
- 빅데이터 처리를 위한 아파치 Kafka 등장배경
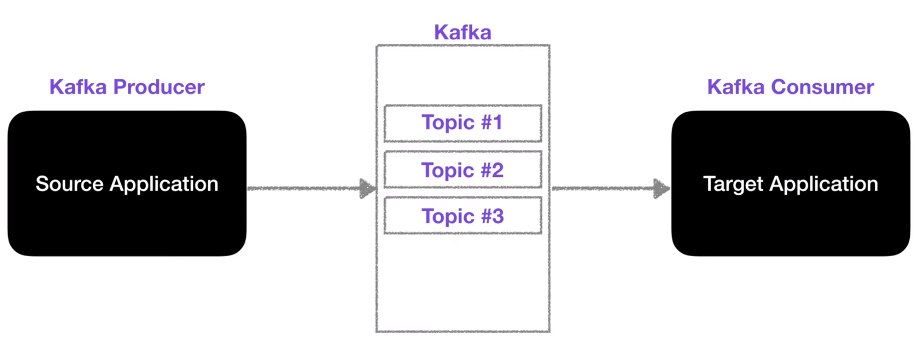
● 데이터를 전송하는 소스 Application → 데이터를 전송받는 Target Application
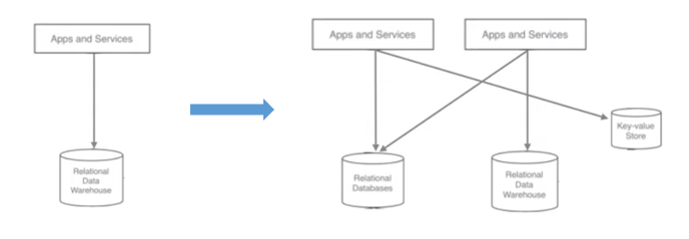
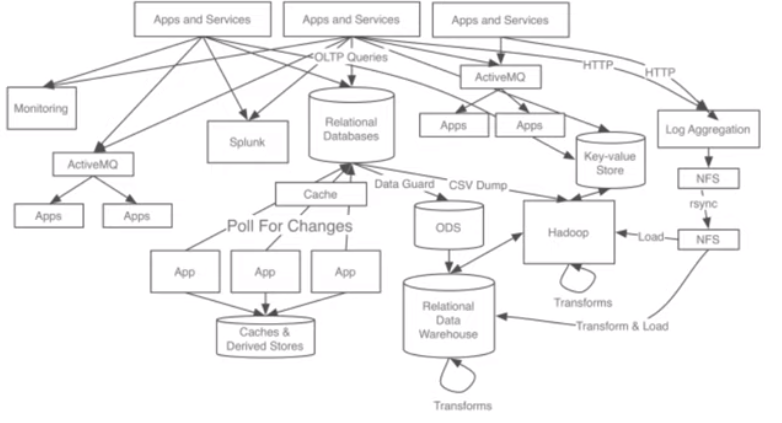
● 복잡해지는 아키텍처
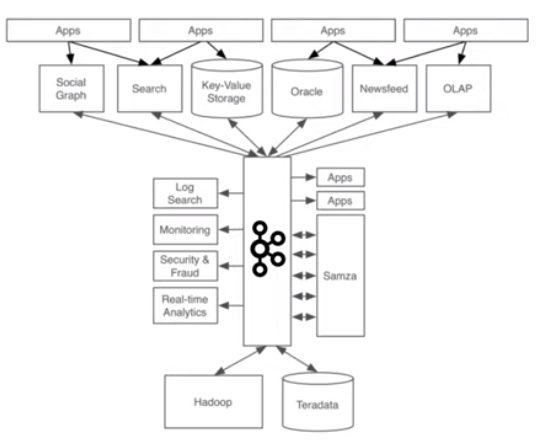
● 이를 해결해기위해 나온것이 - Apache Kafka
● kafka 메시지 처리

● kafka 메시지 처리
● Apache Kafka
LinkedIn에서 최초로 만들고 opensource화 한 확장성이 뛰어난 분산 메시지 큐(FIFO : First In First Out)
→ 분산 아키텍쳐 구성, Fault-tolerance한 architecture(with zookeeper), 데이터 유실 방지를 위한 구성이 잘되어 있음
→ AMQP, JMS API를 사용하지 않은 TCP기반 프로토콜 사용
→ Pub / Sub 메시징 모델을 채용
→ 읽기 / 쓰기 성능을 중시
→ Producer가 Batch형태로 broker로 메시지 전송이 가능하여 속도 개선
→ 파일 시스템에 메시지를 저장하므로, 데이터의 영속성 보장
→ Consume된 메시지를 곧바로 삭제하지 않고 offset을 통한 consumer-group별 개별 consume가능
- 데이터가 저장되는 토픽
● 토픽: 데이터가 들어가는 공간
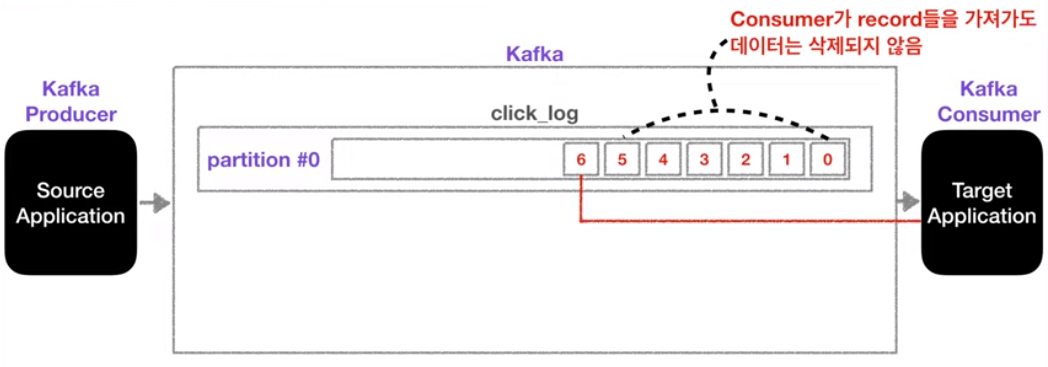
● partition의 record가 (일정기간)삭제되지 않음
● partition의 record 생명주기
→ log.retention.ms: 최대 record 보존 시간
→ log.retention.byte: 최대 record 보존 크기(byte)
● 이에 목적에 따라 동일한 데이터를 활용할 수 있다 (Elastic Search, Hadoop)
● partition과 consumer를 늘려 병렬처리를 할 수 있다.
- 데이터를 분석하고 시각화하기 위해 엘라스틱서치에 저장
- 데이터 백업을 위해 하둡에 저장

- 데이터를 카프카로 전송하는 프로듀서
● 카프카 프로듀서: 데이터를 토픽에 보내는 역할
-
Topic에 해당하는 메시지를 생성
-
특정 Topic으로 데이터를 publish
-
처리 실패/재시도
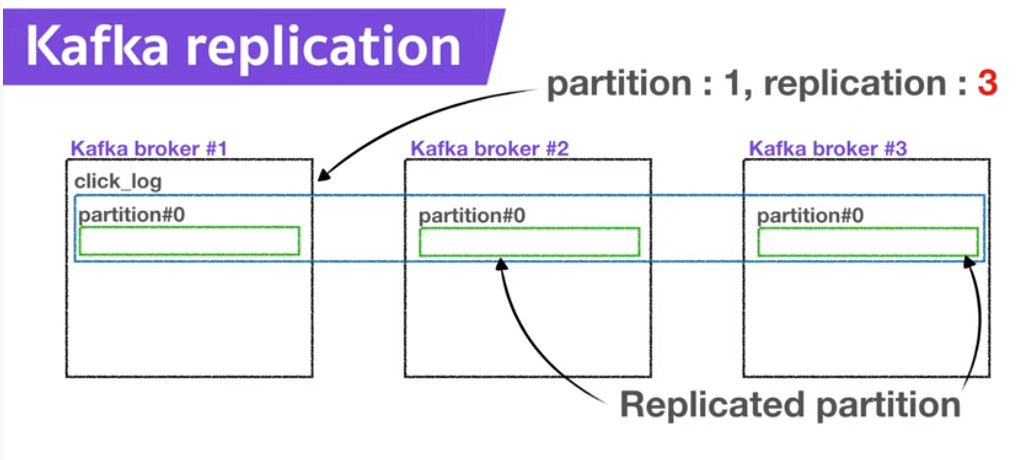
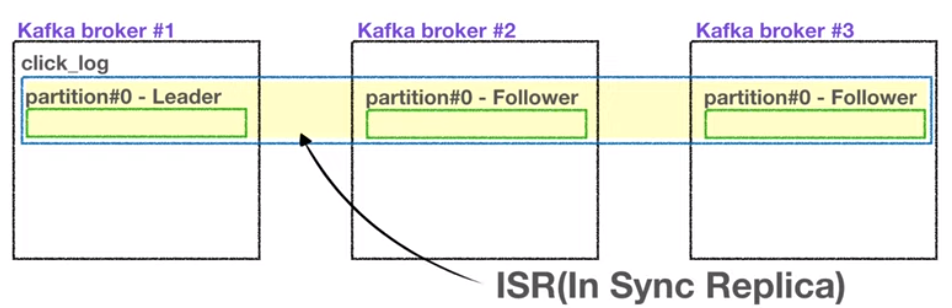
- Broker, Replication, ISR 핵심요소 3가지!
● broker는 kafka가 설치된 서버단위를 의미
● Replication
● ISR
- 카프카 컨슈머 역할
● 카프카 컨슈머
- Topic의 partition으로부터 데이터를 polling: 메시지를 가져와서 특정 DB에 저장하거나 다른 파이프라인에 전달할 수 있다
- Partition offset 위치 기록(commit): offset은 파티션에 있는 데이터 위치를 의미
- Consumer group을 통해 병렬처리: 파티션 개수에 따라 컨슈머를 여러개 만들면 병렬처리가 가능 → 더욱 빠른 속도로 데이터 처리
● 카프카 컨슈머의 동작은 다른 메시징 시스템과는 다소 다름
- 다른 메시징 시스템: 컨슈머가 데이터를 가져가면 큐 내부 데이터가 사라짐
- 카프카에서는 컨슈머가 데이터를 가져가더라도 데이터가 사라지지 않음
→ 이 특징은 카프카 컨슈머가 데이터 파이프라인으로 운영하는데 핵심적인 역할을 함
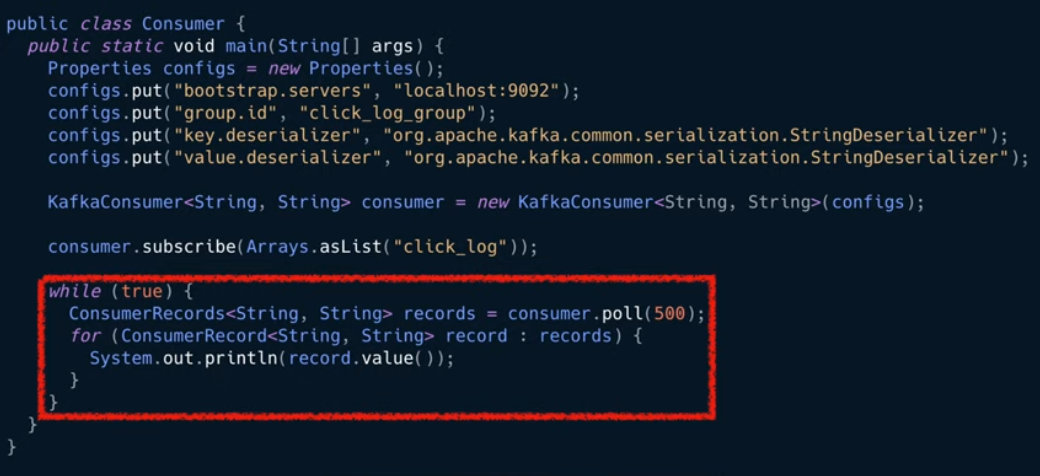
● 카프카 장애 및 컨슈머 재실행시 데이터 처리
__consumer_offsets 토픽의 offset 정보를 토대로 시작위치 복구 가능
→ 고가용성의 특징을 갖음
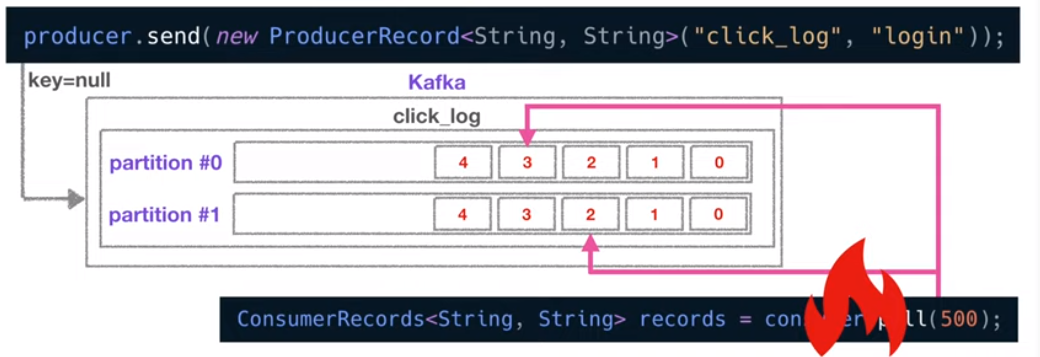
- 카프카 컨슈머 Lag이란?
● lag는 카프카를 운영하는데 있어서 아주 중요한 모니터링 지표
- 프로듀서는 토픽의 파티션에 데이터를 차곡차곡 넣는다
- 이 파티션에 데이터가 하나하나 들어가게되면, 각 데이터에는 오프셋이라고하는 숫자가 붙게 된다.
→ 컨슈머가 마지막으로 읽은 offset, 프로듀서가 마지막으로 넣은 offset의 차이: Lag

