Elasticsearch
Elasticsearch 란
- Apache Lucene 기반의 Java 오픈소스 분산 검색 엔진
- Lucene 라이브러리를 단독으로 사용 가능
- 방대한 양의 데이터를 신속하게 거의 실시간으로 저장, 검색, 분석 가능
ELK 스택
ElasticSearch는 검색을 위해 단독으로 사용되기도 하며, ELK (ElasticSearch / Logstash / Kibana) 스택으로 사용됨
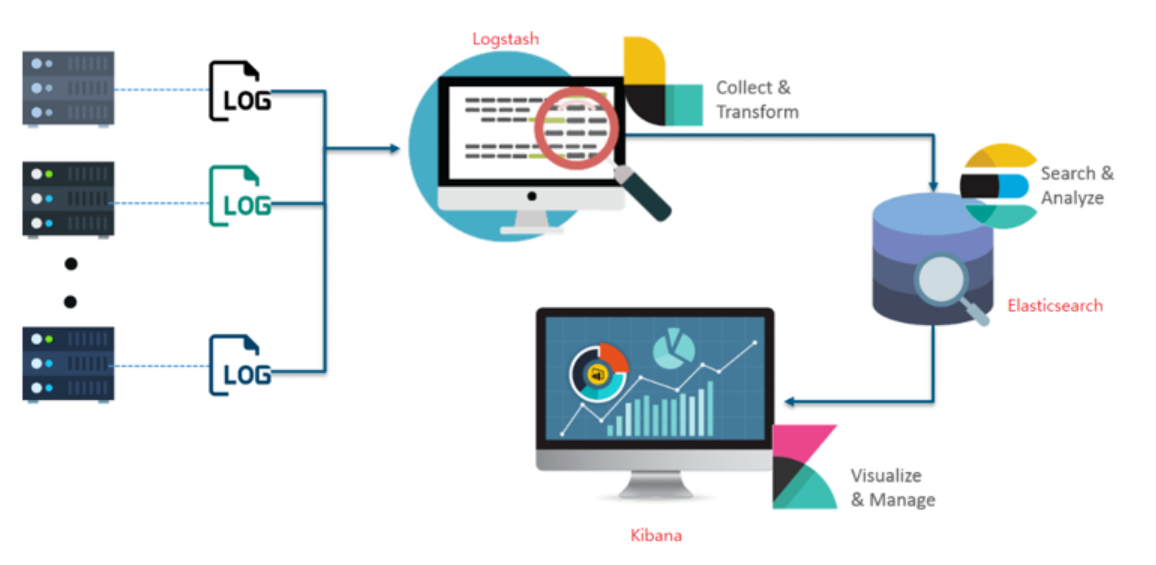
- Logstash
- 다양한 소스(DB, csv파일 등)의 로그 또는 트랜잭션 데이터를 수집, 집계, 파싱하여 ElasticSearch로 전달
- Elasticsearch
- Logstash로부터 받은 데이터를 검색 및 집계를 하여 관심 있는 필요한 정보를 획득
- Kibana
- ElasticSearch의 빠른 검색을 통해 데이터를 시각화 및 모니터링
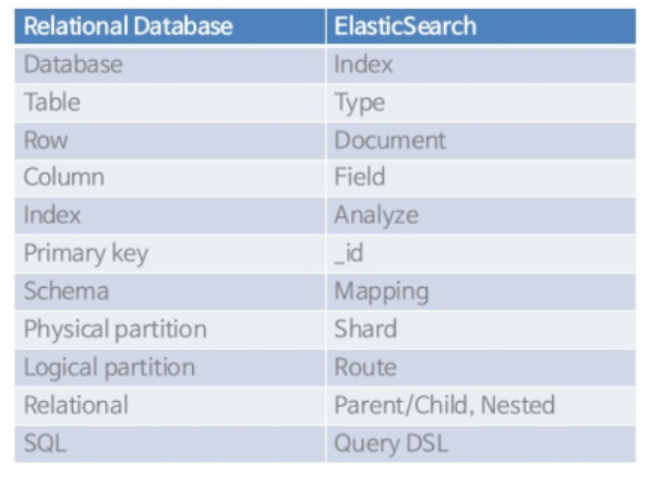
Elasticsearch vs. RDBMS
- RDBMS의 개념은 ElasticSearch에서 다음과 같음

- 차이점
Elasticsearch 구조
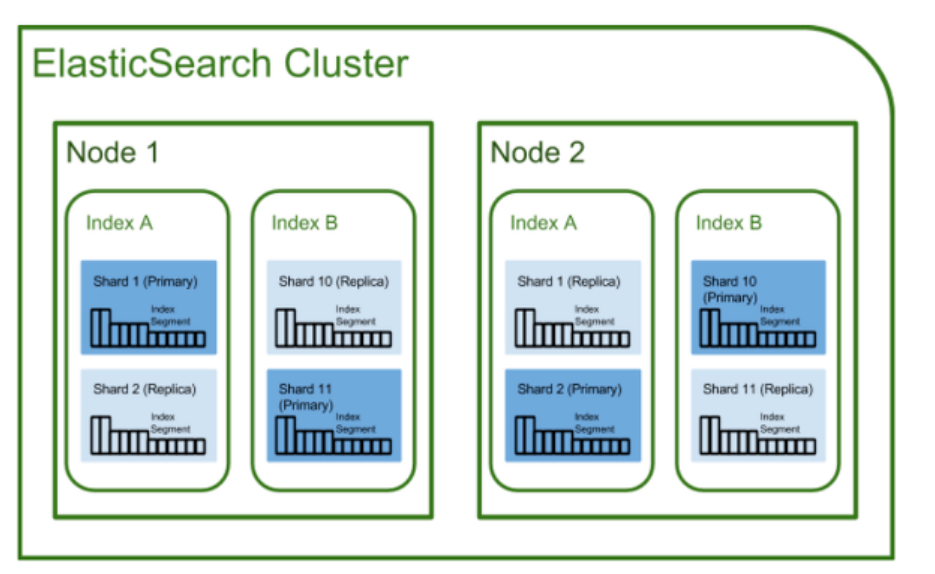
- 클러스터 (cluster)
- 가장 큰 시스템 단위를 의미, 최소 하나 이상의 노드로 이루어진 노드들의 집합
- 서로 다른 클러스터는 데이터의 접근, 교환을 할 수 없는 독립적인 시스템
- 여러 대의 서버가 하나의 클러스터를 구성할 수 있고, 한 서버에 여러 개의 클러스터가 존재할 수도 있음
- 노드 (node)
- 하나의 단위 프로세스
- 역할에 따라 Master-eligible, Data, Ingest, Tribe 노드
- Master-eligible node
- 클러스터를 제어하는 마스터로 선택할 수 있는 노드
- 인덱스 생성, 삭제
- 클러스터 노드들의 추적, 관리
- 데이터 입력 시 어느 샤드에 할당할 것인지
- 클러스터를 제어하는 마스터로 선택할 수 있는 노드
- Data node
- 데이터와 관련된 CRUD 작업과 관련된 노드
- CPU, 메모리 등 자원을 많이 소모하므로 모니터링이 필요
- master 노드와 분리되는 것이 좋음
- Ingest node
- 데이터를 변환하는 등 사전 처리 파이프라인을 실행
- Tribe node
- 서로 다른 클러스터로 구성된 ElasticSearch의 데이터에 대해 질의, 색인이 가능 (RDBMS의 view와 비슷)
- Coordination only node
- 로드밸런서 역할
- Master-eligible node
- 인덱스 (index)
- RDBMS의 Database와 비슷
- 샤드 (Shard)
- 샤딩 (sharding)
- 데이터를 분산해서 저장하는 방법
- 스케일 아웃을 위해 index를 여러 shard로 쪼갠 것
- 기본적으로 1개가 존재하며, 검색 성능 향상을 위해 클러스터의 샤드 갯수를 조정하는 튜닝을 하기도 함
- 인덱스가 샤드로 분할 (분산 및 확장을 위해)
- 샤딩 (sharding)
- 복제 (Replica)
- 또 다른 형태의 샤드 (복제본)
- 노드를 손실했을 경우 데이터의 신뢰성을 위해 샤드들을 복제
- 서로 다른 노드에 존재할 것을 권장함
Elasticsearch 특징
- Scale out
- 샤드를 통해 규모가 수평적으로 늘어날 수 있음
- 고가용성
- Replica를 통해 데이터의 안정성을 보장
- Schema Free
- JSON 문서를 통해 데이터 검색을 수행하므로 스키마 개념이 없음
- RESTful
- 데이터 CRUD 작업은 HTTP RESTful API를 통해 수행함
Database CRUD Elasticsearch RESTful SELECT GET INSERT PUT UPDATE POST DELETE DELETE
- 데이터 CRUD 작업은 HTTP RESTful API를 통해 수행함
Elasticsearch 데이터 조회
search API
- search API는 아래와 같이 모든 document를 검색할 수 있음
curl -XGET 'localhost:9100/_all/_search?banana'
all 지정자를 사용하면 클러스터에 있는 모든 인덱스를 대상으로 검색이 가능하지만, 불필요한 작업 부하를 초래하므로, all 지정자 대신 index를 지정하여 조회하는걸 지향
- search 키워드는 검색 작업을 하겠다는 것이고, 어떻게 검색을 할 것인지에 대한 조건(쿼리)들을 명시를 해줘야 원하는 정보를 얻을 수 있음
- Elasticsearch는 여러 개의 인덱스를 한꺼번에 묶어서 검색할 수 있는 멀티테넌시(Multitenancy)를 지원함
#쉼표로 나열해서 여러 인덱스 검색
[GET] logs-2018-01,2018-02,2018-03/_search
#와일드 카드 * 를 이용해서 여러 인덱스 검색
[GET] logs-2018-*/_search- search api 조건 전달 방법
- URL에 파라미터를 넘기는 방법(URI Search)
- json 파일에 쿼리를 작성하여 POST 방식으로 넘기는 방법(QueryDSL)
- URL이 깔끔해지고, 더 상세한 표현이 가능할 뿐더러 재사용이 가능하기 때문에 더 많이 사용함
URI Search
- 모든 검색 옵션을 노출하지 않지만, 빠른 curl 테스트에 유용한 방법
curl -XGET 'localhost:9100/_all/_search?banana'
- 파라미터 q는 쿼리 스트링으로 Query string query로 변환됨
Search API Response 분석
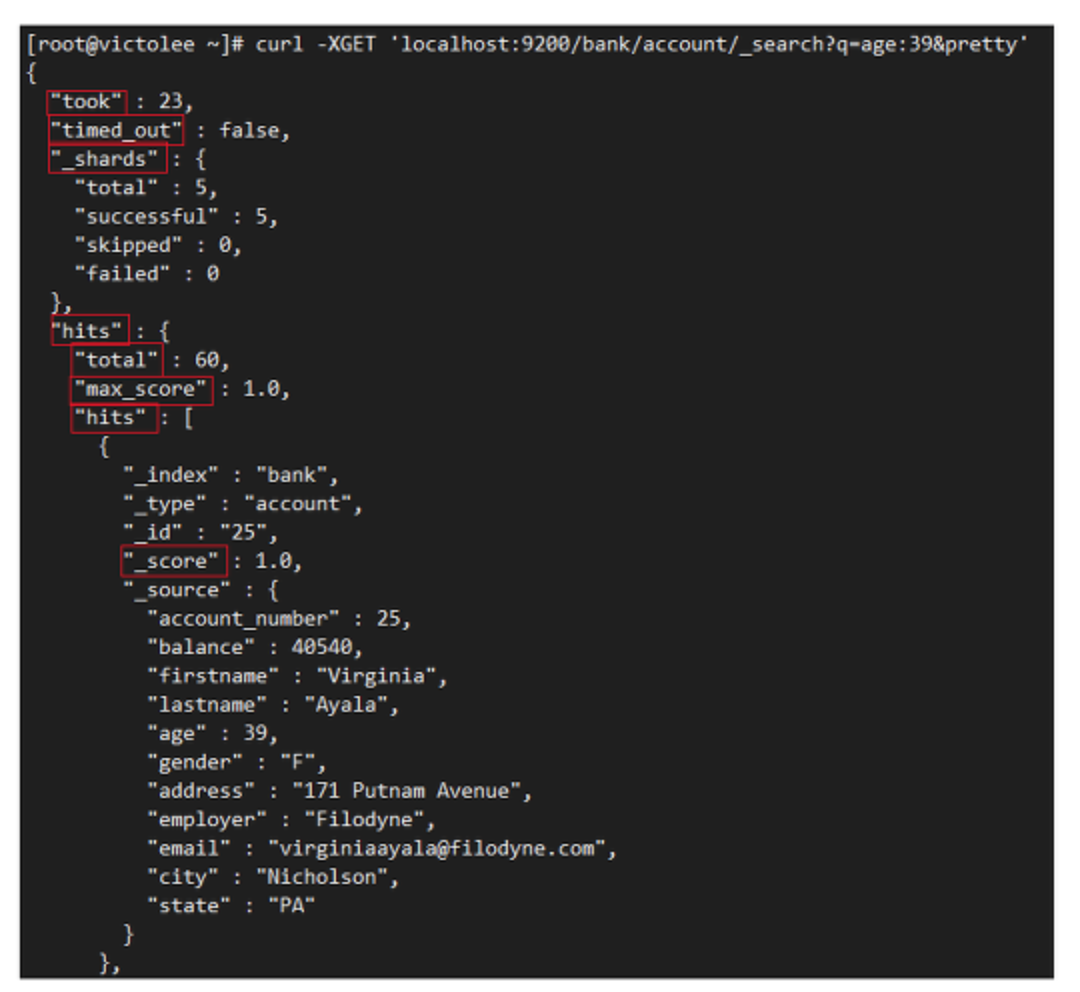
response의 각 의미
- took: 검색하는데 걸린 시간( 단위 : ms )
- timed_out: 검색시 시간 초과 여부
- _shards: 검색한 shard 수 및 검색에 성공 또는 실패한 shard의 수
- hits: 검색 결과
- total: 검색 조건과 일치하는 문서의 총 개수
- max_score: 검색 조건과 결과 일치 수준의 최댓값
- hits: 검색 결과에 해당하는 실제 데이터 ( 기본 값으로 10개가 설정되며, size를 통해 조절 가능 )
- _score: 해당 document가 지정된 검색 쿼리와 얼마나 일치하는지를 상대적으로 나타내는 숫자 값이며, 높을 수록 관련성이 높음
- sort: 결과 정렬 방식을 말하며, 기본 정렬 순서는 _score를 기준으로 내림차순(desc)이고, 다른 항목은 기본적으로 오름차순(asc)으로 정렬함(_score 기준일 경우 노출되지 않음)
QueryDSL
- json 포맷으로 쿼리를 만들어서 검색을 함
- Query Context, Filter Context(참고)
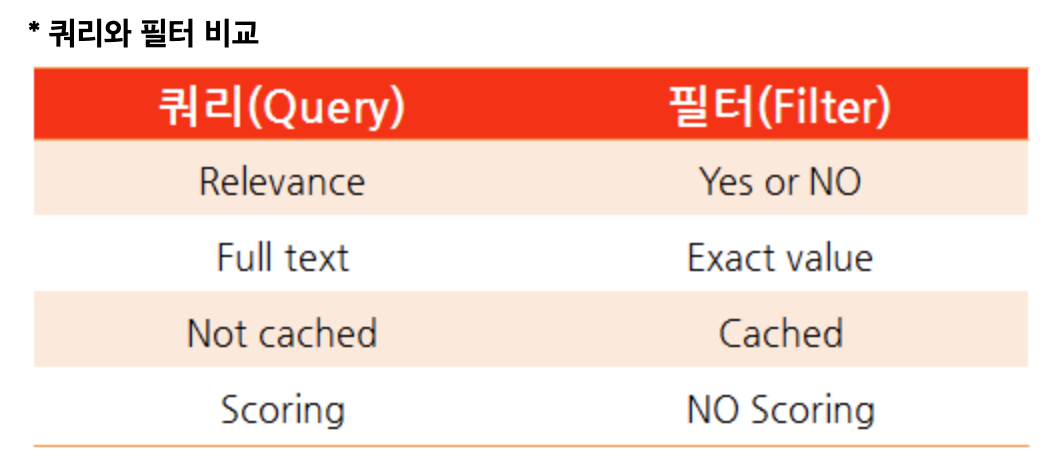
Filter Context
- Filter Context에서 사용되는 query 절은 ‘
해당 document가 query절과 일치하는가?’ 라는 질문에 해당하는데, 그 대답은 true 또는 false이며 점수(score)는 계산하지 않음 - Filter Context는 캐싱(caching)을 사용할 수 있으며, Query Context는 캐싱을 사용할 수 없음
캐싱된 결과
//Shard Request Cache
//size = 0 인 request 결과만 cache (aggregation, suggestions 등)
//https://www.elastic.co/guide/en/elasticsearch/reference/current/shard-request-cache.html
[GET] /_nodes/stats/indices/request_cache?human
//Node Query Cache
//https://www.elastic.co/guide/en/elasticsearch/reference/current/query-cache.html
//Filter Context를 사용했을 경우에만 동작
[GET] /_nodes/stats/indices/query_cache?humanQuery Context
- Query Context에서 사용되는 query 절은 ‘
해당 document가 query 절과 얼마나 잘 일치하는가?’ 라는 질문에 해당하는데, document가 얼마나 잘 일치하는지를 _score(관련성 점수, relevance score)로 표현함 - RDBMS 같은 시스템에서는 쿼리 조건에 부합하는 지만 판단하여 결과를 가져올 뿐 각 결과들이 얼마나 정확한지에 대한 판단은 보통 불가능함
- ES 와 같은 풀 텍스트 검색엔진은 검색 결과와 입력된 검색 조건과 얼마나 일치하는 지를 계산하는 알고리즘을 가지고 있어 이 정확도(relevancy)를 기반으로 사용자가 가장 원하는 결과를 먼저 보여줄 수 있음
- ES의 검색 결과에는 스코어 점수가 표시가 된다. 이 점수는 검색된 결과가 얼마나 검색 조건과 일치하는지를 나타내며 점수가 높은 순으로 결과를 보여줌
Query Context 검색
match_all
match_all쿼리는 지정된 index의 모든 document를 검색하는 방법- 특별한 검색어 없이 모든 document를 가져오고 싶을 때 사용함
- SQL로 치면 WHERE 절이 없는 SELECT문과 같음
match_none
- 모든 document를 가져오고 싶지 않을 때 사용함
[GET] my_index/_search { "query":{ "match_all":{} } }
match
match쿼리는 풀 텍스트 검색에 사용되는 가장 일반적인 쿼리임- 텍스트/숫자/날짜를 허용함
- address에 rlatkd이라는 용어가 있는 모든 document를 조회하는 예제
{ "query":{ "match":{ "address":"rlatkd" } } } - match 검색에 여러 개의 검색어를 집어넣게 되면 디폴트로 OR 조건으로 검색이 되어 입력된 검색어 별로 하나라도 포함된 모든 문서를 모두 검색함
-
검색어로 ‘rlatkd banana’을 주었을 때 ‘rlatkd’과 ‘banana’ 단어 하나라도 포함한 document를 모두 포함함
"match":{ "address":"rlatkd banana" }
-
- 검색어가 여럿일 때 검색 조건을 OR가 아닌 AND로 바꾸려면 operator 옵션을 사용할 수 있음
-
‘rlatkd banana’ 모두 있는 document만 검색
"query": { "match": { "address": { "query" :"rlatkd banana", "operator": "and" } } }
-
match_phase
match_phrase쿼리는 입력된 검색어를 순서까지 고려하여 검색을 수행함"query": { "match_phrase": { "address": "rlatkd banana" } }- match_phrase 쿼리는 slop 이라는 옵션을 이용하여 slop에 지정된 값 만큼 단어 사이에 다른 검색어가 끼어드는 것을 허용할 수 있음
"query": { "match_phrase": { "address": { "query": "288 banana", "slop": 1 } } }
match_phrase 쿼리와 slop을 이용하면 정확도를 조절 해 가며 원하는 검색 결과의 범위를 넓힐 수 있음
slop을 너무 크게 하면 검색 범위가 넓어져 관련이 없는 결과가 나타날 확률도 높아지기 때문에 1이상은 사용하지 않는 것을 권장함
