참고
설명
-
컴퓨터는 0과 1의 2개의 상태만 가질 수 있는 이진 데이터만을 이해할 수 있습니다. 반면 인간은 다양한 문자와 기호를 사용합니다. 그러므로 인간이 사용하는 문자를 컴퓨터가 이해할 수 있는 이진 데이터로 변환하는 과정이 필요합니다. 이를 문자 인코딩이라 부릅니다.
-
컴퓨터 기술이 발전하면서 다양한 회사 또는 기관들의 컴퓨팅 시스템은 자신들 만의 독작적인 문자 인코딩 방식을 사용하였습니다. 하지만 이러한 독자적인 문자 인코딩 방식은 서로 호환되지 않아 데이터를 공유하거나 통신할 떄 많은 문제가 발생하였습니다. 이를 해결하기 위하여 공통된 문자 인코딩 시스템의 필요성을 느껴 ASCII 가 개발되고 표준으로 채택되었습니다.
예를 들어 A 시스템에서는 "1"라는 글자를 1000001로 인코딩 할 수 있으며, B 시스템에서는 "1"라는 글자를 1100001로 인코딩 할 수 있습니다. 이와 같은 동일한 글자에 대하여 해석이 일관되지 않는 경우 문제가 발생할 수 있습니다.이를 해결하기 위해 데이터 전송(교환)의 표준화 방식인 ASCII 가 개발되었으며, 표준화 방식을 사용함으로 다른 시스템간에 데이터 전송 시에도 일간된 데이터를 유지할 수 있습니다.
-
ASCII은 7비트 인코딩을 사용하여 총 128개(2^7)의 문자를 표현할 수 있으며, 영문 알파벳, 숫자, 특수 문자 및 일부 제어 문자를 포함됩니다.
https://ko.wikipedia.org/wiki/ASCII#%EC%B6%9C%EB%A0%A5_%EA%B0%80%EB%8A%A5_%EC%95%84%EC%8A%A4%ED%82%A4_%EB%AC%B8%EC%9E%90%ED%91%9C
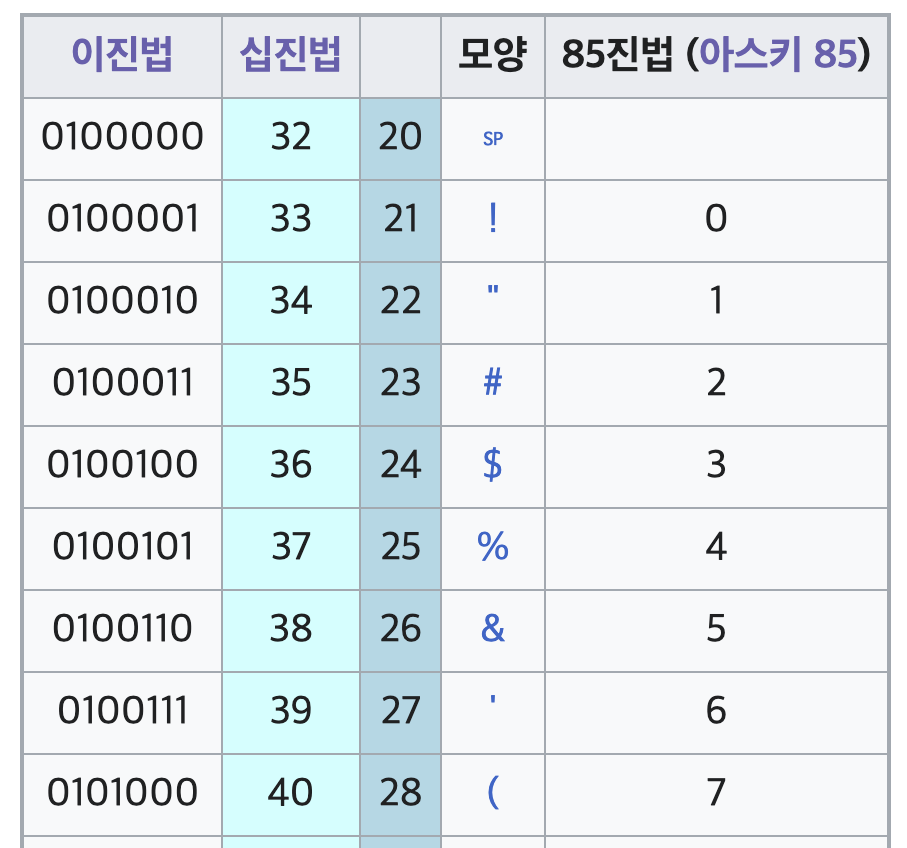
- ASCII는 영어 알파뱃과 몇 가지 기호만을 처리하기 떄문에 비영어권 언어를 처리하는 한계가 있었습니다. 그러하여 현대에는 유니코드와 같은 더많은 언어를 표현할 수 있는 방법이 사용됩니다.
