인튜닝하고, 질문/주장을 조건으로 전체 경로(생각, 행동, 관측값)를 생성하도록 합니다.
More details are in Appendix B.1.
자세한 내용은 부록 B.1에 포함되어 있습니다.
3.3 결과 및 관찰 (RESULTS AND OBSERVATIONS)
ReAct는 Act보다 일관적으로 우수한 성능을 보임
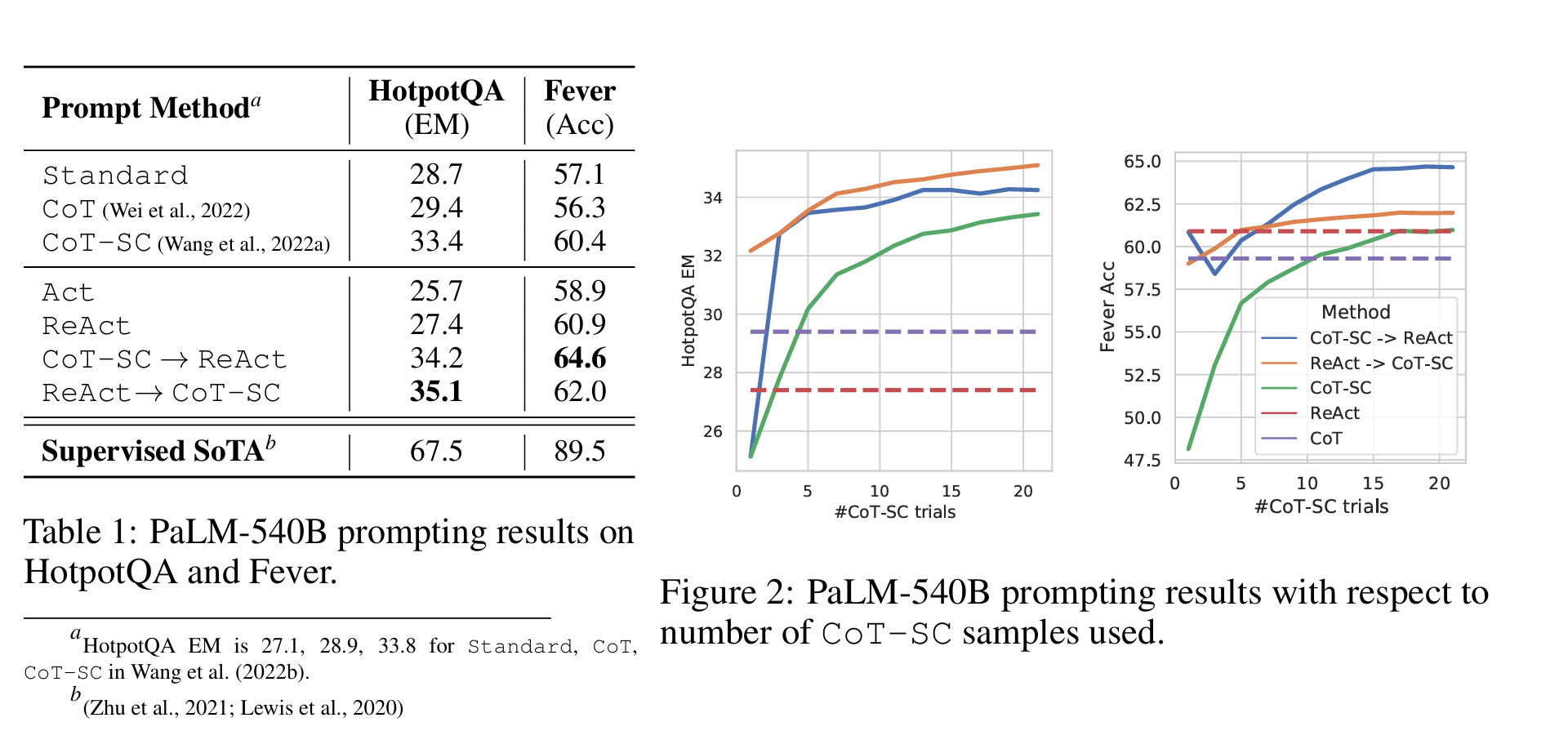
Table 1 shows HotpotQA and Fever results using PaLM-540B as the base model with different prompting methods.
표 1은 PaLM-540B 모델에 다양한 프롬프트 방법을 적용한 HotPotQA와 FEVER의 결과를 보여줍니다.
We note that ReAct is better than Act on both tasks,
ReAct는 두 과제 모두에서 Act보다 더 나은 성능을 보였습니다.
demonstrating the value of reasoning to guide acting, especially for synthesizing the final answer, as shown in Figure 1 (1c-d).
이는 특히 최종 답변을 종합하는 과정에서, 행동을 유도하는 추론의 중요성을 보여주는 결과입니다 (그림 1 (1c-d) 참조).
Fine-tuning results also confirm the benefit of reasoning traces for more informed acting.
파인튜닝 실험 결과 또한, 추론 경로(reasoning trace)가 정보에 기반한 행동을 촉진하는 데 유익함을 확인해줍니다.
ReAct vs. CoT

ReAct outperforms CoT on Fever (60.9 vs. 56.3) and slightly lags behind CoT on HotpotQA (27.4 vs. 29.4).
ReAct는 FEVER에서 CoT보다 더 높은 성능(60.9 vs. 56.3)을 보였으며, HotPotQA에서는 약간 뒤쳐짐(27.4 vs. 29.4)을 보였습니다.
Fever claims for SUPPORTS/REFUTES might only differ by a slight amount (see Appendix D.1), so acting to retrieve accurate and up-to-date knowledge is vital.
FEVER에서 SUPPORTS/REFUTES 구분은 미묘한 차이에 의해 결정되므로, 정확하고 최신 지식을 검색하는 행동이 매우 중요합니다 (부록 D.1 참조).
To better understand the behavioral difference between ReAct and CoT on HotpotQA,
HotPotQA에서 ReAct와 CoT의 행동 방식 차이를 더 잘 이해하기 위해,
we randomly sampled 50 trajectories with correct and incorrect answers (judged by EM) from ReAct and CoT respectively (thus 200 examples in total),
우리는 정답과 오답을 포함한 50개의 경로(EM 기준)를 ReAct와 CoT에서 각각 샘플링하여 총 200개의 예제를 분석했습니다.
and manually labeled their success and failure modes in Table 2.
그리고 표 2에 성공 및 실패 유형을 수작업으로 라벨링했습니다.
주요 관찰사항:
A) Hallucination is a serious problem for CoT,
A) CoT는 사실 환각(hallucination) 문제가 심각합니다.
resulting in much higher false positive rate than ReAct (14% vs. 6%) in success mode, and make up its major failure mode (56%).
CoT는 성공 사례 중에도 오답률(false positive)이 ReAct보다 두 배 이상 높았고 (14% vs. 6%), 전체 실패 사례의 56%는 환각에 기인했습니다.
In contrast, the problem solving trajectory of ReAct is more grounded, fact-driven, and trustworthy, thanks to the access of an external knowledge base.
반면, ReAct는 외부 지식베이스에 접근함으로써, 더 사실 기반(fact-driven)이고 신뢰 가능한 추론 경로를 보여주었습니다.
B) While interleaving reasoning, action and observation steps improves ReAct’s groundedness and trustworthiness,
B) 추론-행동-관측 단계를 교차(interleave)하는 구조는 ReAct의 사실 기반성과 신뢰성을 향상시키지만,
such a structural constraint also reduces its flexibility in formulating reasoning steps,
이러한 구조적 제약은 추론 단계의 유연성을 떨어뜨릴 수 있습니다.
leading to more reasoning error rate than CoT.
그 결과 추론 오류율은 CoT보다 높아질 수 있습니다.
One frequent error pattern specific to ReAct is repetitive generation of previous thoughts and actions,
ReAct에서 자주 발생하는 오류는 이전 생각이나 행동을 반복 생성하는 패턴입니다.
which we categorize as “reasoning error” since the model fails to reason about the proper next action and gets stuck in a loop.
이는 모델이 적절한 다음 행동을 추론하지 못하고 루프에 빠지는 것으로, ‘추론 오류’로 분류됩니다.
C) For ReAct, successfully retrieving informative knowledge via search is critical.
C) ReAct에게 있어 유익한 정보를 검색(search)하는 것은 성공의 핵심 요소입니다.
Non-informative search, which counts for 23% of the error cases,
하지만 의미 없는 검색(non-informative search)은 전체 오류의 23%를 차지했습니다.
derails the model reasoning and gives it a hard time to recover and reformulate thoughts.
이는 모델의 추론을 흐트러뜨리고, 생각을 다시 구성하기 어렵게 만듭니다.
This is perhaps an expected trade-off between factuality and flexibility,
이는 사실성(factuality)과 유연성(flexibility) 사이의 예상 가능한 트레이드오프(trade-off)일 수 있으며,
which motivates our proposed strategies of combining two methods.
이러한 점이 ReAct와 CoT-SC를 결합하는 전략의 동기가 됩니다.
We provide examples for each success and failure modes in Appendix E.1.
각 성공/실패 사례의 예시는 부록 E.1에 수록되어 있습니다.
We also find some HotpotQA questions may contain outdated answer labels, see Figure 4 for example.
또한, 일부 HotpotQA 질문은 오래된 정답 레이블을 포함하고 있을 수 있으며, 그 예시는 그림 4에 제시되어 있습니다.
ReAct + CoT-SC 조합은 LLM 프롬프팅에서 최상의 성능
Also shown in Table 1, the best prompting method on HotpotQA and Fever are ReAct → CoT-SC and CoT-SC → ReAct respectively.
표 1에 나타난 바와 같이, HotPotQA에서는 ReAct → CoT-SC, FEVER에서는 CoT-SC → ReAct 조합이 최상의 프롬프트 방식입니다.
Furthermore, Figure 2 shows how different methods perform with respect to the number of CoT-SC samples used.
또한 그림 2에서는 CoT-SC 샘플 수에 따른 각 방법의 성능 변화를 보여줍니다.
While two ReAct + CoT-SC methods are advantageous at one task each,
두 가지 ReAct + CoT-SC 방식은 각각 하나의 과제에서 우위를 보이지만,
they both significantly and consistently outperform CoT-SC across different number of samples,
모든 샘플 수에서 CoT-SC 단독보다 일관되게 뛰어난 성능을 보였습니다.
reaching CoT-SC performance with 21 samples using merely 3–5 samples.
즉, 3~5개의 샘플만으로도 CoT-SC 21개 샘플 수준의 성능을 달성했습니다.
These results indicate the value of properly combining model internal knowledge and external knowledge for reasoning tasks.
이 결과는 모델의 내부 지식과 외부 지식을 적절히 결합하는 것이 추론 과제에서 매우 유효함을 보여줍니다.
ReAct는 파인튜닝에서도 최상위 성능을 기록
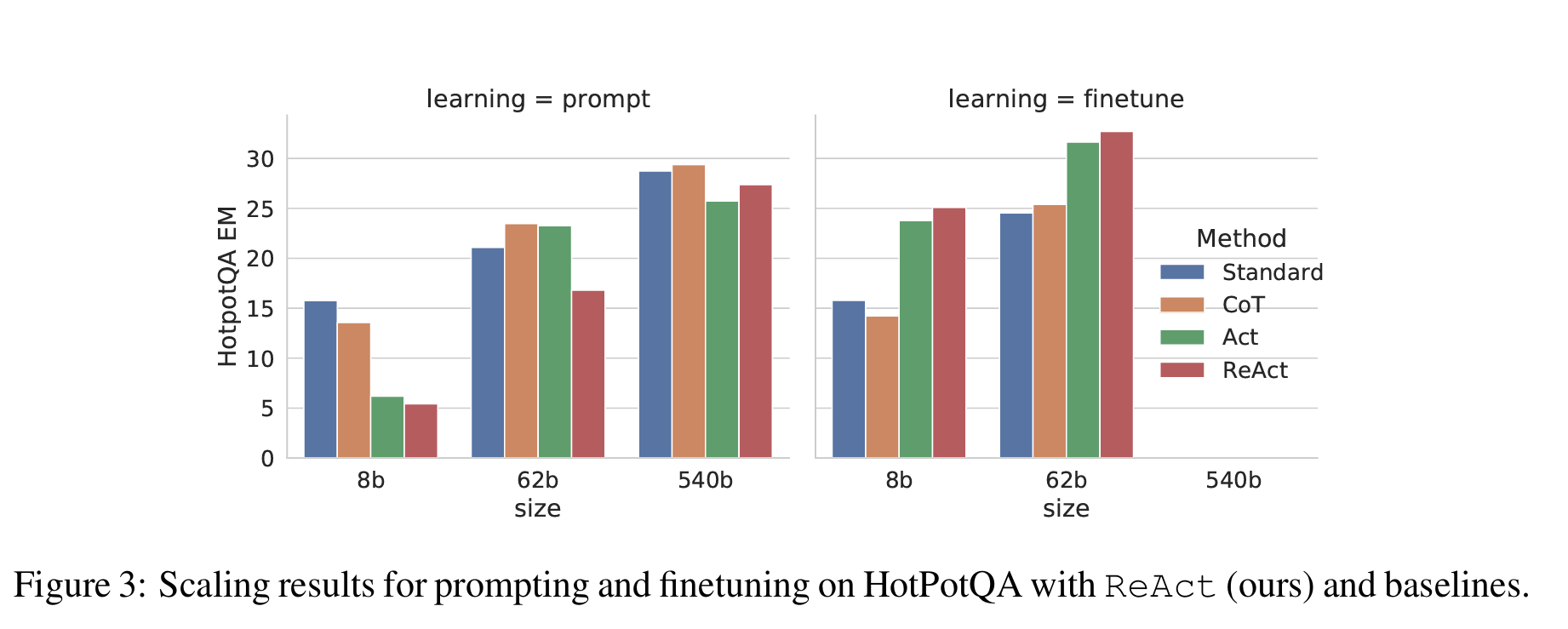
Figure 3 shows the scaling effect of prompting/finetuning four methods (Standard, CoT, Act, ReAct) on HotpotQA.
그림 3은 Standard, CoT, Act, ReAct 네 가지 방법을 HotpotQA에서 프롬프팅 및 파인튜닝했을 때의 스케일링 효과를 보여줍니다.
With PaLM-8/62B, prompting ReAct performs worst among four methods due to the difficulty to learn both reasoning and acting from in-context examples.
PaLM-8B 및 62B에서 ReAct 프롬프트만 사용했을 때는, 추론과 행동을 동시에 학습하기 어려워 성능이 가장 낮았습니다.
However, when finetuned with just 3,000 examples, ReAct becomes the best method among the four,
하지만 단 3,000개의 예시로 파인튜닝한 경우, ReAct는 네 가지 방법 중 최고의 성능을 기록했습니다.
with PaLM-8B finetuned ReAct outperforming all PaLM-62B prompting methods,
PaLM-8B에 파인튜닝된 ReAct는 모든 PaLM-62B 프롬프트 방식보다 뛰어났고,
and PaLM-62B finetuned ReAct outperforming all 540B prompting methods.
PaLM-62B에 파인튜닝된 ReAct는 모든 540B 프롬프트 방식보다도 우수했습니다.
In contrast, finetuning Standard or CoT is significantly worse than finetuning ReAct or Act for both PaLM-8/62B,
반면, Standard나 CoT를 파인튜닝하는 경우, ReAct나 Act를 파인튜닝하는 것보다 성능이 훨씬 떨어졌습니다 (PaLM-8/62B 모두에서).
as the former essentially teaches models to memorize (potentially hallucinated) knowledge facts,
이는 Standard/CoT 방식은 모델에게 (환각일 수도 있는) 지식 사실을 단순 암기하게 만들기 때문이며,
and the latter teaches models how to (reason and) act to access information from Wikipedia,
반면, ReAct/Act는 Wikipedia에서 정보를 검색하는 방법(추론 + 행동)을 학습시키기 때문입니다.
a more generalizable skill for knowledge reasoning.
이는 지식 추론에 있어 더 일반화 가능한 능력입니다.
As all prompting methods are still significantly far from domain-specific state-of-the-art approaches (Table 1),
다만, 모든 프롬프트 기반 방법들은 여전히 도메인 특화 최신 기법들보다는 성능이 크게 부족합니다 (표 1 참조).
we believe finetuning with more human-written data might be a better way to unleash the power of ReAct.
따라서 더 많은 사람이 직접 작성한 데이터로 ReAct를 파인튜닝하는 것이 그 잠재력을 실현할 수 있는 최선의 방법이라고 판단됩니다.
4. 의사결정 과제 (DECISION MAKING TASKS)
We also test ReAct on two language-based interactive decision-making tasks, ALFWorld and WebShop,
우리는 ReAct를 두 가지 언어 기반 상호작용 의사결정 과제, 즉 ALFWorld와 WebShop에서도 실험했습니다.
both of which feature complex environments that require agents to act over long horizons with sparse rewards,
이 두 환경 모두 복잡하고 보상이 드문(sparse) 상황에서 장기적인 행동 수행이 요구되는 특징을 갖고 있습니다.
warranting the need for reasoning to act and explore effectively.
따라서 효과적인 탐색과 행동 수행을 위해 추론이 필수적입니다.
ALFWorld
ALFWorld (Shridhar et al., 2020b) (Figure 1(2)) is a synthetic text-based game designed to align with the embodied ALFRED benchmark (Shridhar et al., 2020a).
ALFWorld는 텍스트 기반 가상 게임으로, ALFRED라는 실제 환경 기반 벤치마크와의 정렬을 위해 설계되었습니다 (그림 1(2)).
It includes 6 types of tasks in which an agent needs to achieve a high-level goal (e.g. examine paper under desklamp)
이 환경에는 6가지 유형의 과제가 있으며, 예를 들어 "책상 조명 아래에 있는 종이를 검사하라" 같은 고차원 목표를 요구합니다.
by navigating and interacting with a simulated household via text actions (e.g. go to coffeetable 1, take paper 2, use desklamp 1).
모델은 텍스트 기반 행동을 통해 가상 가정 환경을 탐색하고 상호작용해야 합니다 (예: "커피테이블 1로 이동", "종이 2를 집기", "조명 1 사용").
A task instance can have more than 50 locations and take an expert policy more than 50 steps to solve,
하나의 과제 인스턴스에는 50개 이상의 위치가 포함될 수 있으며, 전문가 정책도 50단계 이상 소요됩니다.
thus challenging an agent to plan and track subgoals, as well as explore systematically
따라서 에이전트는 세부 목표를 계획하고 추적하며, 체계적으로 탐색해야 하는 도전 과제를 가지게 됩니다.
(e.g. check all desks one by one for desklamp).
예: 조명을 찾기 위해 모든 책상을 하나씩 확인하기.
One challenge built into ALFWorld is the need to determine likely locations for common household items,
ALFWorld의 핵심 난점 중 하나는, 일반적인 가정용 물건이 어디에 있을 가능성이 높은지 추론하는 것입니다.
making this environment a good fit for LLMs to exploit their pretrained commonsense knowledge.
이는 LLM이 사전 학습된 상식 지식을 활용하기에 적합한 환경입니다.
To prompt ReAct, we randomly annotate three trajectories from the training set for each task type,
ReAct 실험을 위해, 우리는 각 과제 유형에 대해 훈련 세트에서 무작위로 3개의 경로를 수동 주석 처리했습니다.
where each trajectory includes sparse thoughts that (1) decompose the goal, (2) track subgoal completion, (3) determine the next subgoal, and (4) reason via commonsense where to find an object and what to do with it.
각 경로에는 희소한 생각(thoughts)이 포함되며, 그 목적은 다음과 같습니다:
(1) 목표 분해, (2) 세부 목표 추적, (3) 다음 하위 목표 결정, (4) 상식에 기반한 추론 수행 (어디서 물건을 찾고, 어떻게 사용할지 등)
We show prompts used for ALFWorld in Appendix C.4.
ALFWorld에서 사용된 프롬프트는 부록 C.4에 수록되어 있습니다.
Following Shridhar et al. (2020b), we evaluate on 134 unseen evaluation games in a task-specific setup.
Shridhar et al. (2020b)를 따라, 우리는 134개의 미사용 평가 게임을 과제별 설정에서 평가했습니다.
For robustness, we construct 6 prompts for each task type through each permutation of 2 annotated trajectories from the 3 we annotate.
강건성을 위해, 3개의 주석 경로 중 2개씩 조합하여 총 6개의 프롬프트를 생성했습니다.
Act prompts are constructed using the same trajectories, but without thoughts —
Act 프롬프트도 동일한 경로를 사용하되, 생각(thought)을 제거하여 구성했습니다.
this provides a fair and controlled comparison to test the importance of sparse thoughts.
이를 통해 희소한 생각의 중요성을 공정하고 통제된 방식으로 평가할 수 있습니다.
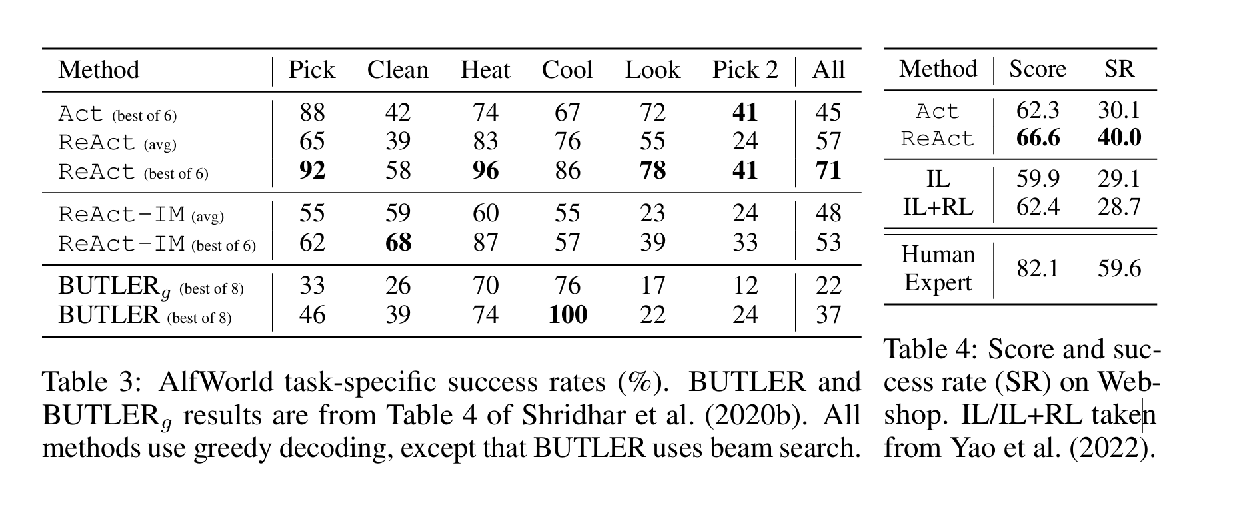
For baselines, we use BUTLER (Shridhar et al., 2020b), an imitation learning agent trained on 10⁵ expert trajectories.
비교 기준으로는 BUTLER를 사용했습니다. 이는 10만 개의 전문가 경로로 학습된 모방 학습 기반 에이전트입니다.
WebShop
Can ReAct also interact with noisy real-world language environments for practical applications?
ReAct는 실제처럼 복잡하고 잡음이 많은 언어 환경에서 실용적인 문제 해결도 가능할까요?
We investigate WebShop (Yao et al., 2022), a recently proposed online shopping website environment with 1.18M real-world products and 12k human instructions.
이를 위해 우리는 WebShop을 실험했습니다. 이 환경은 118만 개의 실제 상품과 1.2만 개의 인간 지시문이 포함된 온라인 쇼핑 시뮬레이션입니다.
Unlike ALFWorld, WebShop contains a high variety of structured and unstructured texts,
ALFWorld와 달리, WebShop은 정형 및 비정형 텍스트(상품명, 설명, 옵션 등)가 매우 다양합니다.
and requires an agent to purchase a product based on a user instruction through web interactions.
이 환경에서는 에이전트가 사용자의 자연어 지시를 기반으로 상품을 검색하고 구매해야 합니다.
e.g. “I am looking for a nightstand with drawers. It should have a nickel finish, and priced lower than $140”
예: “서랍이 있는 협탁을 찾고 있어요. 니켈 마감이어야 하고 가격은 $140 이하여야 해요.”
through web interactions (e.g. search, choose buttons, etc.)
이를 위해 모델은 웹 인터페이스에서 검색하거나 버튼을 클릭해야 합니다.
This task is evaluated by average score (percentage of desired attributes covered by the chosen product)
이 과제는 두 가지로 평가됩니다:
(1) 평균 점수: 선택된 제품이 요구 조건을 얼마나 충족하는지
and success rate (percentage of episodes where the chosen product satisfies all requirements) on 500 test instructions.
(2) 성공률: 모든 조건을 충족한 경우의 비율, 총 500개 테스트 지시문 기준입니다.
We formulate Act prompts with actions to search, choose product, choose options, and buy,
Act 프롬프트는 검색, 제품 선택, 옵션 선택, 구매 등의 행동 시퀀스 중심으로 구성됩니다.
with ReAct prompts additionally reasoning to determine what to explore, when to buy, and what product options are relevant to the instruction.
ReAct 프롬프트는 여기에 더해, 언제 탐색할지, 어떤 옵션이 지시문과 관련 있는지에 대한 추론을 포함합니다.
See Table 6 for an example prompt, and Table 10 for model predictions in the Appendix.
예시 프롬프트는 표 6, 모델 예측 결과는 부록의 표 10에 수록되어 있습니다.
We compare to an imitation learning (IL) method trained with 1,012 human annotated trajectories,
비교 대상은 1,012개의 인간 주석 경로로 학습된 모방 학습(IL) 방식과,
and a imitation + reinforcement learning (IL + RL) method additionally trained with 10,587 training instructions.
10,587개의 추가 지시문으로 학습된 모방 + 강화 학습(IL + RL) 방식입니다.
결과 (Results)
ReAct outperforms Act on both ALFWorld (Table 3) and Webshop (Table 4).
ReAct는 ALFWorld(표 3)와 WebShop(표 4) 모두에서 Act보다 우수한 성능을 기록했습니다.
ALFWorld 결과
The best ReAct trial achieves an average success rate of 71%, significantly outperforming the best Act (45%) and BUTLER (37%) trials.
ReAct의 최고 성능 실험은 71%의 평균 성공률을 기록했으며, 이는 Act(45%)와 BUTLER(37%)보다 월등히 높은 성능입니다.
Even the worse ReAct trial (48%) beats the best trial of both methods.
심지어 가장 낮은 ReAct 성능(48%)도 Act와 BUTLER의 최고 성능을 능가했습니다.
The advantage of ReAct over Act is consistent across six controlled trials,
ReAct의 우위는 6개의 통제된 실험 전반에서 일관되게 유지되었습니다.
with relative performance gain ranging from 33% to 90% and averaging 62%.
상대적 성능 향상은 33%에서 90% 사이, 평균 62%의 개선을 기록했습니다.
Without thoughts, Act fails to decompose goals or track environment state.
생각(thoughts)이 없을 경우, Act는 목표 분해에 실패하거나 현재 상태를 추적하지 못하는 경향이 있습니다.
Example trajectories comparing ReAct and Act can be found in Appendix D.2.1 and D.2.2.
ReAct와 Act의 비교 경로 예시는 부록 D.2.1과 D.2.2에 수록되어 있습니다.
WebShop 결과
One-shot Act prompting already performs on par with IL and IL+RL methods.
WebShop에서는 one-shot Act 프롬프팅만으로도 IL, IL+RL 방식과 비슷한 성능을 보였습니다.
With additional sparse reasoning, ReAct achieves significantly better performance,
그러나 희소한 추론이 추가된 ReAct는 훨씬 더 뛰어난 성능을 기록했고,
with an absolute 10% improvement over the previous best success rate.
기존 최고 성공률보다 10% 절대 향상된 결과를 보였습니다.
ReAct is more likely to identify instruction-relevant products and options,
ReAct는 지시문과 관련된 상품 및 옵션을 더 잘 식별할 수 있었습니다.
by reasoning to bridge the gap between noisy observations and actions.
이는 잡음이 있는 관측 정보와 적절한 행동 사이의 간극을 추론을 통해 메웠기 때문입니다.
e.g. “For ‘space-saving ottoman bench for living room’, the item has options ‘39x18x18inch’ and ‘blue’ and seems good to buy.”
예: “‘거실용 공간 절약형 오토만 벤치’라는 요청에 대해, 해당 제품이 ‘39x18x18인치’, ‘블루’ 옵션을 가지고 있어 구매하기 적절해 보임.”
However, existing methods are still far from the performance of expert humans (Table 4),
다만 모든 방법은 여전히 인간 전문가의 성능에는 크게 미치지 못하며 (표 4),
who perform significantly more product explorations and query re-formulations that are still challenging for prompting-based methods.
이는 사람이 훨씬 더 많은 상품 탐색과 검색어 재구성을 수행하며, 이러한 점은 프롬프트 기반 방법에겐 여전히 큰 도전입니다.
On the value of internal reasoning vs. external feedback
내부 추론과 외부 피드백의 가치에 대하여
To our knowledge, ReAct is the first demonstration of combined reasoning and action using an LLM applied to an interactive environment within a closed-loop system.
우리가 아는 한, ReAct는 폐쇄형 시스템(closed-loop system) 내의 상호작용 환경에서 LLM을 사용하여 추론과 행동을 결합한 최초의 시연 사례입니다.
Perhaps the closest prior work is Inner Monologue (IM), from Huang et al. (2022b), in which actions from an embodied agent are motivated by an eponymous “inner monologue”.
가장 유사한 기존 연구는 Huang et al. (2022b)의 Inner Monologue (IM)로, 여기서 행동은 "내면의 독백(inner monologue)"에 의해 유도됩니다.
However, IM’s “inner monologue” is limited to observations of the environment state and what needs to be completed by the agent for the goal to be satisfied.
하지만 IM의 "내면적 독백"은 환경 상태에 대한 관찰과 목표 달성을 위해 에이전트가 해야 할 작업에만 제한됩니다.
In contrast, the reasoning traces in ReAct for decision making is flexible and sparse,
반면 ReAct의 의사결정을 위한 추론 경로는 더 유연하고 희소하며,
allowing diverse reasoning types (see Section 2) to be induced for different tasks.
섹션 2에서 설명한 다양한 추론 유형들이 과제에 맞게 유도될 수 있도록 설계되어 있습니다.
To demonstrate the differences between ReAct and IM, and to highlight the importance of internal reasoning vs. simple reactions to external feedback,
ReAct와 IM의 차이를 보여주고, 내부 추론과 단순 외부 반응의 중요성을 강조하기 위해,
we ran an ablation experiment using a thought pattern composed of IM-like dense external feedback.
IM 스타일의 조밀한 외부 피드백으로 구성된 생각 패턴을 사용하여 제거 실험(ablation)을 수행했습니다.
As can be seen in Table 3, ReAct substantially outperforms IM-style prompting (ReAct-IM) (71 vs. 53 overall success rate),
표 3에서 볼 수 있듯이, ReAct는 IM 스타일 프롬프트(ReAct-IM)보다 현저히 높은 성공률(71% vs. 53%)을 기록했습니다.
with consistent advantages on five out of six tasks.
이는 6개의 과제 중 5개에서 일관된 우위를 보인 결과입니다.
Qualitatively, we observed that ReAct-IM often made mistakes in identifying when subgoals were finished, or what the next subgoal should be,
질적으로 보면, ReAct-IM은 하위 목표가 완료되었는지 또는 다음 하위 목표가 무엇인지 식별하는 데 자주 오류를 범했습니다.
due to a lack of high-level goal decomposition.
이는 고차원 목표 분해(high-level goal decomposition)가 부족했기 때문입니다.
Additionally, many ReAct-IM trajectories struggled to determine where an item would likely be within the ALFWorld environment,
또한 ReAct-IM 경로 중 다수는 ALFWorld 환경 내에서 특정 아이템이 어디에 있을지를 추론하는 데 어려움을 겪었습니다.
due to a lack of commonsense reasoning.
그 이유는 상식적 추론이 부족했기 때문입니다.
Both shortcomings can be addressed in the ReAct paradigm.
이러한 두 가지 단점은 ReAct 패러다임 내에서는 해결될 수 있습니다.
More details about ReAct-IM is in Appendix B.2.
ReAct-IM에 대한 자세한 내용은 부록 B.2에 있습니다.
An example prompt for ReAct-IM can be found in Appendix C.4, and an example trajectory in Appendix D.2.3.
ReAct-IM의 예시 프롬프트는 부록 C.4, 예시 실행 경로는 부록 D.2.3에서 확인할 수 있습니다.
5. 관련 연구 (RELATED WORK)
Reasoning을 위한 언어 모델(Language model for reasoning)
Perhaps the most well-known work of using LLMs for reasoning is Chain-of-Thought (CoT) (Wei et al., 2022),
LLM을 추론에 활용한 가장 잘 알려진 연구는 Chain-of-Thought (CoT) (Wei et al., 2022)입니다.
which reveals the ability of LLMs to formulate their own “thinking procedure” for problem solving.
이는 LLM이 문제 해결을 위한 자체적인 “사고 절차”를 구성할 수 있는 능력을 보여줍니다.
Several follow-up works have since been performed, including least-to-most prompting for solving complicated tasks (Zhou et al., 2022), zero-shot CoT (Kojima et al., 2022), and reasoning with self-consistency (Wang et al., 2022a).
이후 여러 후속 연구들이 등장했으며, 예로는 복잡한 과제를 위한 least-to-most 프롬프팅 (Zhou et al., 2022), zero-shot CoT (Kojima et al., 2022), 자기 일관성 기반 추론 (Wang et al., 2022a) 등이 있습니다.
Recently, (Madaan & Yazdanbakhsh, 2022) systematically studied the formulation and structure of CoT,
최근에는 Madaan & Yazdanbakhsh (2022)가 CoT의 구조와 형식을 체계적으로 분석하였고,
and observed that the presence of symbols, patterns and texts is crucial to the effectiveness of CoT.
기호, 패턴, 텍스트의 존재가 CoT의 효과성에 매우 중요함을 관찰했습니다.
Other work has also been extended to more sophisticated reasoning architecture beyond simple prompting.
또 다른 연구들에서는 단순한 프롬프팅을 넘어 더 정교한 추론 구조로 확장되었습니다.
For example Selection-Inference (Creswell et al., 2022) divides the reasoning process into two steps of “selection” and “inference”.
예를 들어, Selection-Inference (Creswell et al., 2022)는 추론 과정을 ‘선택’과 ‘추론’의 두 단계로 분리합니다.
STaR (Zelikman et al., 2022) bootstraps the reasoning process by finetuning the model on correct rationales generated by the model itself.
STaR (Zelikman et al., 2022)는 모델이 생성한 올바른 추론 근거에 대해 파인튜닝을 통해 부트스트래핑(bootstrap)합니다.
Faithful reasoning (Creswell & Shanahan, 2022) decomposes multi-step reasoning into three steps, each performed by a dedicated LM respectively.
Faithful reasoning (Creswell & Shanahan, 2022)는 다단계 추론을 세 단계로 분해하고, 각 단계를 전용 언어 모델이 개별 수행합니다.
Similar approaches like Scratchpad (Nye et al., 2021), which finetunes a LM on intermediate computation steps, also demonstrate improvement on multi-step computation problems.
Scratchpad (Nye et al., 2021)처럼 중간 계산 과정을 포함해 파인튜닝하는 방식도, 다단계 계산 문제에서 성능 향상을 입증했습니다.
In contrast to these methods, ReAct performs more than just isolated, fixed reasoning,
이러한 방법들과 달리, ReAct는 고정된 독립적 추론을 넘어서,
and integrates model actions and their corresponding observations into a coherent stream of inputs for the model to reason more accurately and tackle tasks beyond reasoning (e.g. interactive decision making).
행동과 관측값을 통합하여 일관된 입력 흐름을 형성, 모델이 보다 정확하게 추론하고 상호작용적 의사결정과 같은 추론을 넘는 과제까지 해결할 수 있게 합니다.
의사결정을 위한 언어 모델(Language model for decision making)
The strong capability of LLMs has enabled them to perform tasks beyond language generation,
LLM의 강력한 능력은 단순한 언어 생성 그 이상을 수행할 수 있게 만들었습니다.
and it is becoming more popular to take advantage of LLMs as a policy model for decision making, especially in interactive environments.
특히 상호작용 환경에서, LLM을 정책 모델로 활용하여 의사결정에 적용하는 시도가 점점 확산되고 있습니다.
WebGPT (Nakano et al., 2021) uses an LM to interact with web browsers, navigate through web pages, and infer answers to complicated questions from ELI5 (Fan et al., 2019).
WebGPT (Nakano et al., 2021)는 언어 모델을 사용해 웹 브라우저와 상호작용하고, 페이지를 탐색하며, ELI5 데이터셋의 복잡한 질문에 답변합니다.
In comparison to ReAct, WebGPT does not explicitly model the thinking and reasoning procedure,
하지만 ReAct와 달리, WebGPT는 사고와 추론 과정을 명시적으로 모델링하지 않으며,
instead rely on expensive human feedback for reinforcement learning.
대신 고비용의 인간 피드백을 기반으로 강화 학습을 수행합니다.
In conversation modeling, chatbots like BlenderBot (Shuster et al., 2022b) and Sparrow (Glaese et al., 2022)
대화 모델링 분야에서는 BlenderBot (Shuster et al., 2022b), Sparrow (Glaese et al., 2022) 같은 챗봇과
and task-oriented dialogue systems like SimpleTOD (Hosseini-Asl et al., 2020) also train LMs to make decision about API calls.
SimpleTOD (Hosseini-Asl et al., 2020) 같은 목적 지향형 대화 시스템도 API 호출 결정을 내리도록 언어 모델을 훈련합니다.
Unlike ReAct, they do not explicitly consider the reasoning procedure either,
하지만 ReAct와 달리, 이들 역시 추론 과정을 명시적으로 고려하지 않으며,
and also relies on expensive datasets and human feedback collections for policy learning.
고비용의 데이터셋과 인간 피드백 수집에 의존합니다.
In contrast, ReAct learns a policy in a much cheaper way,
반면 ReAct는 훨씬 저렴한 방식으로 정책을 학습합니다.
since the decision making process only requires language description of the reasoning procedure.
이는 추론 절차에 대한 언어적 설명만으로도 의사결정 과정을 학습할 수 있기 때문입니다.
LLMs have also been increasingly employed in interactive and embodied environments for planning and decision making.
LLM은 계획 수립 및 의사결정을 위한 상호작용 및 체화된 환경에서도 점점 더 많이 활용되고 있습니다.
Perhaps most relevant to ReAct in this respect are SayCan (Ahn et al., 2022) and Inner Monologue (Huang et al., 2022b),
이 측면에서 ReAct와 가장 관련 깊은 연구는 SayCan (Ahn et al., 2022)과 Inner Monologue (Huang et al., 2022b)입니다.
which use LLMs for robotic action planning and decision making.
이들은 로봇 행동 계획 및 의사결정에 LLM을 활용합니다.
In SayCan, LLMs were prompted to directly predict possible actions a robot can take,
SayCan에서는 LLM이 로봇이 수행 가능한 행동을 직접 예측하도록 프롬프트되며,
which is then reranked by an affordance model grounded on the visual environments for final prediction.
그 후 시각적 환경에 기반한 어포던스 모델이 이 행동들을 재정렬하여 최종 행동을 선택합니다.
Inner Monologue made further improvements by adding the eponymous “inner monologue",
Inner Monologue는 "내면의 독백(inner monologue)" 개념을 추가하여 더 나은 성능을 보여주었습니다.
which is implemented as injected feedback from the environment.
이는 환경으로부터 주입된 피드백으로 구현됩니다.
To our knowledge, Inner Monologue is the first work that demonstrates such a closed-loop system, which ReAct builds on.
우리가 알기로, Inner Monologue는 이러한 폐쇄형 시스템을 처음 구현한 연구이며, ReAct는 이를 기반으로 확장됩니다.
However, we argue that Inner Monologue does not truly comprise of inner thoughts — this is elaborated in Section 4.
하지만 우리는 Inner Monologue가 진정한 "내면적 사고(inner thought)"를 포함하고 있지는 않다고 주장하며, 이에 대한 설명은 섹션 4에 상세히 기술되어 있습니다.
We also note that leveraging language as semantically-rich inputs in the process of interactive decision making has been shown to be successful under other settings
우리는 또한, 상호작용 기반 의사결정 과정에서 언어를 의미적으로 풍부한 입력으로 활용하는 것이 성공적이었다는 다른 연구 결과들도 존재함을 주목합니다.
(Abramson et al., 2020; Karamcheti et al., 2021; Huang et al., 2022a; Li et al., 2022).
(Abramson et al., 2020; Karamcheti et al., 2021; Huang et al., 2022a; Li et al., 2022)
It is becoming more evident that with the help of LLMs, language as a fundamental cognitive mechanism will play a critical role in interaction and decision making.
LLM의 도움으로 인해, 언어가 근본적인 인지 메커니즘으로서 상호작용과 의사결정에 핵심적 역할을 한다는 사실이 점점 명확해지고 있습니다.
What is more, progress in LLMs has also inspired the development of versatile and generalist agents like Reed et al. (2022).
더 나아가, LLM의 발전은 Reed et al. (2022)와 같은 범용 에이전트 개발에도 영감을 주고 있습니다.
6 결론 (CONCLUSION)
We have proposed ReAct – a simple yet effective method for synergizing reasoning and acting in large language models.
우리는 대형 언어 모델(LLM)에서 추론(reasoning)과 행동(acting)을 시너지 있게 결합하는 간단하면서도 효과적인 방법인 ReAct를 제안했습니다.
Through a diverse set of experiments on multi-hop question-answering, fact checking, and interactive decision-making tasks,
다중 홉 질의응답, 사실 검증, 상호작용적 의사결정 과제에 대한 다양한 실험을 통해,
we show that ReAct leads to superior performance with interpretable decision traces.
ReAct가 해석 가능한 결정 과정을 통해 우수한 성능을 이끌어냄을 입증했습니다.
Despite the simplicity of our method, complex tasks with large action spaces require more demonstrations to learn well,
우리 방법은 단순하지만, 행동 공간이 큰 복잡한 과제에서는 더 많은 시범 사례가 학습에 필요합니다.
which unfortunately can easily go beyond the input length limit of in-context learning.
그러나 이는 in-context learning의 입력 길이 제한을 쉽게 초과할 수 있다는 단점이 있습니다.
We explore the fine-tuning approach on HotpotQA with initial promising results,
HotpotQA에서 파인튜닝 방식을 실험한 결과, 초기에는 유망한 성과를 보였습니다.
but learning from more high-quality human annotations will be the desiderata to further improve the performance.
그러나 더 많은 고품질 인간 주석 데이터로 학습하는 것이 성능 향상의 필수 요건이 될 것입니다.
Scaling up ReAct with multi-task training and combining it with complementary paradigms like reinforcement learning
ReAct를 멀티태스크 학습으로 확장하고, 강화학습과 같은 보완적 패러다임과 결합한다면,
could result in stronger agents that further unlock the potential of LLMs for more applications.
더 강력한 에이전트를 만들어 LLM의 가능성을 다양한 응용 분야로 확장할 수 있을 것입니다.
감사의 말 (ACKNOWLEDGMENTS)
We thank the support and feedback of many people from Google Brain team and Princeton NLP Group.
우리는 Google Brain 팀과 Princeton NLP 그룹의 많은 분들로부터 받은 지원과 피드백에 감사드립니다.
This work was supported in part by the National Science Foundation under Grant No. 2107048.
이 연구는 미국 국립과학재단(NSF) 지원 하에 수행되었으며, 과제 번호는 2107048입니다.
Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s)
이 자료에 나타난 의견, 연구 결과, 결론, 추천 등은 모두 저자들의 견해이며,
and do not necessarily reflect the views of the National Science Foundation.
국립과학재단의 입장을 반드시 대변하는 것은 아닙니다.
재현 가능성 관련 안내 (REPRODUCIBILITY STATEMENT)
Our main experiments are done on PaLM (Chowdhery et al., 2022), which is not an openly accessible model yet.
우리의 주요 실험은 아직 공개되지 않은 모델인 PaLM (Chowdhery et al., 2022)을 기반으로 수행되었습니다.
To increase reproducibility, we have included all used prompts in Appendix C,
재현성을 높이기 위해, 본 논문에서는 사용된 모든 프롬프트를 부록 C에 포함시켰습니다.
additional experiments using GPT-3 (Brown et al., 2020) in Appendix A.1,
또한 GPT-3 (Brown et al., 2020)를 활용한 추가 실험은 부록 A.1에 제공됩니다.
and associated GPT-3 ReAct prompting code at https://anonymous.4open.science/r/ReAct-2268/.
그리고 GPT-3 기반 ReAct 프롬프트 코드는 여기에 있습니다.
윤리 성명 (ETHICS STATEMENT)
ReAct prompts large language models to generate more human interpretable, diagnosable, and controllable task-solving trajectories than previous methods.
ReAct는 기존 방법보다 더 해석 가능하고, 진단 가능하며, 제어 가능한 작업 수행 경로를 생성하도록 LLM을 유도합니다.
However, hooking up a large language model with an action space to interact with external environments (e.g. the web, physical environments) has potential dangers,
하지만 LLM을 외부 환경(예: 웹, 물리적 환경)과 상호작용하는 행동 공간과 연결하는 것은 잠재적인 위험을 동반합니다.
e.g. looking up inappropriate or private information, or taking harmful actions in an environment.
예를 들어, 부적절하거나 개인적인 정보를 검색하거나, 환경 내에서 해로운 행동을 취할 수 있는 가능성이 있습니다.
Our experiments minimize such risks by limiting the interactions to specific websites (Wikipedia or WebShop)
우리의 실험은 이러한 위험을 줄이기 위해, 상호작용을 Wikipedia나 WebShop 같은 특정 웹사이트로 제한했습니다.
that are free of private information, without any dangerous actions in the action space design
이들 웹사이트는 개인 정보를 포함하지 않으며, 행동 공간 설계상 위험한 행동도 불가능합니다.
(i.e. models cannot really buy products on WebShop the research benchmark, or edit Wikipedia).
예를 들어, 모델은 실제로 WebShop에서 제품을 구매하거나 Wikipedia를 편집할 수 없습니다.
We believe researchers should be aware of such risks before designing more extensive experiments in the future.
우리는 연구자들이 앞으로 더 확장된 실험을 설계하기 전에 이러한 위험 요소를 충분히 인식해야 한다고 믿습니다.
