다단계 인덱스
이 시리즈의 1편에서 단일 단계 인덱스에 대해 알아보았다.
이제 다단계 인덱스와 B+tree에 대해 알아볼 차례이다.
다단계 인덱스는 말 그대로 인덱스를 여러 계층으로 구성하는 방식이다.
인덱스 자체가 너무 클 경우, 이 인덱스를 여러 계층으로 표현하여 조회 시간을 최소화하는 것이다.
다단계 인덱스는 하나의 데이터 블록에 현재 계층의 인덱스 엔트리가 모두 포함될 수 있을때 까지 계층을 나누며, 이 때 최상위 계층의 인덱스를 마스터 인덱스라고 부른다. 이 마스터 인덱스는 하나의 데이터 블록으로 이루어지기 때문에 주기억장치에 상주할 수 있다.
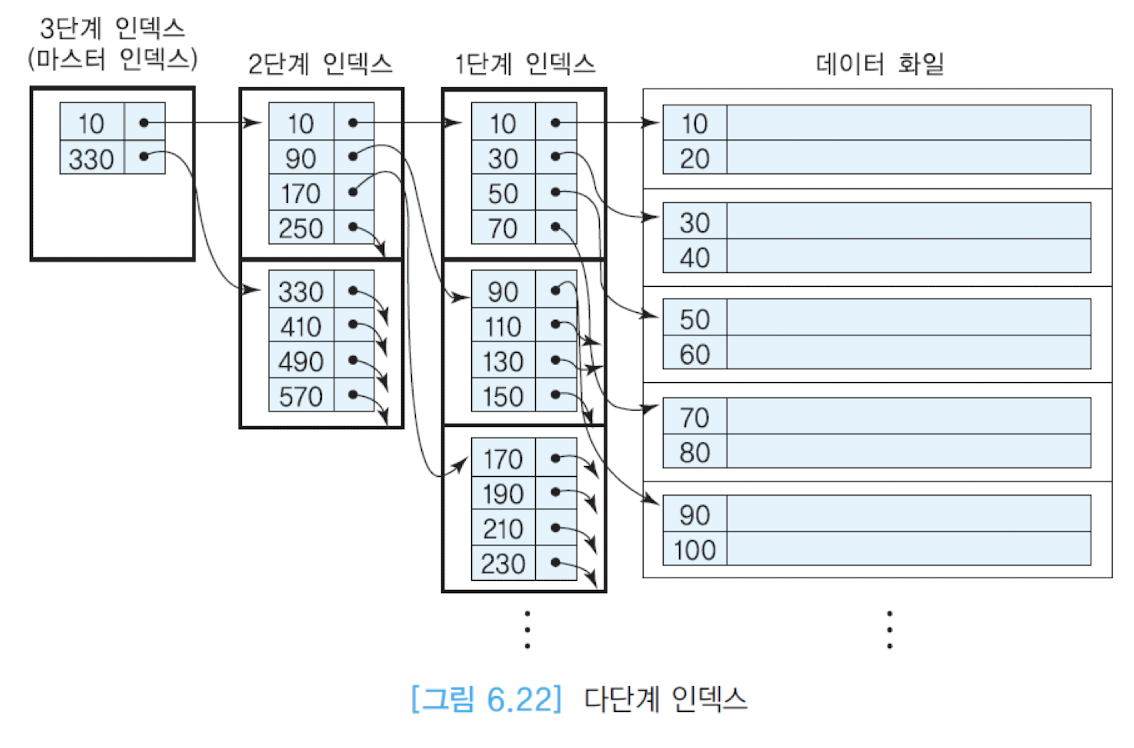
이러한 다단계 인덱스는 보통 B+tree 자료구조를 이용해 저장한다. 그러면 B+tree 자료구조는 대체 무엇인가?
B-tree
B+tree를 알기 위해선 우선 B-tree 자료구조를 살펴보아야 한다.
B-tree는 이진트리가 확장된 형태인데, B-tree의 차수는 2 이상이다. 즉, 하나의 노드가 2개 이상의 branch를 가질 수 있다는 뜻이다.
하나의 노드는 키값과 데이터값을 모두 갖고있을 수 있다. 바로 이 부분이 B+tree와의 차이점이다.
B+tree
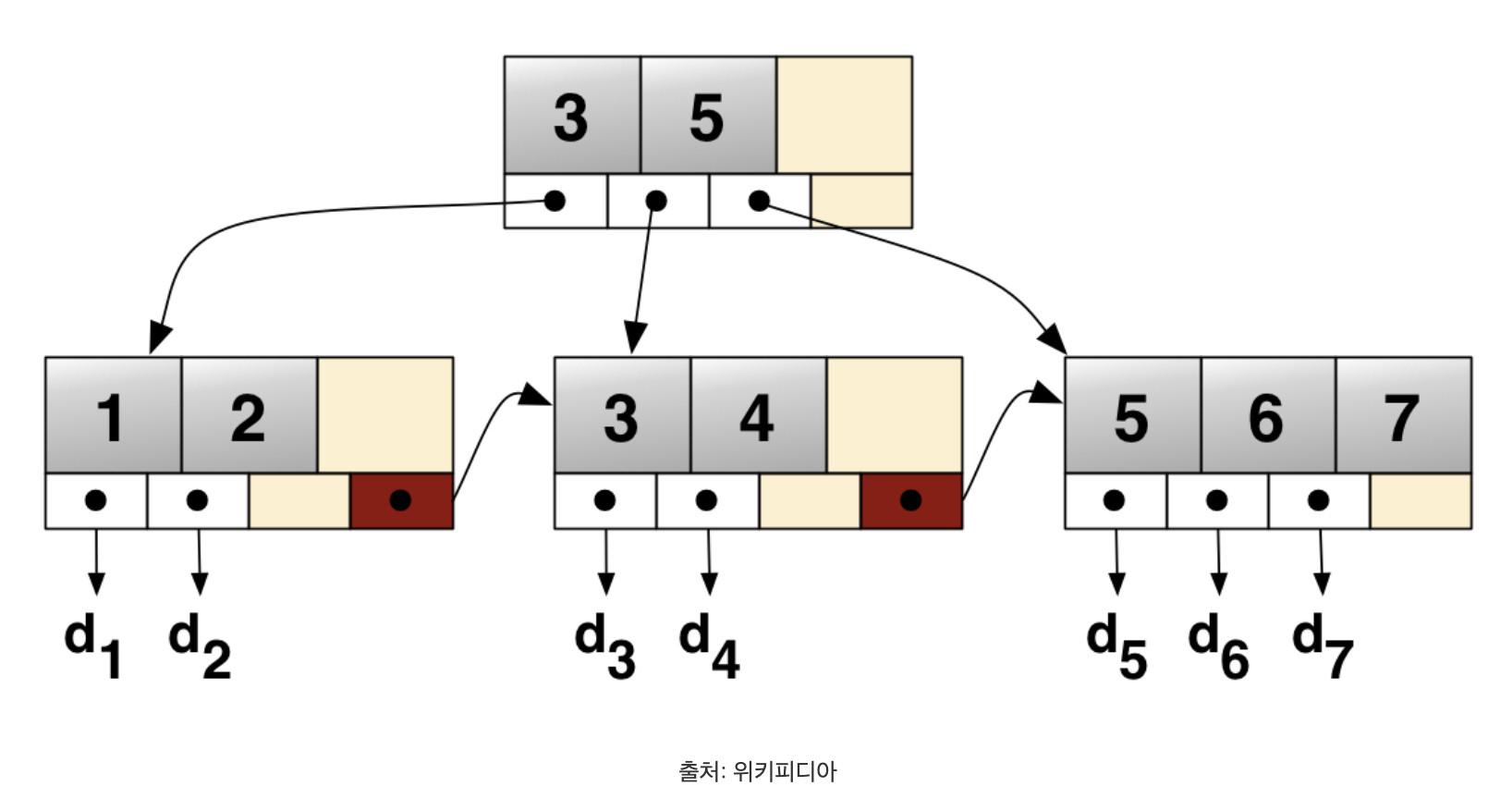
그림이 보이는가?
B+tree는 B-tree와 다르게 리프 노드에만 데이터값을 저장하고 있고 각 리프 노드가 링크드 리스트 형태로 연결되어있다. 이전 글에서 살펴본 다단계 인덱스의 형태와 매우 유사하다. 인터널 노드에 저장된 인덱스 엔트리를 타고 내려가, 실제 데이터가 저장된 데이터 블록(리프 노드)에 다다르면 데이터 값을 읽을 수 있게된다. 그런데 이때, 링크드 리스트를 통해 바로 다른 데이터 블록을 읽어올 수 있으므로, 인덱스가 저장된 블록을 읽는 횟수를 줄일 수 있다. 즉, 순회에 더 유리해지는것이다.
그렇다면, 인덱스는 만능인가?
인덱스는 검색 속도를 향상시키기 위해 사용한다. 다만, 모든 경우에 검색 속도가 향상되는 것이 아니며, 단점도 존재한다. 인덱스를 생성하면 인덱스를 저장하기 위한 공간이 필요하며, 데이터의 삽입, 수정, 삭제가 일어날 경우 인덱스를 수정하는 추가 연산이 필요할 수 있으므로 속도가 저하된다.
다만, 소수의 레코드를 수정하거나 삭제하는 연산의 속도는 향상된다.
대체로 릴레이션이 매우 크고, 질의에서 릴레이션의 튜플들 중 일부 (2% ~ 4%)를 검색하며, where 절이 잘 표현되었을 경우 검색 속도가 향상된다. 물론, 인덱스를 통해 검색되는 레코드의 수도 적어야 한다.
마무리
인덱스. 데이터베이스. 참으로 오묘하고 어렵다.
이번 시리즈는 이쯤에서 마무리 하겠다.
허무해도 어쩔 수 없다.
너무 어려운걸!
추가 자료
