SQL*LOADER
CONTROL FILE 생성
- 로드할 데이터의 위치
- 데이터 형식
- 데이터 조작 세부사항
vi insa.ctl
[ LOAD DATA | UNRECOVERABLE LOAD DATA ] : 새 데이터 로드가 시작되는 의미,
UNRECOVERABLE은 ARCHIVE LOG MODE에서 DIRECT PATH LOAD 사용시에 REDO LOG 정보를 생성하지 않음
INFILE insa.dat : 외부 데이터 파일 지정, 포함하지 않을 경우 * 으로 표시
BADFILE insa.bad : 거부된 레코드(행)를 배치할 파일 이름을 지정(안하면 자동생성)
DISCARDFILE insa.dsc : 폐기된 레코드(행)를 배치할 파일 이름을 지정(옵션)
INSERT : 비어있는 테이블에 데이터를 로드할때(비어있지 않은 테이블에 사용하면 오류)
REPLACE : 테이블의 기존행을 모두 삭제(DELETE)하고 로드(입력)
TRUNCATE : 테이블을 TRUNCATE하고 데이터를 로드(입력)
APPEND : 새로운 데이터를 테이블의 제일 뒤에 로드
INTO TABLE test : 데이터를 로드할 테이블
WHEN(10) = '.' : 데이터를 로드하기 전에 만족시켜야할 각 레코드의 필드조건을 지정
10번째 위치의 문자가 소수점인 경우에만 레코드를 입력
FIELDS TERMINATED BY ',' : 데이터 필드의 종결 문자 지정(구분되는 문자)
OPTIONALLY ENCLOSED BY '"' : 문자 데이터의 앞과 뒤에 " 부호가 지정되어 있음(안되어 있으면 사용하지 않으면 됨)
TRAILING NULLCOLS : NULL값이 있는 데이터도 이관
(ID,NAME,PHONE) : 데이터 필드와 컬럼과 매치하는 부분
--예시
UNRECOVERABLE LOAD DATA
INFILE * --입력해야할 데이터가 컨트롤파일에 같이 있을 경우
INSERT
INTO TABLE test
FIELDS TERMINATED BY ','
OPTIONALLY ENCLOSED BY '"'
(ID,NAME,PHONE)
BEGINDATA --입력해야할 데이터 시작하는 키워드(INFILE *일때)
1,"JAMES","010-9999-0000"
2,"GRACE","010-7777-7777"
3,"SCOTT","010-3333-1234"
3,"LUCAS","010-3453-3452"CONVENTIONAL LOAD
- INSERT 작업과 유사하다.
- UNDO, REDO 발생한다.
- COMMIT
- 모든 제약조건을 체크한다.
- INSERT TRIGGER 실행한다.
- 로드 대상 테이블을 다른 유저들이 사용할 수 있다.
DIRECT PATH LOAD
- DATA SAVE 사용한다. 속도가 빠르다
- sqlldr 도 유저 프로세스이다.
- 특정 조건에서만 리두가 발생한다.(데이터 딕셔너리 테이블들의 변경작업)
- primary key, unique, not null 수행, index 깨짐
- insert trigger 발생하지 않습니다.
- 로드 작업하는 동안 대상 테이블에 대해서 다른 세션에서 작업이 대기할 수 있다.
SPOOL
- 캡쳐라고 생각하면 된다.
<기본>
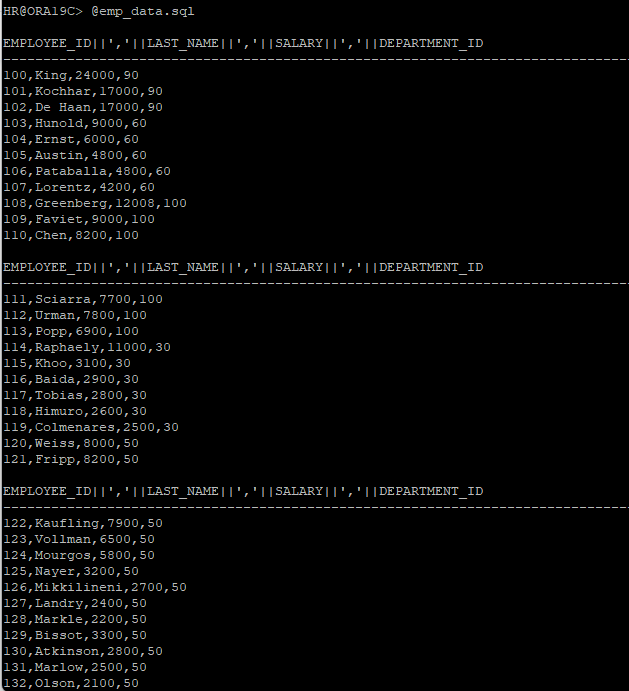
vi emp_data.sql
spool emp_data.csv
SELECT employee_id|| ',' ||last_name||',' ||salary||',' ||department_id
FROM hr.employees
ORDER BY 1;
spool offspool 스크립트 작성

spool 스크립트 실행
<옵션 추가버전>
set pagesize 0 : 헤더부분 출력되지 않음
set linesize 200 : 가로길이 최대 값 설정
set echo off
set trimspool on : 행 간격 없애줌
set feedback off : sql 실행결과에 대한 건수를 표시하지 않음
set termout off : 스크립트 실행시 spool 결과 보여주지 않음
spool emp_data.csv
SELECT employee_id|| ',' ||last_name||',' ||salary||',' ||department_id
FROM hr.employees
ORDER BY 1;
spool offset echo on - 내가 실행한 sql쿼리문까지 같이 보여줌

[문제]
2005년 이전의 입사한 사원들의 정보를 추출해서
hr.emp_before_2005 로드해주세요.
- 스크립트 작성
set pagesize 0
set linesize 200
set echo off
set trimspool on
set feedback off
set termout off
spool emp_data_test.csv
SELECT employee_id||','||last_name||','||salary||','||to_char(hire_date,'yyyy-mm-dd')||','||b.department_id||','||b.department_name
FROM hr.employees a, hr.departments b
WHERE extract(year from hire_date) <= 2005
AND a.department_id = b.department_id;
spool off- 날짜는 세션마다 다를수 있기 때문에 to_char를 이용해서 문자로 바꿔주는게 좋다
- 스크립트 실행
HR@ORA19C> @emp_data_test.sql
vi emp_data_test.csv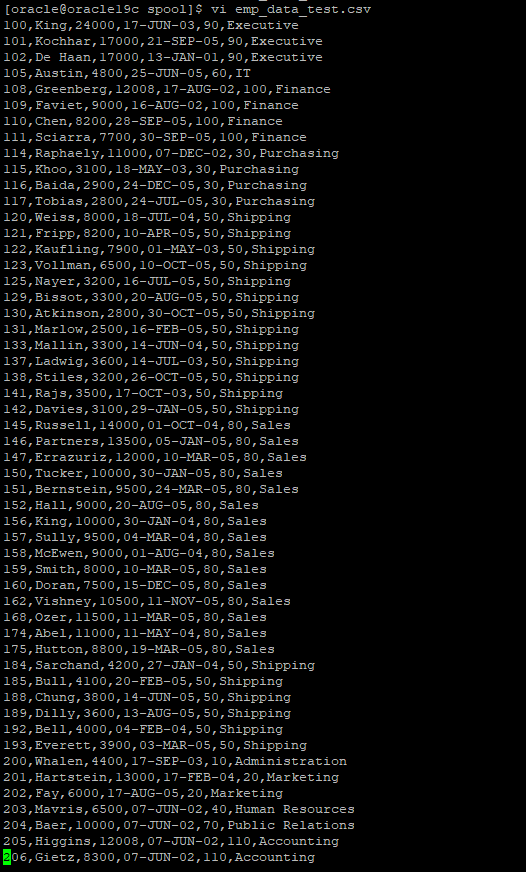
3.control 파일 작성
vi data_test.ctl
LOAD DATA
INFILE emp_data_test.csv
INSERT
INTO TABLE emp_before_2005
FIELDS TERMINATED BY ','
TRAILING NULLCOLS
(id,name,sal,day date 'yyyy-mm-dd',dept_id,dept_name)- 날짜로 매핑해야 하는 컬럼은 날짜 타입 지정하고 내가 지정한 포맷을 사용해야 한다.
- 다른타입은 알아서 매핑
4.데이터 이관
sqlldr hr/hr control=data_test.ctl
5.결과 확인
SELECT * FROM hr.emp_before_2005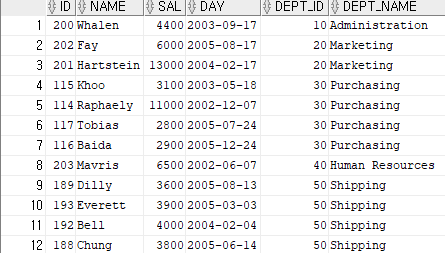
DBLINK
private database link 생성
- CREATE DATABASE LINK 시스템 권한이 있어야한다
public database link 생성
- CREATE PUBLIC DATABASE LINK 시스템 권한이 있어야한다.
dblink 구성
- tnsnames.ora → tns 구성을 해야한다
ORA19C =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.56.150)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = ORA19C)
)
)
- 접속이 잘되는지 확인
- database link 생성
CREATE PUBLIC DATABASE LINK DBLINK이름
CONNECT TO 접속유저 IDENTIFIED BY 패스워드
USING 'TNS이름';
CREATE PUBLIC DATABASE LINK ora19c_hr --dblink 이름
CONNECT TO hr IDENTIFIED BY hr --접속하려는 user and 비밀번호
USING 'ora19c'; -- 접속하고자 하는 tns이름- 생성한 DBLINK 확인
SELECT * FROM all_db_links;
- DBLINK을 통해서 테이블 access
SELECT * FROM employees@ora19c_hr; -- 19c의 hr이 가지고 있는 테이블을 불러옴
DBLINK 삭제
DROP PUBLIC DATABASE LINK DBLINK이름;
