👣 Persistence(영속성)이란?
영속성이란 프로그램이 종료되더라도 데이터가 사라지지 않는 속성을 이야기한다.
영속성을 갖지 않는 데이터는 단지 메모리에서만 존재하기 때문에 프로그램이 종료되면 모두 잃어버리게 된다. 때문에 파일 시스템, 관계형 데이터베이스 혹은 객체 데이터베이스 등을 활용하여 데이터를 영구적으로 저장하여 영속성을 부여한다.
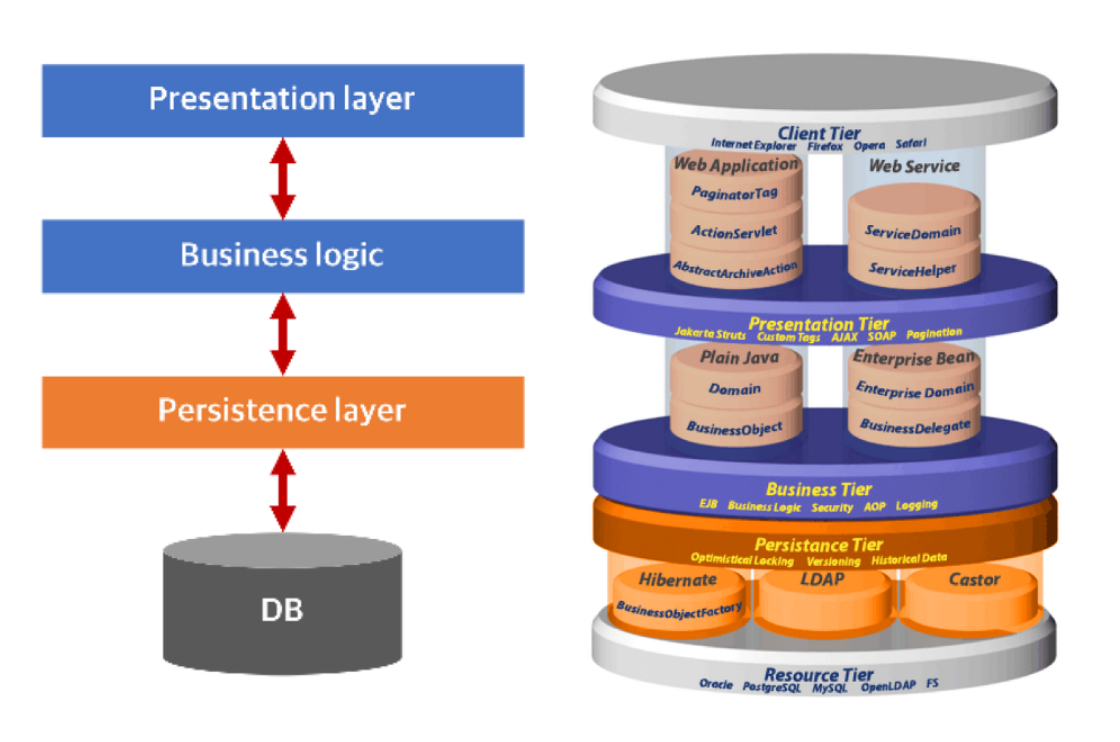
Persistence Layer
: 그림의 아키텍처에서 데이터에 영속성을 부여해주는 계층을 말한다.
📍JDBC (Java Database Connectivity)
실제 서비스를 진행하는 어플리케이션에서 데이터베이스와의 연동 을 위해서는 필요한 Query 마다 데이터베이스에 전송하여 변경된 부분을 반영하는 방식을 사용한다.
하지만 데이터베이스 별로 문법이 상이하기 때문에 같은 Query 문을 작성한다고 해서 서로 다른 데이터베이스에 적용이 가능한 것은 아니다. 이는 개발자로 하여금 불필요한 중복 코드를 생성하게 하고, 관리를 복잡하게 만든다.
이러한 전반적인 문제점을 보완하기 위해서 JDBC 가 사용 되었다.
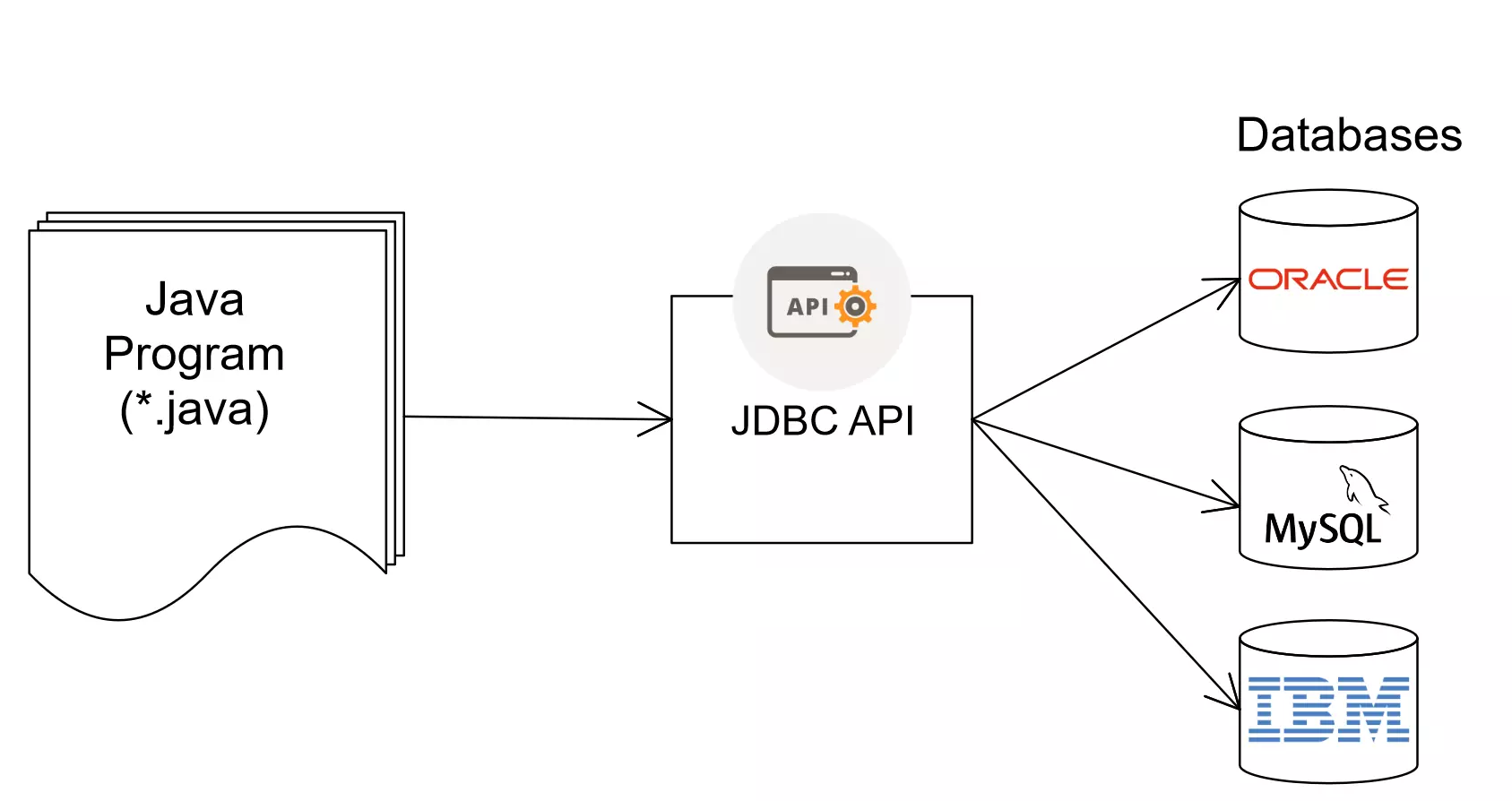
JDBC는 데이터베이스에 접근하기 위한 자바 표준 인터페이스이다. 인터페이스이기 때문에 JDBC API를 이용하면 특정 DBMS에 종속되지 않고, 사용하고자 하는 DBMS를 구현한 JDBC Driver 만 갈아 끼운다면 MySQL, Oracle 등 다양한 DBMS를 사용할 수 있다.
이를 통해 개발자는 데이터베이스 플랫폼에 독립적인 개발환경을 갖출 수 있게 되었고, 동일한 코드 대비 데이터베이스별 동일한 결과를 기대할 수 있게 되었다.
하지만 JDBC를 사용해봤다면 코드가 굉장히 복잡하다는 것을 느낄 수 있다. 실제로 사용되는 SQL 문은 몇 줄 안되지만 DB 연결, 예외 처리 등의 부가적인 요소를 모두 작성해야 하기 때문이다. 또한, 예외 처리나 Connection 같은 비싼 자원은 더 이상 사용하지 않는다면 반환해줘야 하는데 이러한 부분들을 모두 개발자가 직접 처리해야 하기 때문에 개발자가 실수할 가능성도 높고 여전히 불편한 점들이 존재 했다.
위와 같은 부분을 보완하고 독립적인 Query 생성 환경을 구축하기 위하여 위하여 Persistence Framework 가 등장하였다.
물론 개발자 입장에서 좀 더 비즈니스 로직에 집중하도록 JDBC를 한 단계 추상화시켜 불필요한 과정을 숨긴 것이기 때문에 우리가 직접 JDBC를 사용하지 않을 뿐이지 Persistence Framework 내부적으로는 JDBC를 통해 DB에 접근하고 있는 것이다.
📍Persistence Framework
데이터베이스와 연동되는 시스템을 빠르게 개발하고 안정적인 구동을 보장해주는 프레임워크
📍 Persistence Framework 종류
-
SQL Mapper
- SQL문장으로 직접 데이터베이스 데이터를 다루는 SQL Helper ( Mybatis, JDBCTemplates )
-
ORM
- 객체를 통해 간접적으로 데이터베이스를 다루는 ORM ( JPA, Hibernate )
📎 SQL Mapper
SQL Mappe 는 코드의 중복성을 제거하고, 쿼리 작성에 독립적인 환경을 구축하기 위해 개발되었다.
[ MyBatis ]
MyBatis는 xml 파일에 Query 를 작성하고, JDBC 코드로 바꾸어 실행시키는 역할을 한다.
Query 자체를 독립적인 파일에 작성할 수 있기 때문에 가독성이 좋으며, JDBC에서 제공하는 대부분의 기능을 수행할 수 있다는 장점이 있다.
그러나 XML 파일의 특성상, 쿼리문에 오류가 있더라도 빌드과정에서 오류를 발생시키지 않는다는 문제가 발생한다.
빌드과정에서 오류가 발생하지 않기 때문에 유지보수 또는 QA 테스트를 위해서 모델 객체, 컨트롤러, 서비스 등 어플리케이션을 전체적으로 점검 및 확인해야 한다는 어려움이 있다.
MyBatis는 객체의 모델링 보다 데이터 중심 모델링(테이블 설계)에 조금 더 신경을 써야하는 구조이며, 이는 객체 지향의 장점을 사용하지 않는 것이라고 평을 받았다.
[ JdbcTemplate ]
JdbcTemplate은 Spring에서 제공하는 JDBC 기반의 템플릿 클래스이다. JdbcTemplate은 JDBC 작업을 더 간단하게 처리할 수 있도록 도와주며, 연결 및 트랜잭션 관리를 자동으로 처리한다. 개발자는 SQL 쿼리를 직접 작성하지만, 반복적인 작업을 줄일 수 있고 예외 처리도 간소화된다.
📎ORM(Object Relational Mapping: 객체 관계 매핑)
객체 지향 프로그래밍에서 주안점 중 하나는 공통속성을 가지는 데이터는 객체로 관리한다는 것 이다.
데이터베이스 테이블과 쿼리는 객체와 메소드로 생성(mapping) 되기에 적합한 구조인데 이 때 사용되는 개념이 ORM 이다.
ORM 에서의 핵심개념을 통해 개발자는 따로 Query 문을 작성할 필요가 없어지고, 결과적으로 비즈니스 로직 개발에 더욱 집중이 가능하다.
[ JPA (Java Persistence API) ]
JPA란 자바 ORM 기술에 대한 API 표준 명세를 의미한다.
JPA는 ORM을 사용하기 위한 인터페이스를 모아둔 것이며, JPA를 사용하기 위해서는 JPA를 구현한 Hibernate, EclipseLink, DataNucleus같은 ORM 프레임워크를 사용해야 한다.
JPA의 동작은 JAVA가 JDBC API에 명령을 내리는 것이 아니라 JPA가 JDBC API를 사용해서 DB와 통신하고 SQL을 호출하고 반환한다.
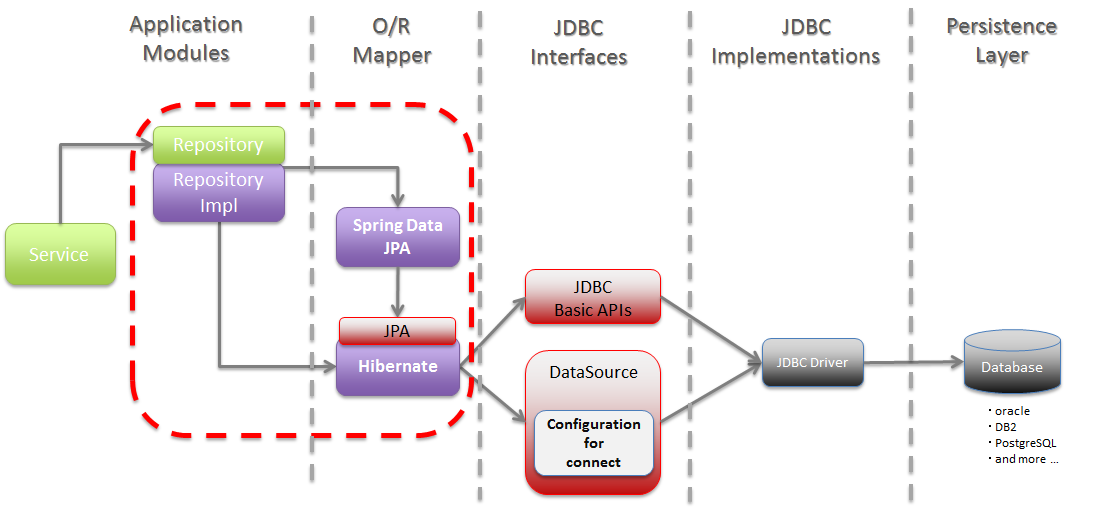
JPA는 내부적으로 영속성 컨택스트를 생성하여 Entity 를 관리한다. 변경 감지를 통해서 개발자가 Entity 를 수정하기만 해도 알맞은 쿼리가 생성되고, 쓰기 지연 방식을 통해서 Query 저장소에 있는 Query 들을 한번에 flush 시킴으로써 Connection 을 최소화해 서비스 성능을 향상시킬 수 있다.
[ Hibernate ]
Java ORM(JPA) 구조에서 개발자가 따로 Query를 작성하지 않아도 되는 이유는 이 Hibernate 가 내부적으로 Query 를 생성하고 JDBC API 를 호출하기 때문이다.
Hibernate는 SQL을 직접 사용하지 않고, 메소드 호출만으로 쿼리가 수행된다.
Mybatis에서는 관련 DAO의 파라미터, 결과, SQL 등을 모두 확인하여 수정해야 한다. 하지만 JPA의 Hibernate를 사용하면 JPA가 이런 일들을 해주기 때문에 테이블 관리가 쉬워진다.
[ Spring Data JPA ]
Spring Data JPA는 Spring에서 JPA를 사용하기 편리하게 만든 모듈이다. Spring Data JPA는 JPA 기반의 리포지토리 인터페이스를 제공하여 개발자가 간단한 인터페이스 정의만으로 데이터 액세스를 처리할 수 있도록 합니다. Spring Data JPA는 개발자가 직접 구현하지 않아도 기본적인 CRUD(Create, Read, Update, Delete) 작업을 자동으로 처리한다.
