프로세스를 넘어, 이제는 쓰레드이다. 대부분의 현대 os 시스템은 이 쓰레드를 이용한 멀티쓰레드 환경이 구축되었을 정도로, os를 논할때 빠질 수 없는 주제이다. 이제부터 다시 알아보자.
Thread?
하나의 프로세스를 유지하기 위해서 다양한 정보들이 존재한다. 프로세스를 위한 스택, 힙영역 등을 할당해주는 process address space와 해당 프로세스의 실행을 위해 그 상태를 저장하는 program counter, 사용 register 등을 저장해두는 PCB 등이 그 정보들에 해당한다.
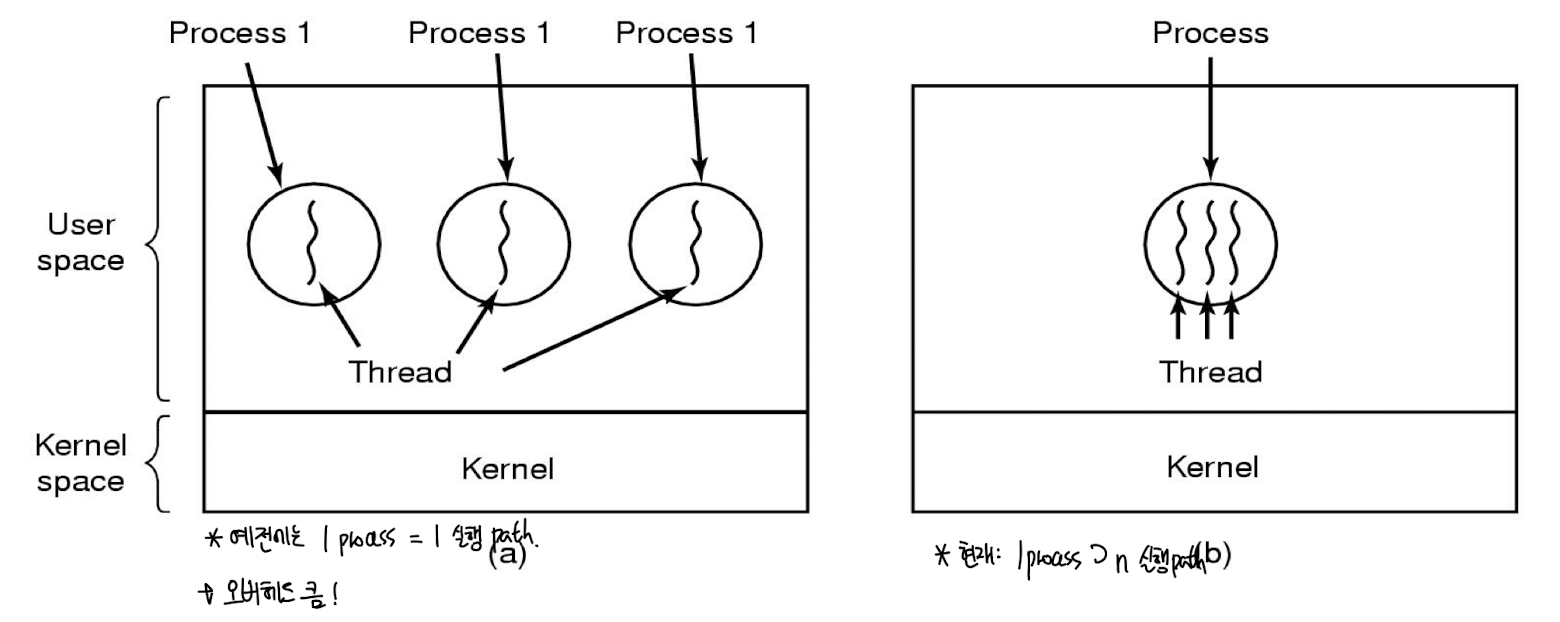
그런데 이 쓰레드는 program counter, stack pointer, register 등등의, 실질적인 프로세스 실행 path를 통틀어 일컫는다.
다시말해, 쓰레드는 프로세스의 실질적인 작업 단위이며 프로세스를 위해 할당된 메모리 공간을 동일 프로세스 내의 쓰레드들이 공유할 수 있다.
이를 그림으로 나타내면 다음과 같다.
Process , Thread
그렇다면 왜 굳이 쓰레드를 사용하는가? 여러개의 작업 단위가 필요하다면, 여러개의 프로세스를 생성하면 되는것 아닌가?
당연하게도 아니다.
앞서 말했듯이, 하나의 프로세스를 생성하기 위해선 수많은 메모리들을 해당 프로세스를 위해 할당해야 한다. 또한 프로세스들로만 작업을 수행하면 그 프로세스들 끼리 공유해야할 데이터가 있을 경우 IPC 과정이 필수적으로 필요하다. 그런데 이 IPC 과정이 일어나면 커널의 오버헤드가 증가하거나, 다른 메모리 주소에 접근해 데이터를 꺼내오는 작업이 추가된다. 쉽게말해, 성능이 나빠진다.
하지만 쓰레드를 사용한다면, 하나의 프로세스를 위해 할당한 메모리 공간을 쓰레드들이 공유하기 때문에 앞서 말한 오버헤드들을 대폭 줄일 수 있다. 쓰레드가 process address space를 공유하는 방식은 다음 그림에 자세히 나타난다.
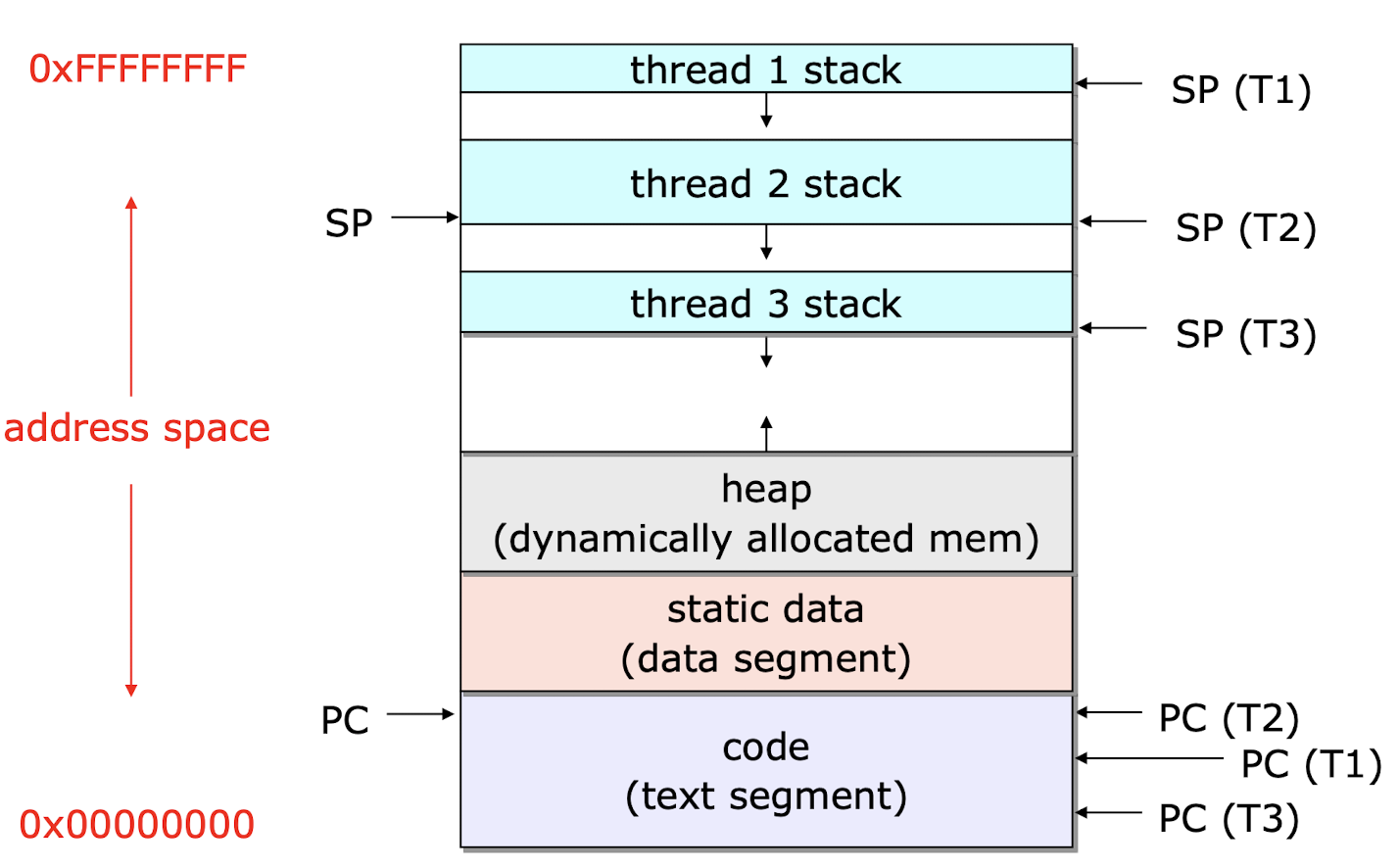
이 뿐만 아니다. 쓰레드를 이용하면 context switching을 할때도 유의미한 성능 향상이 있을 수 있다. CPU가 메모리에 있는 프로세스를 running 하기 위해 프로세스의 정보들을 읽는 상황을 가정해보자. 이 때, 각 프로세스들은 독자적인 process address space를 가지고 있다. 따라서, context switching이 일어나기 전의 프로세스 정보들을 메인메모리와 CPU 사이에 존재하는 캐시에 저장했다고 하더라도, context switching이 일어난 이후에는 또 다른 프로세스의 독자적인 정보를 로드해야 한다.
하지만 쓰레드에 대해 context switching이 일어나면, 그 쓰레드가 사용하는 데이터는 다른 쓰레드가 사용하고 있던 동일 프로세스의 데이터이므로, 캐시에 적재되어 있던 데이터를 바로 사용할 수 있다.
당연하게도, 쓰레드에 대한 context switching이 더 overhead가 적다.
user-level, kernel-level
이러한 쓰레드는 user-level에서만 지원될 수 있고, kernel-level에서도 지원될 수 있다.
1. user-level thread
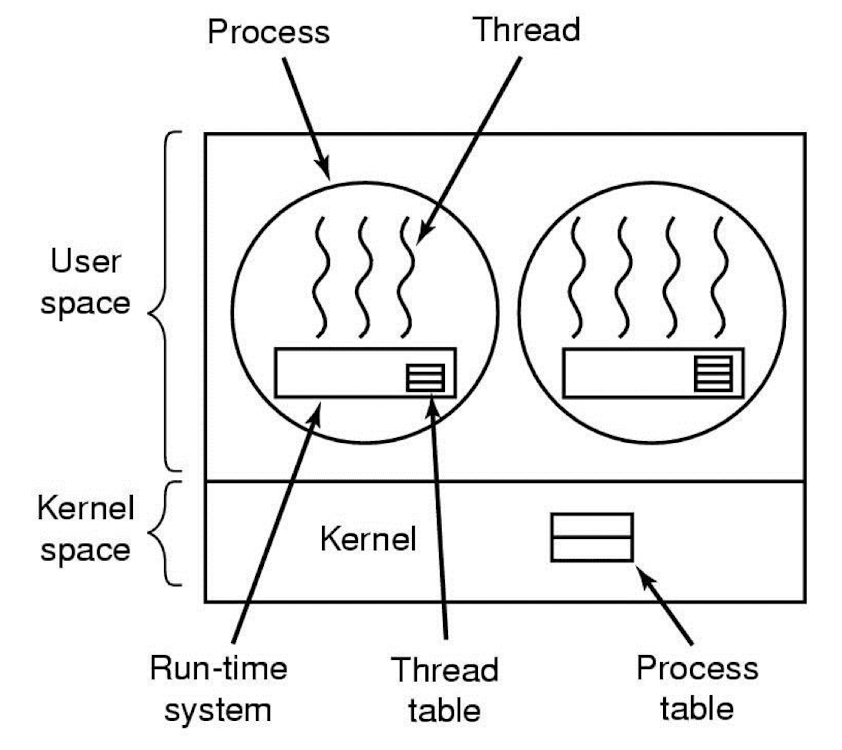
user-level thread는 위의 그림처럼 커널에서 프로세스에 관한 정보를 저장한다. 커널 단위에서 추가적으로 저장할 정보가 없으므로, 구현에는 user-level kernel만 지원하도록 하는것이 더 쉽다.
하지만 이는 blocking 작업이 일어날때 치명적인 약점이 있다. A 프로세스의 특정 쓰레드가 io 호출을 했다고 가정하자. 그 쓰레드는 io 작업의 결과물이 필요하지만, 다른 쓰레드들은 필요하지 않다. 그런데 커널 단위에서 프로세스 정보만 저장하고 있으므로, 해당 쓰레드의 io 호출에 의해 그 프로세스 전체가 waiting 상태로 빠지게 된다. 그렇다면, io 호출과 관련없는 다른 쓰레드들의 실행 또한 중지되어 버린다.
2. kernel-level thread
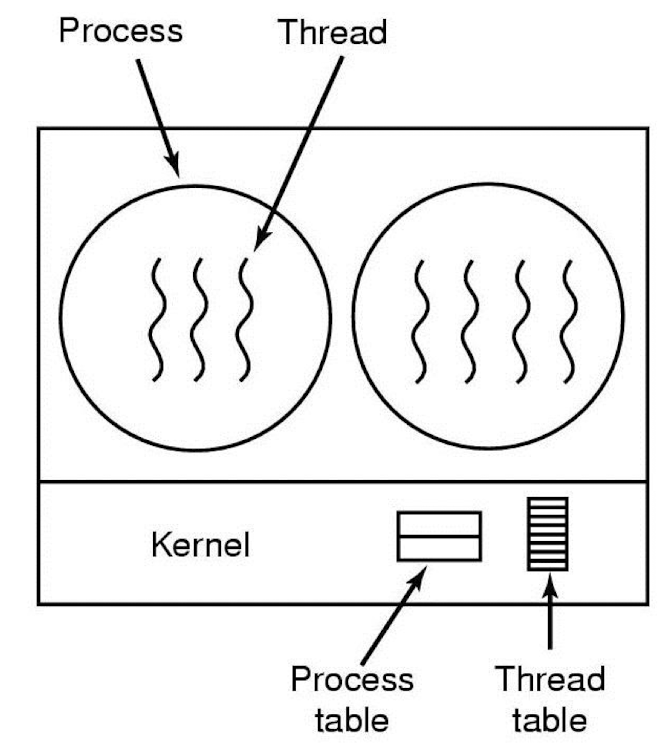
kernel-level thread는 앞서 살펴본 user-level thread의 문제점을 보완한다. 커널에서 프로세스 뿐만 아닌 쓰레드 정도도 포함하고 있기 때문에, 쓰레드 단위의 context-switching을 더 안전하게 지원한다.
그렇다고 단점이 없는것은 아니다. kernel level에서 저장하고 관리해야할 정보가 많아지기 때문에, OS 입장에서 user-level thread를 지원하는것 보다 더 많은 overhead가 발생한다.
마무리
- thread 란?
- 프로세스가 가진 정보중 program counter, stack pointer, register 정보등을 포함한 프로세스 내부의 독자적인 작업 실행 단위이다. 쓰레드는 자신이 포함된 프로세스의 process address space같은 정보들을 공유하며, lightweight 프로세스라고도 불린다. 이러한 특성 때문에 프로세스 만으로 다중 작업을 처리할때보다 그 오버헤드가 적고 성능이 좋다.
- multi thread programming?
- 하나의 프로세스를 여러개의 쓰레드로 나누어 실행하여 자원의 생성과 관리에 드는 오버헤드를 최소화하는 방법이다.
참고자료
