- 인덱스
- 단일 수준 인덱스
- 복합레벨 인덱스
- 단일레벨 정렬 인덱스
- 클러스터링 인덱스
ㄴ 중복값이 나오는 인덱스 - Secondary index
- 클러스터링 인덱스
- primary index
- 키값과 키값이 저장되있는 주소 쌍으로 저장됨
- 각각 대표하는 하나의 레코드를 anchor record 또는 block record라고 함
- primary Index
- 희소 인덱스
- <-> dense index
- 갱신이 가장 큰 문제, 인덱스에 의한 문제
- 순차파일에서 썼던 overflow 방법을 사용
- clustering indexes
- 정렬키가 nonkey field, 유일값이 아님
- 블록당 같은레코드만 저장하는법, 초과 시 링크를 이용해서 오버플로우 블록 연결
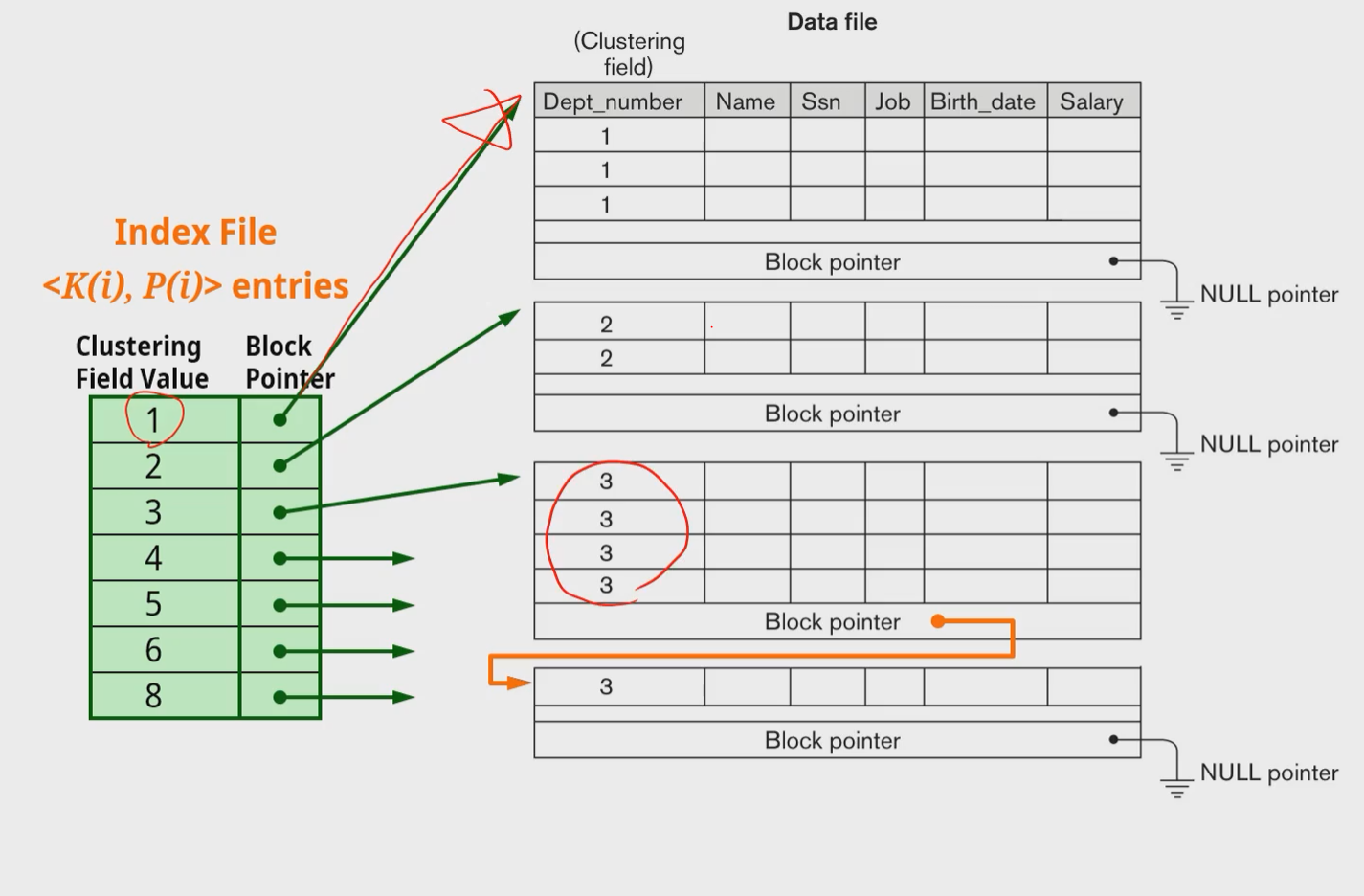
- Secondary Indexes
- dense index
- 정렬되어 있지않음, 섞여있음 ( primary 값이 정렬되어있음)
- multilevel index
- fan out : 몇개로 나뉘어지는지
- B-Tree
- 항상 균형잡힌 트리를 유지하는 트리이다.
- 모든 리프는 같은 레벨
- 루트의 서브트리수 >2
- 한 노드 내의 키 값은 오름차순으로 정렬
- Search Tress
- 탐색을 위한 트리
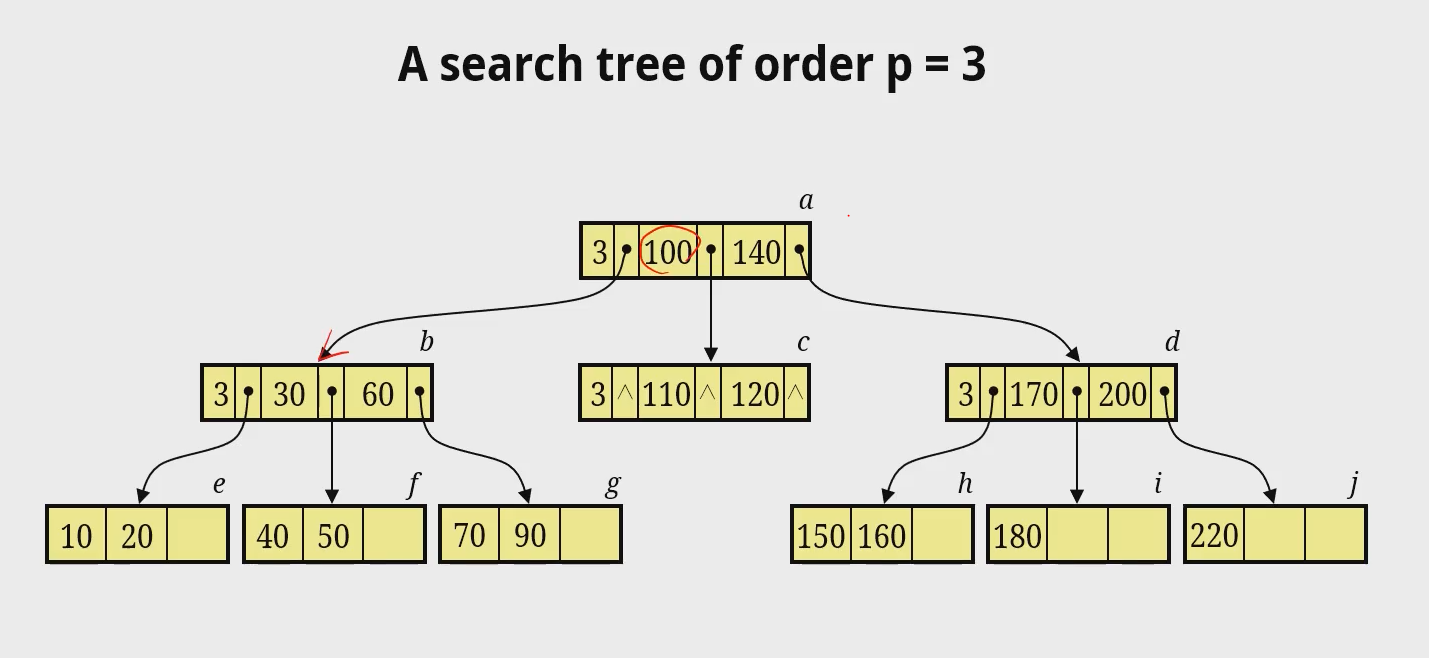
- 탐색을 위한 트리
- B트리의 연산
- 직접탐색 : 키값에 의존한 분기
- 순차탐색 : 중위 순회
- 삽입,삭제 : 트리의 균형 유지
-분할 : 높이 증가
-합병 : 높이 감소
-삭제 : 리프노드에서 삭제
- B+Tree
- B- Tree 의 변형
- 모든 데이터들은 리프데이터에 저장되어있음
- 리프노드의 단말노드들은 순차탐색을 위해 연결리스트로 연결되어있다.
- 구조
-인덱스 세트 : 내부노드, 리프에 있는 키에대한 경로정보만 제공
-순차세트 : 리프노드, 모든 키 값들을 포함 - 루트의 서브트리 : 0,2, [p/2]~p
- B+Tree의 연산
- 탐색 : 리프에서 검색
- 삽입 : 오버플로우시 분열, 부모노드, 분열 노드 모두에 키 값 존재
- 삭제 : 리프에서만 삭제
-합병 : 인덱스의 키 값도 삭제
-재분배 : 트리 구조 유지

백엔드 & 전공 공부