
본 게시물은 고려대학교 스마트생산시스템 연구실 2023년 동계 신입생 세미나 활동입니다.
Michigan 대학의 Justin Johnson 교수님의 강의를 공부하는 형식입니다.
관련 유튜브 영상은 여기에서 확인 가능합니다.
Lecture 20: Generative Models, Part 2 강의에서는 배울 수 있는 내용은 다음과 같습니다.
- Review of Variational Autoencoders
- Generative Adversarial Networks
- Application of GAN
Review of Variational Autoencoders
직전 19강 강의에서는 VAE 모델이 무엇인지, 어떻게 데이터를 생성해낼 수 있는지 배웠습니다.
20강 시작에서도 VAE 모델에 대해서 간단하게 리뷰하고 넘어갑니다.

VAE는 Variational lower bound를 Maximize하여 간접적으로 모델을 학습합니다.
그 과정을 다시 살펴보면 다음과 같습니다.
먼저 입력 데이터를 Encoder를 통과시켜 Latent codes의 분포를 얻어냅니다.
VAE는 일반적으로 Gaussian 분포를 사용하기 때문에 평균과 분산을 추정합니다.
여기서 얻어내는 Gaussian 분포의 평균과 분산은 Unit Gaussian과 match될 수 있도록 학습을 진행합니다.
이를 위해서 Objective function에 KL Divergence term을 써주는 것입니다.
한 학생은 이런 질문을 합니다.
데이터셋에 따라서 다른 prior distribution을 사용해도 되는지,
교수님께서는 그래도 되긴 하지만 어차피 latent variable의 분포를 추정하는 것이기 때문에
Gaussian 분포만 써도 되고, KL Divergence를 계산할 때 Gaussian 분포가 아니면 계산이 복잡할 거다 설명해주십니다.
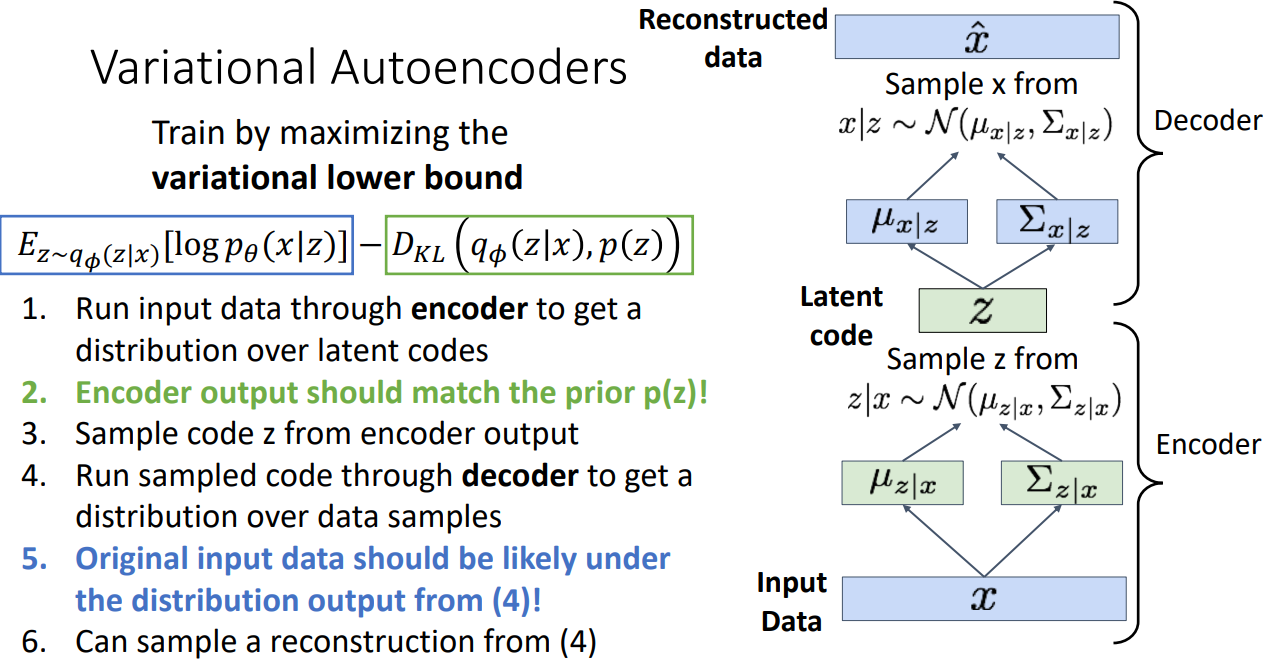
이렇게 Encoder의 분포가 만들어졌다면 이로부터 Latent code 를 샘플링합니다.
샘플로 뽑힌 Latent code를 Decoder를 통해 다시 Unit Gaussian과 match 되도록 하는 분포를 얻어냅니다.
그렇게 얻어진 분포를 통해 데이터를 Reconstruction 해냅니다.
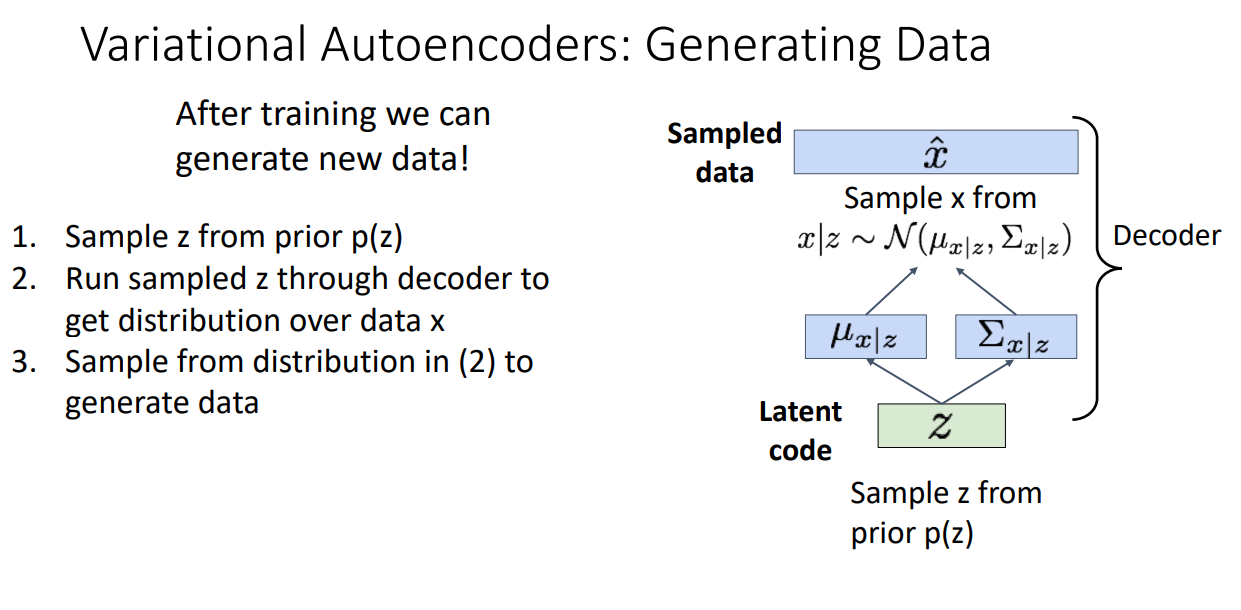
학습이 완료된다면 Decoder 만을 가져와서 생성을 진행합니다.
Decoder는 Latent code로 부터 만들어진 분포에서 데이터를 샘플링하는 방식으로
데이터를 새롭게 생성해내게 됩니다.

VAE의 재밌는 특징입니다.
VAE는 latent 를 통해서 데이터를 표현하는 방법을 배우는 모델입니다.
그 때 의 분포를 Unit Gaussian에 match 되도록 학습을 진행하기 때문에,
의 차원이 서로 independent하게 됩니다.
이러한 특징을 "Disentangling factors of variation"이라고 합니다.
위의 오른쪽 그림을 보시면 latent 의 각 차원값들을 변화시키면 다른 이미지로 바뀝니다.
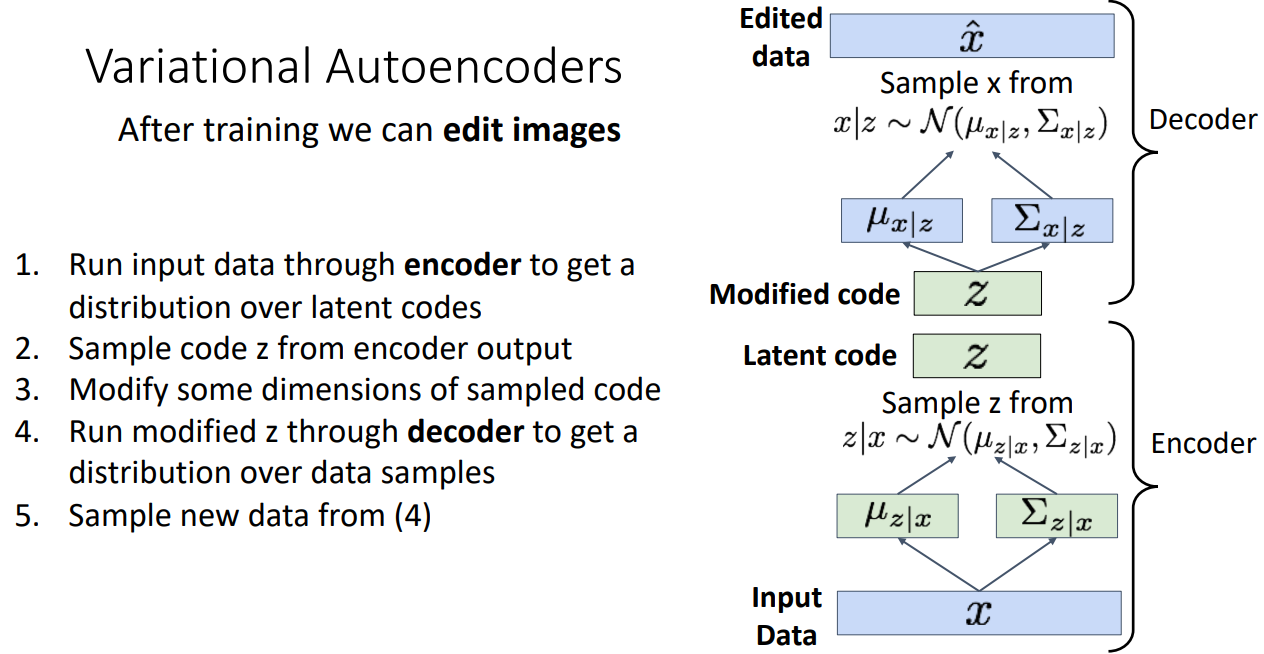
"Disentangling factors of variation" 특징 덕분에 VAE는 이미지를 edit 하는데 유용합니다.
Edit 방법은 원래 VAE 학습하는 과정과 유사한데 추가된 것은 Sample code 를 Modify하여
Decoder를 학습한다는 점이 다입니다.

Edit 하도록 학습이 잘된다면 위 그림처럼 차원을 Degree of smile / Head pose로 나눠서 변형된 샘플을
생성해낼 수 있습니다.

VAE는 이처럼 훌륭한 생성모델이지만 아쉬운 점도 분명 있습니다.
첫번째로, Data Likelihood를 직접적으로 maximize하지 못하고, lower bound를 maximize 하는 방식으로
간접적으로 학습한다는 점입니다. 따라서 good evaluation이 아닙니다.
두번째로, 19년 당시 SOTA 모델이었던 GAN 모델에 비해서 이미지들이 blurry하고 lower quality 라는 점입니다.

19강, 20강에서 Autoregressive 모델과 VAE 모델을 살펴봤는데 둘은 분명하게 장단점이 존재했습니다.
그래서 이들의 장점만을 합친 모델이 제시됩니다.
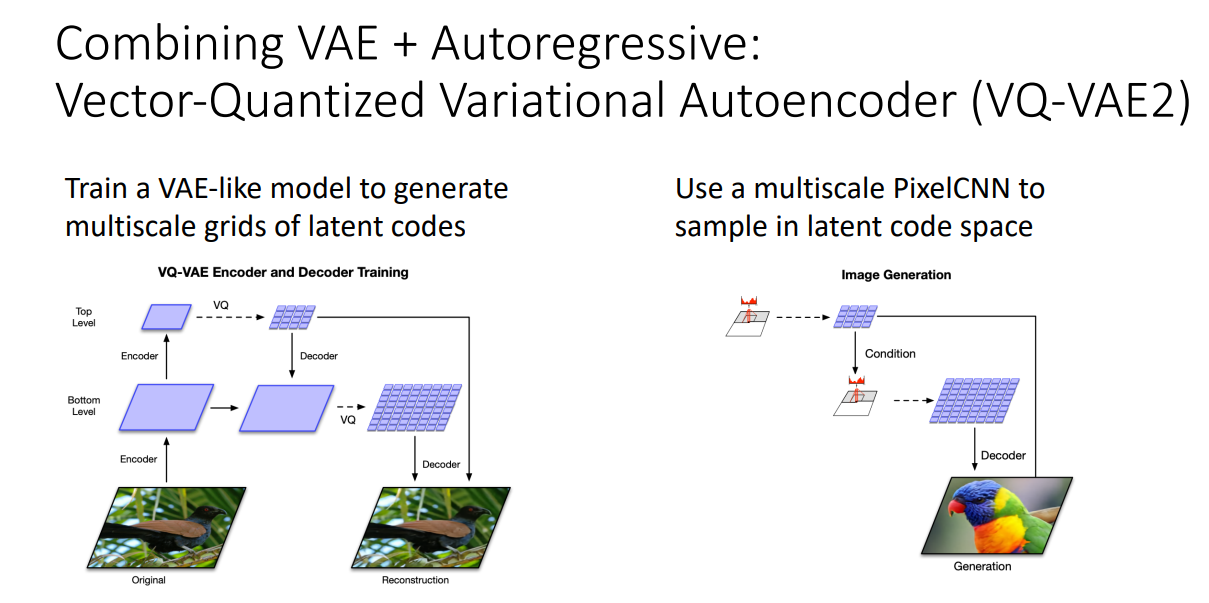
VQ-VAE 가 바로 그러한 모델입니다.
모델 구조를 보시면 VAE 처럼 학습하고, Latent code로부터 샘플링할 때는 PixelCNN을 사용합니다.

VQ-VAE2를 사용하여 생성해낸 이미지입니다. 상당히 고퀄이죠?!
Generative Adversarial Networks

지금까지 살펴본 모델은 Autoregressive 모델과 VAE입니다.
Autoregressive 모델은 직접적으로 training data의 likelihood를 maximize 할 수 있었습니다.
VAE는 latent 를 도입했고, lower bound를 maximize 하는 방식으로 간접적으로 학습했습니다.
지금부터 살펴볼 적대적생성신경망(GAN)은 애초에 모델링을 포기하고 샘플링만 잘하자라는 아이디어입니다.
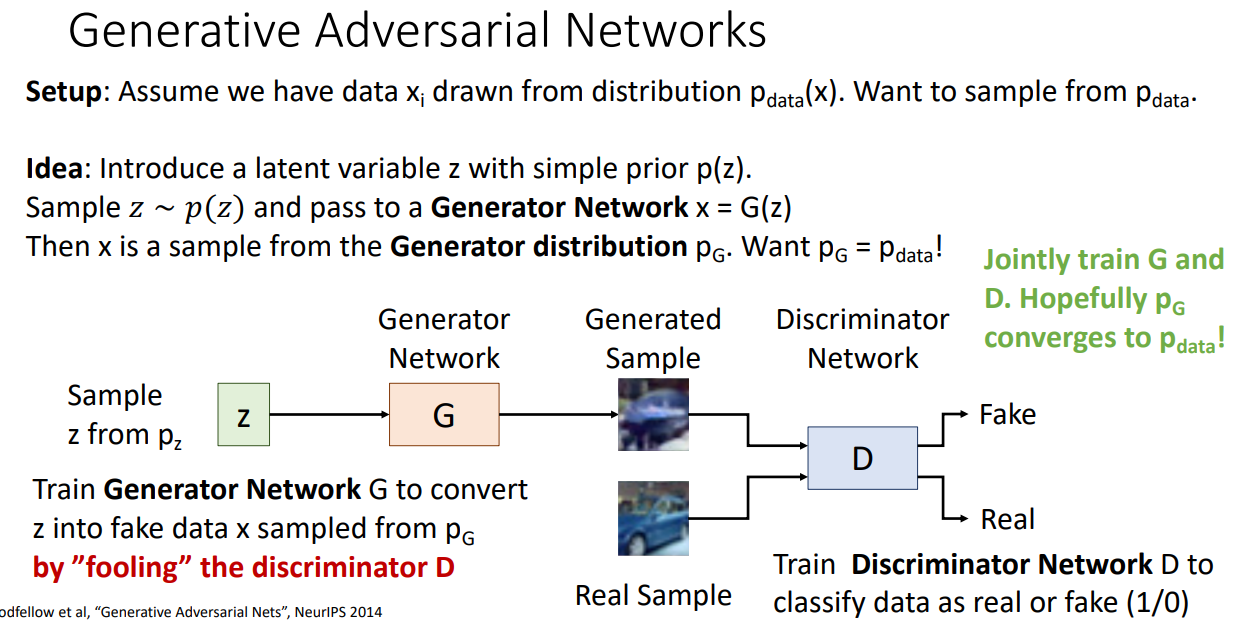
Ian Goodfellow 님이 만드신 GAN 모델의 개요입니다.
아이디어는 간단합니다.
데이터 는 분포에서 나온다고 가정할 때,
Latent variable인 를 Generator Network 에 통과시켜 생성한 가 와 구분이 안되게 만들어주는 것입니다.
이를 위해서 Generator Network의 분포 를 와 같도록 만들어주는 것입니다.
와 가 같은지 다른지를 판단하기 위해서 Discriminator를 도입합니다.
Discriminator Network D는 data를 real(1) 또는 fake(0)으로 판단합니다.
결론적으로 이 Discriminator만 속이면 학습이 잘되었다 할 수 있습니다.

GAN의 Training Objective는 위와 같습니다.
Generator도 학습을 잘해야하고, Discriminator도 학습을 잘해야하는 상황인데
이런 경우 minimax game이라고 부릅니다.
위 그림에서 파란부분이 Discriminator, 주황부분이 Generator 입니다.
Discriminator는 Real data에 대해서는 1 / Fake data에 대해서는 0을 뱉어낼 수 있도록 학습이 되어야하기 때문에 위 식을 최대화하고자 합니다.
반면 Generator는 Discriminator가 생성된 데이터에 대해서도 1을 뱉어낼 수 있도록 학습되기를 기대해야하기 때문에 위 식을 최소화하고자 합니다.

G와 D를 번갈아가면서 gradient update하여 학습시킵니다.
Discriminator update 하고 Generator update하고 계속 반복합니다.
이 경우에 전체적인 Loss를 minimize 하는 상황이 아니기 때문에 training curve는 볼 필요없습니다.

위 그림은 의 모습입니다.
파란색이 원래 Training objective에 있는 모습인데 보시면 학습 초반에는 Generator가 별로여서 0에 가깝다가 학습이 진행되면서 점점 낮아지는 모습입니다.
근데 파란색처럼 학습했다가는 Gradient Vanishing 문제를 피할 수 없습니다.
그래서 파란색 식을 minimize 하는 대신 주황색 식을 maximize 하는 방식으로 학습한다면 Generator가 더 strong한 gradient를 학습 초기에 갖게됩니다.

GAN을 최적화하는 과정은 강의에서 자세하게 설명되어있는데, 꽤나 재밌습니다.
궁금하신 분들은 한 번씩 보시는 걸 추천드립니다.
여기서는 결론만 보여주자면 위처럼 Training Objective가 JSD term을 포함한 간단한 minimize 문제로 바뀝니다.
해당 minimize 문제의 최적 값을 구하면 Summary 부분이 됩니다!
1. Discriminator:
2. Generator:
주의할 점도 있습니다.
G와 D는 고정된 구조의 신경망이기 때문에 실제로 optimal D와 G를 나타내지 못할 수 있습니다.
그리고 번갈아가면서 학습을 진행하기 때문에 Convergence 가 이뤄지지 않을 수 있을 위험이 있습니다.
Application of GAN
지금부터는 GAN을 사용한 사례들을 간단하게 나열하겠습니다.
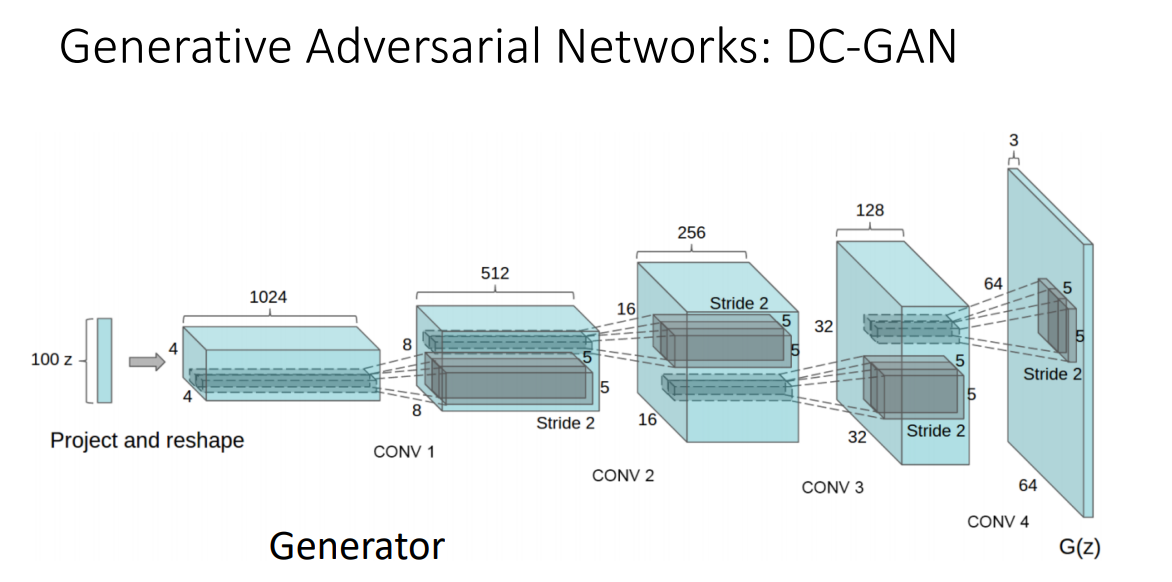
CNN 구조와 GAN을 합친 구조입니다.

퀄리티가 상당합니다.

또한 Latent space의 두점을 보간하는 방식으로 이미지를 생성한다면
위와 같이 이어지는듯 유사한 이미지를 만들어낼 수 있습니다.

재밌는 예시도 있습니다.
Vector 계산하듯 이미지를 계산해서 원하는 이미지를 만들어낼 수 있습니다.
위 예시는 '안경 쓴 남성' 이미지에서 '안경 안 쓴 남성' 이미지를 빼고 '안경 안 쓴 여성' 이미지를 더한다면
결과적으로 '안경 쓴 여성' 이미지가 나오는 예시입니다.
Semi-interpretable vector map 이라고 이해하시면 됩니다.

다음으로는 Loss function을 수정하여 더욱 좋은 성능으로 이미지를 샘플링하는 Wasserstein GAN도 소개되었습니다.

생성된 이미지들이 진짜 같습니다.
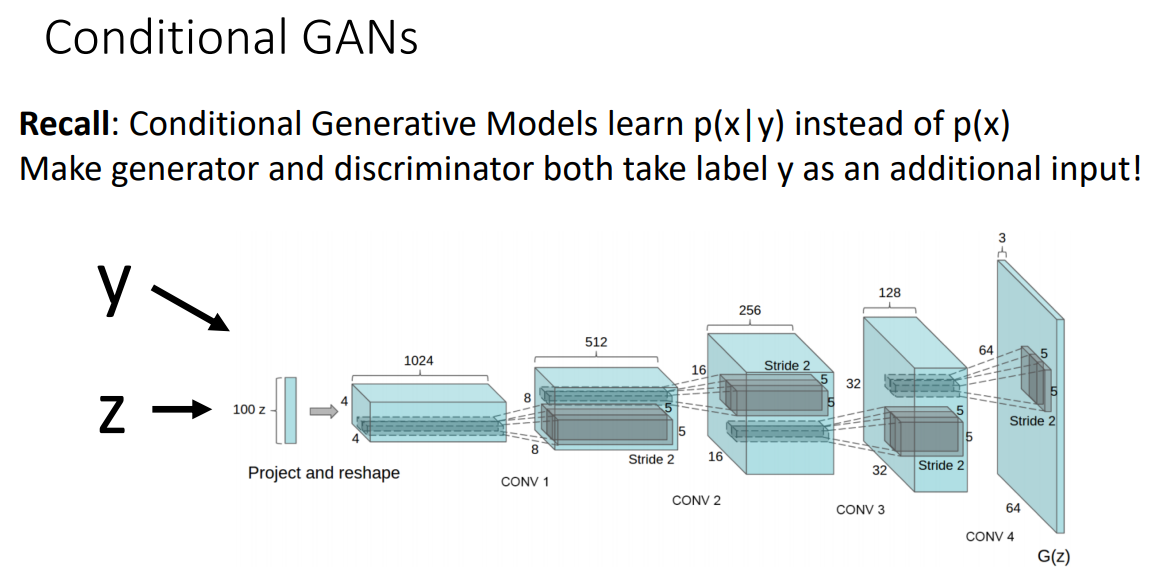
GAN은 무작위의 이미지를 생성해내지만 input으로 label 값을 같이 넣어준다면 원하는 class의 이미지만 생성해낼 수도 있습니다.
해당 모델의 이름은 Conditional GANs(CGAN) 입니다.

input 값에 넣어줘도 되지만, 이처럼 Batch Normalization을 수행할 때 scale과 shift 계수를 계산시에
Label 정보를 반영해줘도 됩니다.

GAN에 Self-attention을 결합한 경우에도 고퀄리티의 이미지를 생성해낼 수 있습니다.

단순히 Label 값을 넣어서 원하는 이미지를 생성해내는 것을 넘어, 문장을 입력으로 넣어서
해당 문장에 맞는 이미지를 생성해낼 수도 있습니다.

해상도를 높이는 Super-Resolution도 흥미로웠구요.

해상도를 넘어서 단순한 스케치 이미지도 실제 사물처럼 그려주는 GAN 도 신기했습니다.
지금까지 신입생 세미나였습니다.
