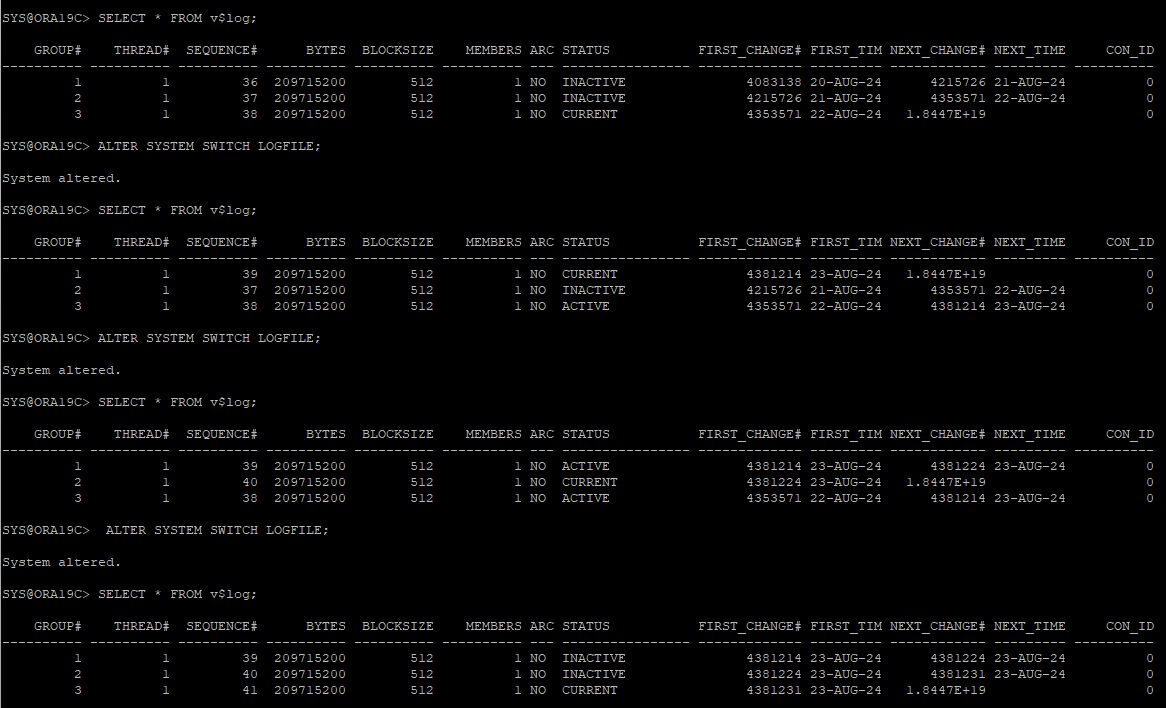
data file 헤더에는 start scn과 stop scn이 있는데 정상적인 db 종료에는 종료시점의 checkpoint scn 번호가 입력되고 start scn과 stop scn이 동일하다.
그리고 다시 db open을 하게 되면 datafile 헤더의 start scn은 종료 scn이 그대로 들어있고 stop scn은 무한으로 설정되어있다.
noarchive 시나리오 1
특정한 파일이 손상(백업이후에 리두가 있다) 완전복구 가능
1. checkpoint, current redo-log group 확인
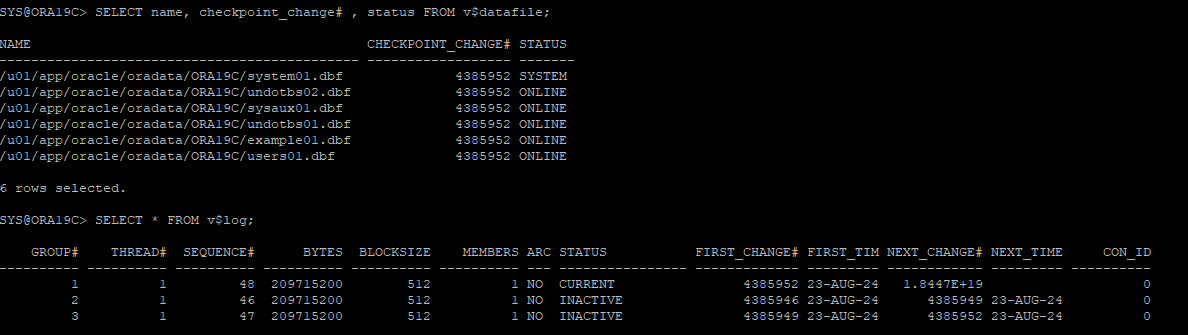
2. DDL, DML 작업으로 redo-log 데이터 추가
- redo-log 파일에는 데이터가 commit 될때의 scn 정보도 있다.
3. 정상적으로 DB SHUTDOWN 후 데이터파일 삭제

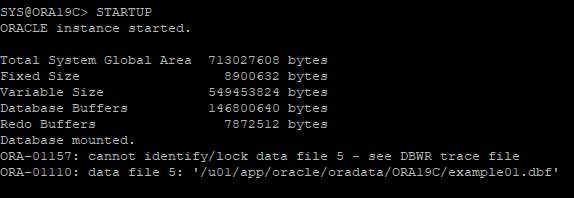
4. DB STARTUP 하면 데이터파일을 찾을수 없어 MOUNT 단계에서 멈춤
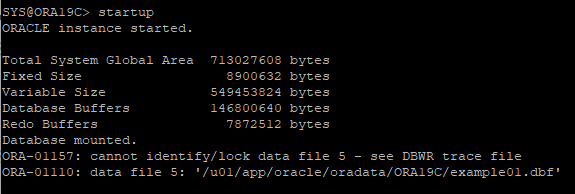
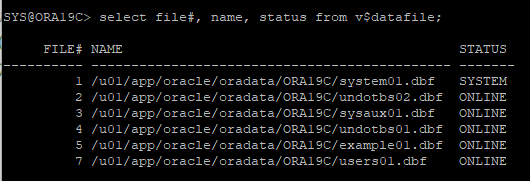
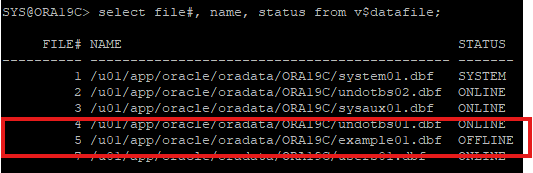
5. 손상된 데이터파일 확인
v$recover_file : 현재 손상된 file이 어떤건지 확인하는 뷰

v$datafile 뷰를 통해 데이터파일 확인
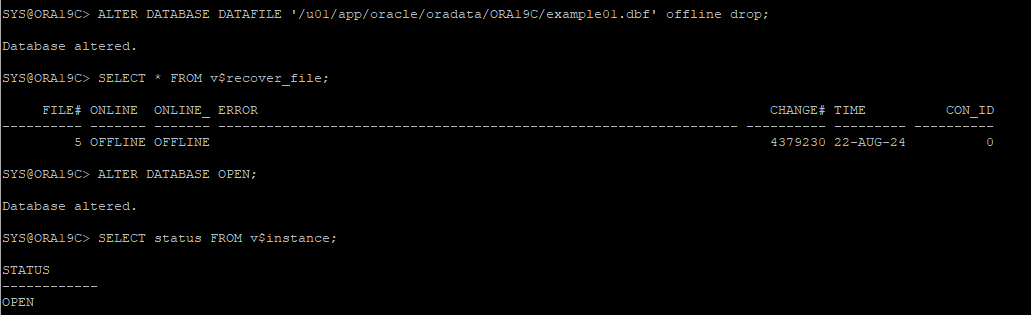
6. 손상된 데이터파일 offline 상태로 변경후 DB OPEN
- noarchive log mode에서는 특정한 데이터파일을 offline 모드로 수행할 경우 꼭 offline drop으로 해야한다.
ALTER DATABASE DATAFILE 오류데이터파일번호 offline drop;

- offline 변경 확인

- DB OPEN
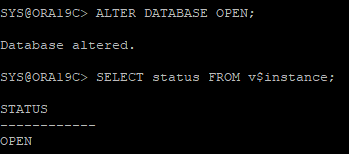
7. RESTORE
- 가장 최근에 받아놓은 백업본을 이용해서 restore 한다.

8. REDO를 이용한 완전복구
recover datafile 손상데이터파일번호;
또는
recover tablespace 손상된 테이블스페이스 이름;
또는
ALTER DATABASE RECOVER DATAFILE 파일번호 or 파일주소;

- 복구를 하였기 때문에 손상된 파일이 없다.

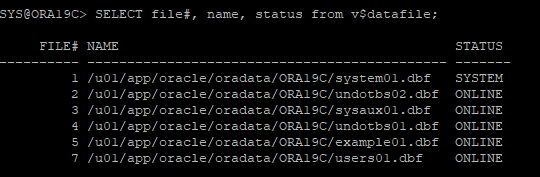
9. recover 한 데이터파일 online으로 변경
-
offline 데이터파일 online으로 변경

-
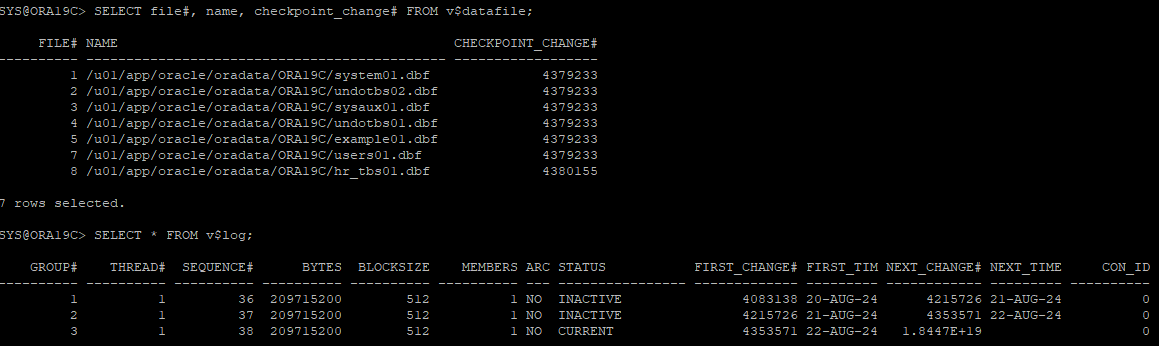
데이터파일 상태 확인
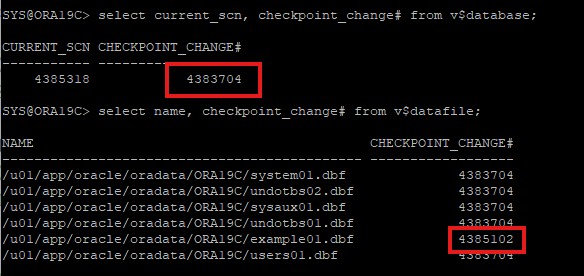
- redo를 통해서 데이터파일을 복구하였지만 복구된 데이터파일의 checkpoint는 새로 갱신되지 않고 이전 checkpoint 정보를 가지고 있다.
noarchive 시나리오 2
특정한 데이터 파일이 손상(백업이후에 리두 정보가 없을경우)
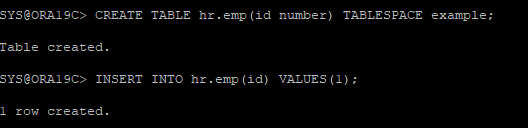
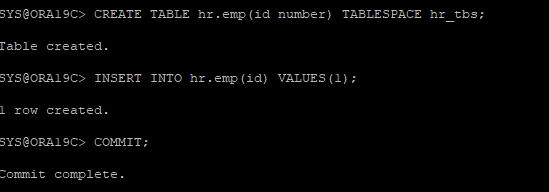
1. 새로운 테이블 생성 후 데이터 삽입
CREATE TABLE hr.emp(id number) TABLESPACE example;
INSERT INTO hr.emp(id) VALUES(1);
COMMIT;2. log switch를 통한 checkpoint 발생으로 redo 정보 overwrite
3. DB SHUTDOWN 후 데이터파일 삭제

4. DB STARTUP
- 손상된 데이터파일 때문에 MOUNT 단계에서 멈춤
5. 손상된 데이터파일 offline으로 변경 후 DB OPEN
6. 손상된 데이터파일의 최근 백업본을 이용해서 restore

7. 리두정보를 이용한 RECOVER (불가)
-
완전 복구가 될 생 각으로 recover 실행

- 마지막 백업 이후에 리두 정보를 이용해서 복구 작업을 시도 하려고 하는데 이미 리두로그는 로그스위치가 발생해서 변경된 정보들이 전부 없어져있다.
- noarchive log mode의 단점은 로그 스위치가 발생하면 리두 정보가 overwrite가 되어 버리기 때문에 완전복구를 할 수 없다. -
아카이브 파일이 없기 때문에 auto를 해도 실패를 한다.

-
noarchive log mode에서 완전 복구를 할 수 없으면 컨트롤파일, 데이터파일, 리두로그 파일 전부를 restore 해야한다.
-
해결방법으로는 clone db에 백업파일을 통해 복구 한뒤 필요한 데이터파일만 export 한뒤 운영db에 import 하는 작업을 해야한다.
noarchive 시나리오 3
백업 받지 않은 테이블스페이스 손상(리두정보가 있을 경우)
1. 테이블스페이스 생성

2. 데이터파일 checkpoint 확인
3. 테이블 생성(신규 테이블스페이스) 및 데이터 삽입
- 해당 과정에서 DDL, DML이 발생하여 REDO ENTRY가 만들어져 COMMIT 시 리두로그 파일에 저장된다.
- 리두로그 파일에는 해당 시점에 대한 SCN이 기록된다.
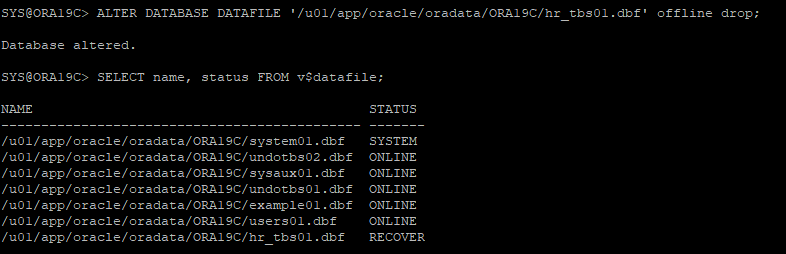
4. 백업 받지 않은 데이터파일 삭제(신규 테이블스페이스)

5. recover 할 데이터파일 offline 변경
- 오프라인 상태여야지만 recover 할 수 있다.
- noarchive log mode에서는 반드시 drop을 작성해야 한다. 안하면 오류 발생
- 논리적으로는 offline 하지만 물리적으로는 데이터파일이 없기 때문에 recover 상태(offline이랑 똑같다)
6. 백업본이 없는 손상된 데이터파일에 대해서 물리적인 파일을 생성
- 빈 데이터파일 생성(restore 하는거랑 같은 원리)
ALTER DATABASE CREATE DATAFILE '데이터파일주소' or 파일번호;

7. 비어있는 데이터 파일에 recover
- 리두로그 파일에 저장되어 있는 데이터로 복구한다.

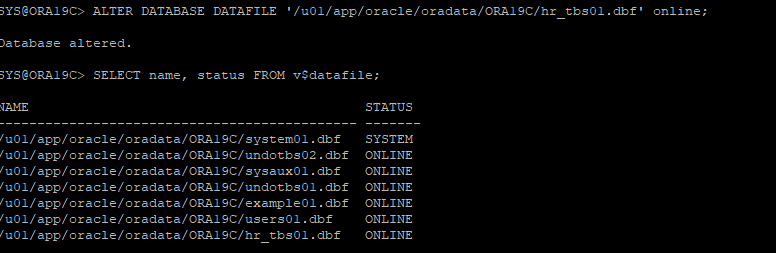
8. offline 상태인 데이터파일 online으로 변경
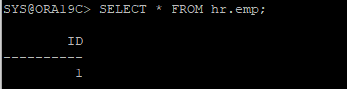
- 데이터가 정상적으로 조회된다
noarchive 시나리오 4
백업받지 않은 테이블스페이스 손상(리두정보가 없을 경우)
1. 테이블스페이스 생성
2. 데이터파일 checkpoint 확인
3. 테이블 생성(신규 테이블스페이스) 및 데이터 삽입
- 해당 과정에서 DDL, DML이 발생하여 REDO ENTRY가 만들어져 COMMIT 시 리두로그 파일에 저장된다.
- 리두로그 파일에는 해당 시점에 대한 SCN이 기록된다.
4. log switch를 통한 checkpoint 발생으로 redo 정보 overwrite
- log switch를 통해 redo 파일이 덮어씌어져 이전 redo가 없어졌다.
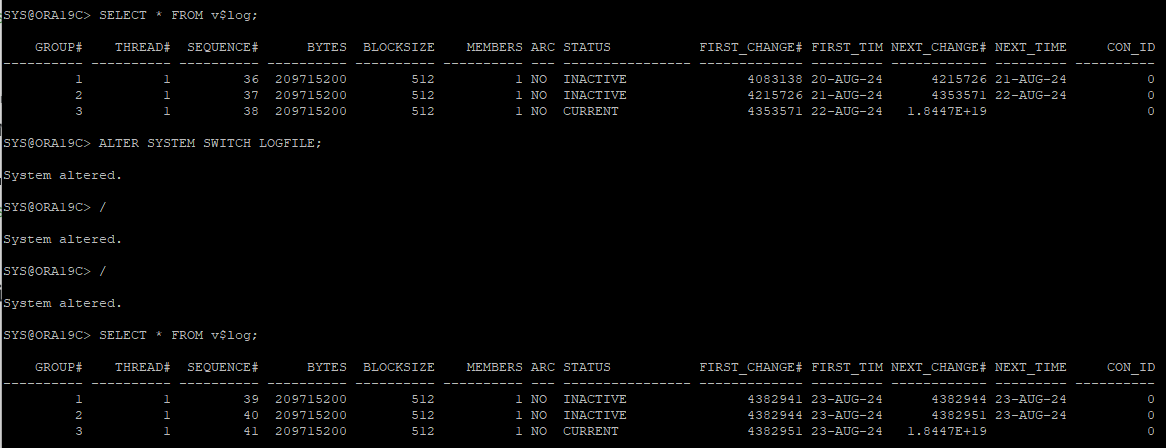
5. 백업 받지 않은 데이터파일 삭제(신규 테이블스페이스)
6. recover 할 데이터파일 offline 변경
- 오프라인 상태여야지만 recover 할 수 있다.
- noarchive log mode에서는 반드시 drop을 작성해야 한다. 안하면 오류 발생
- 논리적으로는 offline 하지만 물리적으로는 데이터파일이 없기 때문에 recover 상태(offline이랑 똑같다)
7. 백업본이 없는 손상된 데이터파일에 대해서 물리적인 파일을 생성
- 빈 데이터파일 생성(restore 하는거랑 같은 원리)
ALTER DATABASE CREATE DATAFILE '데이터파일주소' or 파일번호;
8. 리두정보를 이용한 RECOVER(불가)
- 완전 복구가 될 생 각으로 recover 실행
- 하지만 복구에 필요한 시퀀셜 38번의 REDO 데이터파일이 없기 때문에 복구 불가

9. 손상된 데이터파일 online으로 변경 시도
- offline으로 변경된 손상된 데이터파일은 recover 전까지는 online으로 변경이 안된다.

10. 손상된 데이터파일이 있는 테이블스페이스 삭제 시도
- recover을 시도했던 데이터파일이 있는 테이블스페이스는 삭제도 안된다.
- 프로세스가 내부적으로 꼬였기 때문이다.

11. DB 재로딩 후 삭제
- 손상있는 데이터 파일은 offline 상태이기 때문에 정상적인 DB종료를 해도 checkpoint가 저장되지 않는다.
- 정상적으로 테이블스페이스가 삭제된다.
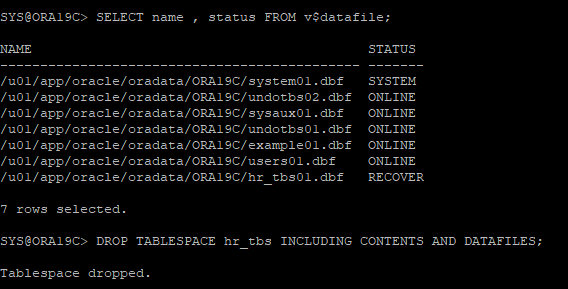
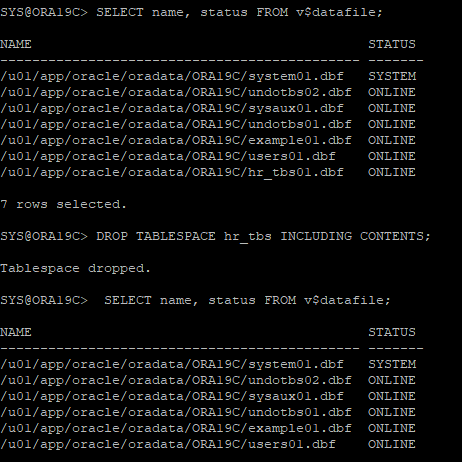
noarchive 시나리오 5
백업 받지 않은 테이블스페이스 삭제
5-1. recover 해야하는 redo 파일이 없어진걸 바로 알았을때
- 데이터파일을 offline으로 내리지도 말고 테이블스페이스를 삭제한다.
noarchive 시나리오 6
시스템 데이터파일 손상
1. 데이터 체크포인트, 로그 파일 확인
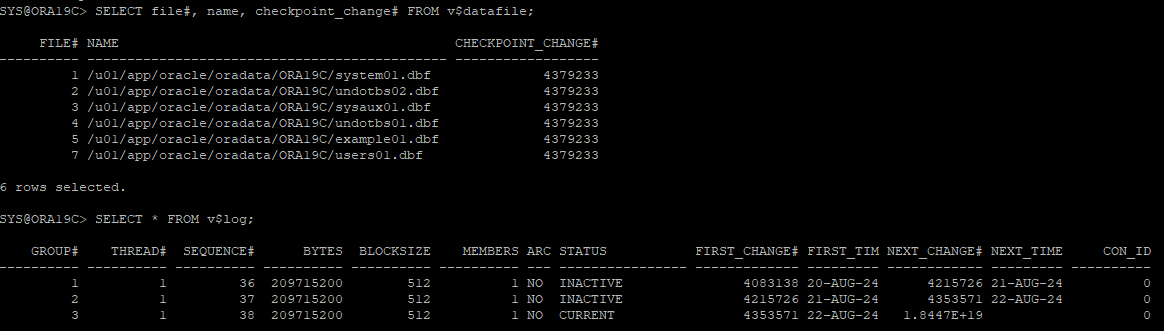
2. 시스템 데이터파일 삭제

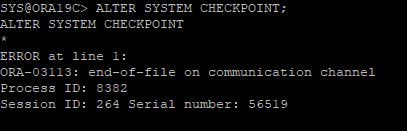
3. ALTER SYSTEM CHECKPOINT
- checkpoint를 유발해 데이터파일 헤더에 checkpoint 정보가 저장되는지 확인해보았다.
- 데이터파일이 없기 때문에 오류가 발생
- 하지만 DDL, DML 작업 후 반응이 즉각적으로 될수도 있고 안될수도 있다..
4. DB DOWN
- DB가 자동으로 내려갔다.
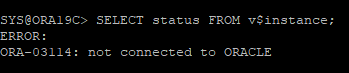
5. DB 재로딩
- 시스템 데이터 파일이 없기 때문에 MOUNT 단계까지만 된다.
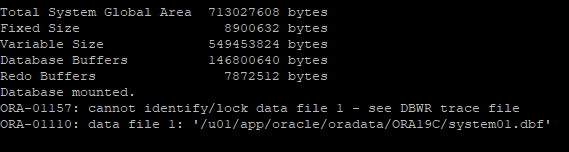
6. 시스템 데이터파일 recover
- 시스템 데이터파일은 offline으로 못내린다.
- 시스템 데이터파일 복구는 mount 단계에서 해야한다.
-
최근의 백업받은 system 데이터파일 restore 하기

-
백업이후에 변경정보를 이용해서 복구작업 recover(리두적용)

noarchive 시나리오 7
undo datafile 손상(리두 정보가 있을 경우) 완전복구 작업
1. checkpoint 정보 및 log 파일 정보 확인
SELECT a.file#, b.name tbs_name, a.name file_name, a.status, a.checkpoint_change#
FROM v$datafile a, v$tablespace b
WHERE a.ts# = b.ts#;
SELECT * FROM v$log;

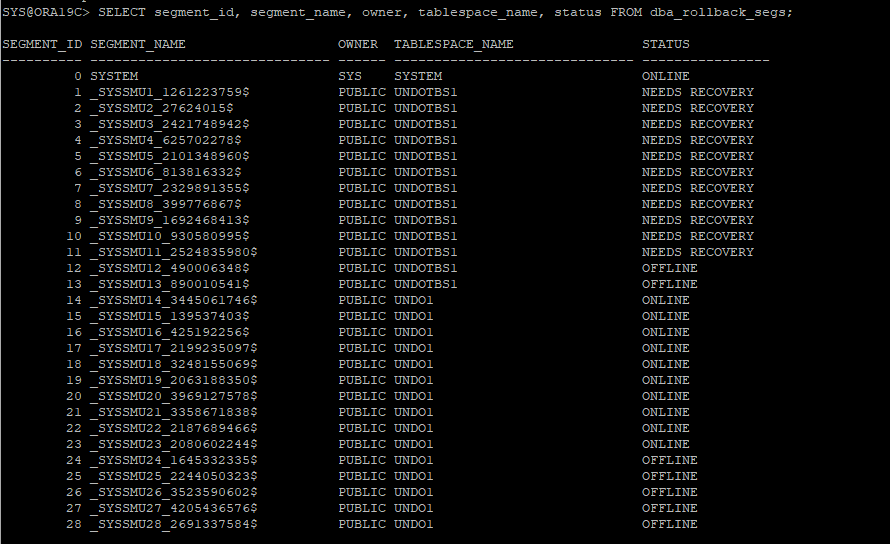
2. undo segments 정보 확인
select segment_id , segment_name, owner, tablespace_name, status
from dba_rollback_segs;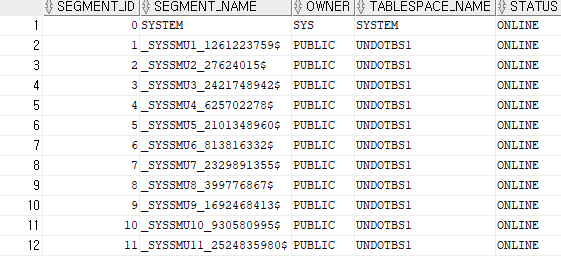
hr session
3. UPDATE를 통한 transaction 유발
UPDATE hr.employees SET salary = salary*1.1 WHERE employee_id = 100;sys session
4. transaction 확인
SELECT s.username, s.sid, s.serial#, r.name, t.xidusn, t.ubafil, t.ubablk, t.used_ublk
FROM v$session s, v$transaction t, v$rollname r
WHERE s.taddr = t.addr
AND t.xidusn = r.usn;
- 어느 유저에서 유입된 트랜잭션인지 확인할 때 사용된다.
- xidusn : undo segment 번호
- ubafil : 데이터파일 번호
- ubablk : undo block 번호
- used_ublk : undo block 사용 갯수
5. UNDO 파일을 삭제해 장애유발

6. CEHCKPOINT 유발
- 체크포인트를 강제 유발했는데 파일을 삭제해서 오류가 나면서 DB연결 끊김
- system과 undo는 장애나면 크리티컬하므로 DB가 내려감
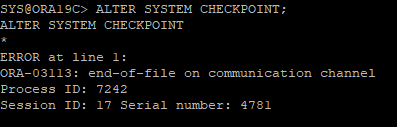
7. DB 재로딩 후 오류발생
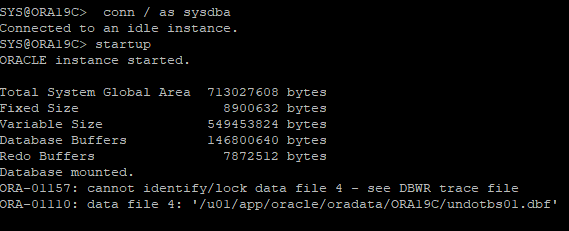
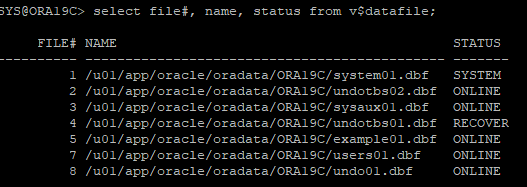
8. recover 해야할 파일 확인 및 데이터파일 상태 확인
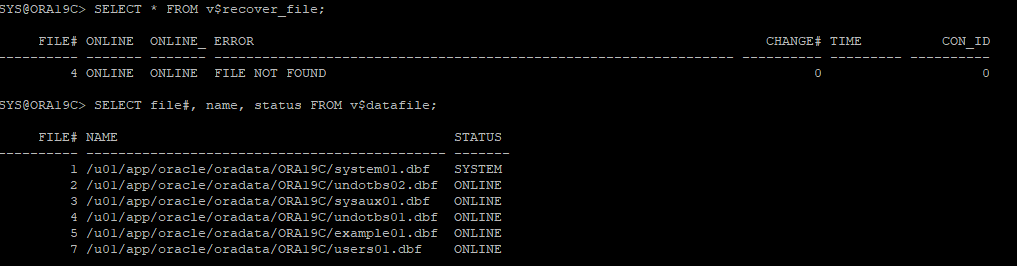
- undo 데이터파일이 online으로 나와있지만 실제로는 online 상태는 아니다.
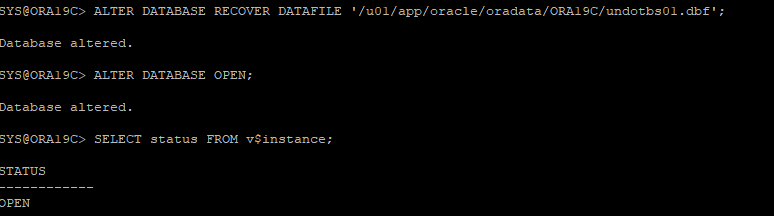
9. 가장 최근 백업본 restore 작업

10. 손상된 데이터파일 recover 후 DB OPEN
- 백업 이후에 변경 정보를 적용(redo적용)
redo가 있어서 Media recovery complete.라는 문구가 출력되며 완전한 복구가 가능
noarchive 시나리오 8
undo datafile 손상(리두 정보가 없을 경우)
- 새로운 undo 테이블스페이스를 생성해서 지정하면 해결할 수 있다.
1. checkpoint 정보 및 log 파일 정보 확인
SELECT a.file#, b.name tbs_name, a.name file_name, a.status, a.checkpoint_change#
FROM v$datafile a, v$tablespace b
WHERE a.ts# = b.ts#;
SELECT * FROM v$log;
2. undo segments 정보 확인
select segment_id , segment_name, owner, tablespace_name, status
from dba_rollback_segs;
hr session
3. UPDATE를 통한 transaction 유발
UPDATE hr.employees SET salary = salary*1.1 WHERE employee_id = 100;sys session
4. transaction 확인
SELECT s.username, s.sid, s.serial#, r.name, t.xidusn, t.ubafil, t.ubablk, t.used_ublk
FROM v$session s, v$transaction t, v$rollname r
WHERE s.taddr = t.addr
AND t.xidusn = r.usn;
- 어느 유저에서 유입된 트랜잭션인지 확인할 때 사용된다.
- xidusn : undo segment 번호
- ubafil : 데이터파일 번호
- ubablk : undo block 번호
- used_ublk : undo block 사용 갯수
5. log switch를 발생시켜 redo 정보 overwrite
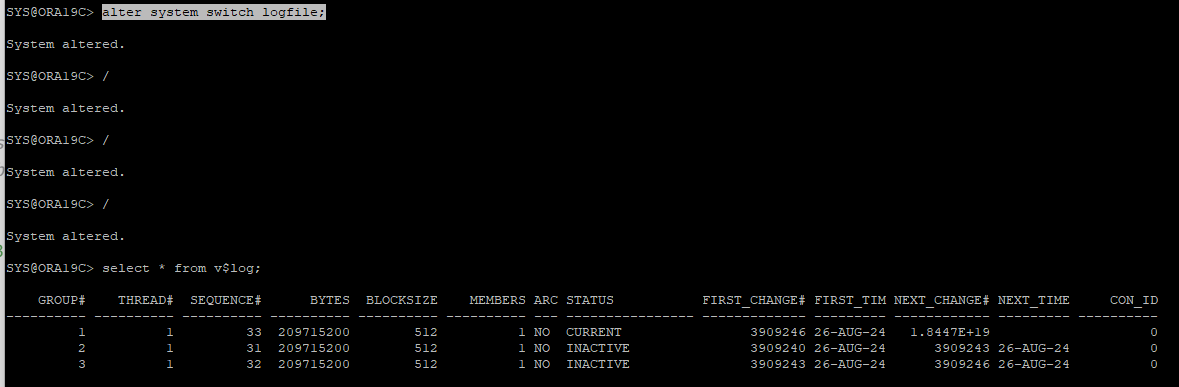
6. undo 데이터파일을 삭제해 장애유발

7. CHECKPOINT 유발 후 DB SHUTDOWN
- shutdown immediate 를 하면 오류가 난뒤 DB가 끊어진다.
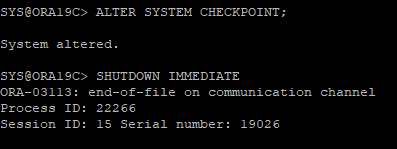
8. 재연결후 DB STARTUP 후 오류발생
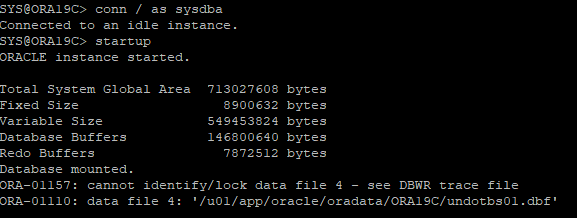
9. recover 파일 확인 및 데이터파일 상태 확인
- 오류발생한 undo 데이터파일이 online으로 조회되지만 실제로는 online상태가 아니다
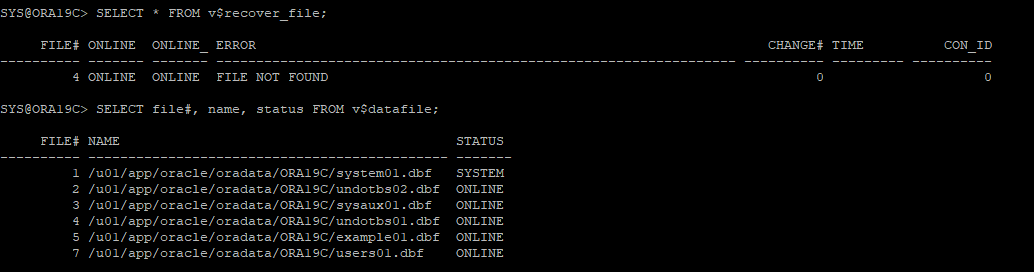
10. 가장 최근에 받아놓은 백업파일 restore 작업

11. 손상된 UNDO 데이터파일에 대한 RECOVER 작업 수행
- recover하려하였지만 필요한 redo데이터가 이미 오버라이트 되어 완전한 복구 실패

12. 손상된 UNDO 데이터파일 OFFLINE상태로 변경 후 DB OPEN
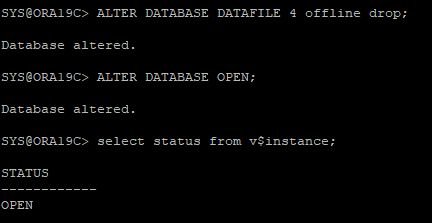
13. 데이터 파일 상태 확인
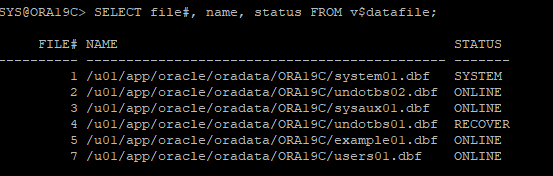
14. dml 시도
- undo가 없기때문에 조회는 되지만 dml작업은 할 수 없다.
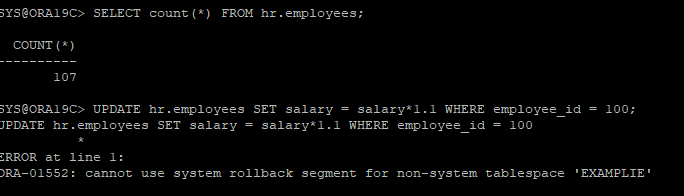
15. 새로운 undo 테이블스페이스 생성
- 불완전한 복구를 하기위해 데이터 파일들을 전부 붓는 건 비효율적이므로 undo 테이블스페이스만 만들어서 붙여주기 위해 undo 테이블스페이스 생성

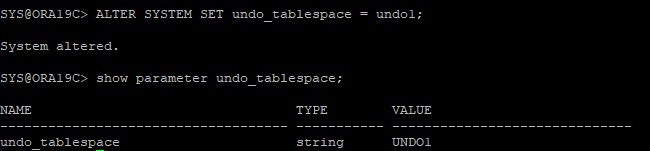
16. undo_tablespace 파라미터 설정
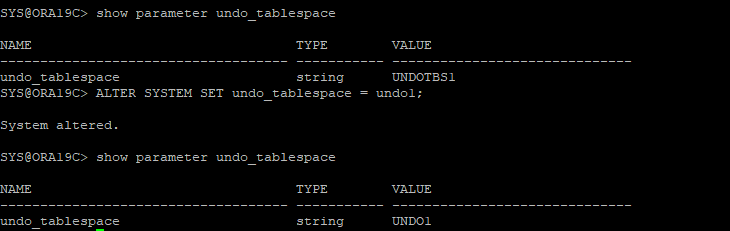
17. undo segments 확인
- 기존 테이블스페이스는 offline상태이고 새롭게 설정한 테이블스페이스가 online상태가 되었다.
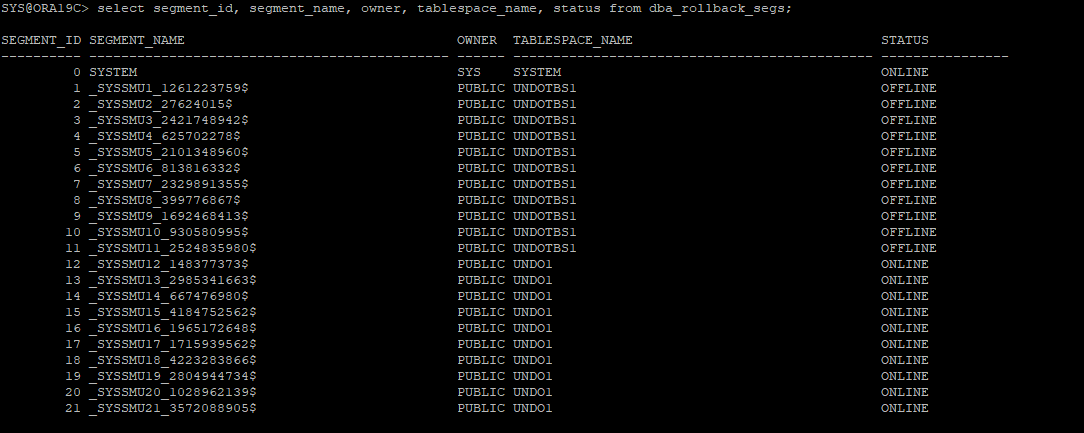
- undo 테이블스페이스는 두개이상 갖고 있을 필요가 없으므로 새롭게 만들고 지정해준 undo 테이블스페이스 말고 문제가 발생한 undo 테이블스페이스 drop후 잘 됐는지 확인
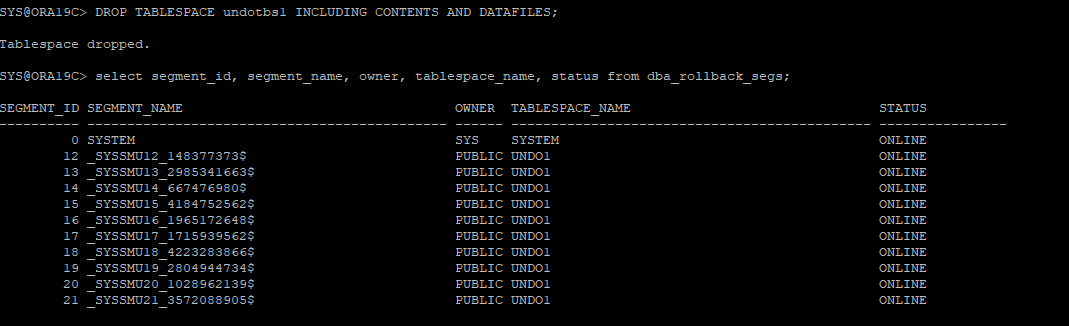
noarchive 시나리오 9
NEEDS RECOVERY 상태의 UNDO 테이블스페이스
- undo datafile 손상, transaction이 진행중인 상태에서 undo datafile이 손상되었고, 새로운 undo 테이블 스페이스를 생성해서 해결했다. 하지만 손상되기 전에 active undo에 속한 데이터를 access하게 되면 문제가 발생하고 기존 undo 테이블 스페이스를 삭제하려고 하는데 삭제가 안되는 오류가 발생한다.
1. checkpoint 정보 및 log 파일 정보 확인
SELECT a.file#, b.name tbs_name, a.name file_name, a.status, a.checkpoint_change#
FROM v$datafile a, v$tablespace b
WHERE a.ts# = b.ts#;
SELECT * FROM v$log;
2. undo segments 정보 확인
select segment_id , segment_name, owner, tablespace_name, status
from dba_rollback_segs;
hr session
3. UPDATE를 통한 transaction 유발
UPDATE hr.employees SET salary = salary*1.1 WHERE employee_id = 100;sys session
4. transaction 확인
SELECT s.username, s.sid, s.serial#, r.name, t.xidusn, t.ubafil, t.ubablk, t.used_ublk
FROM v$session s, v$transaction t, v$rollname r
WHERE s.taddr = t.addr
AND t.xidusn = r.usn;
- 어느 유저에서 유입된 트랜잭션인지 확인할 때 사용된다.
- xidusn : undo segment 번호
- ubafil : 데이터파일 번호
- ubablk : undo block 번호
- used_ublk : undo block 사용 갯수
5. undo 데이터파일을 삭제해 장애유발
6. CEHCKPOINT 유발
- 체크포인트를 강제 유발했는데 파일을 삭제해서 오류가 나면서 DB연결 끊김
- system과 undo는 장애나면 크리티컬하므로 DB가 내려감
7. DB 재로딩 후 오류발생
8. recover 해야할 파일 확인 및 데이터파일 상태 확인
- undo 데이터파일이 online으로 나와있지만 실제로는 online 상태는 아니다.
9. 손상된 UNDO 데이터파일 OFFLINE으로 변경 후 DB OPEN
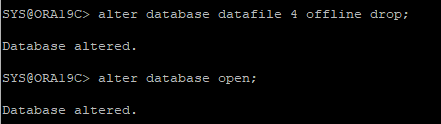
10. 데이터 확인

- 이전 HR 세션은 끊기고 새로운 HR세션으로 조회할때 100번사원의 이전값은 예전 undo 데이터파일에 있어서 새로운 CR 블록을 못만들기 때문에 조회 할 수가 없다.
- acctive undo가 필요한 행을 조회 할때 오류
- 기존 undo tablespace를 삭제할때도 오류
11. 새로운 UNDO 테이블스페이스 생성 후 undo_tablespace 파라미터 설정
create undo tablespace undo1 datafile '/u01/app/oracle/oradata/ORA19C/undo01.dbf' size 10m autoextend on;

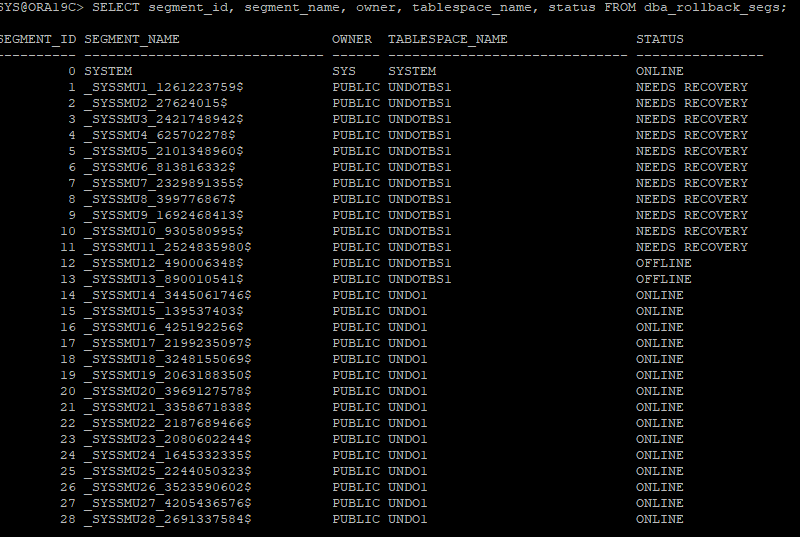
12. UNDO SEGMENT 딕셔너리뷰 확인
- 이전 언두 테이블스페이스가 NEEDS RECOVERY 상태가 되어있다.
13. NEEDS RECOVERY 테이블스페이스 삭제 시도
- 물리적으로는 undotbs1 데이터파일이 삭제되었지만 논리적으로는 undotbs1 테이블스페이스에 데이터가 있기 때문에 삭제가 안된다.

14. 수동으로 오프라인 상태 만들기
- needs recovery 상태인 언두 세그먼트 이름 추출
SELECT segment_name || ','
FROM dba_rollback_segs
WHERE status = 'NEEDS RECOVERY';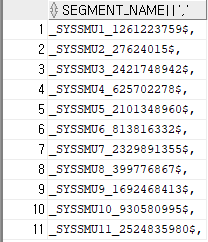
- 현재 초기파라미터를 반영한 pfile 만들기
CREATE PFILE FROM SPFILE
- DB SHUTDWON 후에 vi로 pfile에 해당 명령어 추가
_offline_rollback_segments=(
_SYSSMU1_1261223759$,
_SYSSMU2_27624015$,
_SYSSMU3_2421748942$,
_SYSSMU4_625702278$,
_SYSSMU5_2101348960$,
_SYSSMU6_813816332$,
_SYSSMU7_2329891355$,
_SYSSMU8_399776867$,
_SYSSMU9_1692468413$,
_SYSSMU10_930580995$,
_SYSSMU11_2524835980$)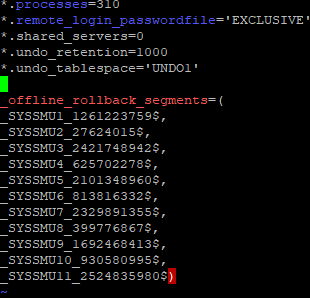
- DB를 pfile로 OPEN 후 UNDO 세그먼트 확인
- 아직 needs recovery 상태로 남아있지만 drop tablespace하면 정상적으로 삭제된다.
15. 오프라인된 이전 UNDO 테이블스페이스 삭제

- 이후에는 정상적으로 employee_id = 100번의 데이터가 조회된다.
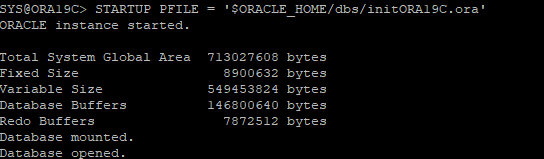
16. DB SHUTDOWN 후 SPFILE로 DB START UP
- 원복할때는 undo tablespace 기존 udnotbs1로 설정해주고 shut down 후 백업파일로 전체 restore 해주면 된다.
noarchive 시나리오 10
temp file 손상 복구
1. 템프파일 삭제로 장애유발

2. hr세션에서 쿼리문 조회
SELECT employee_id, salary FROM hr.employees ORDER BY 2 desc;PGA메모리에서 소트작업을 할 용량이 되기 때문에 가능하다.
- 일부러 PGA메모리에 부하를 주기 위해 카테시안곱을 이용한 쿼리문을 던지기
SELECT s.*, b.*
FROM all_objects s, all_objects b
ORDER BY 1,2,3,4;
해당 쿼리문에만 문제가 생길 뿐 다른 문제는 없기때문에 세션에 영향을 주지는 않는다.
PGA에서 소트작업이 temp 데이터파일로 다이렉트로 내려가는데 temp 데이터파일이 없기때문에 오류가 발생한다.
3. 현재 temp 디폴트 확인하고 테이블스페이스 확인
SELECT property_value
FROM database_properties
WHERE property_name = 'DEFAULT_TEMP_TABLESPACE';
SELECT name FROM v$tempfile;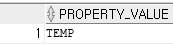

4. 해결방법 - temp file 추가
alter tablespace temp add tempfile '/u01/app/oracle/oradata/ORA19C/temp02.dbf' size 10m;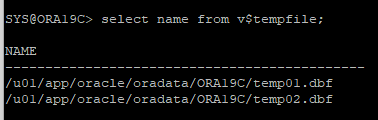
5. 물리적으로 삭제된 데이터파일 논리적으로 삭제
alter tablespace temp drop tempfile '/u01/app/oracle/oradata/ORA19C/temp01.dbf';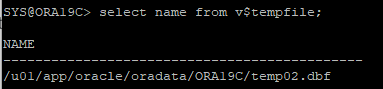
6. 혹시 drop이 안되는 경우에는 이전 temp파일을 세션이 잡고 있기 때문이다.
select b.tablespace, b.segfile#, b.segblk#, b.blocks, a.sid, a.serial#, a.username
from v$session a, v$sort_usage b
where a.saddr = b.session_addr;조회되는 세션이 있다면 kill 시켜주면 된다.
alter system kill session 'sid,serial#' immediate;7. hr세션에서 다시 쿼리문 시도
SELECT s.*, b.*
FROM all_objects s, all_objects b
ORDER BY 1,2,3,4;
다시 오류가 발생하는데 이번 오류는 temp file의 크기가 작게 구성되어 있어서 temp segment를 확장할 수 없어서 생기는 오류이다.
8. temp 크기때문에 생기는 오류 해결방법
1) temp file 크기조정
alter database tempfile '/u01/app/oracle/oradata/ORA19C/temp02.dbf' resize 100m;2) 자동확장기능 활성화
alter database tempfile '/u01/app/oracle/oradata/ORA19C/temp02.dbf' autoextend on;
3) temp file 추가
alter tablespace temp add tempfile '/u01/app/oracle/oradata/ORA19C/temp01.dbf' size 10m autoextend on;
noarchive 시나리오 11
temp file 손상되었을 경우 새로운 temp tablespace를 생성하고 default tablespace로 지정
실습환경
select name from v$tempfile;
select tablespace_name , contents from dba_tablespaces;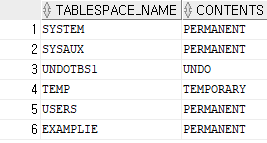
1. 장애유발
! rm /u01/app/oracle/oradata/ORA19C/temp01.dbf
! rm /u01/app/oracle/oradata/ORA19C/temp02.dbf- tip : 네이밍이 똑같고 번호만 다를 경우 /u01/app/oracle/oradata/ORA19C/temp{01,02}.dbf 중괄호를 이용하면 된다.
2. hr세션에서 쿼리문 조회
일부러 PGA메모리에 부하를 주기 위해 카테시안곱을 이용한쿼리문을 던지기
SELECT s.*, b.*
FROM all_objects s, all_objects b
ORDER BY 1,2,3,4;
해당 쿼리문에만 문제가 생길 뿐 다른 문제는 없기때문에 세션에 영향을 주지는 않는다.,
PGA에서 소트작업이 temp 데이터파일로 다이렉트로 내려가는데 temp 데이터파일이 없기때문에 오류가 발생한다.
3. 해결방법
1) 새로운 temporary 테이블스페이스 생성
create temporary tablespace temp_new tempfile '/u01/app/oracle/oradata/ORA19C/temp_new01.dbf' size 10m autoextend on;2) 디폴트 temporary로 설정
ALTER DATABASE default temporary tablespace temp_new;- 변경된 값 조회
SELECT property_value
FROM database_properties
WHERE property_name = 'DEFAULT_TEMP_TABLESPACE'; 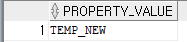
select username, temporary_tablespace from dba_users;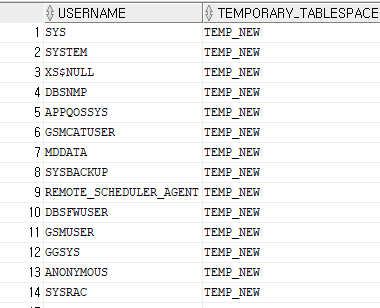
3) 물리적으로 삭제된 temp 테이블스페이스 논리적으로 삭제
drop tablespace temp including contents and datafiles;
해당 오류가 발생 - 원인은 세션이 삭제하려는 temp 테이블스페이스를 잡고 있기 때문이다
원인 세션을 킬 해주면 된다.
ALTER SYSTEM KILL SESSION 'sid,serial#' immediate;
다시 한번 템프 데이터파일 확인해보기
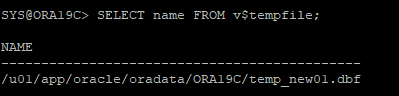
noarchive 시나리오 12
DB 종료 후에 DB OPEN 시점에 temp file 체크하고 없으면 새롭게 생성한 후 DB OPEN 한다.
실습 확인 view
SELECT name FROM v$tempfile;
SELECT property_value
FROM database_properties
WHERE property_name = 'DEFAULT_TEMP_TABLESPACE';1. db shutdown immediate
2. temp파일 삭제
3. DB startup 하고 alert.log 확인

- 오라클이 템프 데이터파일이 없는걸 확인후 자동으로 템프 데이터파일을 생성한다.
4. temp 파일 생성확인
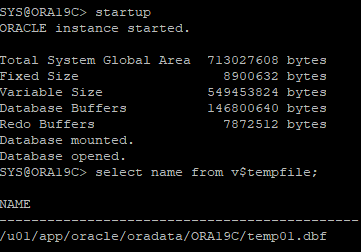

- temp01.dbf는 분명 삭제하였는데 자동으로 생성되어있다.
- recreating 해서 생기는 temp 데이터파일은 control 파일에 설정되어있는 temp 설정값 그대로 만들어진다.
noarchive 시나리오 13
모든 데이터파일, 리두로그 파일, 컨트롤 파일이 있는 디스크 손상
- 백업 본 없이는 복구 불가하다.
1. PFILE 만들어놓기

2. 파일 확인
select name from v$datafile;
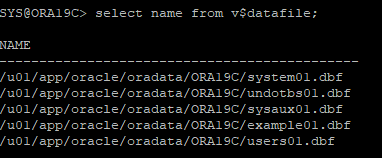
select name from v$tempfile;
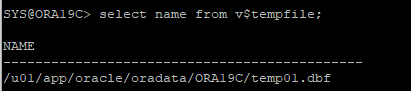
select name from v$controlfile;
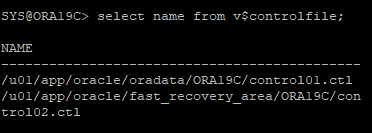
show parameter control_files
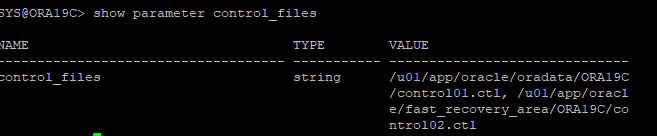
select member from v$logfile;
3. 전체 데이터파일이 삭제되었다고 가정

4. checkpoint 발생
alter system checkpoint;
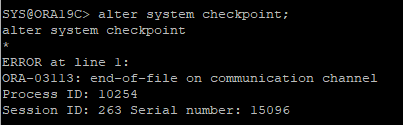
5. 다시 접속후 startup 하지만 오류 발생
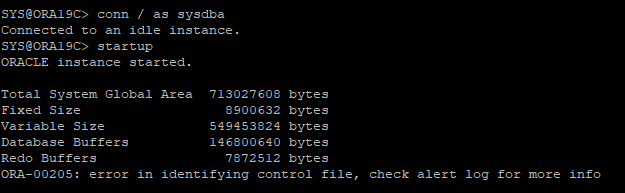
6.새로운 위치에서 복원하기 위해 oracle 홈에 ora_data 디렉토리 생성

7. 백업파일에 있는 데이터파일 전부 ora_data 디렉토리에 복사
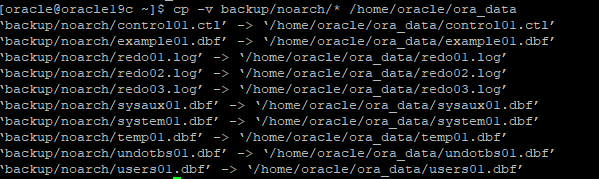
8. 초기파라미터 파일(PFILE)의 컨트롤 파일의 위치 정보 수정
-
이전 컨트롤 파일의 위치
*.control_files='/u01/app/oracle/oradata/ORA19C/control01.ctl','/u01/app/oracle/fast_recovery_area/ORA19C/control02.ctl' -
새로운 컨트롤 파일의 위치
*.control_files='/home/oracle/ora_data/control01.ctl' -
새로운 위치의 컨트롤파일 주소로 변경

9. pfile를 이용해서 데이터베이스를 mount까지 올려놓는다.
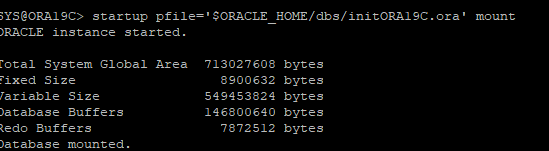
10. mount상태에서 딕셔너리 뷰를 조회하면 옛날 데이터가 조회된다.
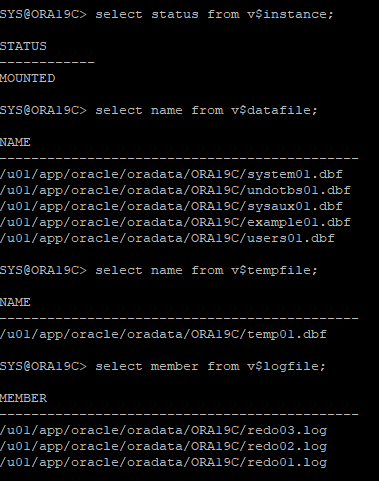
11. 데이터파일, 리두파일 RENAME 하기
alter database rename file '이전파일' to '새로운파일';
alter database rename file '/u01/app/oracle/oradata/ORA19C/system01.dbf' to '/home/oracle/ora_data/system01.dbf';
alter database rename file '/u01/app/oracle/oradata/ORA19C/undotbs01.dbf' to '/home/oracle/ora_data/undotbs01.dbf';
alter database rename file '/u01/app/oracle/oradata/ORA19C/sysaux01.dbf' to '/home/oracle/ora_data/sysaux01.dbf';
alter database rename file '/u01/app/oracle/oradata/ORA19C/example01.dbf' to '/home/oracle/ora_data/example01.dbf';
alter database rename file '/u01/app/oracle/oradata/ORA19C/users01.dbf' to '/home/oracle/ora_data/users01.dbf';
alter database rename file '/u01/app/oracle/oradata/ORA19C/temp01.dbf' to '/home/oracle/ora_data/temp01.dbf';
alter database rename file '/u01/app/oracle/oradata/ORA19C/redo01.log' to '/home/oracle/ora_data/redo01.log';
alter database rename file '/u01/app/oracle/oradata/ORA19C/redo02.log' to '/home/oracle/ora_data/redo02.log';
alter database rename file '/u01/app/oracle/oradata/ORA19C/redo03.log' to '/home/oracle/ora_data/redo03.log';12. DB OPEN 단계로 변경
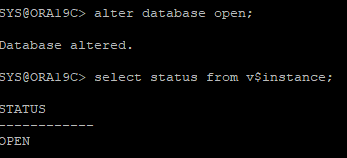
13. spfile 생성 후 DB spfile로 재로딩
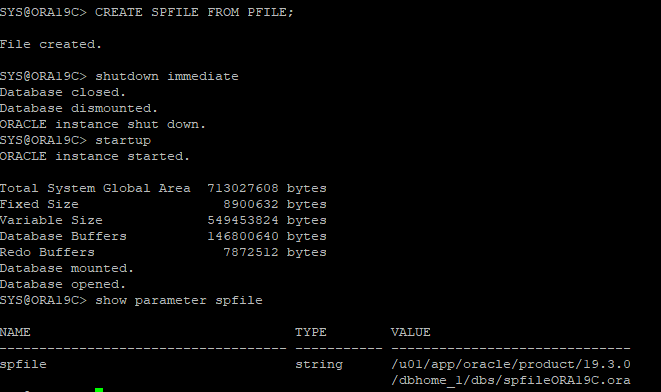
noarchive 시나리오 14
백업본에 redo log file이 없을때 복구 방식
1. DB shutdown immediate
2. 새로운 디렉터리 만들기
mkdir -p /home/oracle/backup/noarch/20240827
3. 새로 만든 디렉터리에 컨트롤, 데이터파일 백업

4. DB startup
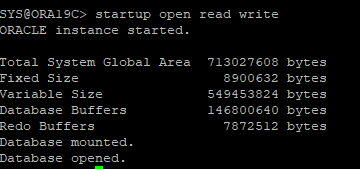
5. 테이블 생성
CREATE TABLE hr.new(id number) TABLESPACE examplie;
6. 데이터 삽입
INSERT INTO hr.new(id) VALUES(1);
COMMIT;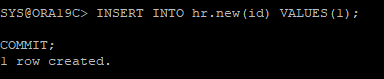
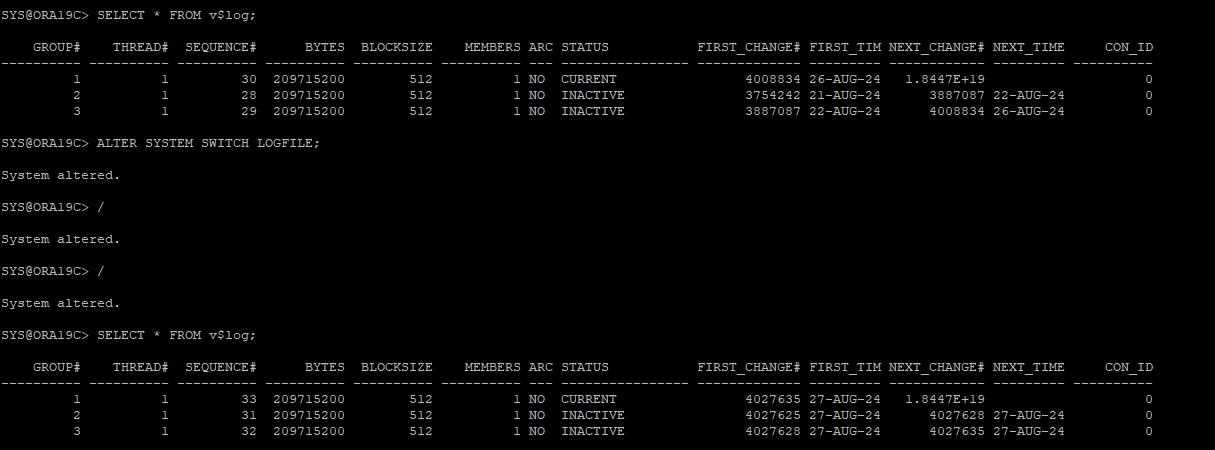
7. 수동으로 로그스위치 발동
8. DB immediate
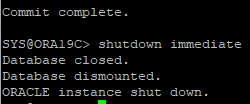
9. 데이터 파일 삭제로 장애 유발

10. DB STARTUP 하지만 오류 발생
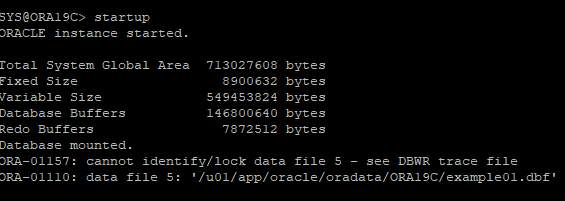
11. 손상된 데이터파일 offline으로 변경후 DB OPEN
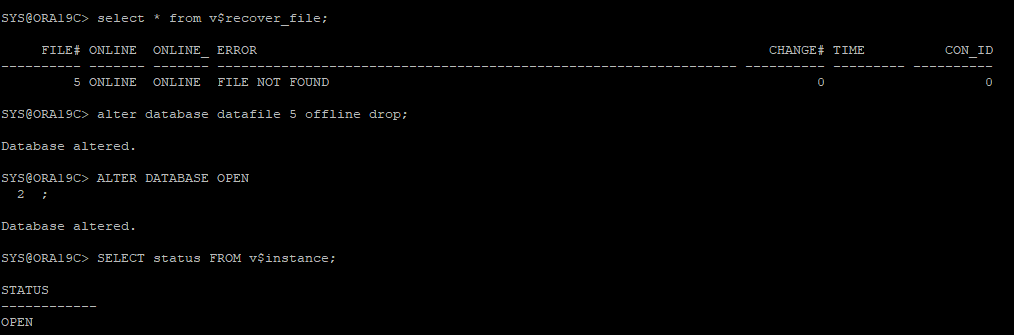
12. datafile 딕셔너리 뷰 확인
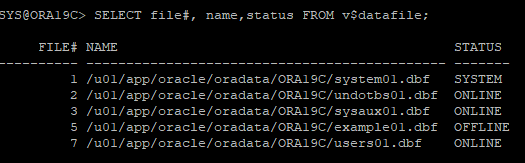
복구작업
13. 문제가 발생한 데이터 파일의 최근 백업본을 restore

14. OFFLINE으로 변경한 데이터파일 RECOVER
- REDO 정보가 LOG SWITCH로 없어졌기 때문에 recover를 할 수 없다.

15. DB SHUTDOWN abort

정보
control 파일은 redo log 파일의 시퀀셜 번호 정보를 가지고 있는데 backup본 control 파일은 이전 redo log 시퀀셜 번호 정보를 가지고 있기 때문에 현재의 redo log 시퀀셜 번호랑은 매핑이 안된다.
16. 이전 백업본의 데이터파일, 컨트롤 파일만 ORA19C 디렉터리로 restore, 리두는 현재 파일을 사용한다.

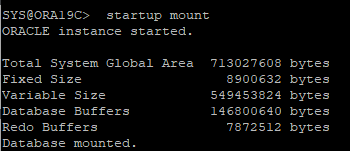
17. DB STARTUP mount
- control 파일의 정보와 redo log 파일의 정보가 불일치 하기 때문에 mount 단계까지만 실행한다.
18. 불안정한 백업, 백업 컨트롤 파일을 가지고 cancel base recovery 한다.
recover database until cancel using backup controlfile;
- cancel 이라고 입력하면 canel base recovery 한다는 의미이다.

19. DB OPEN을 하는데 resetlogs를 해야한다.
ALTER DATABASE OPEN RESETLOGS;
- 컨트롤 파일이 가지고 있는 과거 리두 시퀀셜 번호랑 현재 리두 시퀀셜 번호가 다르기 때문에 reset 해서 1번부터 다시 시작한다.

20. log 딕셔너리 뷰 확인
- 시퀀셜 번호가 1번부터 시작하는걸 알 수 있다.

noarchive 시나리오 15
datafile, redo log file은 손상되지 않고 control file만 손상되었을때 복구
1. datafile, control file, log 확인
SELECT b.file#, a.name as tbs_name, b.name as df_name, b.status, b.checkpoint_change#
FROM v$tablespace a, v$datafile b
WHERE a.ts# = b.ts#;
SELECT * FROM v$controlfile;
SELECT * FROM v$log;
2. 테이블 생성 후 데이터 삽입
3. DB shutdown immediate
4. control file 삭제로 장애유발

5. DB startup 하지만 오류 발생
- control file이 없기때문에 nomount 단계에서 mount 단계로 넘어갈 수 없다.
6. control file 파라미터 확인

7. DB shutdown abort

8. 가장 최근에 백업해놓은 control file의 백업본을 찾아 restore

과거의 백업 control file을 이용해서 복구작업
9. 과거의 control 백업본으로 DB startup mount
10. 과거의 control 백업본에 현재의 redo 정보를 이용하여 recover 한다.
recover database using backup controlfile
- auto로 recover 해달라고 해본다
- recover하려는 CURRENT한 REDO의 정보가 REDO 데이터파일에 있는데 오라클은 자동으로 아카이브 로그에서 찾으려고 해서 오류발생
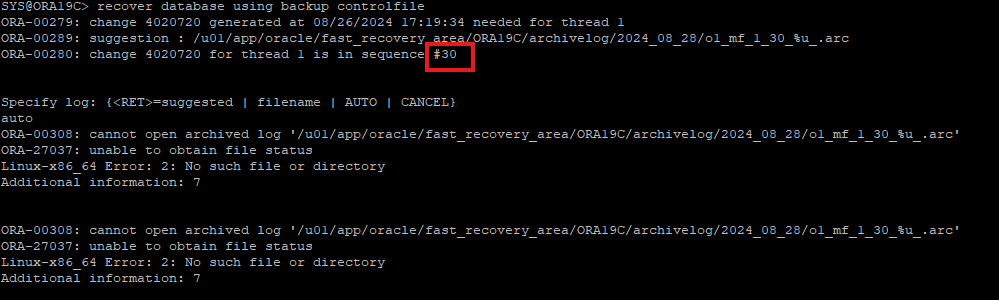
- 리두로그 정보 확인
SELECT a.group#, b.sequence#, a.member, b.bytes/1024/1024 MB, b.archived, b.status,b.first_time, b.next_time
FROM v$logfile a, v$log b
WHERE a.group# = b.group#
ORDER BY 1;
- control 파일이 가지고 있는 이전 리두로그 정보를 볼 수 있다.
11. control file의 recover을 다시 시도한다.
- control file에 현재 current한 redo의 파일 주소로 복구를 시도
- auto가 제대로 작동을 하지 않아 수동으로 해줘야 한다.

12. DATABASE를 OPEN으로 변경
- 단, 현재 redo log의 시퀀셜 번호랑 control file의 시퀀셜 번호를 맞췄다고 해도
NORESETLOGS옵션을 사용할 수 없다. - 어쩔수 없이
RESETLOGS옵션을 사용하여 DB OPEN을 하여야 하고 redo log의 시퀀셜 번호는 초기화 된다.
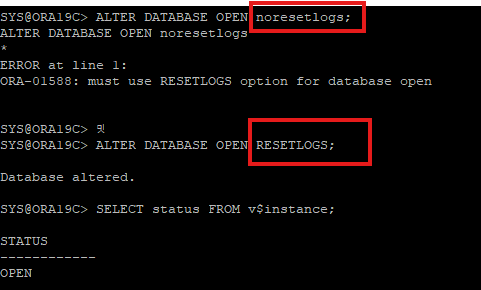

13. resetlogs를 통해 리두정보를 초기화 하였다면, 이전 백업 파일과는 매핑되지 않아 새롭게 whole backup 을 해야한다.
noarchive 시나리오 16
datafile, redo log file은 손상되지 않고 control file만 손상되었을때 control file를 재생성한 후 복구 방식(control file 백업 이후에 리두 정보가 없을경우 )
1. datafile, control file, log 확인
SELECT b.file#, a.name as tbs_name, b.name as df_name, b.status, b.checkpoint_change#
FROM v$tablespace a, v$datafile b
WHERE a.ts# = b.ts#;
SELECT * FROM v$controlfile;
SELECT * FROM v$log;
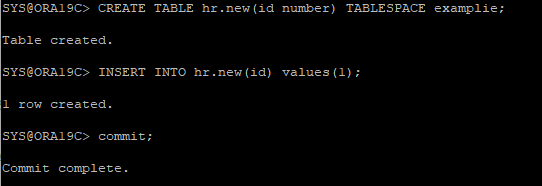
2. 테이블 생성 후 데이터 삽입
3. 수동으로 LOG SWITCH 유발해서 redo 정보 override
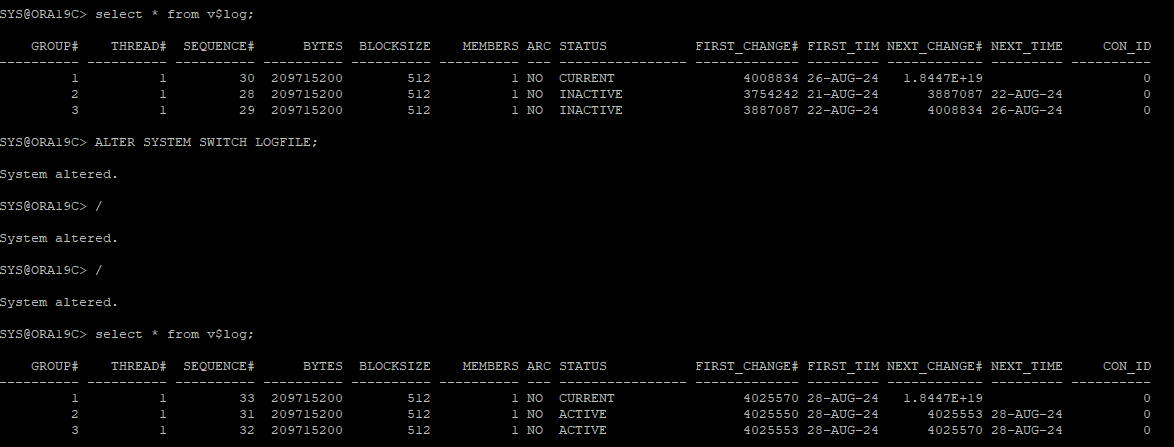
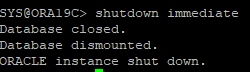
4. DB shutdown immediate
5. control file 삭제로 장애유발
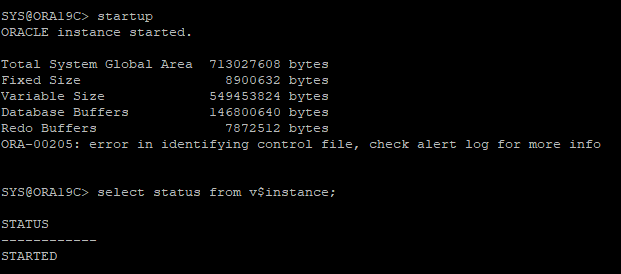
6. DB startup 하지만 오류 발생
- control file이 없기때문에 nomount 단계에서 mount 단계로 넘어갈 수 없다.
7. control file 파라미터 확인
8. DB shutdown abort
9. 가장 최근에 백업해놓은 control file의 백업본을 찾아 restore
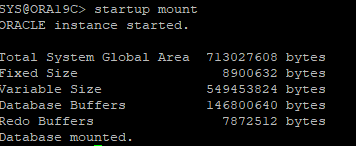
10. 과거의 control 백업본으로 DB startup mount
11. 과거의 control 백업본에 현재의 redo 정보를 이용하여 recover 시도
- 리두로그 정보 확인
SELECT a.group#, b.sequence#, a.member, b.bytes/1024/1024 MB, b.archived, b.status,b.first_time, b.next_time
FROM v$logfile a, v$log b
WHERE a.group# = b.group#
ORDER BY 1;recover database using backup controlfile
- 30번 시퀀셜의 리두 정보가 필요한줄 알고 30번 리두 파일 주소로 recover 하려고 하였지만 이미 현재 리두로그 파일은 override가 되어 30번 리두로그 정보는 없다.
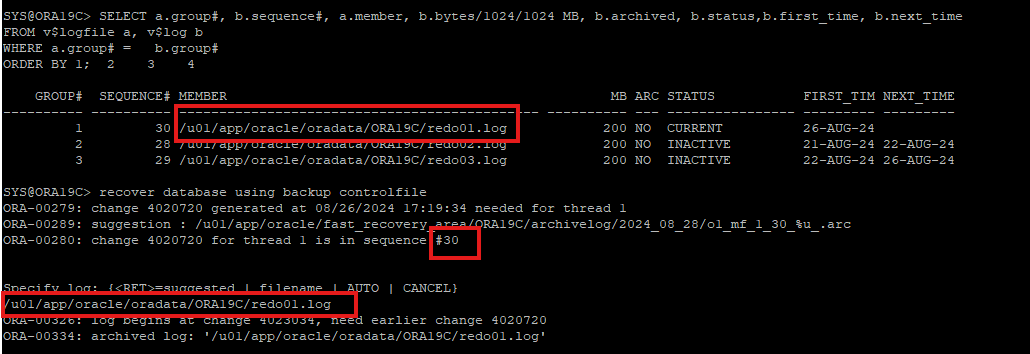
12. 백업 control file을 가지고 trace 파일 생성
control 파일을 재 생성해야 할때
1) DB 이름을 변경할때
2) CONTROL 파일이 깨졌을때
3) MAX 옵션을 변경해야 할때controlfile로 trace 파일을 만들어야 할때
1) tablespace 구조가 바뀔때
2) redolog 구조가 바뀔때
alter database backup controlfile to trace as '파일주소/파일이름.sql';

13. DB shutdown abort

14. vi 편집기로 생성한 trace file 편집
- 해당 구조로 만들어서 저장
- 주석은 다 삭제하고, noresetlogs noarchivelog 문만 사용한다.
- vi 편집기에서 현재 커서 아래를 전체 삭제 하는 명령어 : d + G
- max 옵션
MAXLOGFILES= 리두로그 그룹의 수
MAXLOGMEMBERS= 하나의 그룹당 설정할 수 있는 멤버의 수
MAXDATAFILES= 데이터베이스에서 생성할수 있는 데이터파일의 수
MAXINSTANCES= 하나의 데이터베이스당 설정할 수 있는 인스턴스의 수
MAXLOGHISTORY= 아카이브로그 파일을 생성할수 있는 수
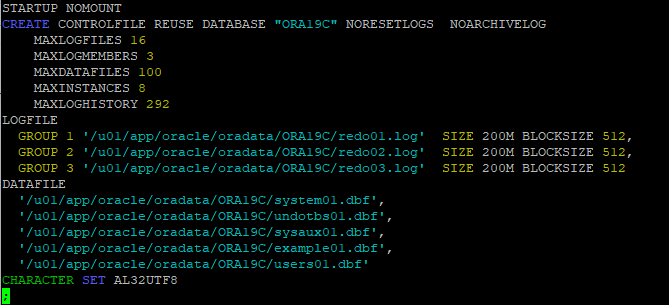
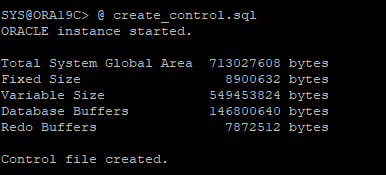
15. sqlplus 에서 trace 파일 실행
- 스크립트에 nomount 시작후 controlfile 만들었기 때문에 mount 상태
- 스크립트에서 control 파일을 재생성 하는거라 spfile의 control_files 파라미터에 설정된 control파일에 덮어씌우는 방식이다.
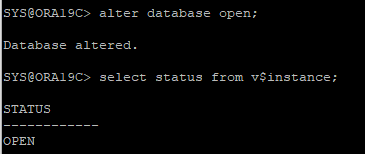
16. DB open으로 변경
- trace file안에서 생성한 control 파일에 현재 리두로그 파일 정보가 있기 때문에
noresetlogs로 open이 되었다. - 컨트롤파일 안에 있는 로그 시퀀셜번호랑 현재 로그파일의 시퀀셜 번호가 같기 때문이다.
17. temp 파일은 trace file에 control파일을 재생성 할때 정의되지 않았기 때문에 물리적으로는 데이터 파일이 있어도 논리적으로는 없어 조회되지 않는다.
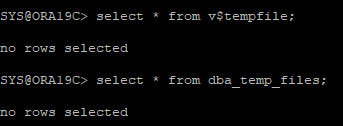
18. 컨트롤파일을 재생성 한 경우 꼭 temp 파일을 추가해줘야 한다.
ALTER TABLESPACE TEMP ADD TEMPFILE '/u01/app/oracle/oradata/ORA19C/temp01.dbf' REUSE;noarchive 시나리오 17
datafile, redo log file은 손상되지 않고 control file만 손상되었다. 비정상적인 종료 되었을 경우 control file를 재생성한 후 복구 방식(control file 백업 이후에 리두 정보가 없을경우 )
1. datafile, control file, log 확인
SELECT b.file#, a.name as tbs_name, b.name as df_name, b.status, b.checkpoint_change#
FROM v$tablespace a, v$datafile b
WHERE a.ts# = b.ts#;
SELECT * FROM v$controlfile;
SELECT * FROM v$log;
2. 테이블 생성 후 데이터 삽입
3. control 파일 삭제해서 장애유발

4. 백업 컨트롤 파일이 너무 오래되어서 리두파일이 로그스위치가 일어났을거라고 예상
- 원래대로라면 오류가 발생해야 하는데 원래세션에서는 감지가 안된다.(오라클의 버그)
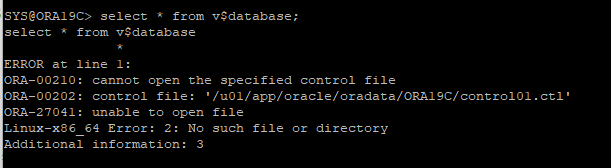
- 다른 세션에서 감지가 됬다.
5. DB shutdown abort
- DB를 불안정하게 종료

6. 가장 최근에 받아놓은 백업본 restore

7. DB startup 하지만 컨트롤 파일이 오래전꺼라 오류 발생
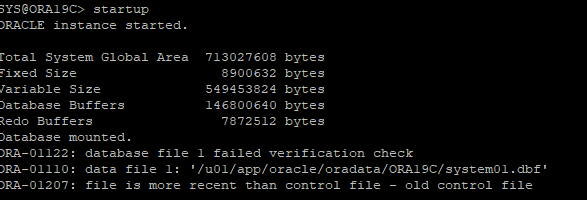
8. recover 하려고 하지만 오래전 백업 파일이라 redo는 이미 override 되었다고 가정
9. 백업 control file을 가지고 trace 파일 생성
control 파일을 재 생성해야 할때
1) DB 이름을 변경할때
2) CONTROL 파일이 깨졌을때
3) MAX 옵션을 변경해야 할때controlfile로 trace 파일을 만들어야 할때
1) tablespace 구조가 바뀔때
2) redolog 구조가 바뀔때
alter database backup controlfile to trace as '파일주소/파일이름.sql';
10. DB shutdown abort
11. vi 편집기로 생성한 trace file 편집
- 해당 구조로 만들어서 저장
- 주석은 다 삭제하고, noresetlogs noarchivelog 문만 사용한다.
- vi 편집기에서 현재 커서 아래를 전체 삭제 하는 명령어 : d + G
- max 옵션
MAXLOGFILES= 리두로그 그룹의 수
MAXLOGMEMBERS= 하나의 그룹당 설정할 수 있는 멤버의 수
MAXDATAFILES= 데이터베이스에서 생성할수 있는 데이터파일의 수
MAXINSTANCES= 하나의 데이터베이스당 설정할 수 있는 인스턴스의 수
MAXLOGHISTORY= 아카이브로그 파일을 생성할수 있는 수
12. sqlplus 에서 trace 파일 실행
- 스크립트에 nomount 시작후 controlfile 만들었기 때문에 mount 상태
- 스크립트에서 control 파일을 재생성 하는거라 spfile의 control_files 파라미터에 설정된 control파일에 덮어씌우는 방식이다.
13. DB open 하려고 하면 오류 발생
- db가 불안정하게 종료되었기 때문에 데이터파일의 체크포인트 수위가 맞지 않아 생기는 오류

14. recover database 해주면 된다.
- redo파일이 살아있기 때문에 instance reocovery 해준다.

15. 다시 open 하면 정상적으로 된다.
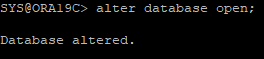
16. 데이터파일의 체크포인트 수위가 맞춰져 있다.
17. temp 파일은 trace file에 control파일을 재생성 할때 정의되지 않았기 때문에 물리적으로는 데이터 파일이 있어도 논리적으로는 없어 조회되지 않는다.
18. 컨트롤파일을 재생성 한 경우 꼭 temp 파일을 추가해줘야 한다.
ALTER TABLESPACE TEMP ADD TEMPFILE '/u01/app/oracle/oradata/ORA19C/temp01.dbf' REUSE;noarchive 시나리오 18
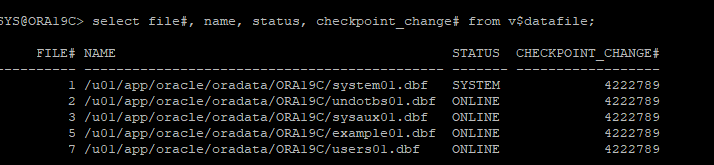
datafile, control file만 손상되었을 경우 복구(데이터베이스 정상적인 종료)
1. 테이블 생성 후 데이터 입력
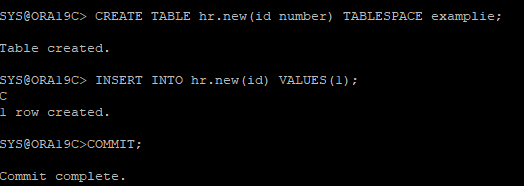
- 리두로그 정보도 확인
SELECT a.group#, b.sequence#, a.member, b.bytes/1024/1024 MB, b.archived, b.status,b.first_time, b.next_time
FROM v$logfile a, v$log b
WHERE a.group# = b.group#
ORDER BY 1;
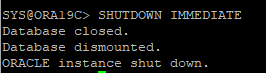
2. DB 정상종료
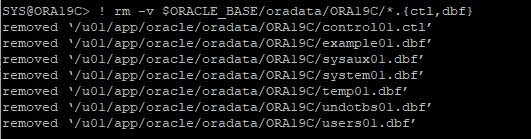
3. data file, control file 삭제로 장애 유발
4. db startup 하지만 오류 발생


5. db shutdown abort

6. 가장 최근의 data file, control file백업본 restore

7. 백업 control file을 이용해서 DB mount 단계까지 실행
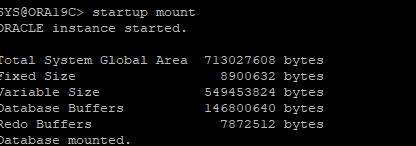
8. 백업 control file을 현재 redo 정보를 이용해서 recover 시도
- 리두파일에 컨트롤파일 복구에 필요한 시퀀셜 번호의 리두로그정보가 있다는 가정하에 진행
- 전체 데이터베이스에 대한 recover을 하기때문에 데이터파일도 이때 같이 recover 된다.
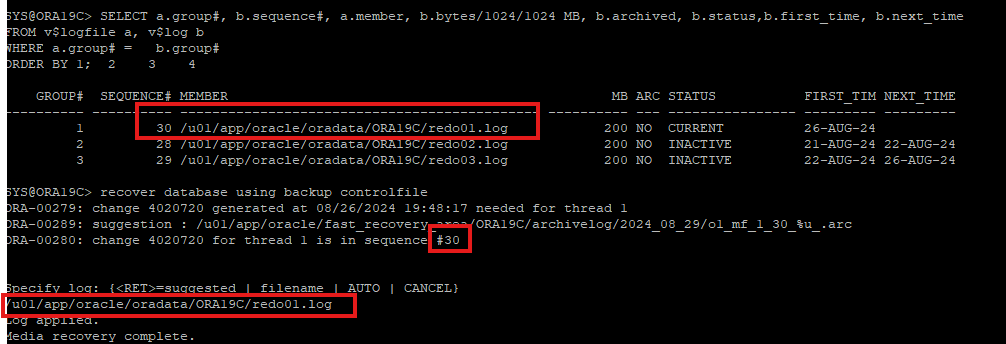
9. DB OPEN으로 변경
- 컨트롤파일에 현재 리두로그 정보랑 똑같이 recover 하였지만 오라클은
noresetlogs옵션을 허용하지 않는다.resetlogs옵션으로 실행해야한다.
noarchive 시나리오 19
datafile, control file만 손상되었을 경우 복구(데이터베이스 비상적인 종료)
1. 테이블 생성 후 데이터 입력
- 리두로그 정보도 확인
SELECT a.group#, b.sequence#, a.member, b.bytes/1024/1024 MB, b.archived, b.status,b.first_time, b.next_time
FROM v$logfile a, v$log b
WHERE a.group# = b.group#
ORDER BY 1;
2. 수동으로 로그스위치 발생
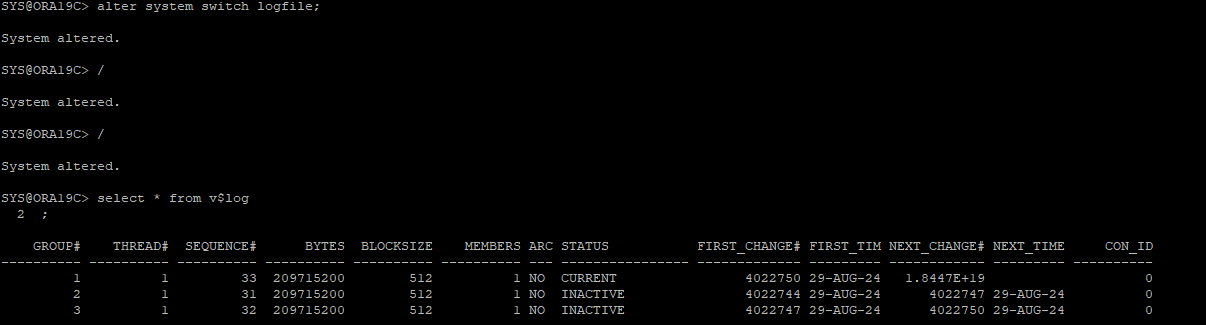
3. data file, control file 삭제로 장애유발

4. DB shutdown abort

5. 가장 최근의 data file, control file 백업본 restore
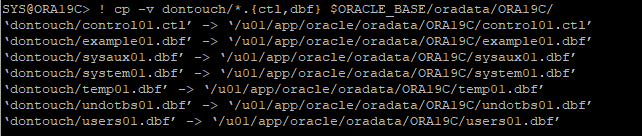
6. DB startup mount
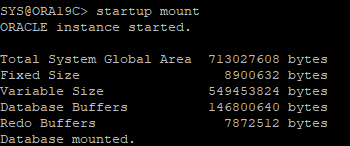
7. 컨트롤 파일이 필요한 리두의 정보와 현재 리두 정보의 갭이 있기 때문에 cancel base recovery 작업을 수행한다.
- 현재 컨트롤 파일은 30번 리두 정보가 필요하지만 현재 리두파일에는 override로 인해 30번 정보가 없기 때문에 cancel base recovery를 통해 30번까지만 recover 한다.

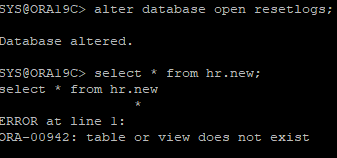
8. DB open resetlogs
- cancel base recovey로 과거 백업 데이터 파일 이기 때문에 만들었던 hr.new 테이블이 없다.
noarchive 시나리오 20
redo log file, control file만 손상되었을 경우 복구(데이터베이스 정상적인 종료)
1. 테이블 생성 후 데이터 입력
- 리두로그 정보도 확인
SELECT a.group#, b.sequence#, a.member, b.bytes/1024/1024 MB, b.archived, b.status,b.first_time, b.next_time
FROM v$logfile a, v$log b
WHERE a.group# = b.group#
ORDER BY 1;
2. DB 정상종료
3. redo log file, control file 삭제로 장애 유발


4. DB startup 하지만 오류 발생
5. DB shutdown abort
6. 가장 최근의 control file백업본 restore
- redo log 파일은 필수 백업이 아니고, redo log 파일이 없다면 자동으로 생성해준다.

7. 백업 control file을 이용해서 DB mount 단계까지 실행
8. 백업 control file을 이용해 trace파일 생성

9. DB shutdown abort

trace 파일에서 발췌
10. DB startup nomount
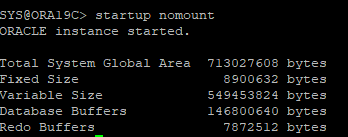
11. control file 재생성하기
- 리두파일이 없기 때문에 resetlogs로 설정해야한다.
- 재생성 되면서 db 상태는 mount 단계까지 올라간다.
CREATE CONTROLFILE REUSE DATABASE "ORA19C" RESETLOGS NOARCHIVELOG
MAXLOGFILES 16
MAXLOGMEMBERS 3
MAXDATAFILES 100
MAXINSTANCES 8
MAXLOGHISTORY 292
LOGFILE
GROUP 1 '/u01/app/oracle/oradata/ORA19C/redo01.log' SIZE 200M BLOCKSIZE 512,
GROUP 2 '/u01/app/oracle/oradata/ORA19C/redo02.log' SIZE 200M BLOCKSIZE 512,
GROUP 3 '/u01/app/oracle/oradata/ORA19C/redo03.log' SIZE 200M BLOCKSIZE 512
DATAFILE
'/u01/app/oracle/oradata/ORA19C/system01.dbf',
'/u01/app/oracle/oradata/ORA19C/undotbs01.dbf',
'/u01/app/oracle/oradata/ORA19C/sysaux01.dbf',
'/u01/app/oracle/oradata/ORA19C/example01.dbf',
'/u01/app/oracle/oradata/ORA19C/users01.dbf'
CHARACTER SET AL32UTF8
;12. DB open으로 변경
ALTER DATABASE OPEN RESETLOGS;
- mount 단계에서 open 단계로 올라갈때 redo log 파일을 여는데 물리적인 redo log파일이 없다면 자동으로 생성한다.
- redo log가 없기 때문에 resetlogs를 통해 리셋 시켜준다.

13. control 파일을 재 생성으로 하였기 때문에 temp파일은 따로 만들어줘야 한다.

noarchive 시나리오 21
redo log file, control file만 손상되었을 경우 복구(데이터베이스 비정상적인 종료)
1. 테이블 생성 후 데이터 입력
- 리두로그 정보도 확인
SELECT a.group#, b.sequence#, a.member, b.bytes/1024/1024 MB, b.archived, b.status,b.first_time, b.next_time
FROM v$logfile a, v$log b
WHERE a.group# = b.group#
ORDER BY 1;
2. redo file, control file 삭제로 장애유발
3. DB shutdown abort

4. 가장 최근의 data file, control file백업본 restore
- whole backup 파일을 restore 해도 되지만 redo 백업 파일은 없다는 가정
5. 백업 control file을 이용해서 DB mount 단계까지 실행
6. redo가 없어 control 파일이 가지고 있는 정보로만 recover 해야하기 때문에 cancel base recovery를 한다.

9. DB open resetlogs

shutdown abort 를 하면 data file들 끼리 checkpoint 수위가 안맞게 되어서 깨지게 되는데 이걸 다시 올릴때 만약 정상적인 리두 파일이 있다면 redo에 있는 checkpoint 정보를 가지고 자동으로 instance recovery를 해준다. 하지만 리두 로그 파일이 없다면 instance recovery를 해줄수 없기 때문에 data file을 restore 해줘야한다.
noarchive 시나리오 22
백업한 control file의 내용과 현재 datafile 정보가 달라졌을 경우 복구방식(데이터베이스 정상종료)
1. 새로운 테이블스페이스 생성
CREATE TABLESPACE data_tbs
DATAFILE '/u01/app/oracle/oradata/ORA19C/data01.dbf' size 5m
EXTENT MANAGEMENT local uniform size 64k
SEGMENT SPACE MANAGEMENT AUTO;2. 데이터파일 확인
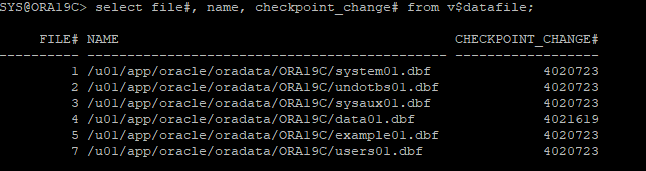
- data01.dbf 파일은 db open 후 생성하였기 때문에 checkpoint가 다르다
3. 테이블 생성 후 데이터 입력
-
새로 만든 테이블스페이스에 생성한다.
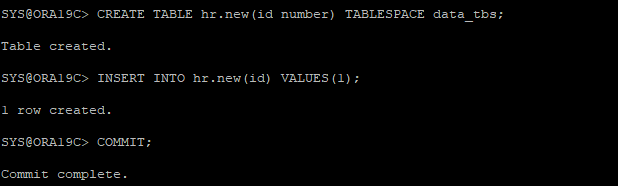
-
리두 정보 확인
SELECT a.group#, b.sequence#, a.member, b.bytes/1024/1024 MB, b.archived, b.status,b.first_time, b.next_time
FROM v$logfile a, v$log b
WHERE a.group# = b.group#
ORDER BY 1;
4. db 정상종료
5. 운영 컨트롤파일을 삭제 하여 장애유발

6. db startup 후 오류발생
7. db shutdown abort

8. 가장 최근의 control 백업파일 restore

9. DB startup mount
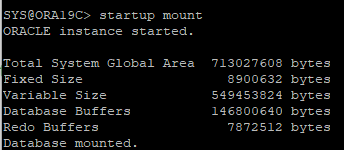
10. 과거 control 파일의 로그 정보, 데이터파일 정보 확인
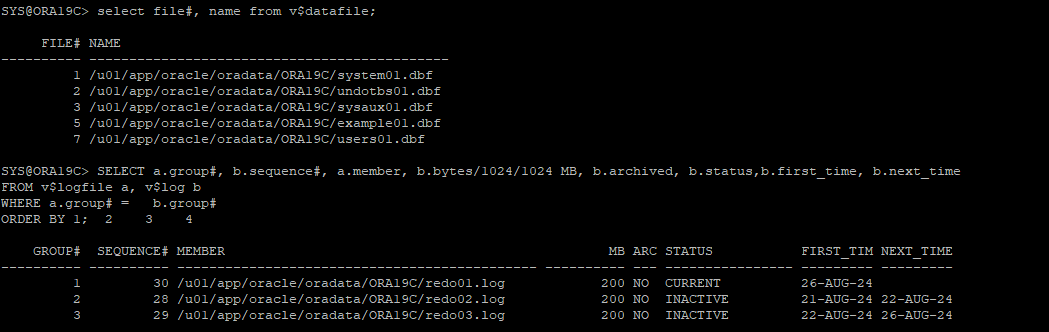
11. alter database open 시도
- 컨트롤 파일이 과거 백업본이라 현재 data file 과 redo log file의 scn과 맞지 않아 오류 발생

12. recover database using backup controlfile 시도
- 백업 컨트롤파일이 가지고 있던 데이터파일의 구성 정보와 원래 있었던 컨트롤파일의 데이터파일 구성정보가 맞지 않아 오류 발생
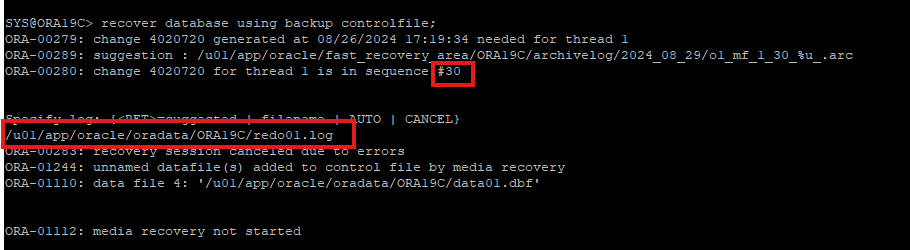
13. 백업 컨트롤파일로 trace 파일 생성
trace 파일 생성 시도를 recover을 시도한 뒤에 한 이유는 redo정보가 가지고 있는 원래의 컨트롤 파일의 정보가 있는데 백업 컨트롤 파일에는 정보가 없기 때문에 백업컨트롤 파일에 알수없는 이름의 데이터파일을 생성한다.

14. DB shutdown abort

trace 파일에서 발췌
15. startup nomount
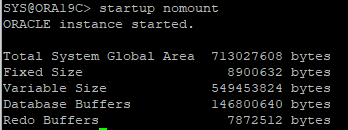
16. control file 재생성
- redo log 파일이 정상적으로 있기 때문에 noresetlogs 옵션
- 알수 없는 이름의 데이터파일 주소 수정해줘야한다.
CREATE CONTROLFILE REUSE DATABASE "ORA19C" NORESETLOGS NOARCHIVELOG
MAXLOGFILES 16
MAXLOGMEMBERS 3
MAXDATAFILES 100
MAXINSTANCES 8
MAXLOGHISTORY 292
LOGFILE
GROUP 1 '/u01/app/oracle/oradata/ORA19C/redo01.log' SIZE 200M BLOCKSIZE 512,
GROUP 2 '/u01/app/oracle/oradata/ORA19C/redo02.log' SIZE 200M BLOCKSIZE 512,
GROUP 3 '/u01/app/oracle/oradata/ORA19C/redo03.log' SIZE 200M BLOCKSIZE 512
DATAFILE
'/u01/app/oracle/oradata/ORA19C/system01.dbf',
'/u01/app/oracle/oradata/ORA19C/undotbs01.dbf',
'/u01/app/oracle/oradata/ORA19C/sysaux01.dbf',
/*'/u01/app/oracle/product/19.3.0/dbhome_1/dbs/UNNAMED00004' 이전에 recover을 시도 했기 때문에 redo가 만들어놓은 논리적인 주소이다.*/
'/u01/app/oracle/oradata/ORA19C/data01.dbf', -- 실제 주소로 수정해서 입력
'/u01/app/oracle/oradata/ORA19C/example01.dbf',
'/u01/app/oracle/oradata/ORA19C/users01.dbf'
CHARACTER SET AL32UTF8
;17. DB open
ALTER DATABASE OPEN;
18. temp 데이터파일 추가
ALTER TABLESPACE TEMP ADD TEMPFILE '/u01/app/oracle/oradata/ORA19C/temp01.dbf' REUSE;
