
0. 개요
이번에 연구실에서 내 주도의 새로운 프로젝트를 진행하게 되었다.
해당 프로젝트를 수행하기 위해서는 이미지 또는 영상에서 realtime으로 이미지 객체를 식별할 수 있는 딥러닝 모델이 필요했는데, 기존의 YOLO 모델처럼 바운딩 박스를 구하는 것 뿐만이 아닌 object 모양 그대로의 좌표를 가져올 수 있는 방법을 찾게 되었다.
그리고 이를 현재 최신 버전인 YOLOv5 7.0 version에서 Segmentation Model로 제공하는 것을 확인하였다.
기존의 YOLOv5처럼 labelIMG툴로 네모난 bounding box를 그리던 것과는 달리, Segmentation은 정확한 사물의 모양 학습이 필요하기 때문에 마치 포토샵의 다각형 올가미 도구를 사용하는 것처럼 labeling을 진행하여야 한다.
YOLOv5 공식 깃허브에서 roboflow를 활용하여 Segmentation을 진행할 수 있는 방법을 소개하고 있었고, 해당 게시글을 토대로 labeling 및 train을 진행하였다.
아래 링크는 YOLOv5 공식 깃허브 주소 및 roboflow 훈련 안내 깃허브이다.
YOLOv5 Github
YOLOv5-seg-tutorial
1. YOLOv5 설치
개발환경 : Ubuntu 20.04 LTS
YOLOv5는 가장 최근에 release된 7.0버전부터 Segmentation을 지원한다. 기존에 YOLOv5를 쓰고 있다면 업그레이드해야 한다.
$ git clone https://github.com/ultralytics/yolov5
$ cd yolov5
$ pip install -qr requirements.txt기존 YOLOv5 모델은 yolov5s.pt, yolov5s.yaml로 pretrained model이 제공되었다면, Segmentation이 가능한 모델은 yolov5s-seg.pt등의 이름으로 제공되고 있다.
위에 링크한 YOLOv5 공식 깃허브 링크에서 해당 모델 파일을 다운받을 수 있다. 성능에 따라 n, s, m, l, x로 제공되며, 성능이 늘어날수록 object detect 시간이 길어진다. 이는 webcam 등의 카메라를 사용하는 영상에서의 detecting에서 큰 단점이 될 수 있어 적절한 모델 선택이 필요하다.
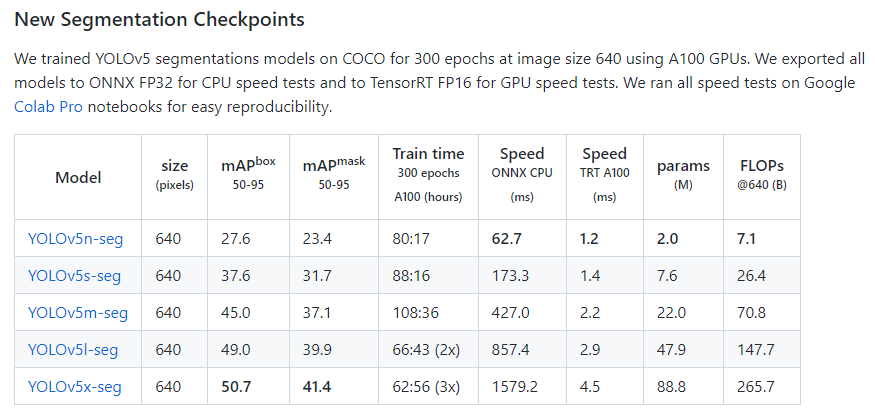
해당 모델을 다운받아 리눅스의 yolov5 폴더에 넣어주면 훈련 준비가 끝난다.
2. 훈련 데이터 생성
YOLOv5 Segmentation tutorial에 소개된 roboflow를 이용한다.
https://roboflow.com/
계정을 생성하고 Workspace를 추가하면 훈련 데이터를 생성할 수 있는 프로젝트를 만들 수 있다.
Workspace를 생성할 때, Public인지 Private인지 선택할 수 있는데, Private로 하면 나중에 훈련 데이터의 export가 되지 않아 Public으로 설정해야 한다.
Project type는 Instance Segmentation으로 설정한다.
Project Name과 Detecting 항목을 설정할 수 있는데, 두번째 란인 Detecting 항목 이름은 앞으로 우리가 Segmentation할 label 이름이 된다.
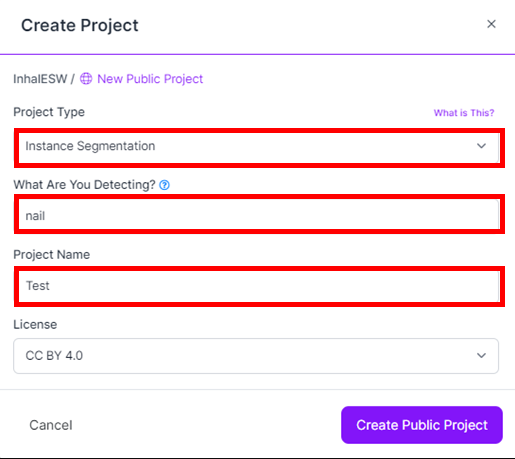
프로젝트를 생성하고 나면 아래와 같이 Projects의 초기 화면이 출력된다.
여기서 우리는 훈련 데이터를 준비한 뒤, 중앙의 Select Files 또는 Folder를 선택한다.
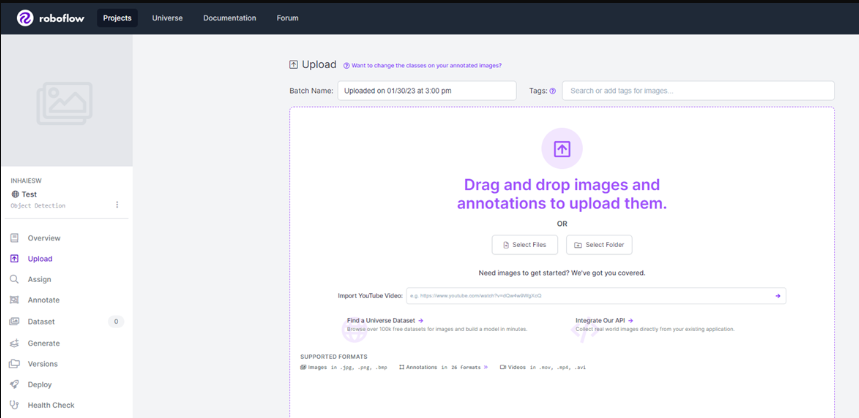
나는 예시로 사람의 손톱을 검출하기 위하여 손 사진을 업로드했다.
해당 이미지를 Segmentation하기 위하여 Annotate 탭을 누르거나, 사진을 더블클릭한다.
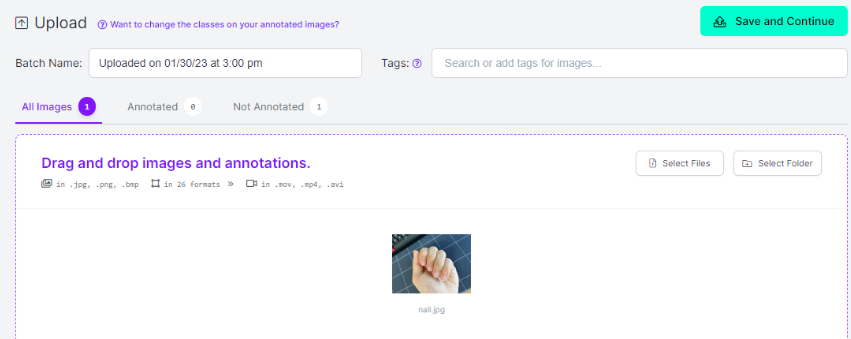
더블클릭하면 이러한 창이 나타난다.
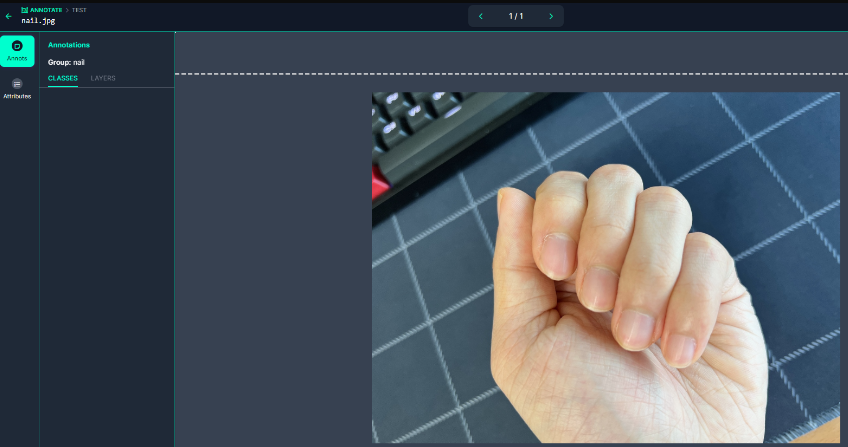
우측에 객체를 선택하기 위한 여러 도구들이 있는데, Polygon tool, Smart Polygon 중 하나를 선택하여 객체를 선택하면 된다. 다각형을 만들면 label name을 설정하고 저장하면 된다.

모든 Segmentation을 진행하면, 다음 장으로 넘어가거나 esc를 눌러 원래의 화면으로 돌아가면 된다.

이후 save and continue 버튼을 클릭하면 아래와 같은 선택창이 나타난다. Training Set ONLY로 진행하는지, 또는 Validation Set과 Test Set을 만드는지 선택할 수 있다.
만약 valid set, test set으로 나누지 않는다면 모델을 훈련할 때 진행에 문제가 생기므로 가급적 나누기를 추천한다.
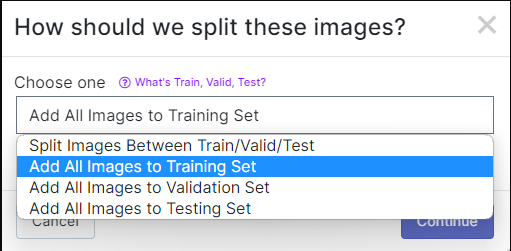
이후 아래와 같은 창에서 이미지 크기나 사진 효과를 선택하고 training set을 만들 수 있다.
만약 Validation, Test set로 나누었다면 여기에 비율을 조정하는 바가 추가된다.
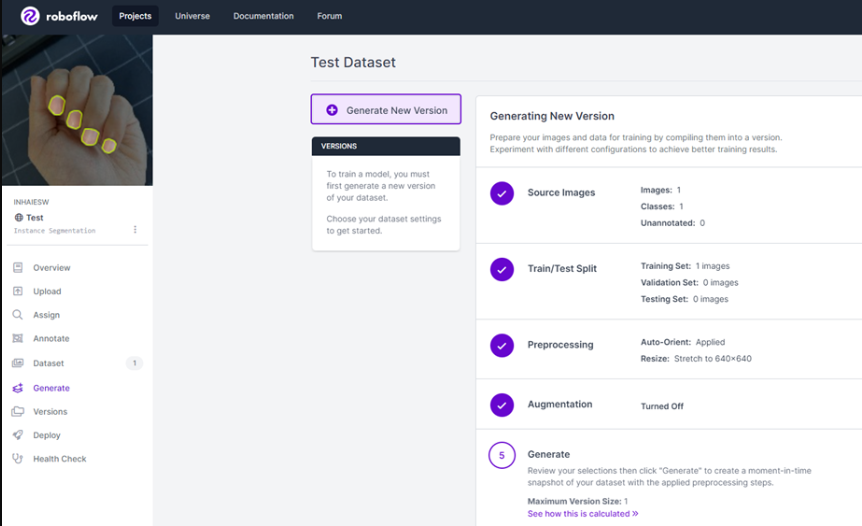
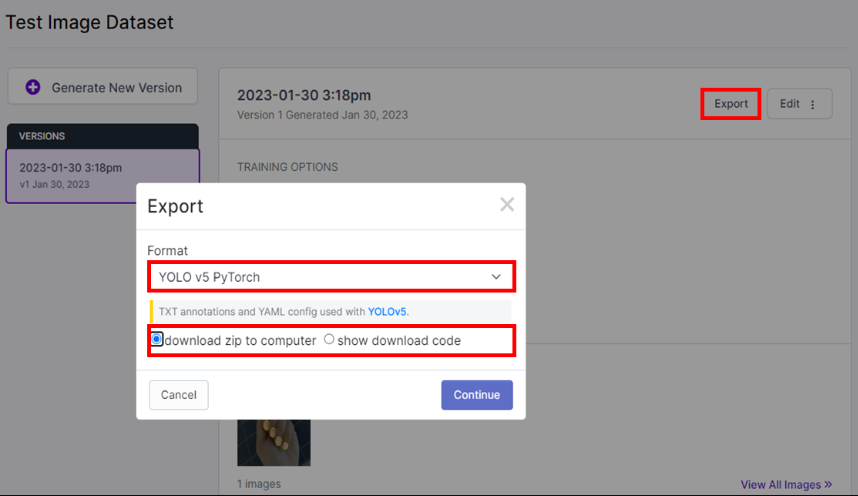
모든 과정을 마치고 Export를 버튼을 눌러 데이터 세트를 저장할 수 있다.
Format은 YOLOv5 Pytorch를 선택하고, zip 파일로 다운로드한다.
download code를 선택하면 api key를 받을 수 있는데, 현재는 리눅스에서 직접 훈련 데이터를 구축할 것이기 때문에 zip 파일로 다운로드를 선택하였다.
필자는 이 폴더의 이름을 dataset으로 지정하였다.
3. Yolov5-seg 훈련 및 예측
파일을 옮기기에 앞서, 현재 필자의 리눅스 서버는 가상머신이 아닌 원격서버로, Filezilla라는 sftp 프로그램을 이용하여 파일을 옮긴다. 만약 가상머신을 사용한다면 공유폴더 사용 등 다른 방법을 사용해야 한다.
앞서 다운받은 yolov5s-seg.pt와 다운받은 dataset을 리눅스 서버로 옮긴다.
현재 리눅스 내 yolov5 폴더의 구조는 이렇다.

만약 위에서 train과 valid, test set을 split했다면 위 폴더처럼 dataset이 생성되지만, 그렇지 않다면 val폴더와 test 폴더가 생성되지 않는다. 해당 폴더가 없다면 모델을 train할 때 에러가 생기므로, 가급적 training data를 split해야한다.
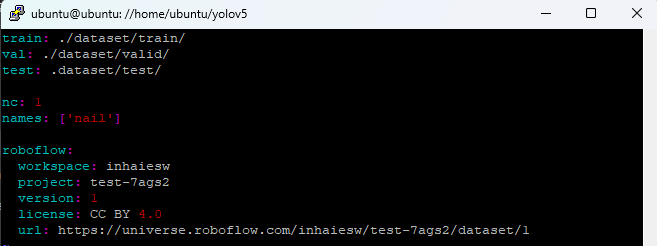
yolov5/dataset/data.yaml 파일도 수정해야 한다. 데이터셋의 경로에 맞게 파일을 아래와 같이 수정해준다. vim 등을 사용하여 리눅스에서 수정해도 되고, 텍스트 편집기의 사용이 어렵다면 윈도우 상에서 파일을 수정해도 된다.
$ vim ./dataset/data.yaml
train: ./dataset/train/
val: ./dataset/valid/
test: .dataset/test/
이제 훈련 데이터의 준비는 끝났다. 준비된 segment 모델을 통해 해당 모델을 훈련할 수 있다.
--batch-size --img 등의 하이퍼파라미터 또한 설정할 수 있다.
훈련이 끝나면 runs/train-seg/exp 폴더에 훈련된 모델, 결과가 저장된다.
$ python ./segment/train.py --data ./dataset/data.yaml --batch-size 16 --weights "./yolov5s-seg.pt" --epoch 3훈련된 모델로 예측도 가능하다. 이전에 만든 테스트세트로 predict를 진행해도 되고, 별도의 폴더에 파일을 옮겨서 다른 이미지 또는 영상을 source로 사용할 수 있다.
$ python segment/predict.py --weights runs/train-seg/exp/weights/best.pt --source dataset/test/ --img 640 --save-txt--save-txt 옵션을 인자로 넣으면 예측된 segmentation의 좌표가 txt파일로 저장된다.
4. 마무리
여기까지 YOLOv5 Segmentation을 알아보았다. Object Detection을 가능하게 하는 우수한 모델 중 하나인 YOLO에서 Segmentation을 지원하면서 연구개발을 하며 필요한 자원과 시간이 크게 줄어들었다고 느낀다. 특히, 오브젝트의 좌표값을 얻어올 수 있게 되어 다양한 방식으로 연구를 수행할 수 있게 되었다.
yolov5 폴더 내부의 predict.py 등 몇 파일을 수정하여 예측된 이미지를 다양하게 가공할 수 있는데, 이는 따로 게시글로 정리할 생각이다.

손톱 너무 귀여우세요💅 앞으로도 민우님의 벨로그 기대할게요!