ARCHIVE 시나리오 1
DB 운영중에 offline되는 데이터 파일이 손상되어을때 복구 방식
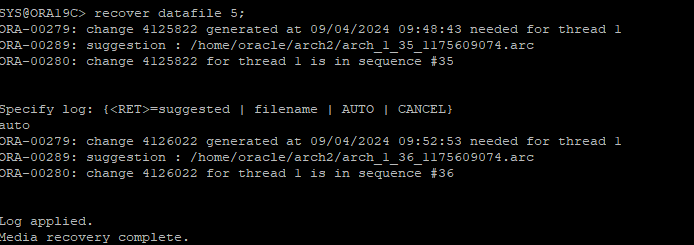
1. 가장 최근에 받아놓은 백업 정보 확인
- checkpoint_change# : 현재 데이터 파일의 체크포인트 SCN 번호
- change# : 백업시점의 체크포인트 SCN 번호
select a.name, a.checkpoint_change#, b.status, b.change#, to_timestamp(b.time)
from v$datafile a, v$backup b
where a.file# = b.file#;2. 마지막 백업 받은 시점의 SCN번호를 기준으로 현재 SCN번호 까지 리두 정보 확인
select a.group#,a.sequence#,b.member,a.status, first_change#, next_change#
from v$log a , v$logfile b
where a.group#=b.group#;
select sequence#,name, first_change#, next_change# from v$archived_log;
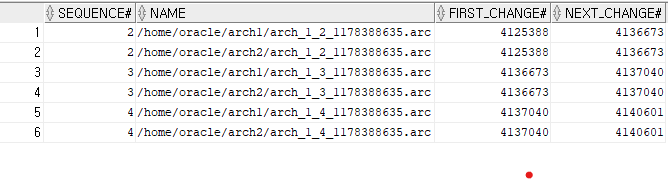
3. archive log file이 물리적으로 있는지 체크

4. 테이블 생성 후 데이터 입력
5. 데이터파일 삭제로 장애 유발

6. 다이렉트방식으로 create 해보기
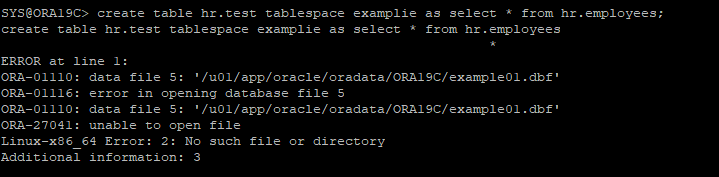
- examplie 테이블스페이스 데이터 파일이 존재하지 않기 때문에 오류발생
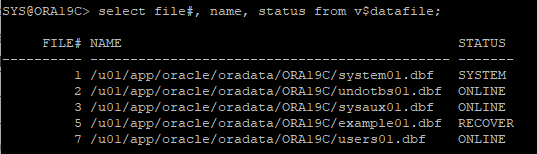
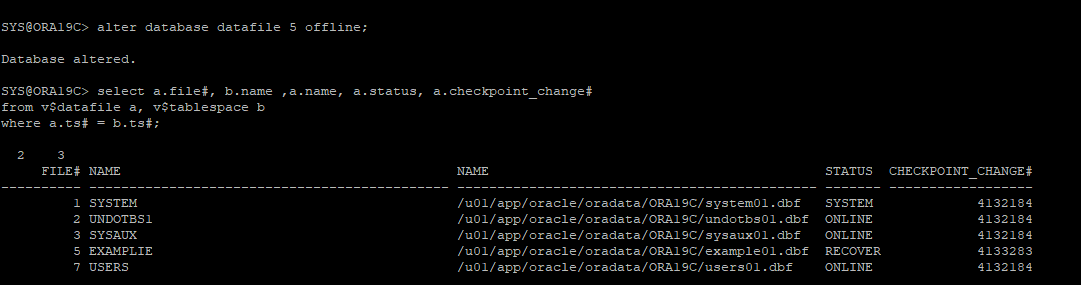
7. 데이터파일 상태 확인
select a.file#, b.name ,a.name, a.status, a.checkpoint_change#
from v$datafile a, v$tablespace b
where a.ts# = b.ts#;
복구 진행
8. 손상된 테이블스페이스를 offline으로 변경
alter tablespace 테이블스페이스이름 offline [normal | temporary | immediate]
noraml : 체크포인트 발생
temporary : 체크포인트 발생 할거는 하고 하지 말거는 하지말고
immediate : 체크포인트 발생하지 않음
alter tablespace example offline immediate;
9. 가장 최근에 백업 파일을 원본파일이 있어야 할 위치에 restore

10. 백업 이후에 변경된 redo 정보 recover

11. 손상되었던 테이블스페이스를 online으로 변경
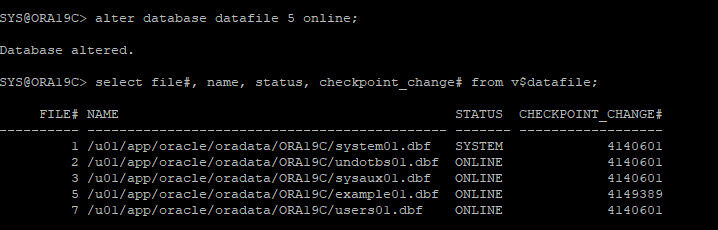
12. recover 한 데이터 확인
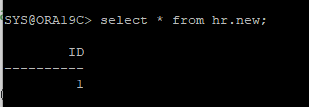
ARCHIVE 시나리오 2
DB 정상적인 종료 후 데이터파일이 손상되었을 경우 복구
1. DB 정상적인 종료
SHUTDOWN IMMEDIATE
2. 데이터파일 삭제로 장애 유발

3. DB STARTUP 후 오류 발생
- open 시점에 있어야 할 데이터파일이 없기 때문에 오류발생
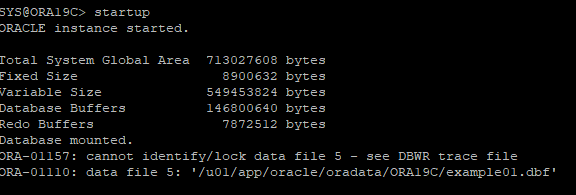

4. 손상된 파일만 offline으로 변경
- 현재 archive 모드이기 때문에 drop 옵션을 사용할 필요가 없다.

5. 데이터파일 상태 확인

6. DB OPEN
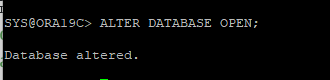
복구 진행
7. 가장 최근에 받아놓은 백업파일을 찾아서 원래 위치에 restore

8. 백업 이후에 변경된 redo 정보를 recover

9. 복구 완료 대상 파일에 대해서 online으로 변경

10. recover 한 데이터파일 확인
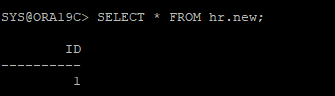
ARCHIVE 시나리오 3
DB 정상적인 종료 후 여러 데이터파일이 손상되었을 경우 복구
1. DB 정상적인 종료
SHUTDOWN IMMEDIATE
2. 데이터파일 삭제로 장애 유발
- example01.dbf, users01.dbf 삭제

3. DB STARTUP 후 오류 발생
- open 시점에 있어야 할 데이터파일이 없기 때문에 오류발생
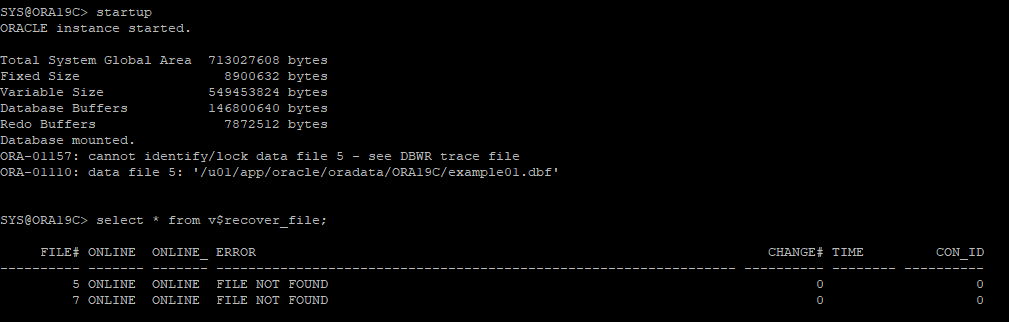
4. 손상된 파일만 offline으로 변경
- 현재 archive 모드이기 때문에 drop 옵션을 사용할 필요가 없다.
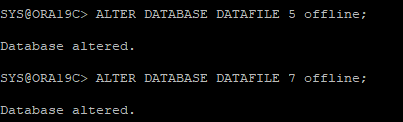
5. 데이터파일 상태 확인
6. DB OPEN
복구 진행
7. 가장 최근에 받아놓은 백업파일을 찾아서 원래 위치에 restore

8. 백업 이후에 변경된 redo 정보를 recover
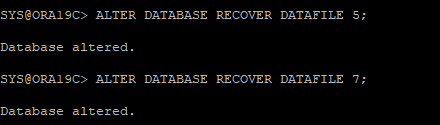
9. 복구 완료 대상 파일에 대해서 online으로 변경
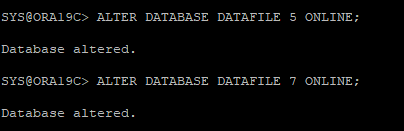
10. recover 한 데이터파일 확인
ARCHIVE 시나리오 4
백업 받지 않은 테이블스페이스에 데이터 파일 손상되었을 경우 복구
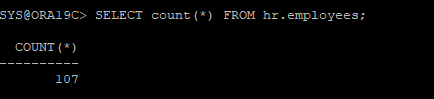
1. 테이블스페이스 생성

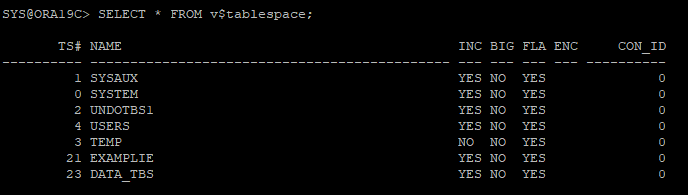
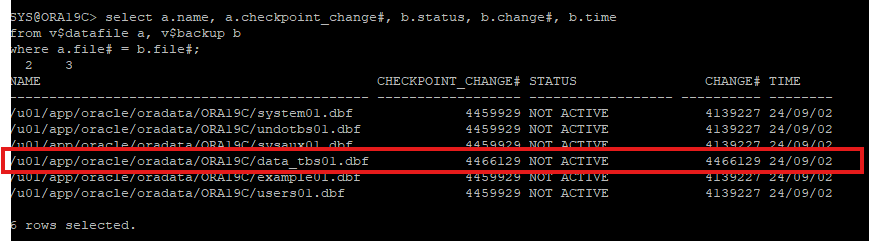
2. 대상 파일의 백업 확인
select a.name, a.checkpoint_change#, b.status, b.change#, b.time
from v$datafile a, v$backup b
where a.file# = b.file#;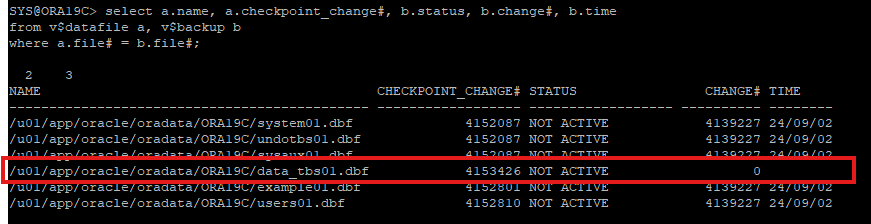
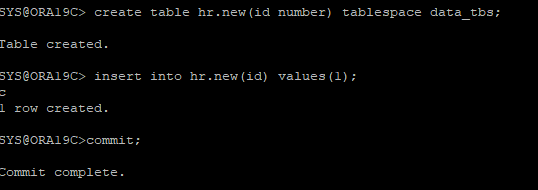
3. 테이블 생성 후 데이터 입력
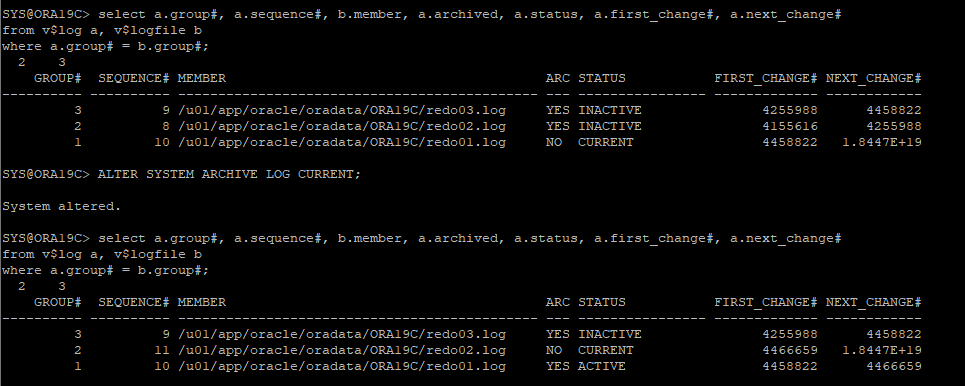
4. 강제로 로그 스위치 발생
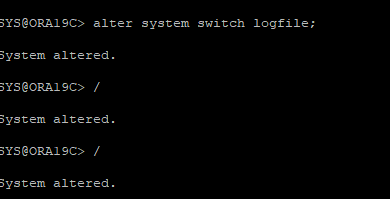
5. 백업받지 않은 데이터 파일을 삭제해 장애 유발

6. DB SHUTDOWN IMMEIDATE
- 체크포인트를 발생해야 하는데 해당 데이터 파일이 없기 때문에 비정상적으로 DB가 내려간다.
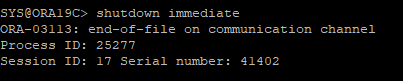
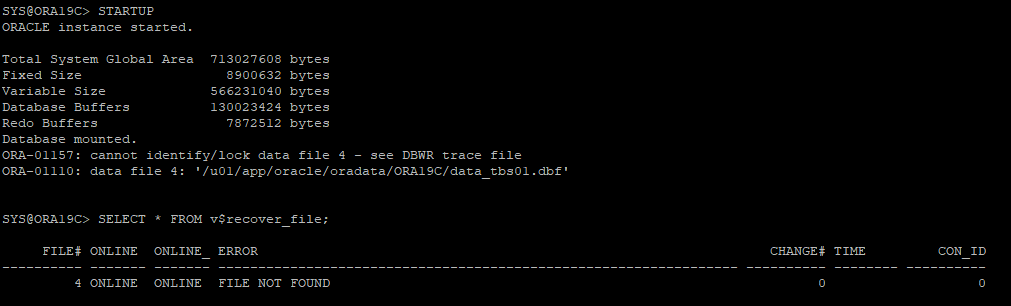
7. DB STARTUP 시도 후 오류 데어터파일 확인
8. 오류 데이터파일 OFFLINE 변경 후 DB OPEN
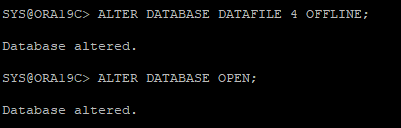
복구작업
9. 백업 받지 않은 테이블스페이스에 속한 파일을 재생성


10. 재생성 한 이후에 변겨오딘 리두 정보 recover
- archive log 파일이 있기 때문에 로그스위치로 인한 redo override 상황에서도 복구가 가능하다.
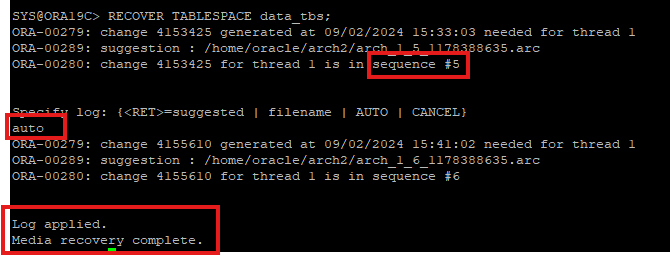
11. 대상 테이블스페이스를 online으로 변경
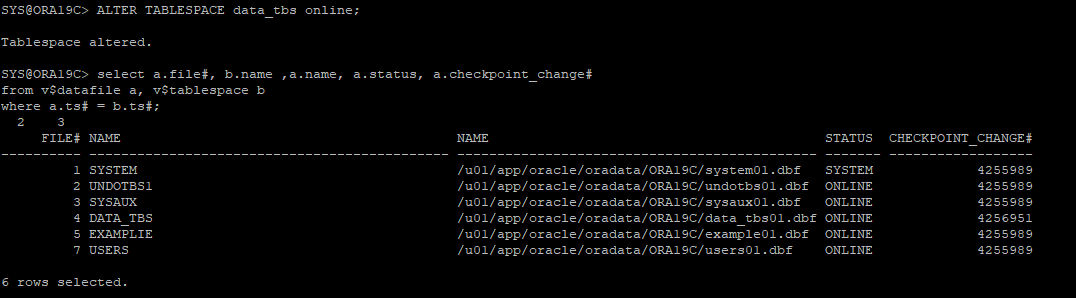
12. recover 한 테이블스페이스 데이터 확인
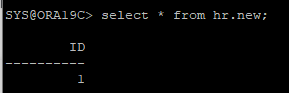
재생성 해야할 위치가 새로운 위치일 경우
ALTER DATABASE CREATE DATAFILE 기존위치 as 새로운위치;
ALTER DATABASE CREATE DATAFILE '$ORACLE_BASE/oradata/ORA19C/data_tbs01.dbf' as 'home/oracle/data_tbs01.dbf';ARCHIVE 시나리오 5
특정한 테이블스페이스에 대해서 백업
- 백업 뷰 정보
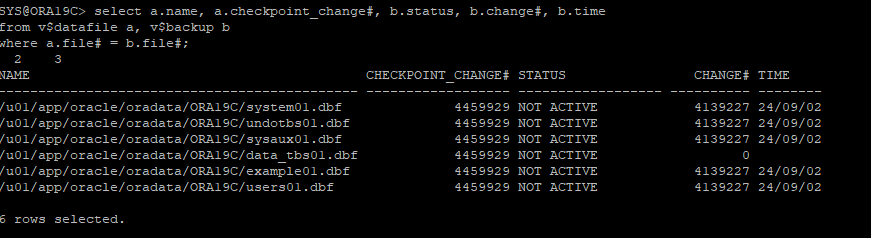
-
테이블스페이스 레벨로 백업 시작
ALTER TABLESPACE 테이블스페이스명 BEGIN BACKUP;

-
백업 시킬 데이터파일 copy

-
백업 종료
ALTER TABLESPACE 테이블스페이스명 END BACKUP;

-
갱신된 백업 뷰 확인
- DB OPEN 상태에서 변경된 내용에 대한 컨트롤 파일 백업
alter database backup controlfile to 저장위치;

- 백업 받아놓은 파일에 대한 아카이브 로그 저장
ARCHIVE - 시나리오 6
특정한 데이터파일이 손상되었다. 기존위치가 아닌 새로운 위치로 복구
-
특정한 데이터 파일 삭제로 장애 유발

-
DB SHUTDOWN IMMEDIATE 시도
- 세션 끊김
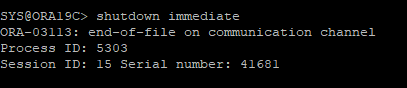
-
세션 재 연결 후 DB STARTUP 시도
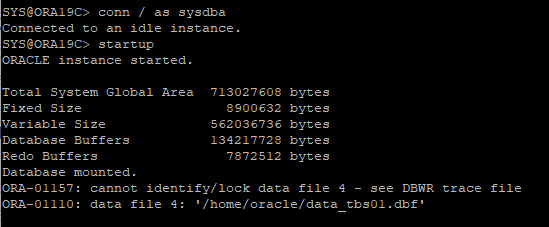
-
손상된 데이터 파일 확인
SELECT * FROM v$recover_file;
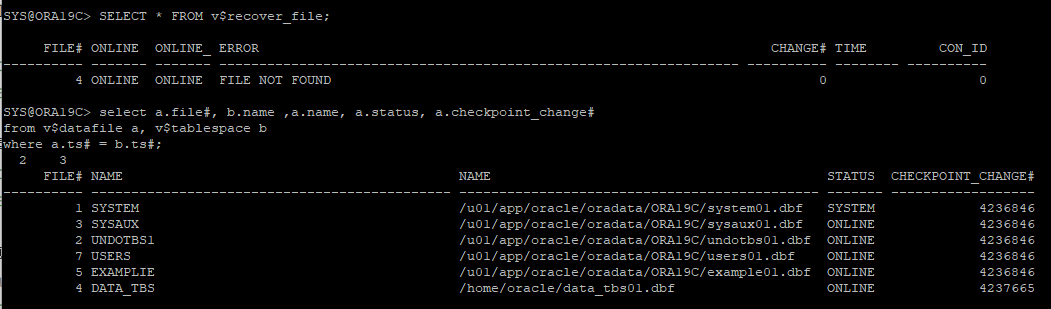
-
손상된 데이터파일 offline 변경 후 DB OPEN
- archive log 모드이기 때문에 offline만 입력해도 된다.
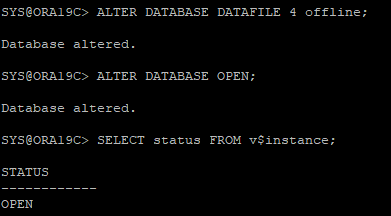
기존 위치가 아닌 새로운 위치로 복구 작업
- 가장 최근 백업본을 찾아서 새로운 위치에 restore

- recover 해야하는 데이터파일 위치를 rename

-
백업 이후에 변경 redo 적용

-
복구 완료된 테이블스페이스를 online으로 변경
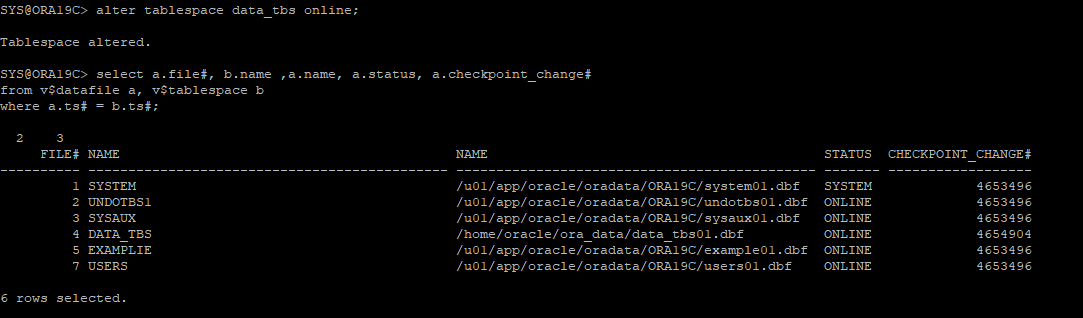
ARCHIVE - 시나리오 7
테이블스페이스에 속한 여러 데이터 파일들 중에 특정한 파일이 손상되었을 경우 복구
- 테이블스페이스 데이터파일 추가
alter tablespace data_tbs add datafile '/u01/app/oracle/oradata/ORA19C/data_tbs02.dbf' size 5m;- 테이블스페이스 데이터파일 확인
select a.file#, b.name ,a.name, a.status, a.checkpoint_change#
from v$datafile a, v$tablespace b
where a.ts# = b.ts#;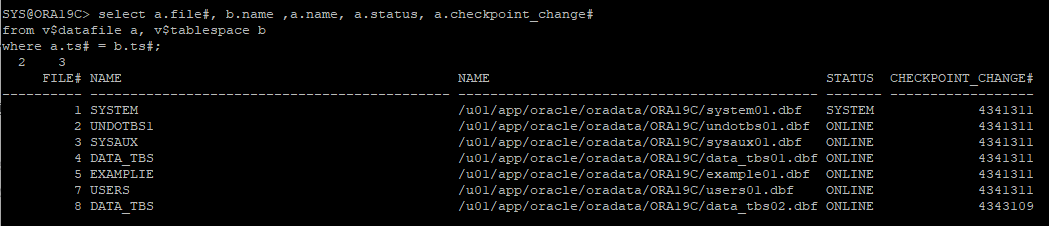
- 사이즈 확인
SELECT a.tablespace_name,
b.file_name,
b.bytes/1024/1024 as "Total Size MB",
(b.bytes - c.free_byte)/1024/1024 as "Used Size MB",
c.free_byte/1024/1024 as "Free Size MB",
b.autoextensible
FROM dba_tablespaces a, dba_data_Files b,
(SELECT tablespace_name, file_id, sum(bytes) AS free_byte
FROM dba_free_space
GROUP BY tablespace_name, file_id) c
WHERE a.tablespace_name = b.tablespace_name
AND a.tablespace_name = c.tablespace_name
AND b.file_id = c.file_id;
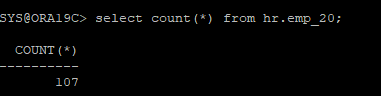
- 테이블 생성
create table hr.emp_2024
tablespace data_tbs as
select * from hr.employees;- 할당된 데이터파일 확인
select f.tablespace_name, f.file_name
from dba_extents e, dba_data_files f
where f.file_id = e.file_id
and e.segment_name = 'EMP_2024'
and e.owner = 'HR';
-
대용량 데이터 삽입
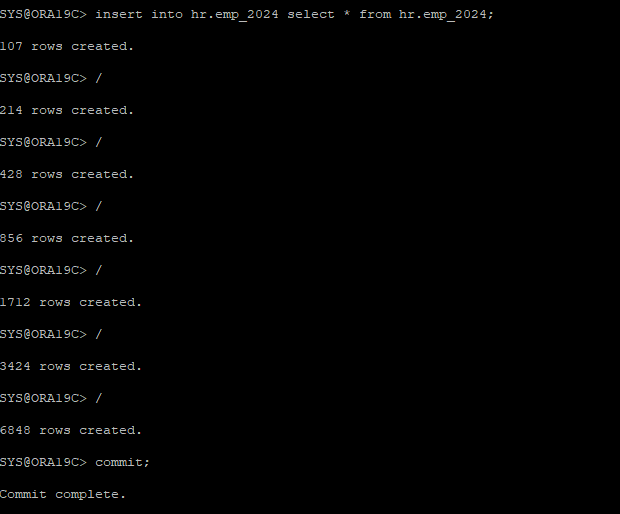
-
테이블스페이스 데이터파일 사용 공간 확인
select f.tablespace_name, f.file_name,count(*)
from dba_extents e, dba_data_files f
where f.file_id = e.file_id
and e.segment_name = 'EMP_2024'
and e.owner = 'HR'
group by f.tablespace_name, f.file_name;
- 특정한 테이블스페이스에 속한 데이터파일을 백업 진행
- 기존에는 새롭게 추가한 데이터파일이라 백업이 없었다.

- 특정 테이블 스페이스만 백업
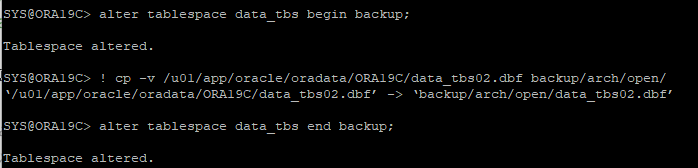
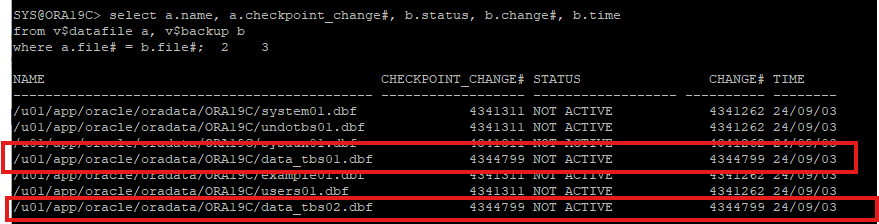
- 백업 확인
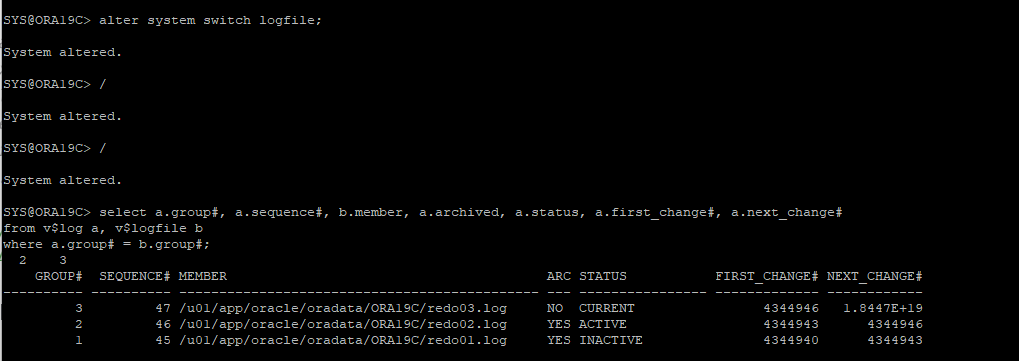
- 수동 log switch 로 아카이브 로그 파일 생성
- 테이블 생성 후 생성된 데이터파일 위치 확인
create table hr.dept_2024 tablespace data_tbs as select * from hr.departments;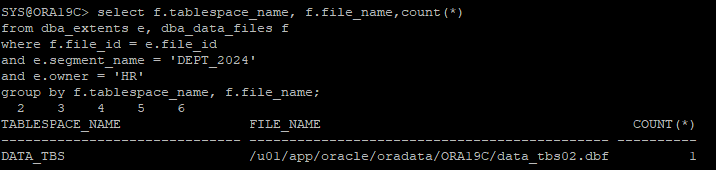
-
특정 데이터파일 삭제로 장애유발

-
테이블스페이스에 속한 데이터파일을 offline으로 수행하되 가능한 데이터파일은 체크포인트 발생하고 문제되는 데이터파일은 체크포인트 발생하지 않겠다.
alter tablespace data_tbs offline temporary;

-
데이터파일 상태 확인
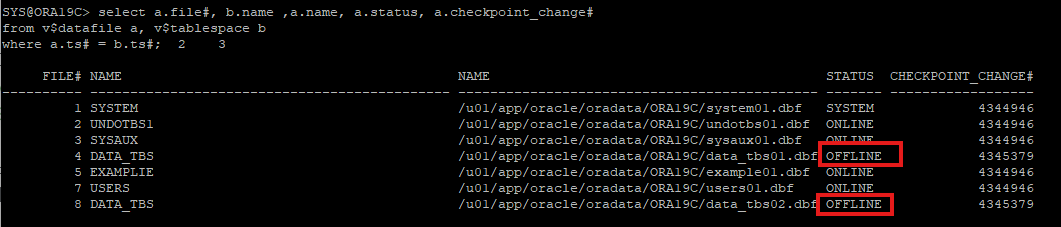
-
문제되는 데이터파일의 가장 최근에 백업본을 찾아 restore

-
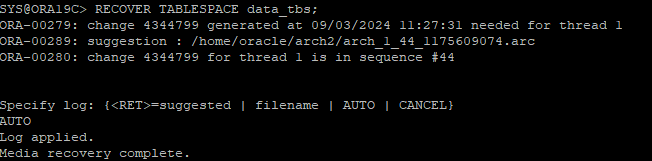
백업 이후에 변경된 redo 적용
- 아카이브 로그 파일이 있기 때문에 AUTO
RECOVER TABLESPACE data_tbs;- 특정 데이터파일만 삭제되었다고, 그 데이터파일만 recover 하면 안되는 이유가 해당 테이블스페이스가 가지고 있는 전체 데이터파일의 checkpoint를 맞춰줘야 하기 때문이다. datafile 레벨로 recover을 하게 되면 같은 테이블스페이스내의 다른 datafile과 checkpoint가 맞지 않을 수 있다.
- 복구 작업 완료된 테이블스페이스를 online으로 변경

번외
- 새로운 테이블 생성 후 생성된 데이터파일 위치 확인
create table hr.loc_2024 tablespace data_tbs as select * from hr.locations;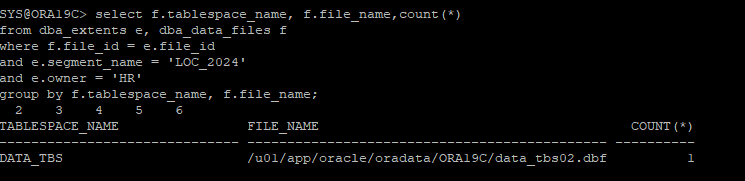
-
특정 데이터파일 삭제로 장애유발
-
데이터파일 상태 확인
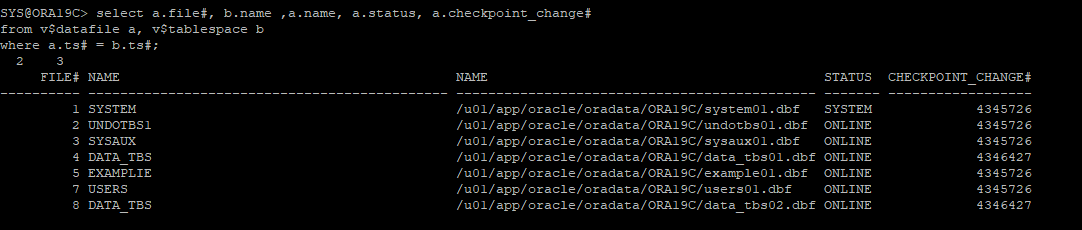
- 문제되는 데이터파일에 대해서만 offline으로 변경

-
문제되는 데이터파일의 가장 최근에 백업본을 찾아 restore
-
백업 이후에 변경된 redo 적용
-
아카이브 로그 파일이 있기 때문에 AUTO
-
MOUNT 단계에서 RECOVER 할때는 ALTER DATABASE RECOVER 로 시작하고 DB OPEN 시점에는 RECVOER로만 하면 된다.
RECOVER DATAFILE 8;
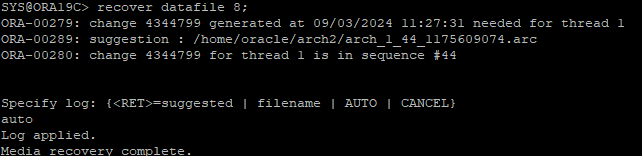
- 복구 작업 완료된 테이블스페이스를 online으로 변경

ARCHIVE - 시나리오 8
system data file 손상
- 시스템 데이터 파일 확인
select a.file#, b.name ,a.name, a.status, a.checkpoint_change#
from v$datafile a, v$tablespace b
where a.ts# = b.ts#;
-
시스템 데이터 파일 삭제로 장애유발

-
체크포인트 유발
- 데이터를 내릴 데이터파일이 없기때문에 오류 발생하면서 세션 끊김
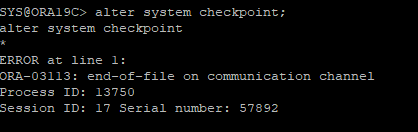
-
DB STARTUP 후 오류 발생
- MOUNT 단계 까지 실행된다.
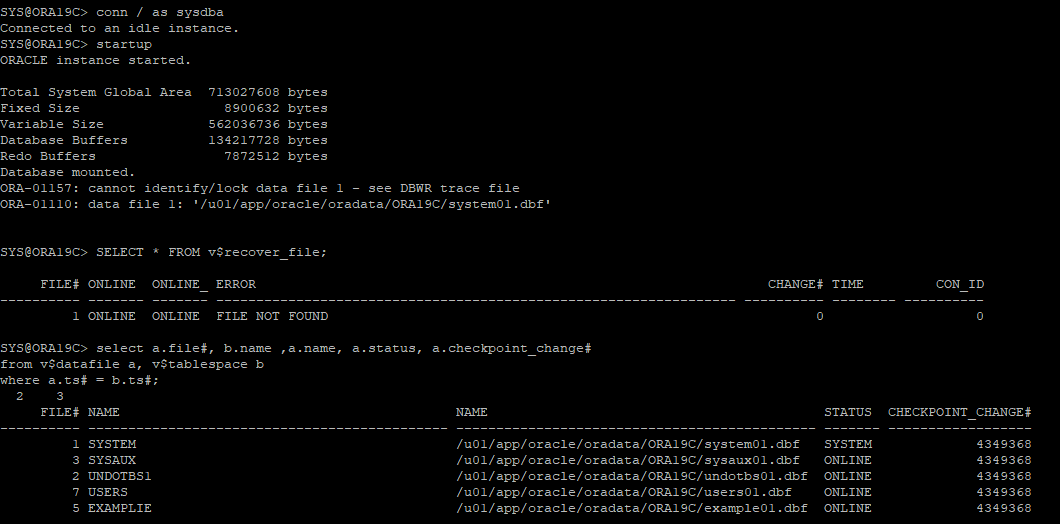
-
가장 최근에 백업 받아놓은 시스템 데이터 파일을 원래위치로 restore

-
REDO 정보를 이용하여 RECOVER 후 DB OPEN
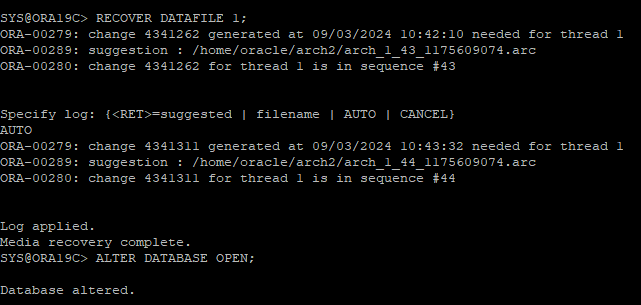
ARCHIVE - 시나리오 9
모든 데이터파일이 손상
-
모든 데이터파일 삭제로 장애 유발

-
세션 끊긴 후 DB 재 시작
- MOUNT 단계 까지 실행되고 오류 발생
- RECOVER 해야 하는 데이터 파일 확인
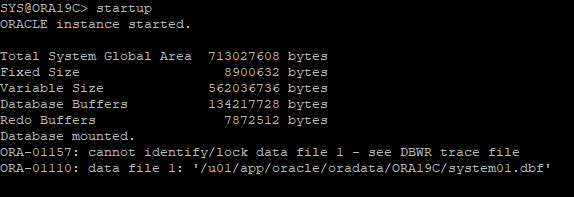

복구방법
-
문제되는 데이터파일들의 가장 최근의 백업본 찾아 restore

-
백업 이후에 redo 적용
- 데이터파일 하나하나 recover 하기 싫을때는 전체 database를 recover 해주면 된다.
recover database
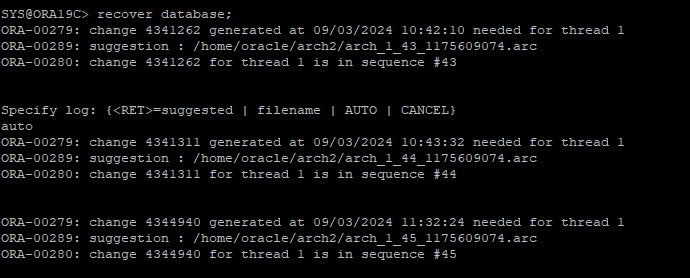
-
DB OPEN
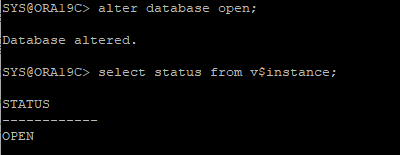
ARCHIVE - 시나리오 10
undo datafile 손상
-
DB 정상종료
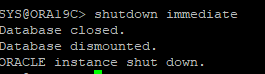
-
UNDO 데이터파일 삭제로 장애유발

- DB STARTUP 후 오류발견
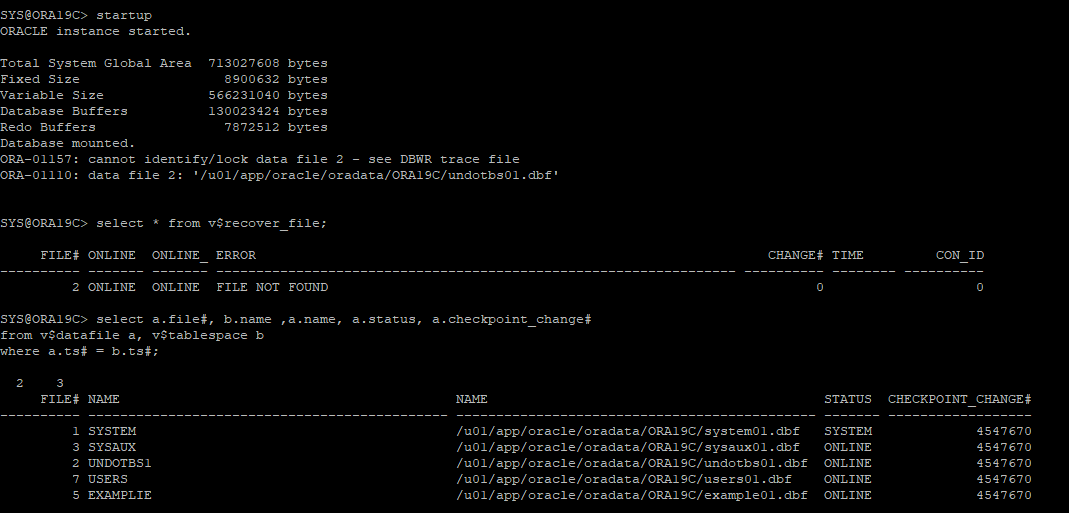
-
가장 최근 백업본 찾아서 restore

-
백업 이후에 변경된 redo 적용

-
DB OPEN
ARCHIVE - 시나리오 11
운영중에 undo 데이터 파일이 손상
hr session
udate hr.employees
set salary = salary * 1.1
where employee_id = 100;sys session
- undo 데이터파일 삭제를 통해 장애유발

-
alert log를 통해 장애 발생 확인

-
새로운 undo tablespace 생성
CREATE UNDO
TABLESPACE undo
DATAFILE '/u01/app/oracle/oradata/ORA19C/undo01.dbf' size 10m
autoextend on;-
undo segment 확인
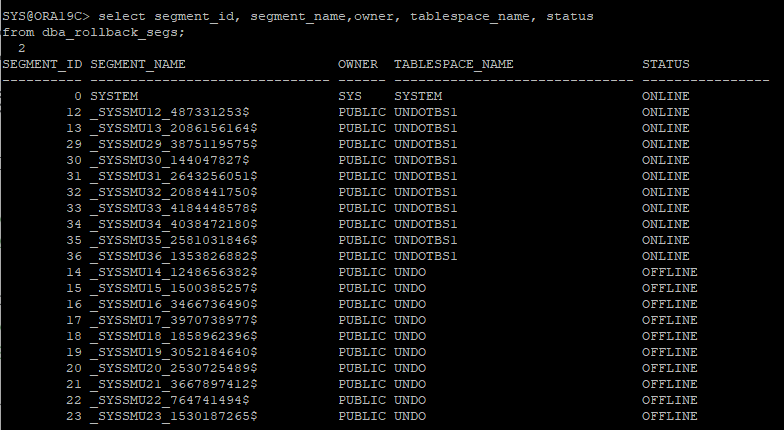
-
새로 생성한 undo tablespace를 사용할 수 있도록 지정
alter system set undo_tablespace = undo; -
변경된 undo segment 확인
새로운 hr session
- update를 실행해 새로운 udno segment에 할당받기
update hr.employees
set salary = salary * 1.1
where employee_id = 200;sys session
- transaction 확인해보기
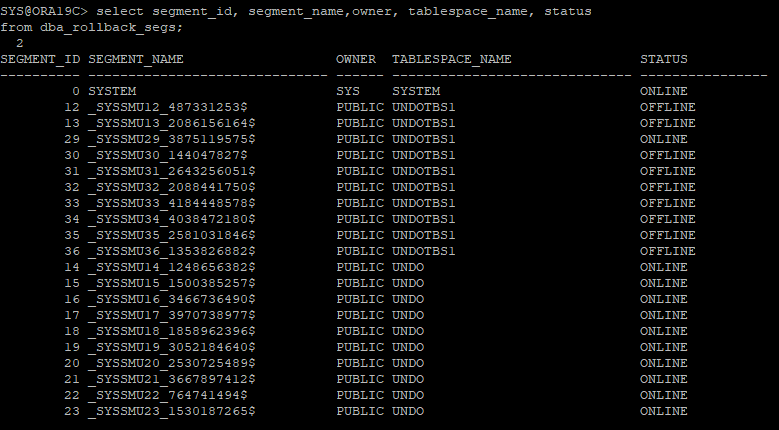
select segment_id, segment_name,owner, tablespace_name, status
from dba_rollback_segs;- 다른 undo 세그먼트에 할당되어있는걸 확인 할 수 있다.

- offline 상태도 변경 지연되고 있는 undo 확인
select a.name, b.status
from v$rollname a, v$rollstat b
where a.usn = b.usn; 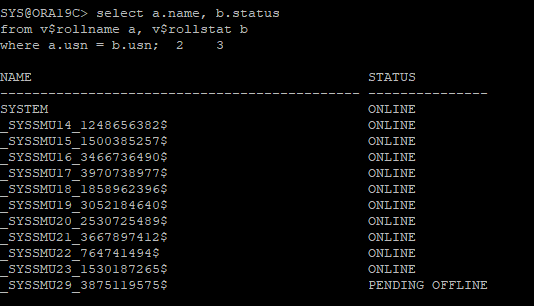
- 이전 undo에 transaction 할당되어있는 세션 kill 하기

- 세션 킬
alter system kill session 'sid,serial#' immediate;

- 세션을 킬 해도 여전히 이전 udno segment가 offline으로 변경되지 않는다.
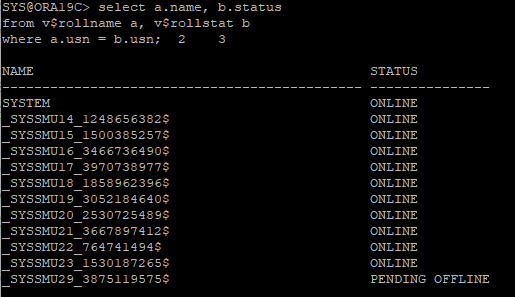
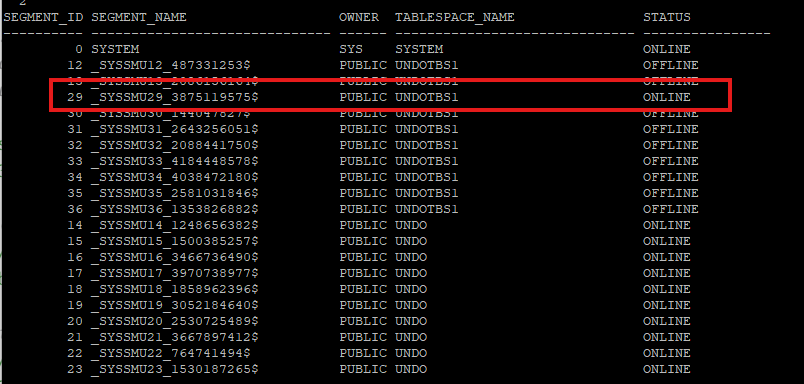
- 이전 언두 테이블스페이스에 속한 세그먼트중에 아직도 online 상태로 되어 있을 경우는 테이블스페이스를 삭제할 수 없다.
해결방법
- 데이터베이스를 정상적인 종료
shutdown immediate - 초기파라미터 파일(pfile)에 수동으로 offline 등록을 해야한다.
vi initORA19C.ora
_offline_rollback_segments = (세그먼트 이름)
- pfile을 이용해서 데이터베이스 mount 시작
startup pfile='$ORACLE_HOME/dbs/initORA19C.ora' mount
-
기존 데이터파일을 offline으로 설정
alter database datafile 이전 언두 파일번호 offline; -
데이터베이스 open 한 후 기존 undo tablespace 삭제
alter database open
drop tablespace undotbs1 including contents and datafiles;
create spfile from pfileARCHIVE - 시나리오 12
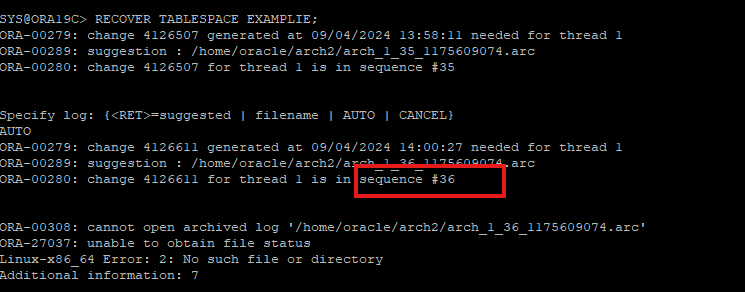
복구 작업시 필요한 archive log file이 한 쪽에 없을 경우
- 특정 데이터파일 및 아카이브 로그파일 삭제로 장애 유발
- 데이터 조회

- 유/무 확인 후 삭제 진행

-
문제되는 데이터파일 offline으로 변경
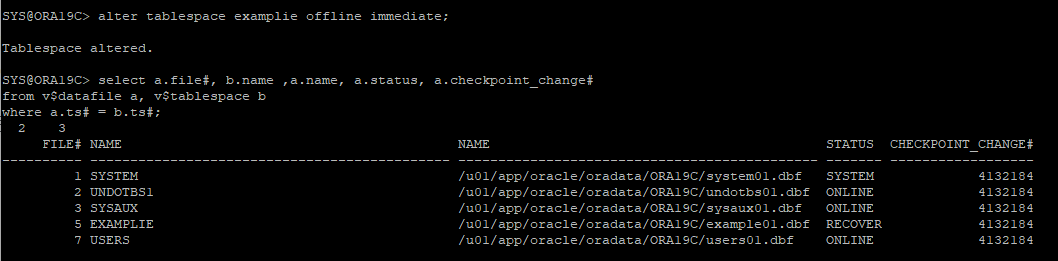
-
가장 최근의 백업을 찾아 restore

-
백업 이후에 리두 정보 적용
- archive log 파일을 통해 recover 하려고 하였지만 dest2에 해당 archive log 파일을 삭제하였기때문에 auto 옵션 복구 실패
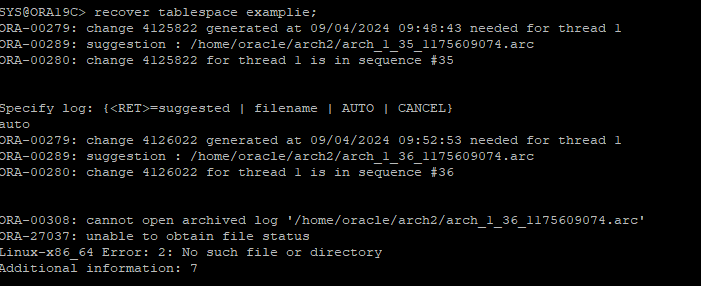
- dets1에 있는 archive log 파일 적용
- 이미 sequence 35는 recover 적용을 했기 때문에 문제가 되었던 sequence 36 부터 recover을 재 시도 한다.
- sequence 36은 dest1에 있기 때문에 파일 위치를 입력해준다.
- 그 후 37,38은 현재 redo log group에 존재하기 때문에 archive를 보지 않고 redo log file을 확인하게 된다.
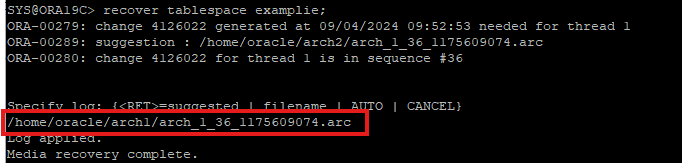
- 복구 완료한 테이블스페이스 online으로 변경

archive file이 생성되는 위치를 여러곳으로 설정한 경우 복구 작업시에 가장 마지막에 설정된 위치에서 아카이브 파일을 찾는다. 없을 경우 아카이브 log 파일이 존재하는 디렉터리를 설정하면 되고 또는 다른 디렉터리에 아카이브 파일을 마지막 파일 위치에 복사를 한 후 복구 작업을 진행하면 된다.
ARCHIVE - 시나리오 13
복구 작업시 필요한 archive log file이 삭제됐지만 redo log file이 있어 문제없이 복구
- 가장 마지막 archive log file을 삭제
-
현재 아카이브 로그 파일은 38번이 마지막이다
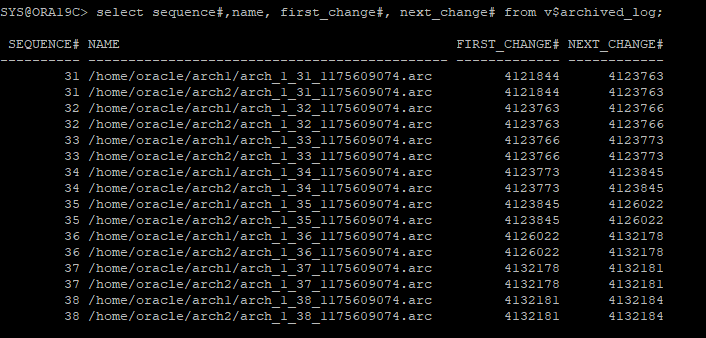
-
38번 아카이브 로그 파일은 redo log file에도 보관중이다.

-
38번 아카이브 로그 파일 삭제

-
특정 데이터 파일도 삭제

-
문제되는 데이터파일 offline으로 변경
-
가장 최근의 백업본으로 restore

- redo 정보를 통해 recover
- 35번 , 36번 은 archive log file이 존재하기 때문에 recover 가능하고 37번, 38번은 redo log file에 존재하기 때문에 38번 archive log file이 손상 되었어도 redo log file로 recover 하게 된다.
- 추후 오류를 방지하기 위해 현재 redo log file을 archive log file로 copy를 해줘야 한다.
- 현재 redo log file의 redo03.log가 38번 이기 때문에 복사해준다.

ARCHIVE - 시나리오 14
복구 작업시 필요한 archive log file이 손상되었을 경우 완전 복구 실패로 인해 불완전 복구
온라인 백업 받은 시점의 SCN
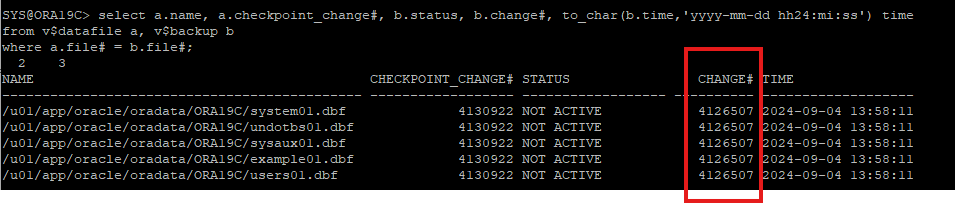
아카이브 로그 파일 번호 & 리두로그파일 번호
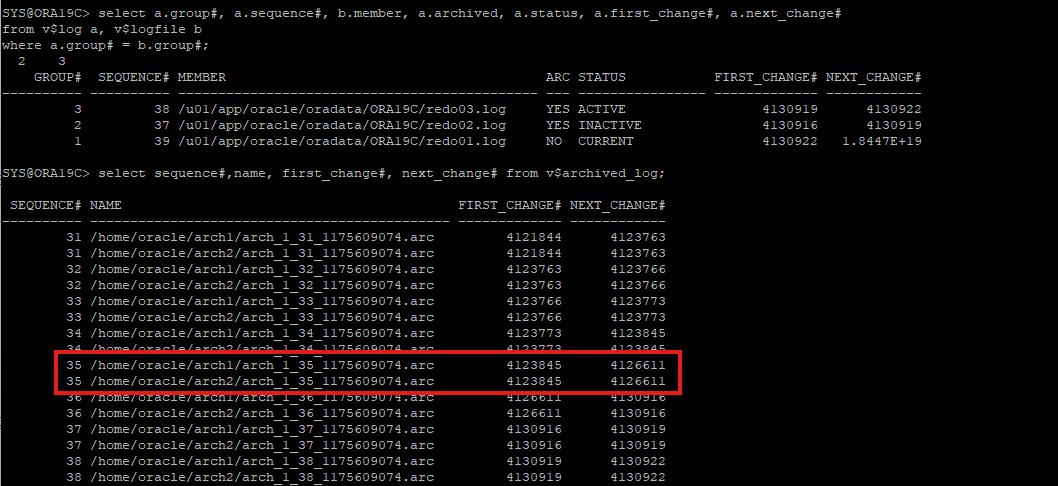
백업 받은 백업본의 SCN이 시작하는 아카이브 로그 파일은 35번부터 시작이다.
현재 리두 로그파일에는 37,38,39 번의 파일이 있으니 36번 아카이브 로그 파일을 삭제해보겠다.
장애유발
-
redo log file에 없는 아카이브 로그 파일 삭제

-
특정 데이터 파일 삭제
- example01.dbf 파일을 삭제하였다.

완전 복구시도
- 문제 있는 데이터파일 offline으로 변경


-
가장 최근에 백업 받아놓은 백업본 restore

-
아카이브 정보를 이용해서 recover 시도
- 중간 아카이브 파일이 존재하지 않아 완전복구 실패
- 다시 한번 recover 시도 후 cancel base recovery로 시도
- 불완전 복구는 절대로 테이블스페이스 레벨로 복구 할 수 없다.
- cancel base recovery는 특정한 파일만 recover 할 수 없고 전체 database 기준으로 한다.
- 문제가 있는 데이터파일 online으로 변경 시도
- online으로 변경 불가
- 복구 작업에 필요한 리두 정보가 있어야 할 위치에 없어서 완전 복구 실패
- 복구 작업에 필요한 아카이브 파일이 없어서 실패
해결 방법
- 문제 있는 데이터파일을 사용하지 않음
- 불안전한 복구 방식으로 데이터베이스를 살려야 한다.
불완전한 복구 방식
-
DB 비정상적인 종료

-
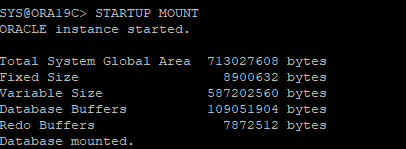
백업받아놓은 전체 데이터파일을 restore

-
DB를 MOUNT 단계까지만 실행
-
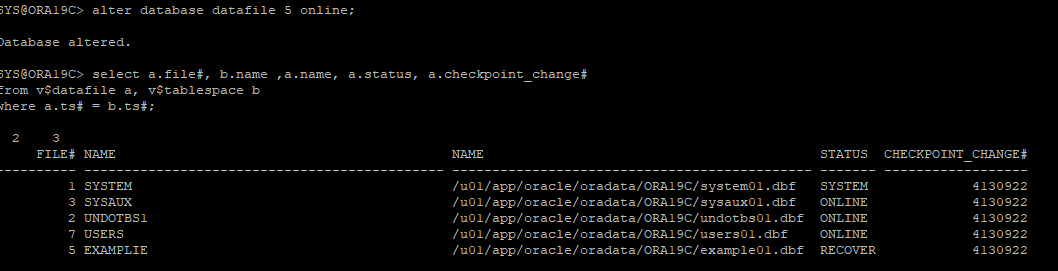
control file이 가지고 있는 데이터파일 정보 확인

- offline 상태인 데이터파일 online으로 변경
- online으로 변경하였지만 여전히 recover으로 되어있지만 online으로 변경된거다
오전 실습에서 offline상태에서 db open resetlogs를 한 후 online으로 변경 시도 시 실패한 이유
- offline데이터파일 헤더가 가지고 있는 RESETLOGS 번호랑 RESETLOGS로 데이터베이스 오픈 후 다른 online상태의 데이터파일 RESETLOGS 번호랑 다르기 때문에 online으로 변경되지 않는다.
- open resetlogs를 한뒤 offline 상태로 되어있던 데이터파일에는 write를 할수 없어 online으로 바꿀 수 없었다.
번외 - resetlogs 번호
select * from v$database_incarnation;
데이터베이스를 resetlogs로 open 하게 되면 데이터파일 헤더의 resetlogs_id 정보가 새롭게 갱신된다. 하지만 offline으로 되어있는 데이터파일에는 갱신되지 않기 때문에 현재 resetlogs_id와 같지 않아 offline에서 online으로 변경되지 않는다.

-
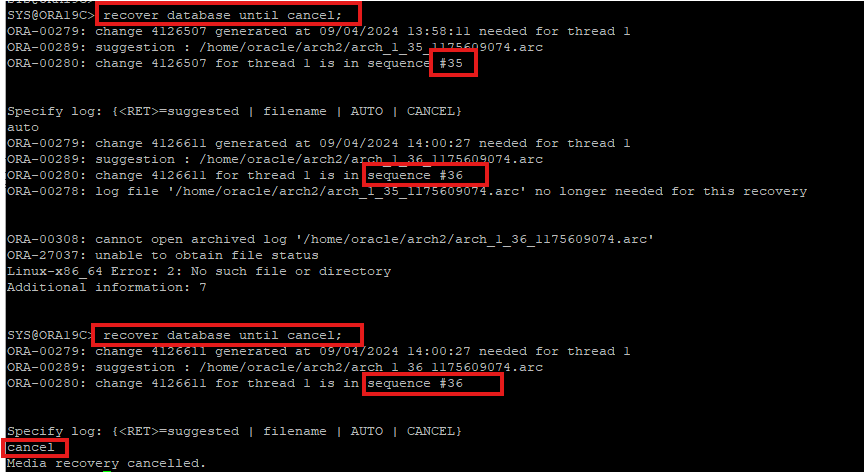
cancel base recovery 로 전체 파일 복구
RECOVER DATABASE UNTIL CANCEL
- 현재 control file은 아카이브 로그 파일과 같은 scn이기 때문에 using backup controlfile 키워드를 사용하지 않는다.
-
DB OPEN
- 불안전한 복구로 하였기 때문에 redo log가 가지고 있는 정보랑 control file 정보가 달라서 resetlogs로 DB를 OPEN 해야한다.

- 데이터 파일 상태 확인
- online으로 변경된 걸 확인할 수 있다.

ARCHIVE - 시나리오 15
데이터 파일 삭제, 모든 아카이브 파일이 삭제 복구(일관성 있는 백업이 있을 경우, close backup, offline backup, cold backup)
-
특정 데이터 파일 및 모든 아카이브 파일 삭제로 장애유발

-
DB SHUTDOWN ABORT
- CHECKPOINT 기록해야할 데이터파일이 삭제되었기 때문에 정상적인 종료 불가능
-
가장 최근의 offline 백업본 유무 확인

-
일관성 있는 백업 찾아서 restore(controlfile, datafile)

-
RESTORE한 CONTROLFILE을 가지고 MOUNT 단계까지 실행
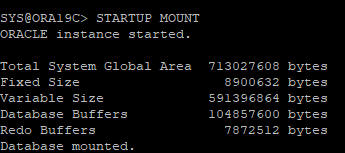
-
cancel base recovery 실행
- 어차피 전체 아카이브 로그 파일이 삭제되어 바라봐야할 redo가 없어 restore한 control file의 scn은 datafile과 동일하기 때문에 using backup controlfile은 사용하지 않는다.

- DB를 OPEN 하는데 리두는 RESETLOGS 방식으로 OPEN 해야한다.
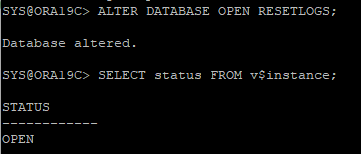
ARCHIVE - 시나리오 16
데이터 파일 삭제, 모든 아카이브 파일이 삭제 복구(일관성 없는 백업이 있을 경우, open backup, online backup, hot backup)
-
특정 데이터 파일 및 모든 아카이브 파일 삭제로 장애유발
-
DB SHUTDOWN ABORT
- CHECKPOINT 기록해야할 데이터파일이 삭제되었기 때문에 정상적인 종료 불가능
- 가장 최근의 online 백업본 유무 확인

-
일관성 없는 백업 찾아서 restore(controlfile, datafile)
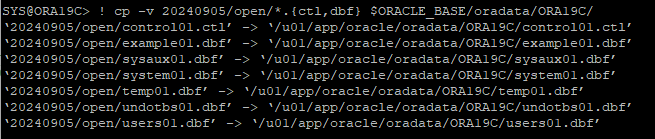
-
RESTORE한 BACKUP CONTROLFILE을 가지고 MOUNT 단계까지 실행
백업 control 파일을 이용해서 불완전한 복구 작업 수행
- cancel base recover 실행
- 현재 control file은 backup을 받은 control이기 때문에 using backup control 키워드 사용
- 일관성 없는 backup 파일로는 불완전한 복구를 할 수 없다.
- recover은 성공한 상태이다.
- 온라인 백업시 data file은 being backup ~ end backup 시행도중 백업되고 control file은 그 뒤 백업을 시도하는데 이때 미세하게 checkpont 정보가 다르기 때문에 복구 할 수가 없다.
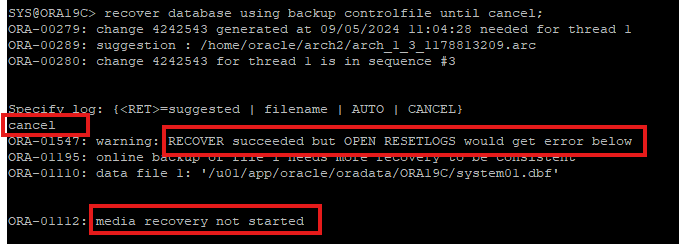
- init 파일 만들기

-
DB SHUTDOWN ABORT

-
init 파일에 히든 파라미터 설정
- online 백업으로 받은 data file 과 control file의 미세한 checkpoint 차이를 무시하게 설정해야 한다.
- _로 시작하는 파라미터는 히든 파라미터이다
_allow_resetlogs_corruption=true
_corrupted_rollback_segments=true
-
PFILE을 이용해서 DB MOUNT 단계까지만 실행
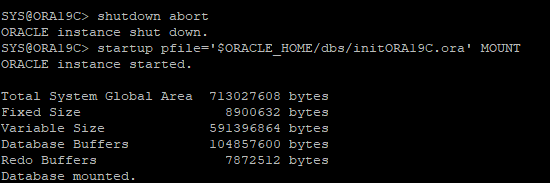
-
DB resetlogs 옵션으로 OPEN
- 이전에 recover은 하였기 때문에 db open만 하면 된다.

- SPFILE로 DB 다시 재실행
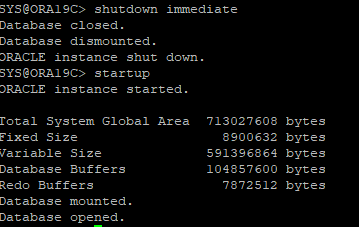
ARCHIVE - 시나리오 17
archive 생성된 후 inactive 상태에 있는 redo log file 삭제 복구(데이터베이스 정상종료)
- 현재 redo log 파일 및 archive 파일 확인


- DB 정상 종료
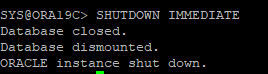
-
INACTIVE 상태인 REDO LOG GROUP 삭제

-
DB STARTUP 하지만 REDO 파일이 없어 오류 발생
- 세션 끊어짐
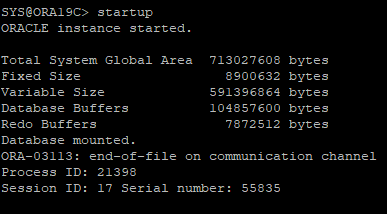
-
DB MOUNT 단계까지 실행
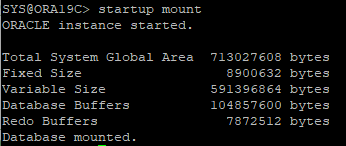
-
문제되는 REDO LOG GROUP 삭제
ALTER DATABASE DROP LOGFILE GROUP 1;
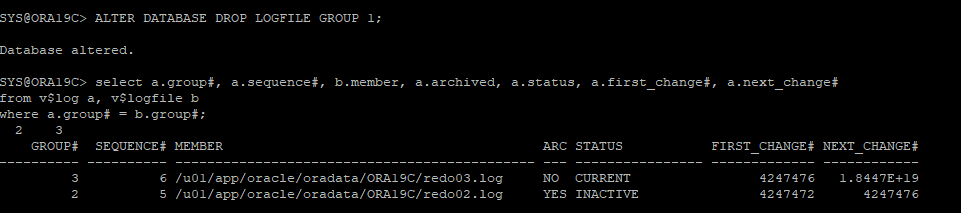
-
DB OPEN
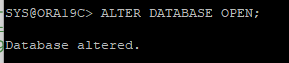
-
REDO LOG GROUP 추가해주기
ALTER DATABASE ADD LOGFILE GROUP 1 '/u01/app/oracle/oradata/ORA19C/redo01.log' size 200m;

ARCHIVE - 시나리오 18
archive 생성된 후 inactive 상태에 있는 redo log file 삭제 복구(데이터베이스 운영중인 상태)

-
inactive 상태인 redo log group 1개 삭제

-
많은 log switch 발생
- 횡상태가 발생
-
로그파일 확인
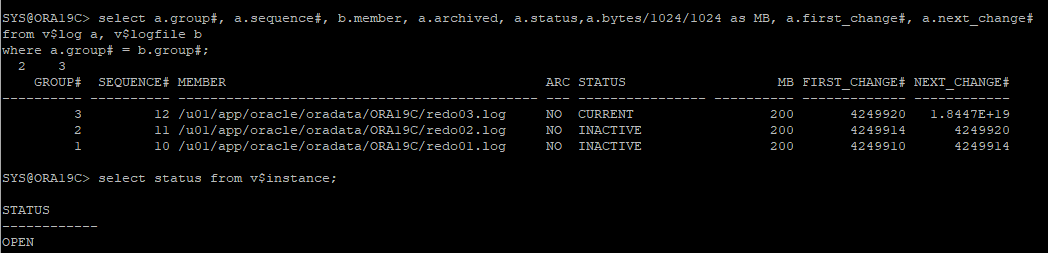
-
아카이브 로그 파일 확인
- 로그파일과 아카이브 로그 파일 사이에 갭이 생긴다.

- redo log file을 논리적으로 삭제후 재 생성
alter database clear unarchived logfile group 1;

- redo log file 확인
-
물리적으로도 redo log file을 생성해준다.

-
시퀀스 번호도 초기화 된다.

- 아카이브 파일의 손실이 발생하였기 때문에 즉시 백업을 수행해야 한다.
ARCHIVE - 시나리오 19
current redo log file 삭제된 후 데이터베이스 정상적인 종료

-
log switch 발생으로 아카이브 생성
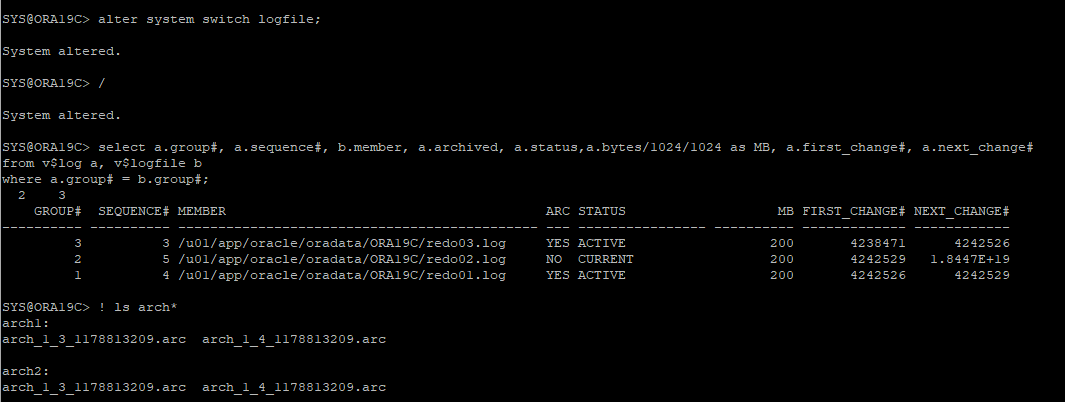
-
새로운 테이블 생성
- 생성 정보는 current한 redo log group에 저장되어있다.

- current한 redo log 파일 삭제로 장애유발
- 시퀀스 번호 5, 그룹 번호 2

- DB 정상종료
- redo 파일은 없어서 data file 헤더에만 checkpoint 정보가 기록된다.
- DB OPEN 시도 하지만 오류 발생
- MOUNT 단계에서 OPEN 단계로 올라갈라고 할때 오류발생
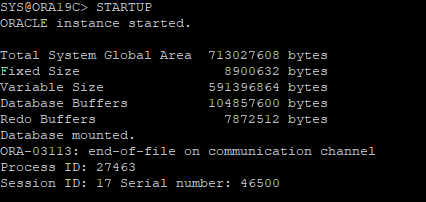
-
다시 DB MOUNT 단계까지만 실행
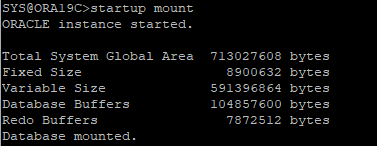
-
current redo전까지 복구해야하기 때문에 cancel base recover 시도해야한다.
- DB가 정상적으로 종료되었기 때문에 controlfile은 restore 할 필요없어 until cancel으로만 하면 된다.

- DB OPEN은 RESETLOGS 키워드로 해야한다.
- control file이 가지고 있는 시퀀스와 redo log file이 가지고 있는 번호가 다르기때문이다.

-
RESETLOGS로 OPEN 하였기 때문에 물리적으로 없던 REDO LOG FILE은 자동으로 생성해준다.

-
생성했던 테이블 확인
- 정상종료를 할때 dirty buffer에 있던 값이 disk로 내려가 cancel base recover을 해도 데이터는 존재한다.
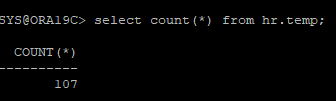
ARCHIVE - 시나리오 20
current redo log file 삭제된 후 데이터베이스 비정상적인 종료(일관성 있는 백업본 사용)
- log switch 발생으로 아카이브 생성
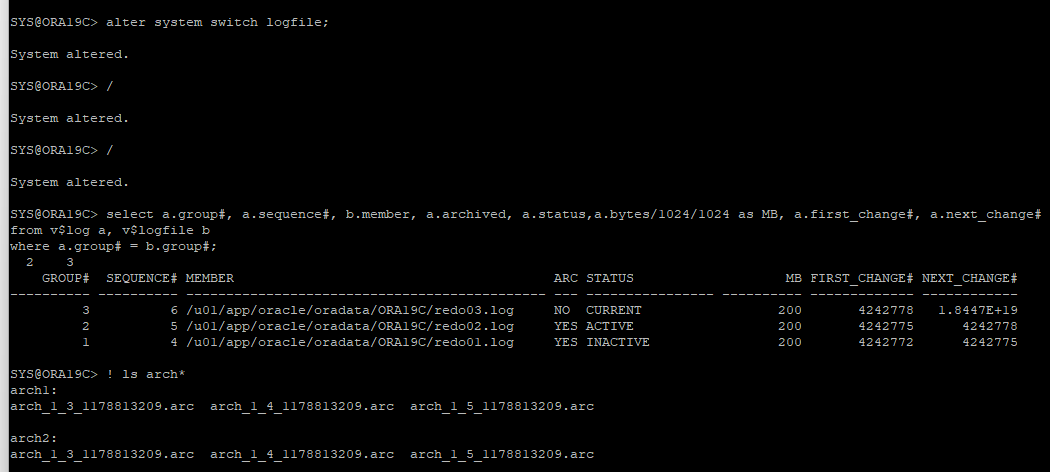
- 새로운 테이블 생성
- 생성 정보는 current한 redo log group에 저장되어있다.
- current한 redo log 파일 삭제로 장애유발
- 시퀀스 번호 6, 그룹 번호 3

-
DB 비정상적인 종료

-
DB STARTUP 하지만 오류 발생
- DB가 비정상적으로 종료된 후 다시 START 할때는 CURRENT한 REDO가 instance recover을 해줘야 하지만 current한 리두가 없기 때문에 오류 발생
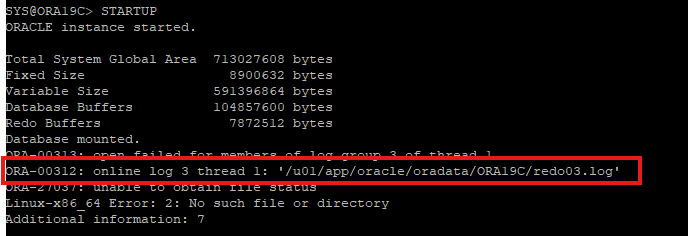
불완전 복구로 실행
6. DB SHUTDOWN ABORT 후 다시 MOUNT 단계 까지만 실행
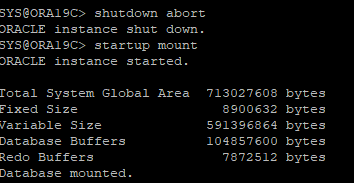
- data file만 restore
- checkpoint 수위가 맞춰져 있는 data file(offline backup)을 restore

- cancel base recover 시도
- archive log file이 있는 시퀀스 까지는 auto로 복구
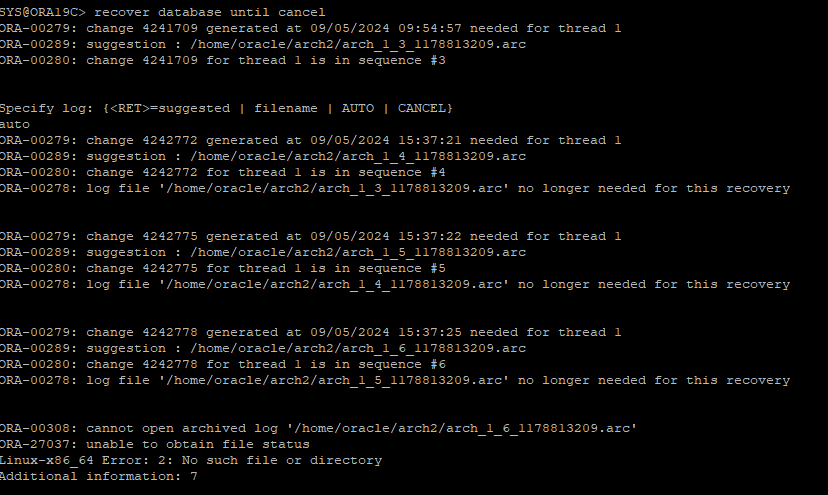
- 다시 cancel base recover 시도
- 6번 시퀀스는 current한 redo 였기 때문에 archive 파일이 없어 cancel 해준다.
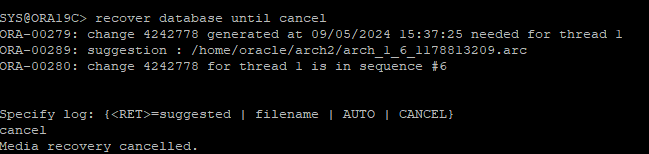
-
DB resetlogs 옵션으로 OPEN

-
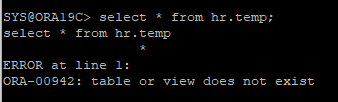
current한 리두는 적용되지 않았기 때문에 current 리두에 저장된 hr.temp 테이블은 조회할 수 없다.
ARCHIVE - 시나리오 21
current redo log file 삭제된 후 데이터베이스 비정상적인 종료(일관성 없는 백업본 사용)
- log switch 발생으로 아카이브 생성
- 새로운 테이블 생성
- 생성 정보는 current한 redo log group에 저장되어있다.
- current한 redo log 파일 삭제로 장애유발
- 시퀀스 번호 6, 그룹 번호 3
-
DB 비정상적인 종료
-
DB STARTUP 하지만 오류 발생
- DB가 비정상적으로 종료된 후 다시 START 할때는 CURRENT한 REDO가 instance recover을 해줘야 하지만 current한 리두가 없기 때문에 오류 발생
불완전 복구로 실행
6. DB SHUTDOWN ABORT 후 다시 MOUNT 단계 까지만 실행
- data file만 restore
- checkpoint 수위가 맞춰져 있는 data file(online backup)을 restore

- cancel base recover 시도
- archive log file이 있는 시퀀스 까지는 auto로 복구
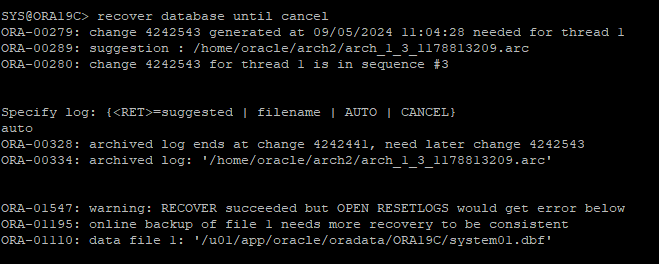
- recover에는 성공했지만 open resetlogs는 오류 발생한다는 경고
- DB OPEN RESETLOGS 시도
- online 백업파일로는 바로 불완전한 복구가 불가능하다
- 히든 파라미터를 사용해야 한다.

- init 파일에 히든 파라미터 설정
- online 백업으로 받은 data file 과 control file의 미세한 checkpoint 차이를 무시하게 설정해야 한다.
- _로 시작하는 파라미터는 히든 파라미터이다
_allow_resetlogs_corruption=true
_corrupted_rollback_segments=true
-
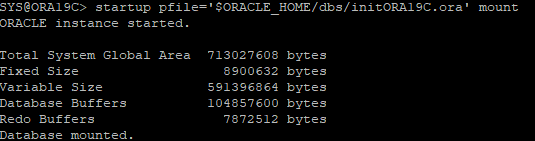
init 파일로 DB MOUNT 단계까지 실행
-
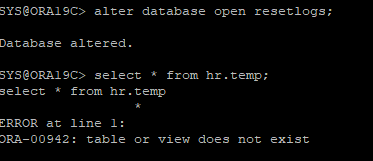
이전 RECOVER 시도로 RECOVER은 이미 되어있기 때문에 바로 OPEN RESETLOGS만 하면 된다.
- 비정상 종료를 했기 때문에 만들었던 테이블은 조회되지 않는다.
ARCHIVE - 시나리오 22
data file, redo log file 손상되지 않고 control file 손상되었다. (control file 백업이 있을때)
-
테이블 생성
현재 current한 redo 그룹에 정보 입력

-
DB 정상종료
-
컨트롤 파일 삭제로 장애 유발

-
DB STARTUP 하지만 오류발생
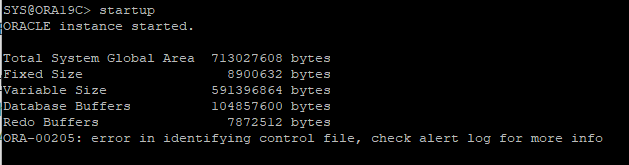
- alert log에서 확인한 내용
-
현재 상태는 nomount 단계이다
-
가장 최근 control file 백업본을 원래 위치에 restore

-
백업 control file을 이용해서 mount 단계까지 실행
-
contorl file을 recover 해줘야한다.
recover database using backup controlfile -
control file을 recover 할때는 복구가 필요한 시점의 redo log 부터 current redo log 까지 오라클에서는 아카이브에서 찾는다.
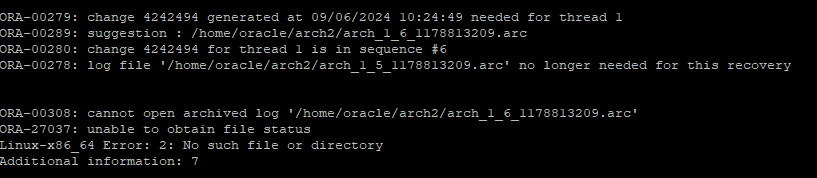
하지만 현재 사용하고 있는 control 파일은 과거 시점의 control 파일이기 때문에 redo log 정보 또한 과거정보를 가지고 있어 현재 current한 redo log를 찾으려면 오류가 발생한 sequence 번호를 alert log에서 확인할수 있다.

- current한 redo log는 따로 주소를 지정해줘야한다.
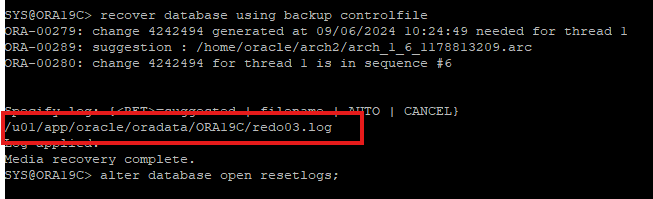
- control file을 recover 하였기 때문에 DB를 오픈할때 resetlogs로 해야한다.

recover database using backup control을 하게 되면 백업 sequen번호와 현재 sequen번호가 맞지 않아 recover 하는 동안에 자동으로 백업 control 파일이 가지고 있는 redo 정보에서 sequence 번호를 초기화 하는 로직이 발생되었다. 따라서 db를 open할때 resetlogs로 open 하는것 같다.
ARCHIVE - 시나리오 23
data file, redo log file 손상되지 않고 control file 손상되었다. (control file 재생성 복구)
-
테이블 생성
현재 current한 redo 그룹에 정보 입력
-
DB 정상종료
-
컨트롤 파일 삭제로 장애 유발
-
DB STARTUP 하지만 오류발생
- alert log에서 확인한 내용
-
현재 상태는 nomount 단계이다
-
가장 최근 control file 백업본을 원래 위치에 restore
-
백업 control file을 이용해서 mount 단계까지 실행
-
backup control 파일을 이용해 trace 파일 생성

-
DB 종료

-
trace 파일 내용으로 control file 재생성
STARTUP NOMOUNT
CREATE CONTROLFILE REUSE DATABASE "ORA19C" NORESETLOGS ARCHIVELOG
MAXLOGFILES 16
MAXLOGMEMBERS 3
MAXDATAFILES 100
MAXINSTANCES 8
MAXLOGHISTORY 292
LOGFILE
GROUP 1 '/u01/app/oracle/oradata/ORA19C/redo01.log' SIZE 200M BLOCKSIZE 512,
GROUP 2 '/u01/app/oracle/oradata/ORA19C/redo02.log' SIZE 200M BLOCKSIZE 512,
GROUP 3 '/u01/app/oracle/oradata/ORA19C/redo03.log' SIZE 200M BLOCKSIZE 512
DATAFILE
'/u01/app/oracle/oradata/ORA19C/system01.dbf',
'/u01/app/oracle/oradata/ORA19C/undotbs01.dbf',
'/u01/app/oracle/oradata/ORA19C/sysaux01.dbf',
'/u01/app/oracle/oradata/ORA19C/example01.dbf',
'/u01/app/oracle/oradata/ORA19C/users01.dbf'
CHARACTER SET AL32UTF8
;-
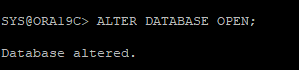
복구 작업 수행할게 있으면 하는데 없기 때문에 recover 할 필요가 없다는 메시지
RECOVER DATABASE

-
재생성한 control file sequence와 현재 redo log 의 sequence가 같기 때문에 그냥 open을 해도 된다.
ALTER DATABASE OPEN;
-
control file을 재생성하였기 때문에 temp 파일을 추가해줘야 한다.
alter tablespace temp add tempfile '$ORACLE_BASE/oradata/ORA19C/temp01.dbf' reuse;

ARCHIVE - 시나리오 24
data file, control file 손상
- 테이블 생성

- 수동 로그스위치도 발생
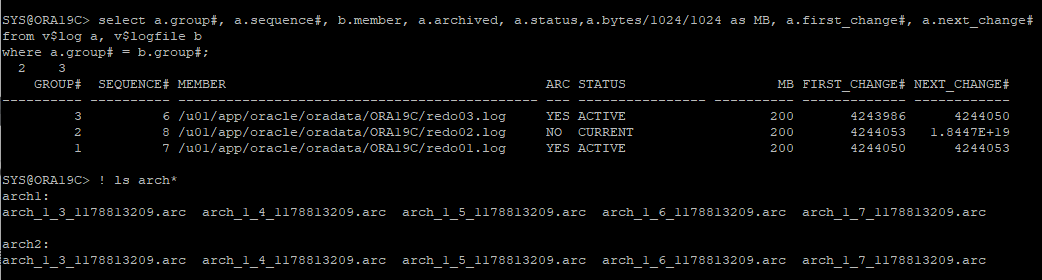
- control file, data file 삭제로 장애유발

- alert log에서도 확인할 수 있다.
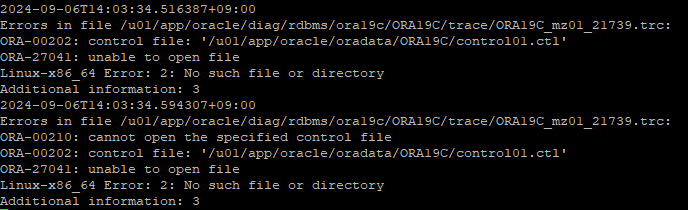
-
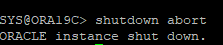
DB SHUTDOWN ABORT
-
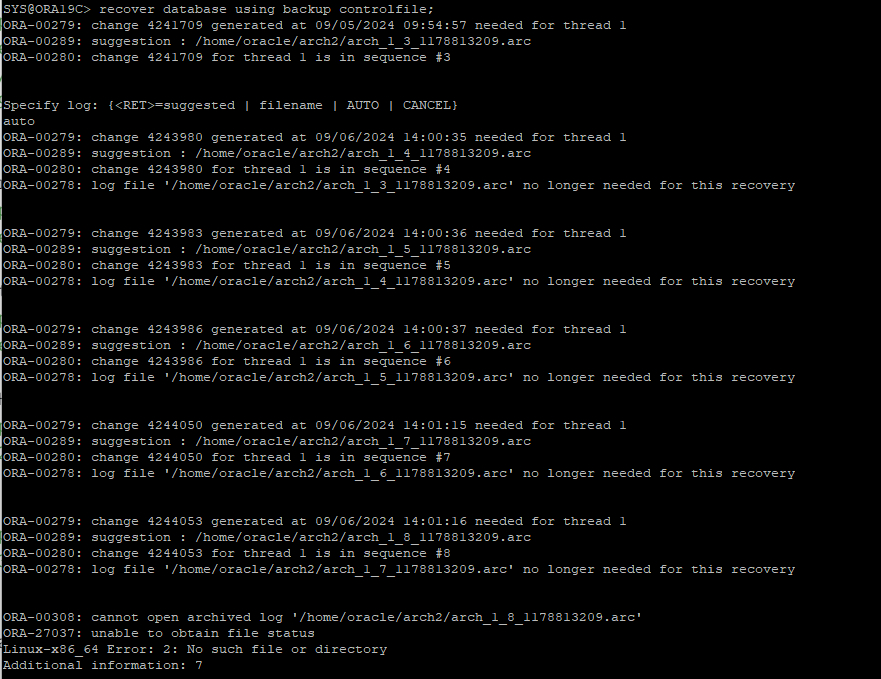
가장 최근의 백업 받은 control file, data file을 원래 위치에 restore

-
현재 정상 redo파일 입장에서는 restore한 control file이 예전 scn을 가지고 있기 때문에 using backup control 키워드를 사용해야 한다.
-
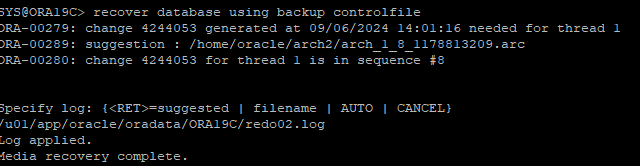
current한 redo log는 아카이브 파일이 없기 때문에 redo log 파일을 따로 지정해줘서 backup control 파일한테 마지막 복구라는 것을 지정해줘야 한다.
-
recover 한 백업 컨트롤 파일에 redo log 시퀀스 번호는 초기화 되었기 때문에 맞춰주기 위해 resetlogs 키워드로 db를 open해야한다.

-
current한 리두로그에 생성해 놓은 테이블이 그대로 있는걸 확인할 수 있다.
ARCHIVE - 시나리오 25
system data file, control file 손상
-
system file, control file 삭제로 장애유발

-
DB SHUTDOWN ABORT로 강제종료

-
가장 최근에 백업 받은 SYSTEM FILE, CONTROL FILE을 원래 위치에 RESTORE

-
백업 컨트롤 파일로 MOUNT 단계까지 실행
-
현재 정상 redo파일 입장에서는 restore한 control file이 예전 scn을 가지고 있기 때문에 using backup control 키워드를 사용해야 한다.
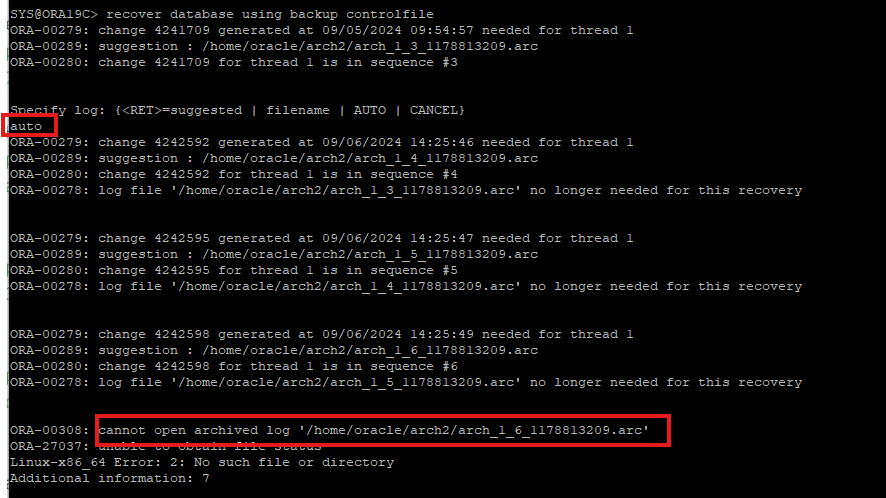
-
6번 시퀀스 리두로그 파일은 current한 redo log였기 때문에 아카이브 파일이 없다. 따라서 6번 시퀀스의 redo log 파일 주소를 직접 지정해줌으로써 마지막 recover 인걸 지정해줘야 한다.
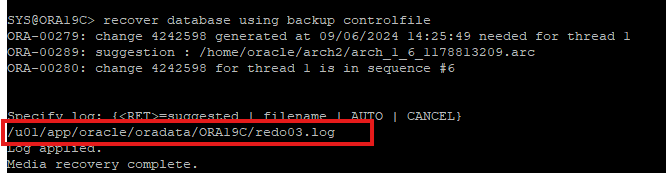
-
recover 한 백업 컨트롤 파일에 redo log 시퀀스 번호는 초기화 되었기 때문에 맞춰주기 위해 resetlogs 키워드로 db를 open해야한다.
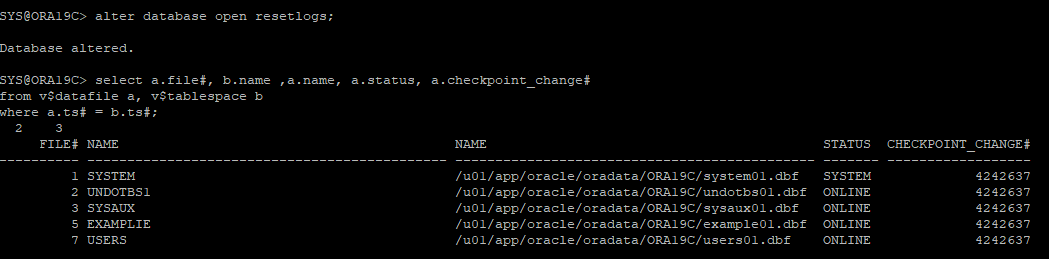
ARCHIVE - 시나리오 26
control file, redo log file 손상
-
현재 redo log 상태 및 archive 상태
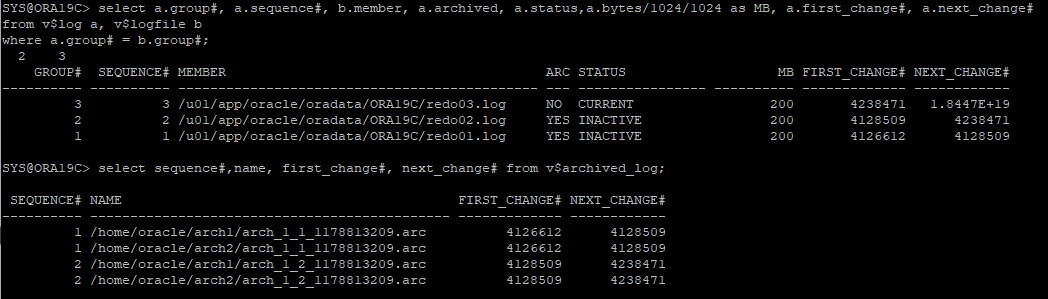
-
새로운 테이블 생성

-
수동으로 로그스위치 발생해서 아카이브 로그 파일 생성
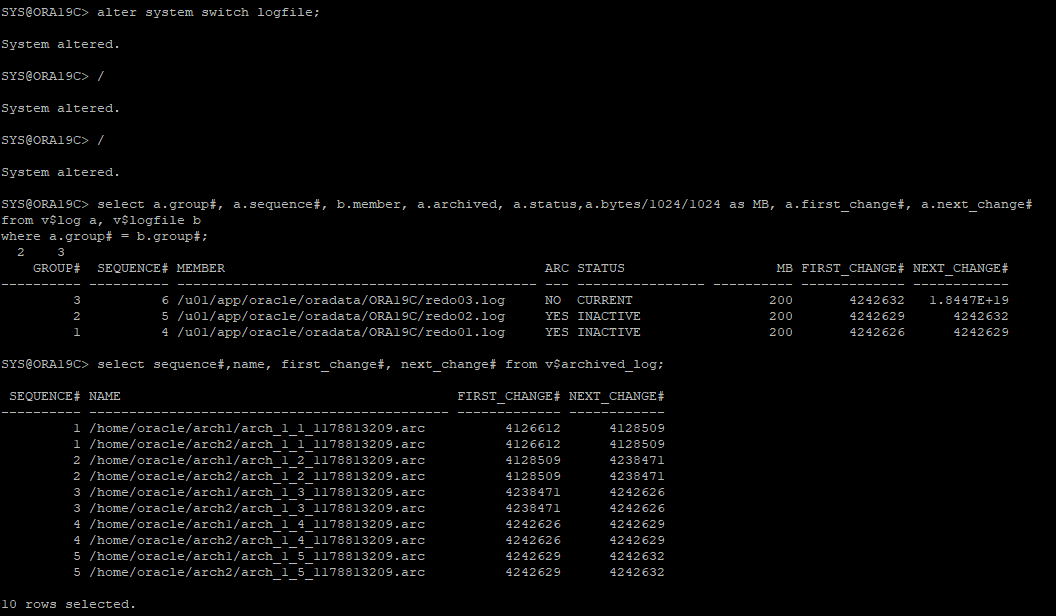
-
control file, redo log file 삭제해서 장애유발

-
DB SHUTDOWN ABORT
- DB가 비정상적으로 종료 되었기 때문에 data file의 scn은 서로 같지 않다. 따라서 instance recovery를 수행해야 하는데 current한 redo log 파일 마저 삭제되어 완전 복구를 할수 없으니, 불완전 복구로 진행해야 한다.

- 가장 최근에 백업 받은 control file 및 data file을 원래 위치로 restore
- redo log 파일은 필수 백업 파일이 아니기 때문에 restore 하지 않고 아카이브 로그 파일이 있기 때문에 상관 없다. 또한 나중에 dp를 open 할때 resetlogs로 하게 되면 자동으로 redo log 파일은 생성된다.
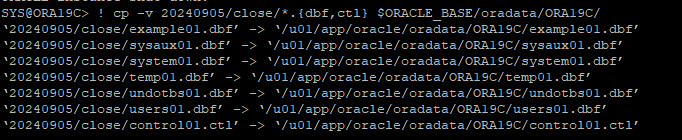
-
백업 control file을 가지고 DB를 MOUNT 단계까지만 실행
-
아카이브 로그 파일이 있는 시퀀스 까지는 recovery 하지만 current했던 redo log 파일은 아카이브 파일이 없기 때문에 current redo log 시퀀스에서는 cancel 한다.
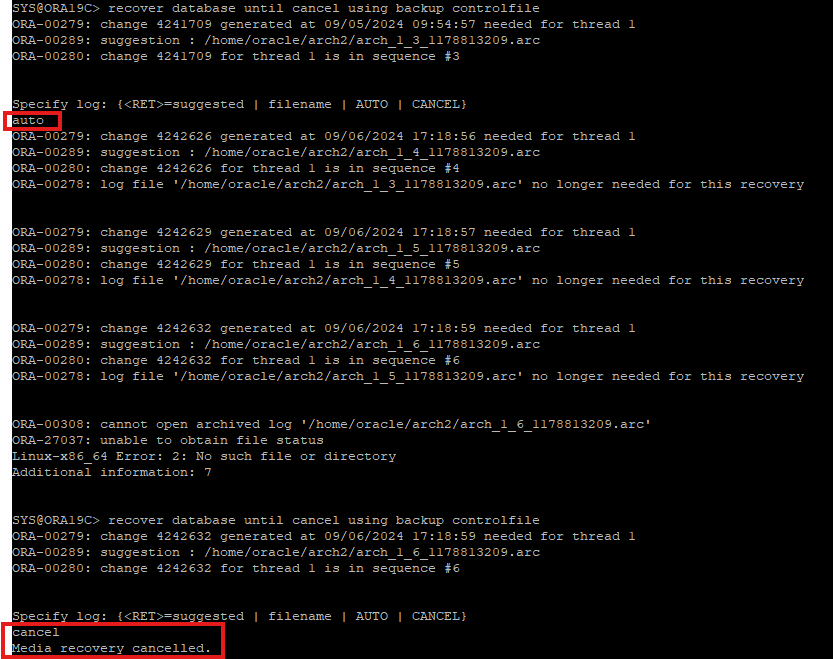
-
백업 컨트롤 파일을 아카이브 로그 파일을 사용해 recover 할때 redo log 정보 중 sequence 번호는 서로 맞지 않기 때문에 초기화 되었다. 그 상태에서 DB OPEN은 RESETLOGS로 해야하며 RESETLOGS는 컨트롤 파일에 입력되어있는 물리적으로 redo log file이 없다면 자동으로 생성도 해준다.

-
아카이브 로그 파일에 기록되어있던 생성 테이블도 정상적으로 조회된다.
ARCHIVE - 시나리오 27
example01.dbf, inactive redo log file, control file 손상
-
현재 redo log 상태 및 아카이브 로그 파일 상태
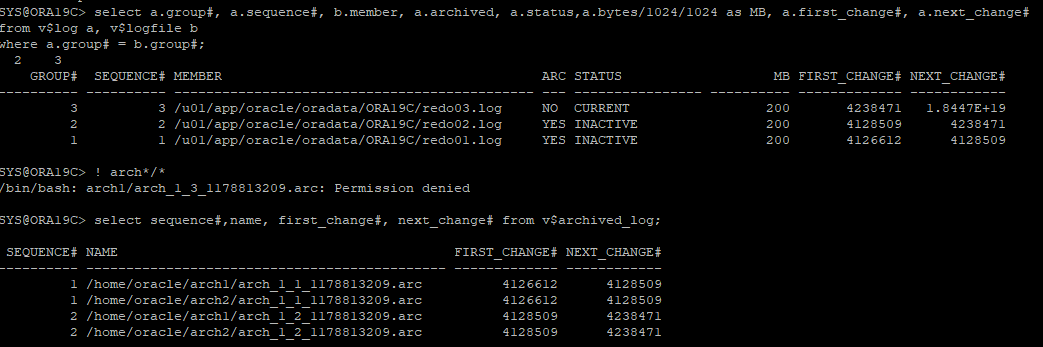
-
수동으로 로그 스위치 발생해서 아카이브 파일 생성
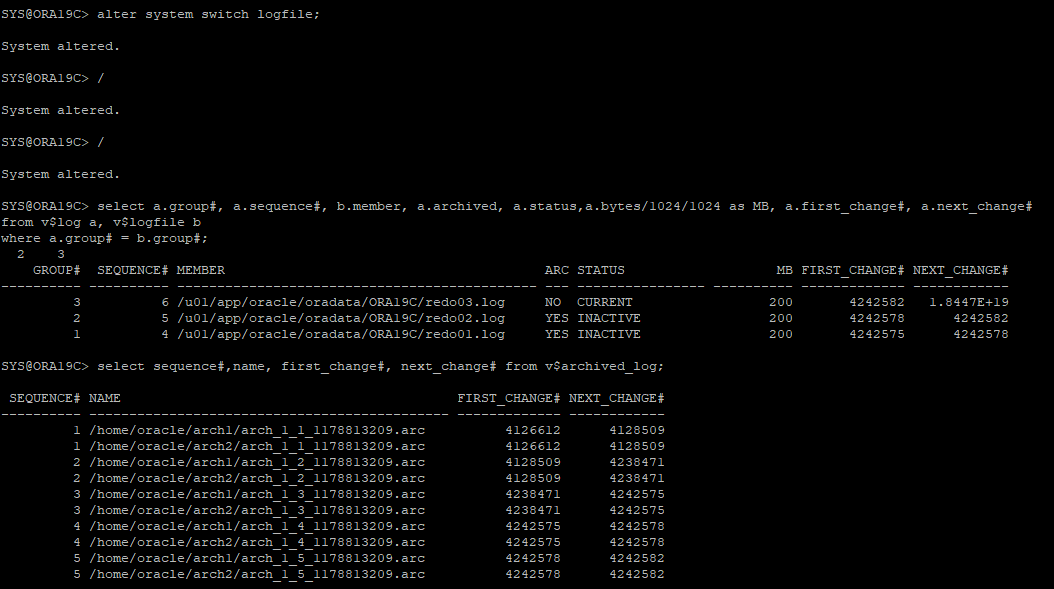
-
example01.dbf, incative한 redo log 파일 1개 , control file 삭제로 장애유발

-
DB SHUTDOWN ABORT로 비정상 종료

-
가장 최근에 백업 받아놓은 example01.dbf, control file 백업본 restore

-
백업 control file로 DB mount 단계까지 실행
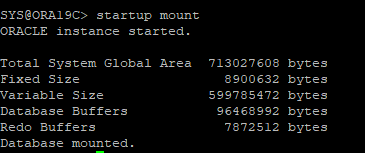
-
삭제한 inactive 한 redo log는 아카이브 파일로 가지고 있고, current한 리두도 redo log file에 존재 하기 때문에 완전 복구가 가능하다. 다만, restore한 control 파일이 아카이브 로그 파일들 보다는 old 하기 때문에 using backup controlfile 키워드를 사용해야 한다.
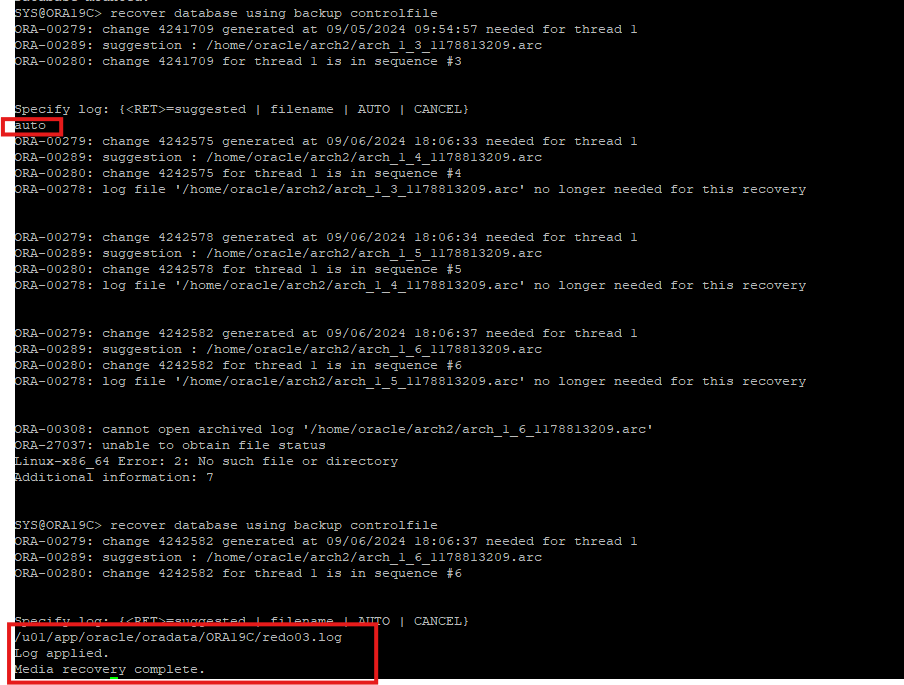
-
cancel base로 불완전하게 복구 하였기 때문에 resetlogs로 db를 open 해야 하고 resetlogs로 open 하게 되면 물리적으로 삭제되었던 redo02.log 파일도 자동생성 된다.

ARCHIVE - 시나리오 28
example01.dbf, inactive redo log file, control file 손상 후에 log switch가 발생 했을 경우
-
현재 redo log 상태 및 아카이브 로그 파일 상태
-
수동으로 로그 스위치 발생해서 아카이브 파일 생성
-
example01.dbf, incative한 redo log 파일 1개 , control file 삭제로 장애유발
-
강제 log switch 발생으로 hang 상태 유도
- 논리적으로 control file에는 current 파일이 갱신 되지만 물리적으로는 삭제된 redo log 파일에 대해서는 아카이브가 생성되지 않기 때문에 컨트롤 파일 redo 정보와 실제 아카이브 파일에는 갭이 생긴다.
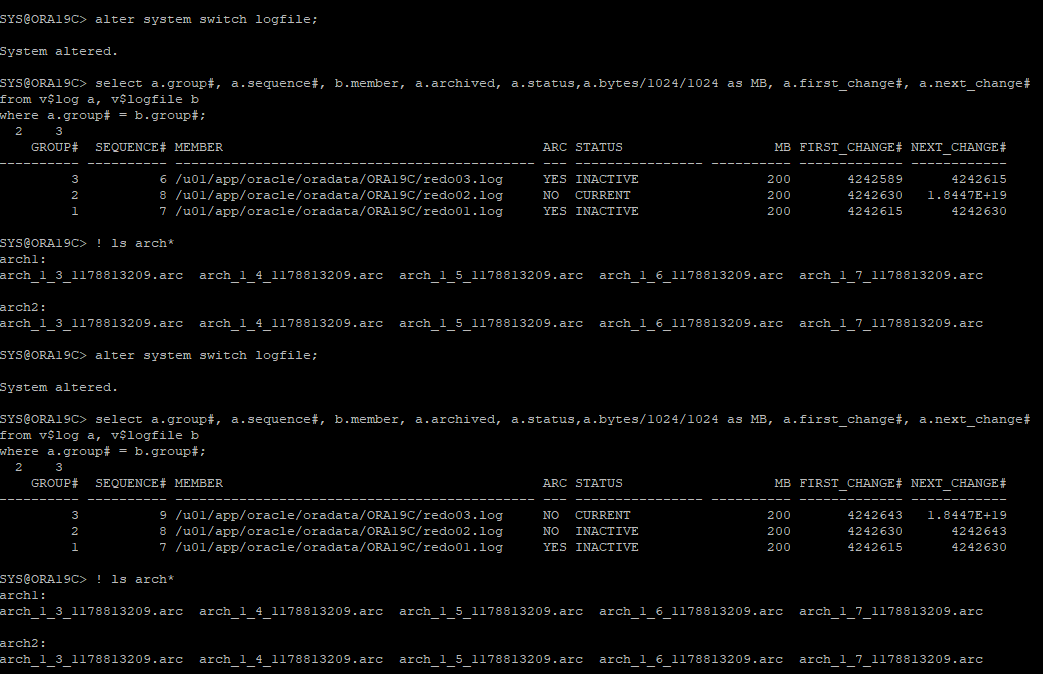
-
DB SHUTDOWN ABORT로 비정상종료 시킨다.

-
가장 최근에 백업받은 전체 data file과 control file을 restore 한다.
- redo 사이에 갭이 생겨 cancel base recover을 해야 하기 때문에 전체 data file을 restore 해야한다.
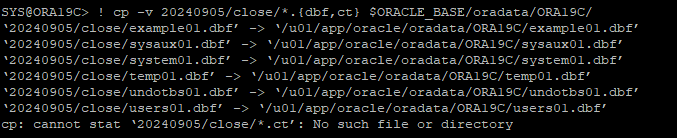
- restore한 백업 컨트롤 파일로 db를 mount 단계 까지 실행 한뒤 recover을 시도한다.
- restore한 컨트롤 파일은 아카이브 로그 파일의 scn 보다 낮기 때문에 using backup controlfile 키워드를 사용한다.
- 아카이브 파일이 있는 시점까지만 복구 가능하다.
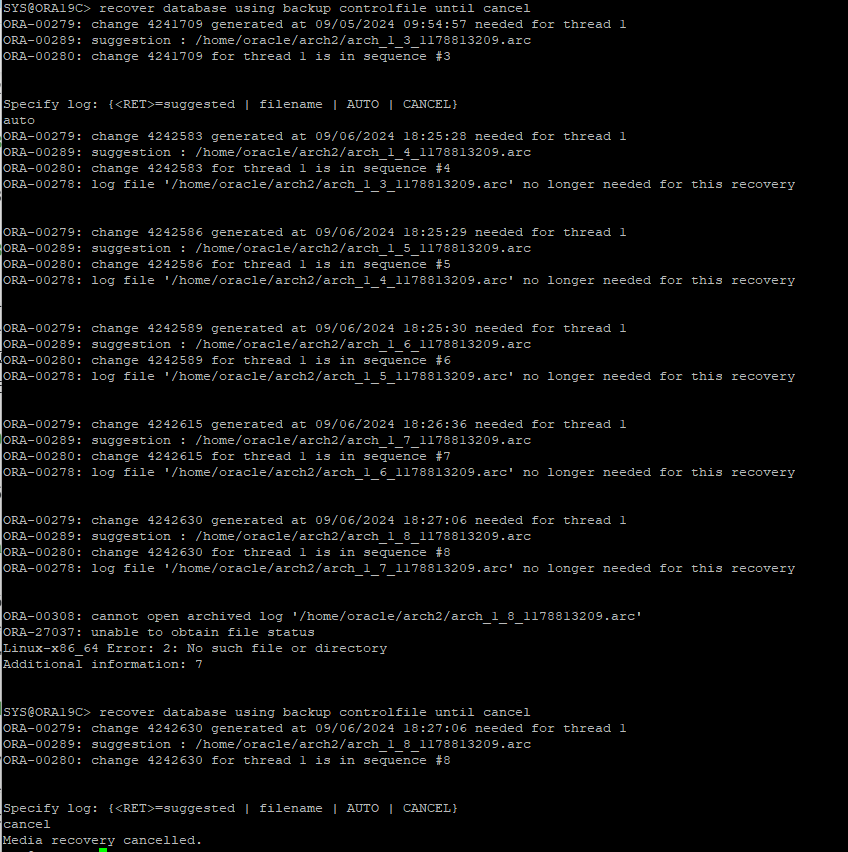
- DB를 RESETLOGS로 오픈하게 되면 물리적으로 없는 redo log 파일도 자동으로 생성해준다.

ARCHIVE - 시나리오 29
모든 데이터파일, 컨트롤 파일, 리두로그 파일 삭제(백업 이후 아카이브 정보 있을 경우)
-
현재 redo log 파일 상태 및 아카이브 로그 확인
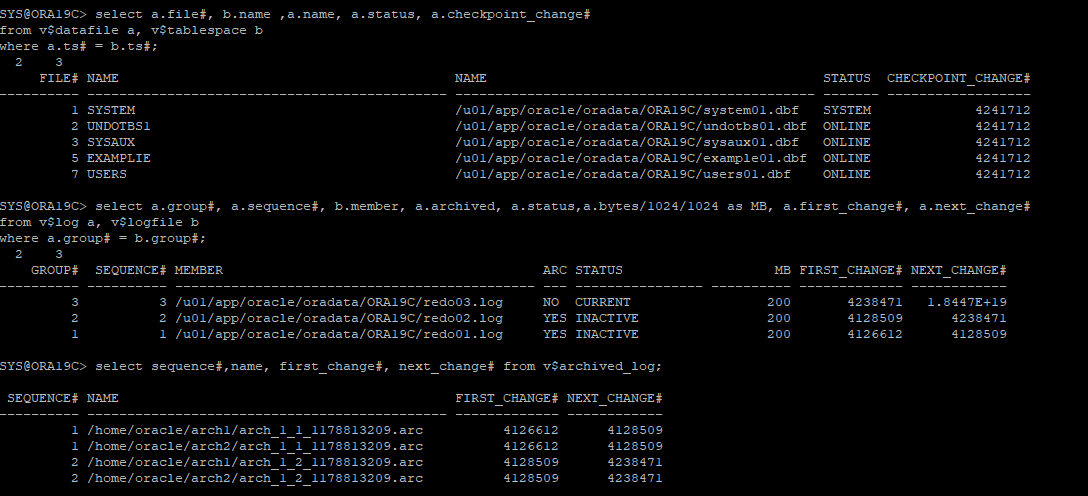
-
특정 데이터파일을 사용하는 테이블스페이스에 신규 테이블 생성
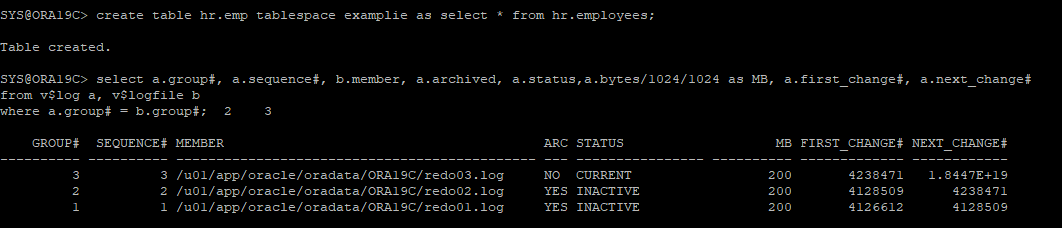
-
수동으로 로그스위치 발생해 아카이브 로그파일 생성
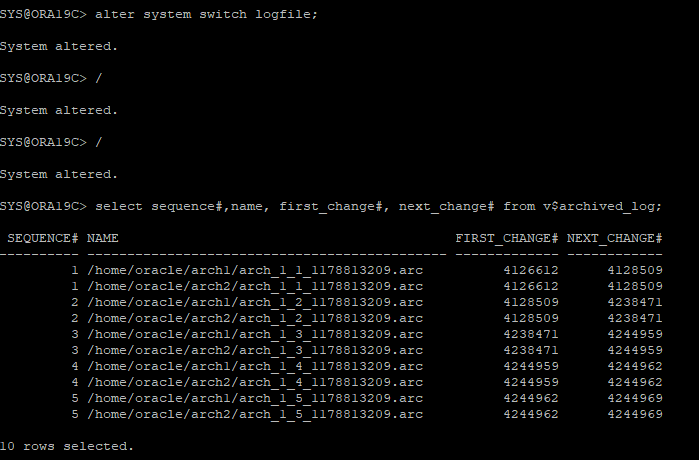
-
모든 데이터파일, 컨트롤파일, 리두로그 파일 삭제로 장애유발

-
DB 비정상적인 종료 후 다시 재가동 하지만 오류가 발생한다.
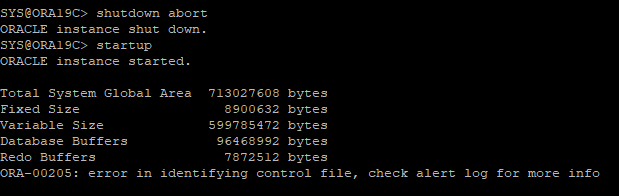
-
current한 리두 로그 파일이 없기 때문에 아카이브 로그 파일이 가지고 있는 시점까지 불완전 복구를 진행해야 한다. 따라서 가장 최근에 백업 받은 컨트롤 파일, 데이터 파일을 원래 위치에 restore 한다.
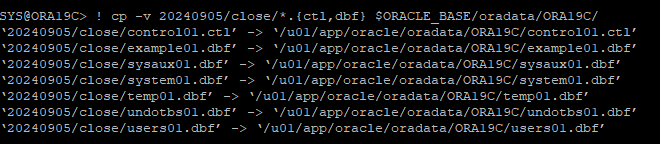
-
백업받은 컨트롤 파일로 DB를 MOUNT 단계까지 올리기
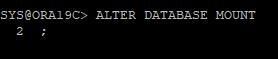
-
아카이브 로그파일을 이용해 cancel base recovery를 진행한다.
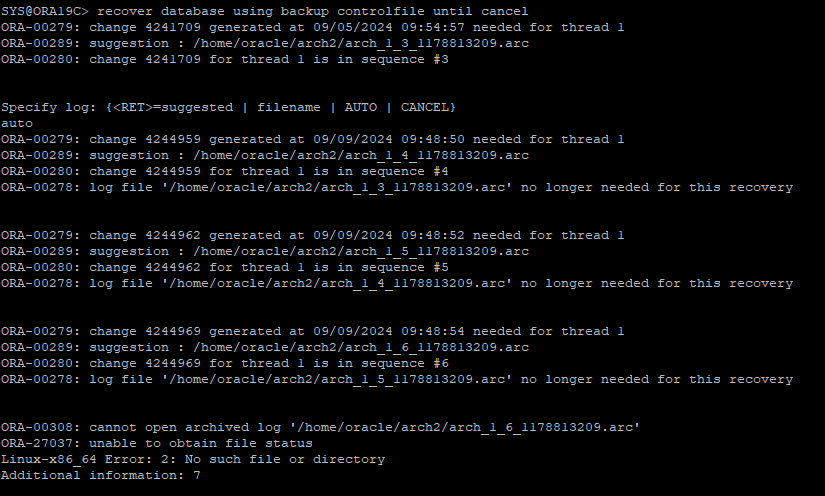
-
복구진행 하다보면 current redo log 파일은 아카이브가 없기 때문에 복구가 멈춘다.
우리는 current 리두로그 파일 직전까지 recover 하기 때문에 cancel 해주면 된다.
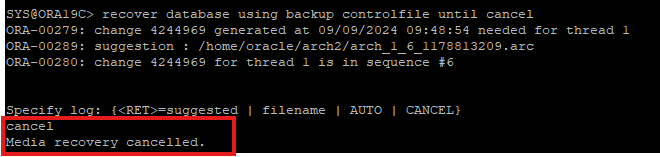
-
cancel base recovery로 복구하였기 때문에 DB를 open 할때는 resetlogs로 설정해야 하며, resetlogs로 설정 시 물리적으로 redo log 파일을 자동생성 해준다.

-
아카이브 로그 파일에 기록되어 있던 신규 테이블도 정상적으로 복구 된걸 확인할 수 있다.
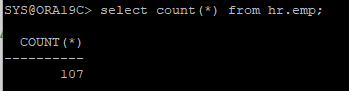
ARCHIVE - 시나리오 30
모든 데이터파일, 컨트롤 파일, 리두로그 파일, 아카이브 로그 파일 삭제
-
현재 redo log 파일 상태 및 아카이브 로그 확인
-
특정 데이터파일을 사용하는 테이블스페이스에 신규 테이블 생성
-
수동으로 로그스위치 발생해 아카이브 로그파일 생성
-
모든 데이터파일, 컨트롤파일, 리두로그 파일, 아카이브 로그 파일 삭제로 장애유발

-
DB 비정상적인 종료 후 다시 재가동 하지만 오류가 발생한다.
-
가장 최근에 백업 받은 control file과 data file을 원래 위치에 restore 한 후 백업 control 파일로 mount 단계 까지 올린다.
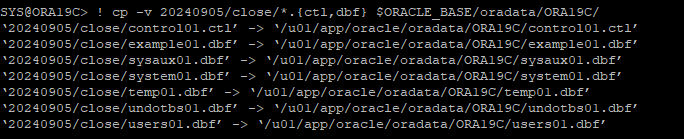
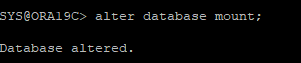
-
리두로그 파일, 아카이브 로그파일 모두 없기 때문에 백업 control 파일과 datafile이 가지고 있는 정보까지만 복구 해야한다.
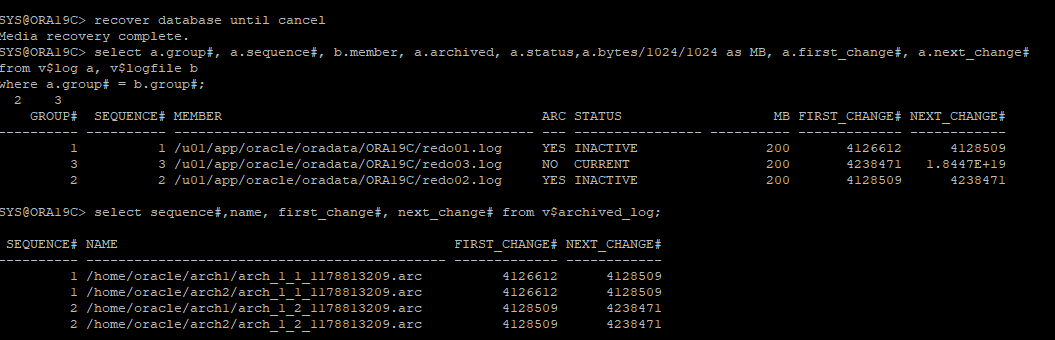
-
cancel base recovery로 복구 하였으니 DB를 OPEN 할때 RESETLOGS로 실행해야 한다.
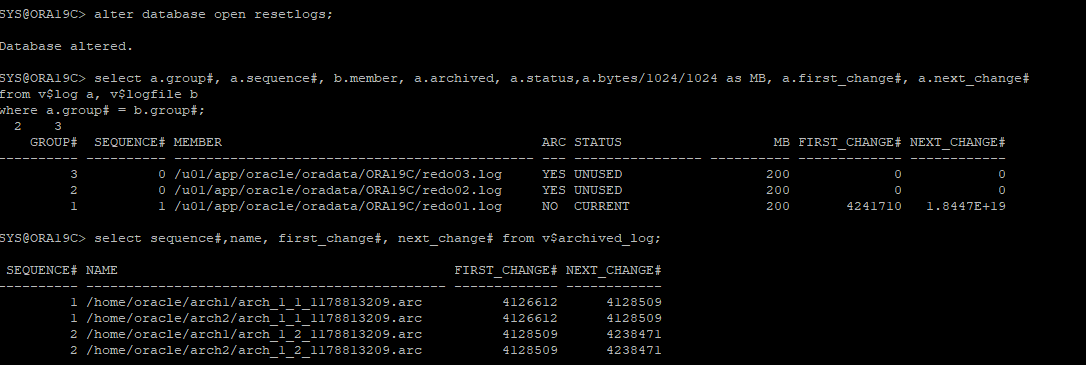
-
당연히 과거 백업 데이터 파일에는 새롭게 생성한 신규 테이블이 존재하지 않는다.
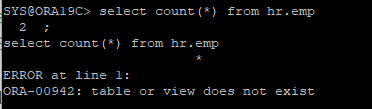
ARCHIVE - 시나리오 31
데이터베이스가 정상 종료 후에 control file 손상되었고 백업한 controlfile 내용과 현재 data file 정보가 틀린 경우 복구
-
새로운 테이블스페이스 생성
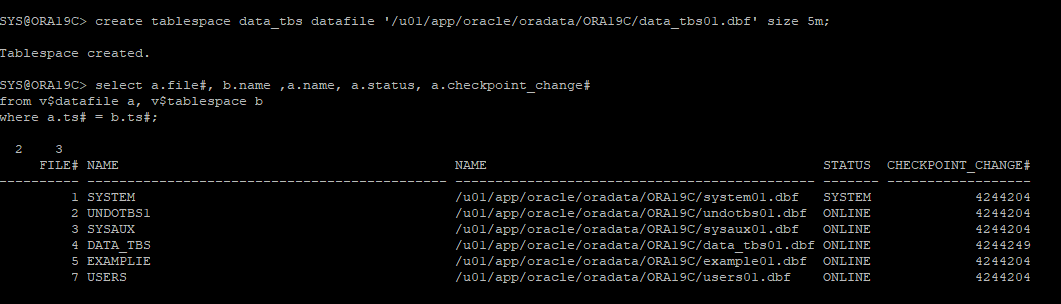
-
신규 테이블스페이스로 지정해서 테이블 생성

-
DB 정상종료
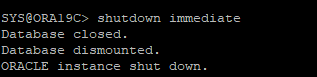
-
control file 삭제로 장애유발

-
DB STARTUP 해보지만 오류 발생
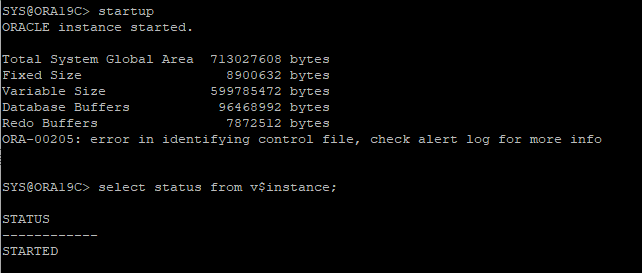
-
가장 최근에 백업 받은 control file을 원래 위치에 restore

-
redo log 파일을 이용해서 control file을 recover 하지만 redo log파일이 가지고 있는 control file 정보와 백업 control file의 정보가 달라 완전복구 불가
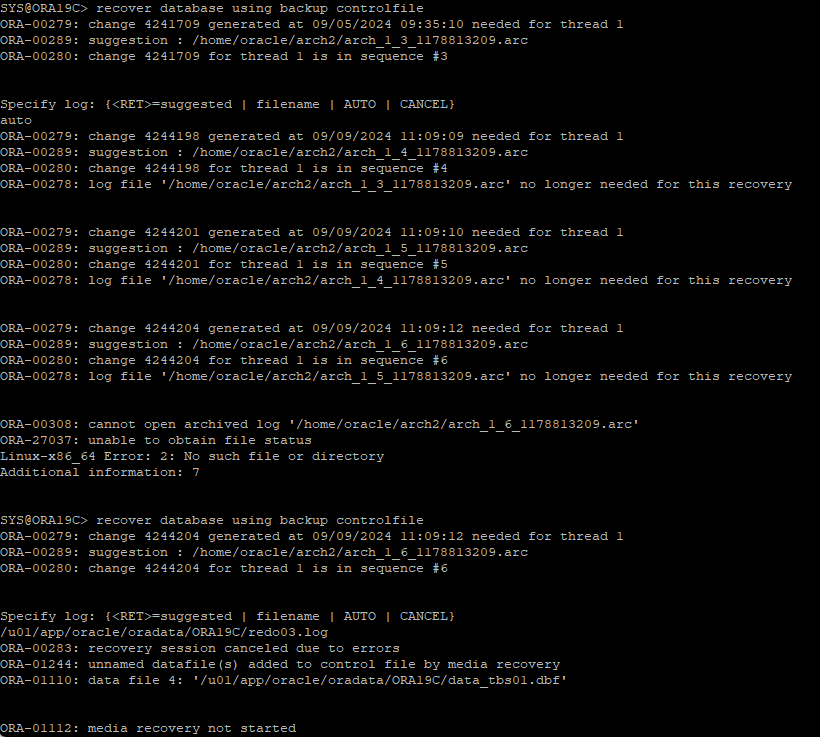
-
백업 control file을 가지고 trace 파일 생성

-
trace 파일을 확인해보면 알수 없는 이름의 데이터파일이 생성되어 있는데 이전에 생성한 신규데이터파일 이름으로 변경작업 해야한다.
STARTUP NOMOUNT
CREATE CONTROLFILE REUSE DATABASE "ORA19C" NORESETLOGS ARCHIVELOG
MAXLOGFILES 16
MAXLOGMEMBERS 3
MAXDATAFILES 100
MAXINSTANCES 8
MAXLOGHISTORY 292
LOGFILE
GROUP 1 '/u01/app/oracle/oradata/ORA19C/redo01.log' SIZE 200M BLOCKSIZE 512,
GROUP 2 '/u01/app/oracle/oradata/ORA19C/redo02.log' SIZE 200M BLOCKSIZE 512,
GROUP 3 '/u01/app/oracle/oradata/ORA19C/redo03.log' SIZE 200M BLOCKSIZE 512
DATAFILE
'/u01/app/oracle/oradata/ORA19C/system01.dbf',
'/u01/app/oracle/oradata/ORA19C/undotbs01.dbf',
'/u01/app/oracle/oradata/ORA19C/sysaux01.dbf',
--'/u01/app/oracle/product/19.3.0/dbhome_1/dbs/UNNAMED00004', recover을 시도해서 생긴 데이터파일 주소
'/u01/app/oracle/oradata/ORA19C/data_tbs01.dbf',
'/u01/app/oracle/oradata/ORA19C/example01.dbf',
'/u01/app/oracle/oradata/ORA19C/users01.dbf'
CHARACTER SET AL32UTF8
;- control file 재생성 후 DB OPEN 해주면 된다.
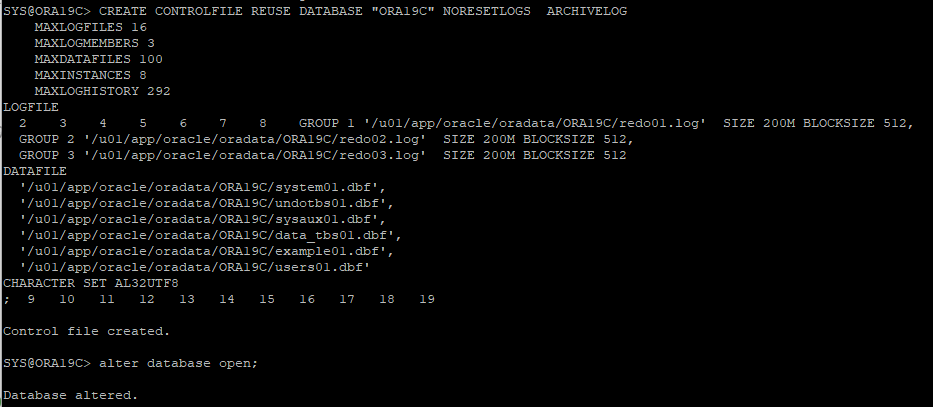
ARCHIVE - 시나리오 32
데이터베이스가 비정상 종료 후에 control file 손상되었고 백업한 controlfile 내용과 현재 data file 정보가 틀린 경우 복구
-
새로운 테이블스페이스 생성
-
신규 테이블스페이스로 지정해서 테이블 생성
-
DB 비정상종료

-
control file 삭제로 장애유발
-
DB STARTUP 해보지만 오류 발생
-
가장 최근에 백업 받은 control file을 원래 위치에 restore
-
redo log 파일을 이용해서 control file을 recover 하지만 redo log파일이 가지고 있는 control file 정보와 백업 control file의 정보가 달라 완전복구 불가
-
백업 control file을 가지고 trace 파일 생성
-
trace 파일을 확인해보면 알수 없는 이름의 데이터파일이 생성되어 있는데 이전에 생성한 신규데이터파일 이름으로 변경작업 해야한다.
STARTUP NOMOUNT
CREATE CONTROLFILE REUSE DATABASE "ORA19C" NORESETLOGS ARCHIVELOG
MAXLOGFILES 16
MAXLOGMEMBERS 3
MAXDATAFILES 100
MAXINSTANCES 8
MAXLOGHISTORY 292
LOGFILE
GROUP 1 '/u01/app/oracle/oradata/ORA19C/redo01.log' SIZE 200M BLOCKSIZE 512,
GROUP 2 '/u01/app/oracle/oradata/ORA19C/redo02.log' SIZE 200M BLOCKSIZE 512,
GROUP 3 '/u01/app/oracle/oradata/ORA19C/redo03.log' SIZE 200M BLOCKSIZE 512
DATAFILE
'/u01/app/oracle/oradata/ORA19C/system01.dbf',
'/u01/app/oracle/oradata/ORA19C/undotbs01.dbf',
'/u01/app/oracle/oradata/ORA19C/sysaux01.dbf',
--'/u01/app/oracle/product/19.3.0/dbhome_1/dbs/UNNAMED00004', recover을 시도해서 생긴 데이터파일 주소
'/u01/app/oracle/oradata/ORA19C/data_tbs01.dbf',
'/u01/app/oracle/oradata/ORA19C/example01.dbf',
'/u01/app/oracle/oradata/ORA19C/users01.dbf'
CHARACTER SET AL32UTF8
;-
control file 재생성 후 db 비정상적인 종료로 인해 datafile의 checkpont scn 수위가 맞지 않아 INSTANCE RECOVER을 해줘야 한다.
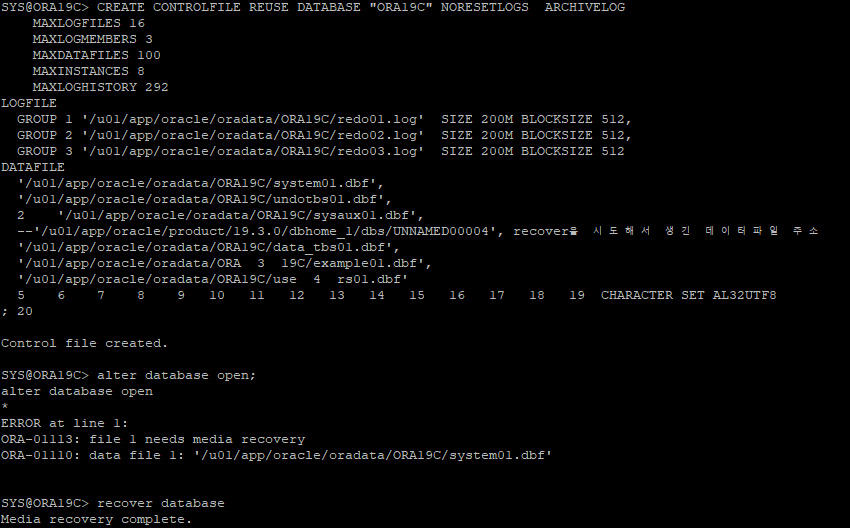
-
DB를 OPEN 하면 정상적으로 DB가 가동된다.
ARCHIVE - 시나리오 33
시간을 기준으로 데이터베이스 복구
-
신규 테이블 생성

-
데이터 삽입

-
수동으로 log switch 발생
-
신규테이블이 생성되어있던 테이블스페이스 삭제

-
users 테이블스페이스에 신규 테이블 생성 후 데이터 추가
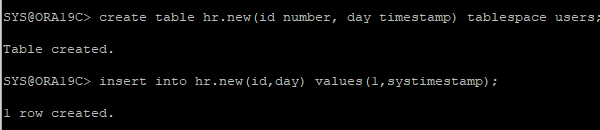
-
employees 테이블을 조회해 봤지만 테이블스페이스 삭제로 조회되지 않는다.
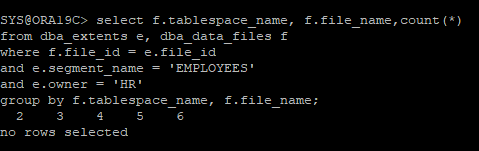
-
DB SHUTDOWN ABORT

-
복구하려고 하는 테이블스페이를 가지고 있는 가장 최근에 close 백업 control file, datafile을 restore
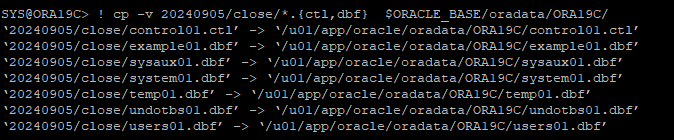
-
백업 control file을 이용해 DB MOUNT 단계까지 실행
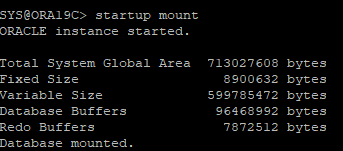
-
백업 control file 시점의 테이블스페이스 및 리두로그 파일 상태 확인
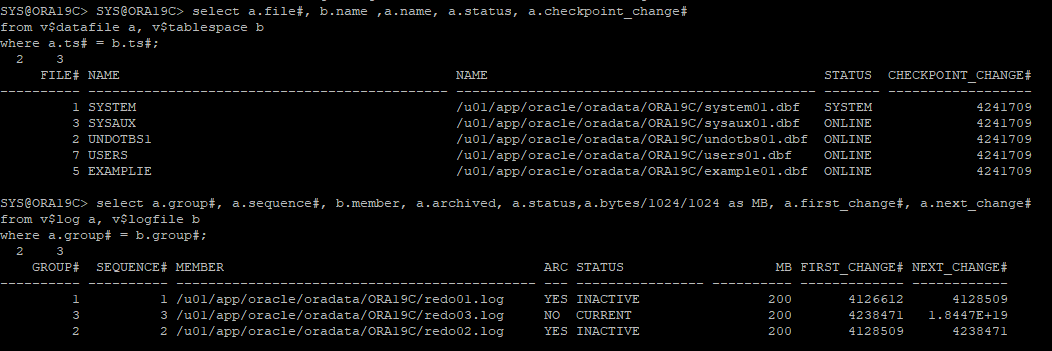
-
current 한 redo 까지 recover 할 수 있는 아카이브 파일이 존재하는지 확인

-
alert log 에서 테이블스페이스를 drop 한 시간 확인
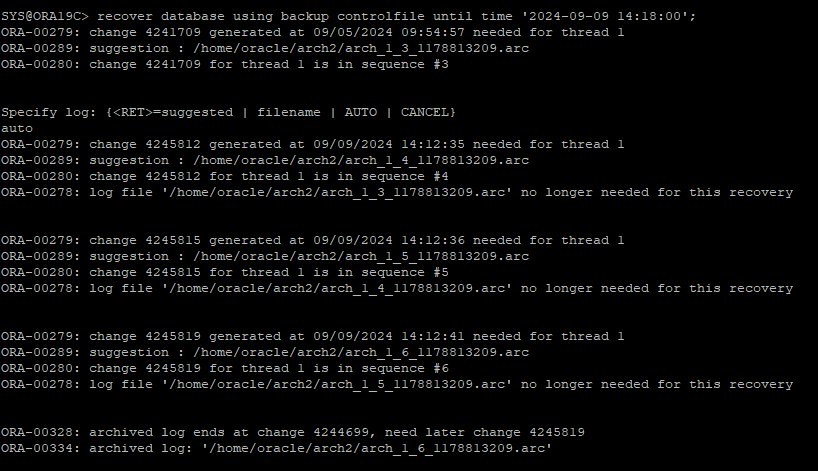
 - 원래 drop한 시간은 14:19 이지만 그 이전까지 백업이 필요하기 때문에
- 원래 drop한 시간은 14:19 이지만 그 이전까지 백업이 필요하기 때문에 2024-09-09 14:18:00으로 설정 하고 time base recovery를 해야한다. -
세션의 date format을 alert log에 표시되는 형식으로 변경해야한다.
alter session set nls_date_format = 'yyyy-mm-dd hh24:mi:ss';

-
time base recovery를 수행
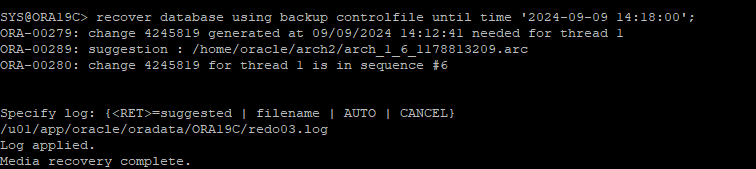
- recover를 수행하다보면 cancel base recovery 처럼 막히는 부분이 발생하는데, 14:18분의 redo가 current한 redo 였기 때문에 따로 지정해줘야한다.
-
current redo는 따로 지정
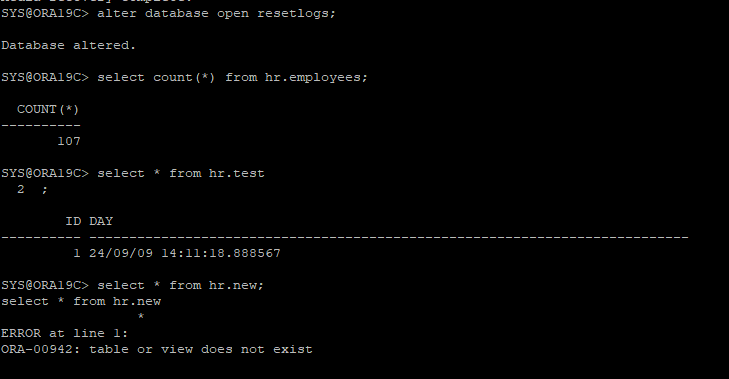
-
DB는 resetlogs로 open 하고 생성 테이블들을 조회해본다.
- 백업 시점이 hr.test 테이블의 삭제 직전 이기 때문에 hr.test는 조회되지만 hr.test 삭제 이후에 생성한 hr.new 테이블은 조회되지 않는걸 확인할 수 있다.
ARCHIVE - 시나리오 34
특정한 테이블 삭제한 후 시간을 기준으로 복구
-
수동으로 log switch 를 발생해서 alert log에 current 시퀀스의 redo log 파일 확인

-
특정 테이블을 PURGE로 삭제
- 테이블을 삭제한다고 alert log에는 기록되지 않는다.

-
DB 비정상적인 종료

-
time base recovery를 해야하기 때문에 가장 최근 control file,모든 datafile를 restore 한다.
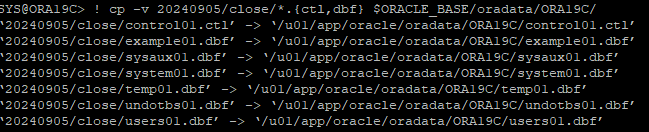
-
백업 control file로 DB mount 단계까지 실행
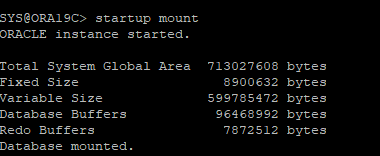
-
세션 date 포맷 설정

-
time base recovery로 진행
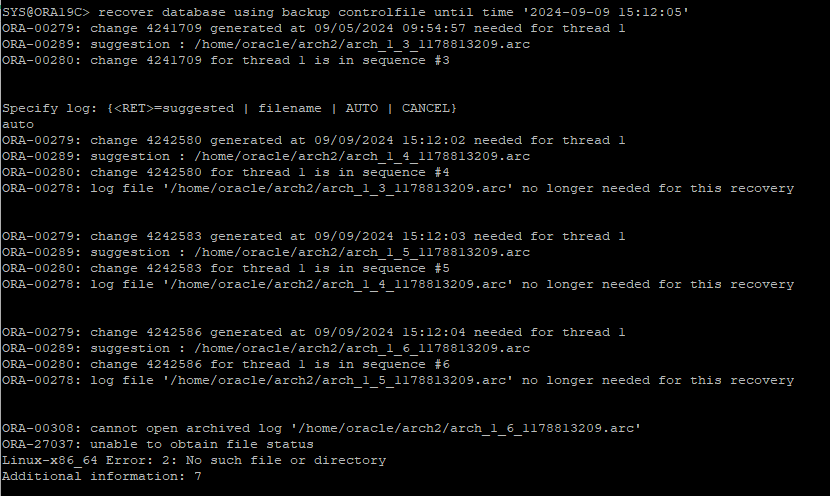
-
current 한 리두가 살아 있기 때문에 current한 리두는 따로 주소를 지정해줘야 한다.
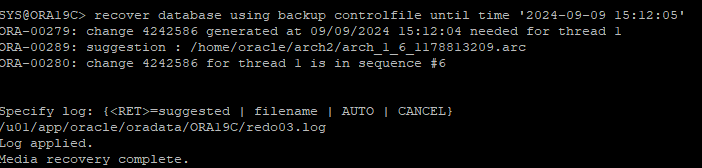
-
DB resetlogs로 open 후 삭제했었던 테이블이 잘 복구 되었는지 확인
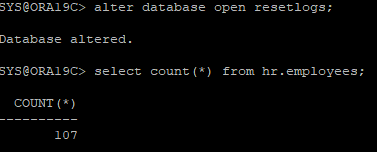
ARCHIVE - 시나리오 35
특정한 테이블에서 truncate을 잘못 수행한 후 시간을 기준으로 복구
-
수동으로 log switch 발생
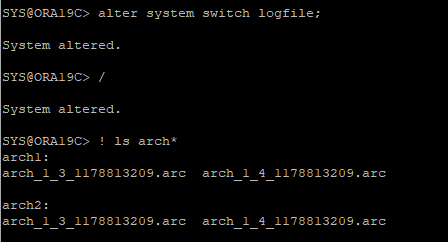
-
현재 current한 redo log file 확인

-
신규 테이블 생성후 데이터 추가
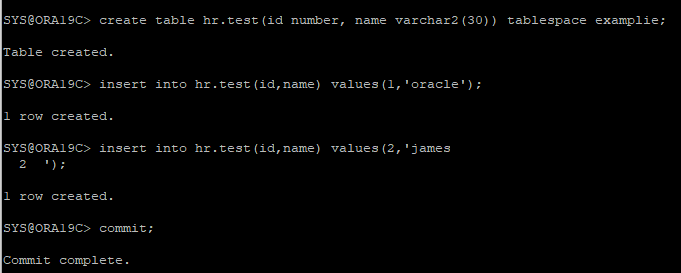
-
다시 log switch 발생 후 current한 redo log 확인
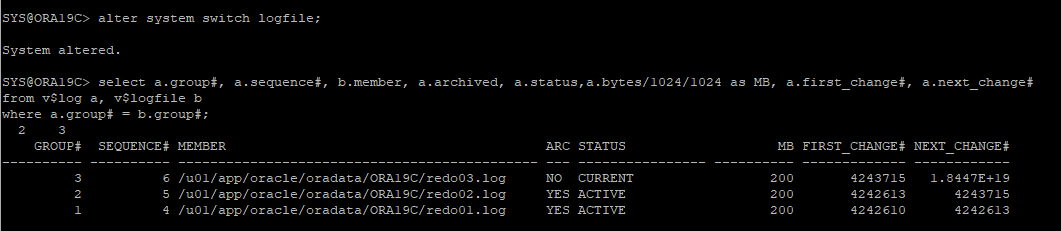
-
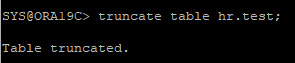
생성했던 테이블을 TRUNCATE 한다.
-
log miner 해야하는 redo log file 설정
begin
dbms_logmnr.add_logfile(logfilename=>'/u01/app/oracle/oradata/ORA19C/redo03.log', options=>dbms_logmnr.new); -- 처음 분석 대상 파일은 new
dbms_logmnr.add_logfile(logfilename=>'/u01/app/oracle/oradata/ORA19C/redo02.log', options=>dbms_logmnr.addfile); -- 이후부터는 addfile로 진행
end;
/- 설정된 redo log file 확인
select db_name, filename from v$logmnr_logs;
- redo 분석 시작
begin
dbms_logmnr.start_logmnr(options=>dbms_logmnr.dict_from_online_catalog);--분석기
end;
/- 분석 결과 확인
- 분석 결과로 truncate 한 시간을 확인할 수 있다.
select to_char(timestamp,'yyyy-mm-dd hh24:mi:ss') as timestamp, operation,sql_redo, sql_undo from v$logmnr_contents where seg_name = 'TEST';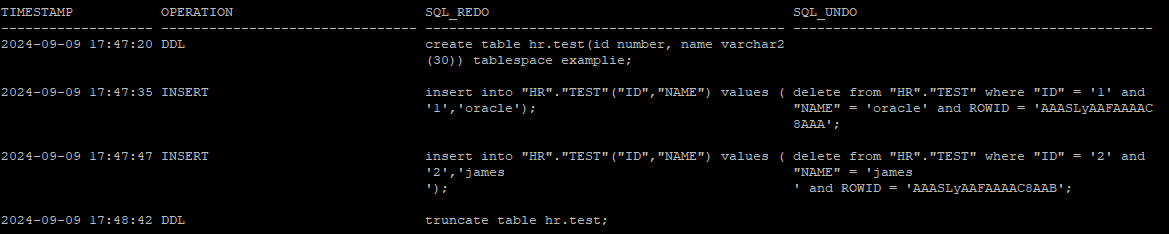
- 분석 종료
execute dbms_logmnr.end_logmnr;-
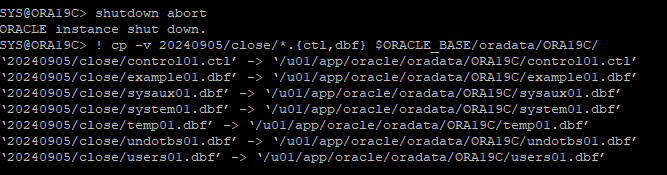
DB 비정상 종료 후 TRUNCATE 하기 이전의 가장 최근 백업 control file, data file을 원래 위치에 restore 한다.
-
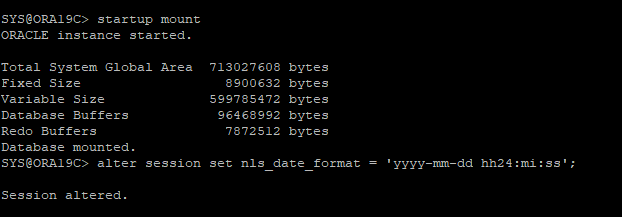
백업 control file로 DB MOUNT 단계까지 실행 후 세션 DATAE 포맷 변경
-
log miner로 확인한 TRUNCATE 시점보다 조금 앞으로 TIME BASE RECOVERY를 수행한다.
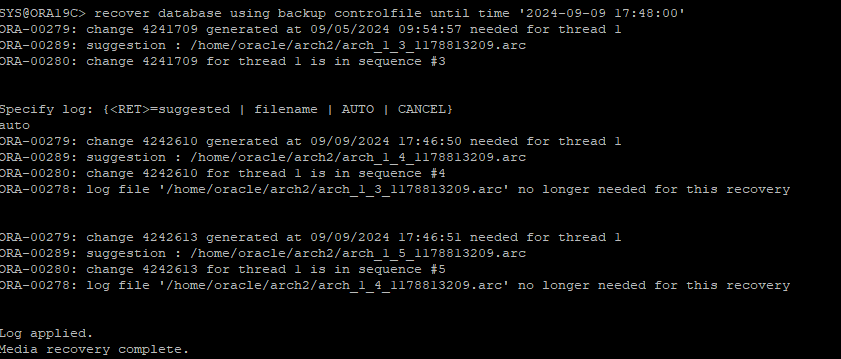
-
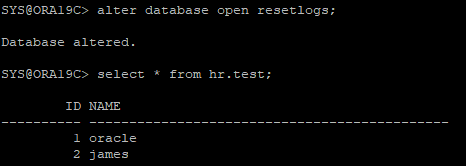
DB는 RESETLOGS로 OPEN 해야하며, TRUNCATE 되기 전의 데이터가 온전히 살아 있는걸 확인할 수 있다.
ARCHIVE - 시나리오 36
특정한 테이블에서 DML 작업을 잘못 수행한 후 시간을 기준으로 복구
- supplemental 데이터베이스 파라미터 YES로 설정
SELECT supplemental_log_data_min FROM v$database;
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;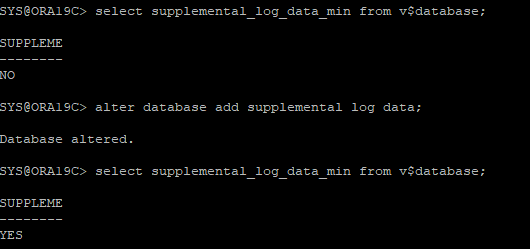
-
수동으로 log switch 발생
-
현재 current한 redo log file 확인
-
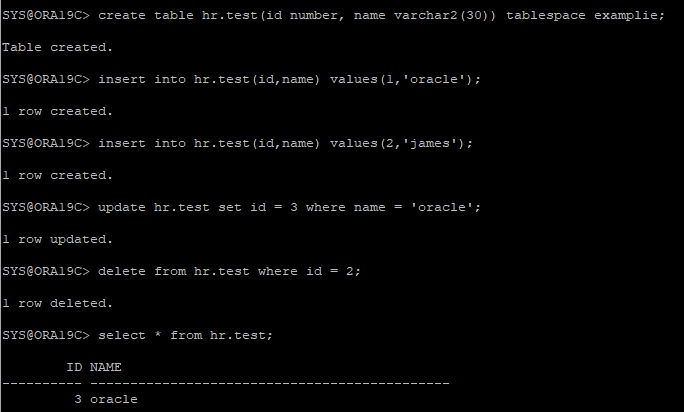
신규 테이블 생성후 DML작업
LOG MINER 작업
- log miner 해야할 redo log file 설정(아카이브에도 적용 가능하다)
begin
dbms_logmnr.add_logfile(logfilename=>'/u01/app/oracle/oradata/ORA19C/redo02.log', options=>dbms_logmnr.new); -- 처음 분석 대상 파일은 new
dbms_logmnr.add_logfile(logfilename=>'/u01/app/oracle/oradata/ORA19C/redo01.log', options=>dbms_logmnr.addfile); -- 이후부터는 addfile로 진행
end;
/- log miner 설정된 redo log 파일 확인
select db_name, filename from v$logmnr_logs;- redo 분석 시작
begin
dbms_logmnr.start_logmnr(options=>dbms_logmnr.dict_from_online_catalog);--분석기
end;
/- 분석 결과 확인
- 분석 결과로 DML 한 시간을 확인할 수 있다.
select to_char(timestamp,'yyyy-mm-dd hh24:mi:ss') as timestamp, operation,sql_redo, sql_undo from v$logmnr_contents where seg_name = 'TEST';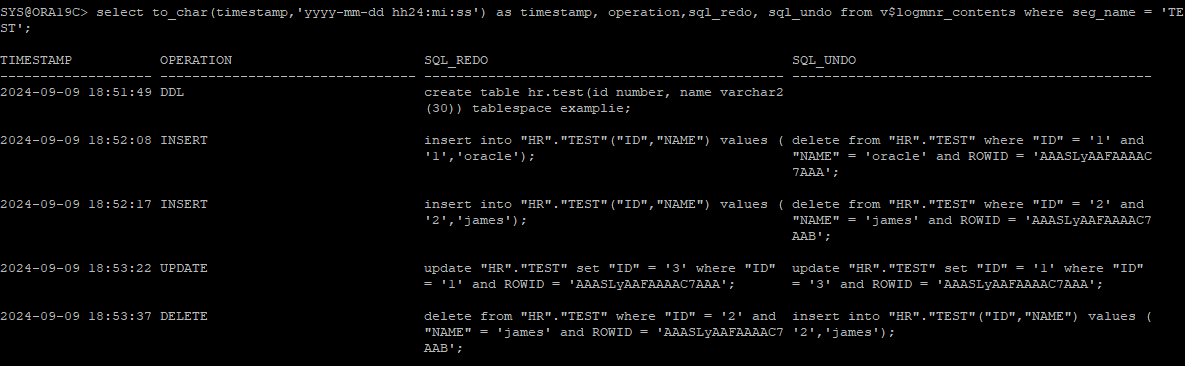
- 분석 종료
execute dbms_logmnr.end_logmnr;
-
DB 비정상 종료 후 TRUNCATE 하기 이전의 가장 최근 백업 control file, data file을 원래 위치에 restore 한다.
-
백업 control file로 DB MOUNT 단계까지 실행 후 세션 DATAE 포맷 변경
-
log miner로 확인한 특정 DML 시점보다 조금 앞으로 TIME BASE RECOVERY를 수행한다.
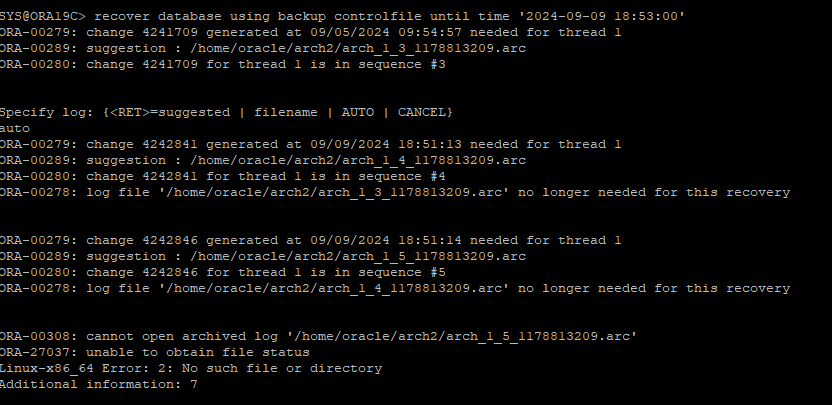
-
recover 시점이 current한 redo log file까지 복구 해야해서 current redo log file은 따로 지정해줘야 한다.
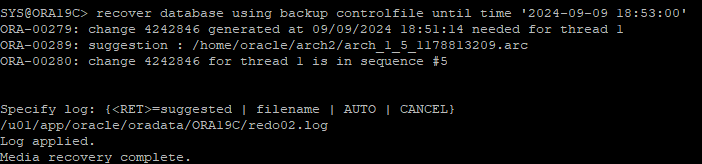
-
DB는 RESETLOGS로 OPEN

ARCHIVE - 시나리오 37
유저를 잘못 삭제한 후 시간을 기준으로 복구
- supplemental 데이터베이스 파라미터 YES로 설정
SELECT supplemental_log_data_min FROM v$database;
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
-
수동으로 log switch 발생
-
현재 current한 redo log file 확인
-
신규 테이블 생성

-
유저 삭제 후 데이터 조회를 하면 조회되지 않는다.
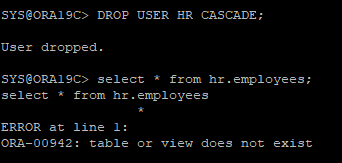
LOG MINER 작업
- log miner 해야할 redo log file 설정(아카이브에도 적용 가능하다)
begin
dbms_logmnr.add_logfile(logfilename=>'/u01/app/oracle/oradata/ORA19C/redo02.log', options=>dbms_logmnr.new); -- 처음 분석 대상 파일은 new
dbms_logmnr.add_logfile(logfilename=>'/u01/app/oracle/oradata/ORA19C/redo01.log', options=>dbms_logmnr.addfile); -- 이후부터는 addfile로 진행
end;
/- log miner 설정된 redo log 파일 확인
select db_name, filename from v$logmnr_logs;- redo 분석 시작
begin
dbms_logmnr.start_logmnr(options=>dbms_logmnr.dict_from_online_catalog);--분석기
end;
/- 분석 결과 확인
- 분석 결과로 유저를 삭제한 시간을 확인할 수 있다.
select to_char(timestamp,'yyyy-mm-dd hh24:mi:ss') as timestamp, operation,sql_redo, sql_undo from v$logmnr_contents where seg_name = 'TEST';
- 분석 종료
execute dbms_logmnr.end_logmnr;
-
DB 비정상 종료 후 TRUNCATE 하기 이전의 가장 최근 백업 control file, data file을 원래 위치에 restore 한다.
-
백업 control file로 DB MOUNT 단계까지 실행 후 세션 DATAE 포맷 변경
-
log miner로 확인한 특정 DDL 시점보다 조금 앞으로 TIME BASE RECOVERY를 수행한다.
-
recover 시점이 current한 redo log file까지 복구 해야해서 current redo log file은 따로 지정해줘야 한다.
-
DB는 RESETLOGS로 OPEN
-
복구한 유저가 정상적으로 조회된다.
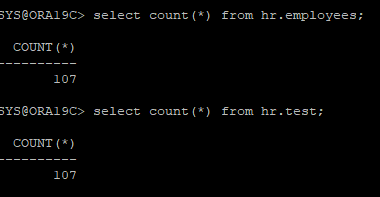
ARCHIVE - 시나리오 38
temp DB로 복구
-
supplemental log data를 활성화
-
수동으로 로그스위치 발생
-
특정 유저 삭제
log miner
- 분석해야할 리두로그 파일 설정
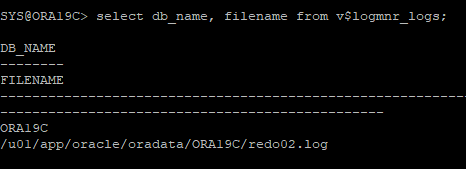
execute dbms_logmnr.add_logfile(logfilename=>'/u01/app/oracle/oradata/ORA19C/redo02.log', options=> dbms_logmnr.new);-
설정한 리두로그파일 확인
-
분석 시작
begin
dbms_logmnr.start_logmnr(options=>dbms_logmnr.dict_from_online_catalog);--분석기
end;
/- 분석 결과 확인
select to_char(timestamp,'yyyy-mm-dd hh24:mi:ss') as timestamp, operation,sql_redo, sql_undo from v$logmnr_contents where seg_owner = 'HR';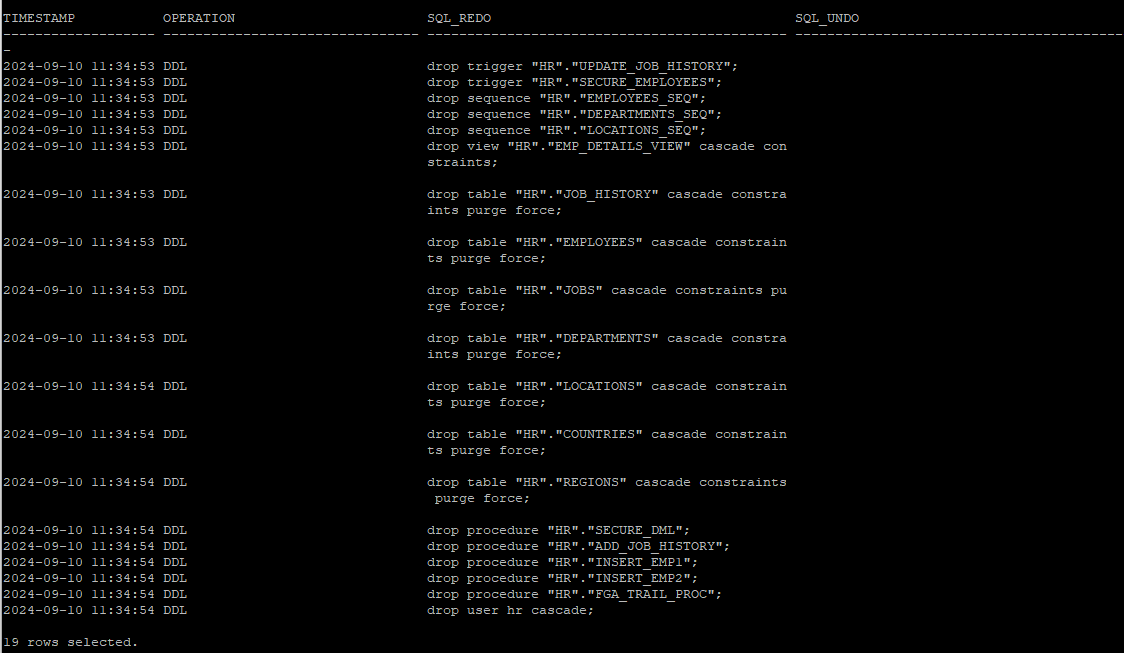
- 분석 종료
execute dbms_logmnr.end_logmnr;-
time base recovery를 해야하는 목표 시간 확인
2024-09-10 11:34:00 -
spfile을 이용해서 pfile 생성

-
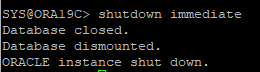
DB는 정상적으로 종료
- current한 redo log file도 사용하기 위해서
- vi 편집기로 생성한 pfile 열어서 control file 위치 변경
- 기존 control file 위치는 #으로 주석처리
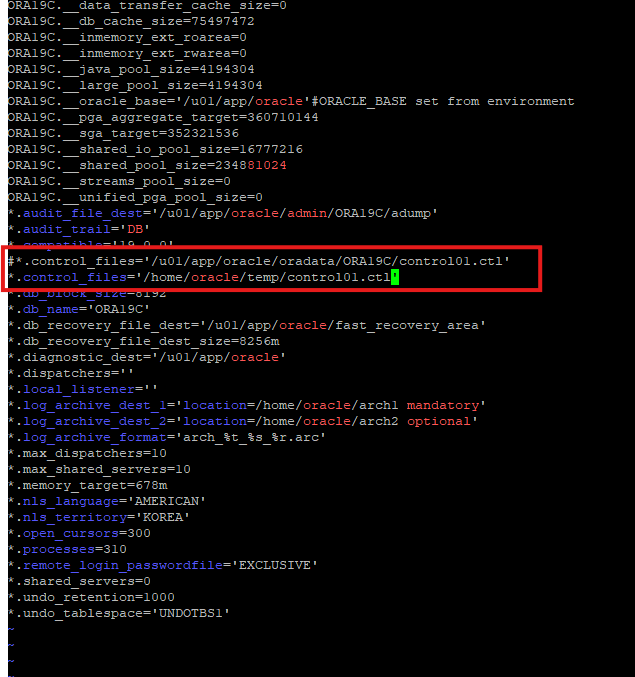
-
새로운 control file 위치로 설정한 디렉터리 생성 후 close 백업본 복사
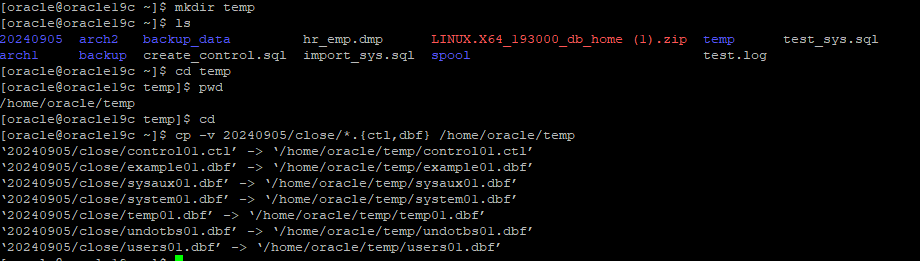
-
운영 DB에 있는 REDO LOG를 TEMP 디렉터리에 복사

-
temp pfile을 이용해서 DB를 MOUNT 단계까지만 실행
- 현재 control file은 temp 디렉터리로 설정되어있지만, 데이터파일은 운영db로 설정되어있기 때문에 변경작업이 필요하다.
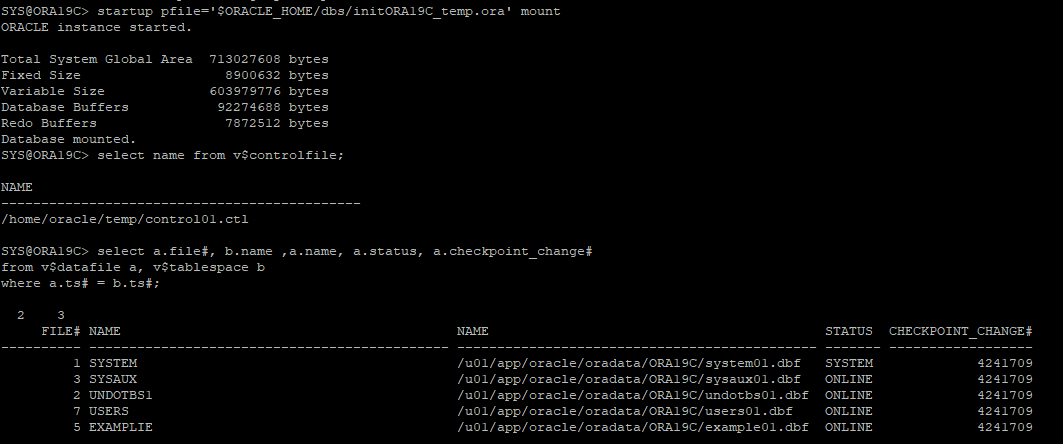
- control file에 설정되어있는 데이터파일, 리두로그 파일의 위치를 변경해준다.
alter database rename file '/u01/app/oracle/oradata/ORA19C/system01.dbf' to '/home/oracle/temp/system01.dbf';
alter database rename file '/u01/app/oracle/oradata/ORA19C/sysaux01.dbf' to '/home/oracle/temp/sysaux01.dbf';
alter database rename file '/u01/app/oracle/oradata/ORA19C/undotbs01.dbf' to '/home/oracle/temp/undotbs01.dbf';
alter database rename file '/u01/app/oracle/oradata/ORA19C/users01.dbf' to '/home/oracle/temp/users01.dbf';
alter database rename file '/u01/app/oracle/oradata/ORA19C/example01.dbf' to '/home/oracle/temp/example01.dbf';
alter database rename file '/u01/app/oracle/oradata/ORA19C/redo01.log' to '/home/oracle/temp/redo01.log';
alter database rename file '/u01/app/oracle/oradata/ORA19C/redo02.log' to '/home/oracle/temp/redo02.log';
alter database rename file '/u01/app/oracle/oradata/ORA19C/redo03.log' to '/home/oracle/temp/redo03.log';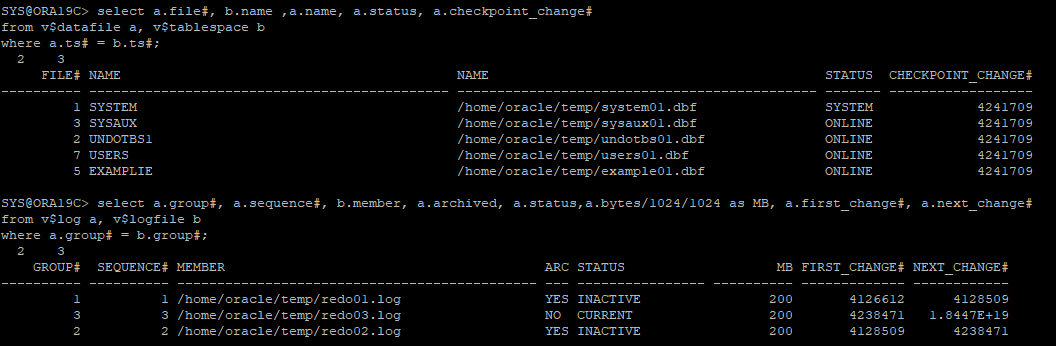
-
세션레벨에서 date 포맷 변경

-
time base recovery로 유저가 삭제되기 전 시간대로 recover
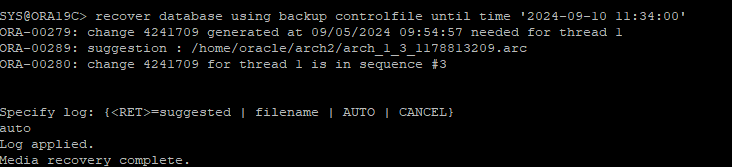
-
RESETLOGS로 DB를 OPEN

-
복구한 유저 확인
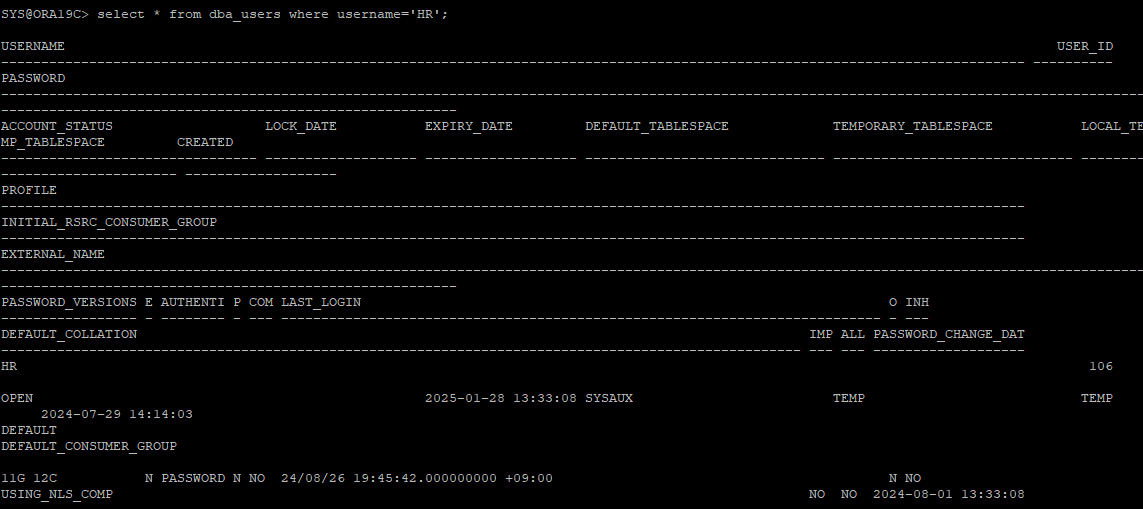
-
운영 DB에 import하기전에 유저를 생성해줘야 하는데 temp DB에서 유저의 메타데이터를 추출해야 한다.
-
유저 생성 구조를 확인
SET long 1000000-- meta 데이터의 타입은 long 타입이다.
SELECT dbms_metadata.get_ddl('USER','HR') from dual;
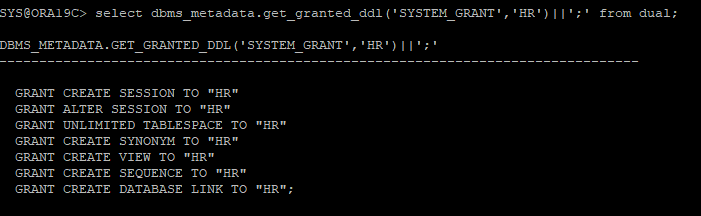
-
유저에게 부여된 시스템 권한 확인
select dbms_metadata.get_granted_ddl('SYSTEM_GRANT','HR') from dual;

-
유저에게 부여된 객체 권한 확인
select dbms_metadata.get_granted_ddl('OBJECT_GRANT','HR') from dual;

-
유저에게 부여된 쿼터값 확인
select dbms_metadata.get_granted_ddl('TABLESPACE_QUOTA','HR') from dual;
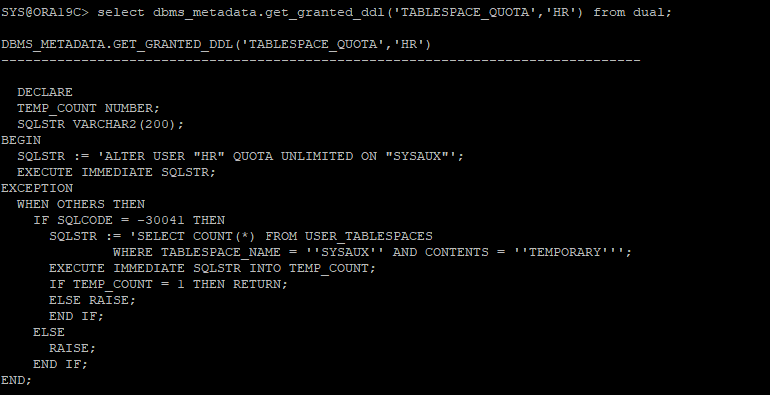
-
유저에게 부여된 ROLE 확인
select dbms_metadata.get_granted_ddl('ROLE_GRANT','HR') from dual;

-
SYSTEM 계정에 대한 패스워드 설정

-
HR 계정 Export 받기
exp userid=system/oracle owner=hr file=hr_owner.dmp direct=y
-
temp DB 정상종료
-
startup 으로 기존 운영 DB 시작
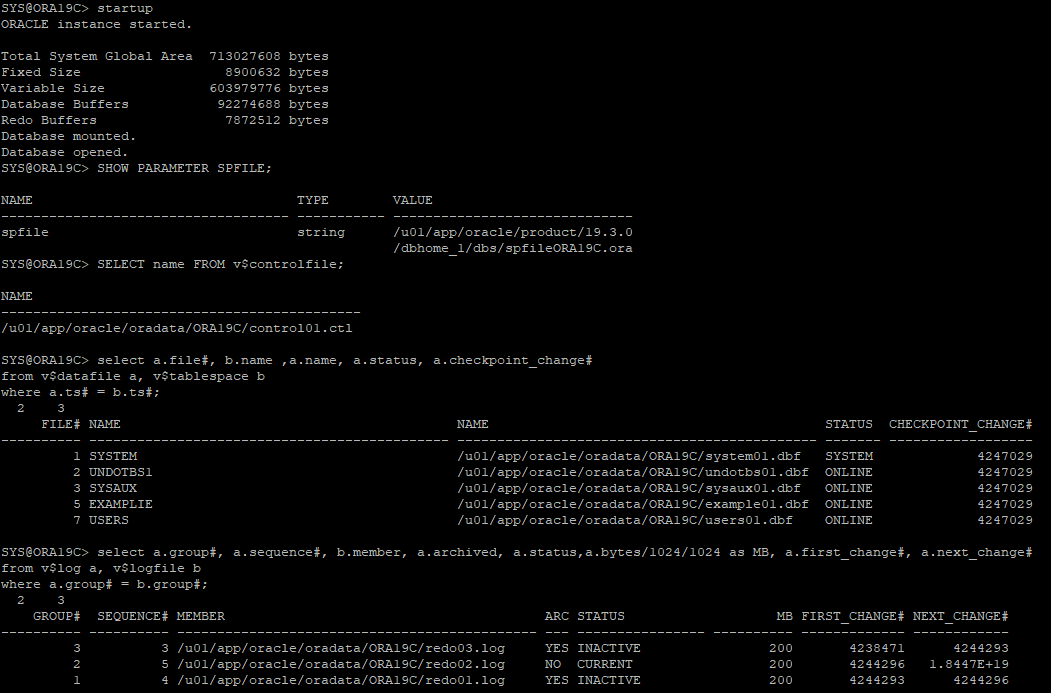
- 운영 DB에 import 할 유저 생성
-- 유저 구조생성
CREATE USER "HR" IDENTIFIED BY hr
DEFAULT TABLESPACE "SYSAUX"
TEMPORARY TABLESPACE "TEMP";
-- 시스템권한
GRANT CREATE SESSION TO "HR";
GRANT ALTER SESSION TO "HR";
GRANT UNLIMITED TABLESPACE TO "HR";
GRANT CREATE SYNONYM TO "HR";
GRANT CREATE VIEW TO "HR";
GRANT CREATE SEQUENCE TO "HR";
GRANT CREATE DATABASE LINK TO "HR";
-- 객체권한
GRANT EXECUTE ON "SYS"."DBMS_STATS" TO "HR";
-- 쿼타 부여
DECLARE
TEMP_COUNT NUMBER;
SQLSTR VARCHAR2(200);
BEGIN
SQLSTR := 'ALTER USER "HR" QUOTA UNLIMITED ON "SYSAUX"';
EXECUTE IMMEDIATE SQLSTR;
EXCEPTION
WHEN OTHERS THEN
IF SQLCODE = -30041 THEN
SQLSTR := 'SELECT COUNT(*) FROM USER_TABLESPACES
WHERE TABLESPACE_NAME = ''SYSAUX'' AND CONTENTS = ''TEMPORARY''';
EXECUTE IMMEDIATE SQLSTR INTO TEMP_COUNT;
IF TEMP_COUNT = 1 THEN RETURN;
ELSE RAISE;
END IF;
ELSE
RAISE;
END IF;
END;
/
-- ROLE 부여
GRANT "RESOURCE" TO "HR";-
dump 파일을 이용해서 import 하기
imp userid=system/oracle file=hr_owner.dmp fromuser=hr -
import 된 유저 확인

ARCHIVE - 시나리오 39
clone DB로 복구
-
supplemental log data를 활성화
-
특정 유저 삭제
log miner
- 분석해야할 리두로그 파일 설정
execute dbms_logmnr.add_logfile(logfilename=>'/u01/app/oracle/oradata/ORA19C/redo02.log', options=> dbms_logmnr.new);-
설정한 리두로그파일 확인
-
분석 시작
begin
dbms_logmnr.start_logmnr(options=>dbms_logmnr.dict_from_online_catalog);--분석기
end;
/- 분석 결과 확인
select to_char(timestamp,'yyyy-mm-dd hh24:mi:ss') as timestamp, operation,sql_redo, sql_undo from v$logmnr_contents where seg_owner = 'HR';
- 분석 종료
execute dbms_logmnr.end_logmnr;-
time base recovery를 해야하는 목표 시간 확인
2024-09-10 11:34:00 -
클론 DB에서 사용하기 위해 user를 drop 했던 redo 정보를 아카이브 파일로 만듬

-
clone 디렉터리 생성

-
clone DB에서 사용할 초기파라미터 파일 만들기

-
control file을 trace 파일로 만들기

-
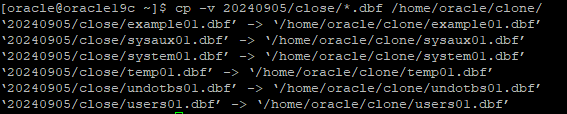
close 백업 받은 data file만 clone 디렉터리에 복사
-
아카이브 파일 clone 디렉터리에 복사

-
pfile을 vi 편집기로 편집
- 초기파라미터 파일에 필수 파라미터들이다. 나머지는 없어도 구동하는데 문제 없다.

- trace파일에 있는 control 파일 생성 쿼리문 수정
- control file을 새롭게 생성할때는 꼭 SET 키워드를 작성해야한다.
- redo log 파일을 새롭게 만들어야 하기 때문에 RESETLOGS로 설정해야한다.
CREATE CONTROLFILE SET DATABASE "CLONE" RESETLOGS ARCHIVELOG -- 새롭게 생성할때는 SET 키워드를 사용해야한다.
MAXLOGFILES 16
MAXLOGMEMBERS 3
MAXDATAFILES 100
MAXINSTANCES 8
MAXLOGHISTORY 292
LOGFILE
GROUP 1 '/home/oracle/clone/redo01.log' SIZE 200M BLOCKSIZE 512,
GROUP 2 '/home/oracle/clone/redo02.log' SIZE 200M BLOCKSIZE 512,
GROUP 3 '/home/oracle/clone/redo03.log' SIZE 200M BLOCKSIZE 512
DATAFILE
'/home/oracle/clone/system01.dbf',
'/home/oracle/clone/undotbs01.dbf',
'/home/oracle/clone/sysaux01.dbf',
'/home/oracle/clone/example01.dbf',
'/home/oracle/clone/users01.dbf'
CHARACTER SET AL32UTF8
;- 새로운 세션창으로 CLONE DB 환경설정
. oraenv: oracle 환경변수
- SID 입력에 새롭게 띄울 SID 이름 입력
- ORACLE_HOME 에는 oracle 소프트웨어가 설치되어있는 @ORACLE_HOME 환경변수 주소를 입력

- clone 디렉터리에 있는 pfile로 DB를 nomount 단계까지 실행
- clone db는 임시 db 이기때문에 alert log에는 기록되지 않는다.
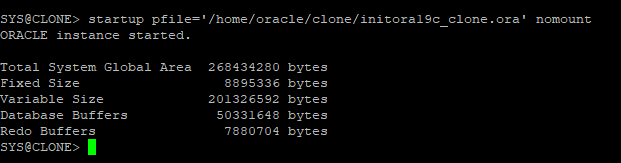
-
만들어 놓은 control file 생성 쿼리문으로 생성
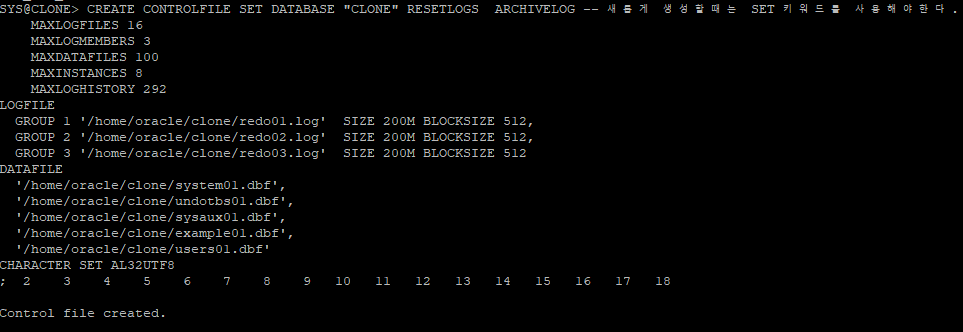
-
현재 세션에서 포맷 설정
alter session set nls_date_format = 'yyyy-mm-dd hh24:mi:ss';

-
time base recovery 수행
recover database using backup controlfile until time '2024-09-10 15:31:00'
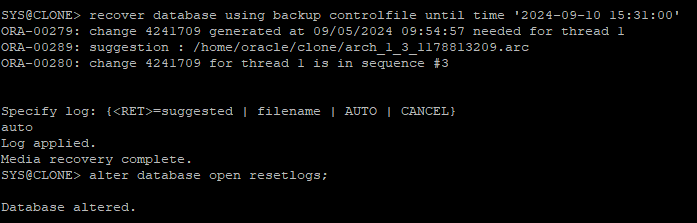
-
RESETLOGS로 DB를 OPEN

-
clone DB 생성완료
-
control file을 생성 하였기 때문에 temp 파일 설정 및 SYSTEM 계정 패스워드 설정

-
USER 모드로 데이터 Export 작업 수행
exp userid=system/oracle owner=hr file=clone_hr.dmp direct=y -
clone DB에서 Export한 유저의 metadata 정보 추출
-
유저 생성 구조를 확인
SET long 1000000-- meta 데이터의 타입은 long 타입이다.
SELECT dbms_metadata.get_ddl('USER','HR') from dual;
-
유저에게 부여된 시스템 권한 확인
select dbms_metadata.get_granted_ddl('SYSTEM_GRANT','HR') from dual;
-
유저에게 부여된 객체 권한 확인
select dbms_metadata.get_granted_ddl('OBJECT_GRANT','HR') from dual;
-
유저에게 부여된 쿼터값 확인
select dbms_metadata.get_granted_ddl('TABLESPACE_QUOTA','HR') from dual;
-
유저에게 부여된 ROLE 확인
select dbms_metadata.get_granted_ddl('ROLE_GRANT','HR') from dual;
- 운영 DB에서 clone DB에서 추출한 metadata를 이용해 import 받아야 할 USER 생성
-- 유저 구조생성
CREATE USER "HR" IDENTIFIED BY hr
DEFAULT TABLESPACE "SYSAUX"
TEMPORARY TABLESPACE "TEMP";
-- 시스템권한
GRANT CREATE SESSION TO "HR";
GRANT ALTER SESSION TO "HR";
GRANT UNLIMITED TABLESPACE TO "HR";
GRANT CREATE SYNONYM TO "HR";
GRANT CREATE VIEW TO "HR";
GRANT CREATE SEQUENCE TO "HR";
GRANT CREATE DATABASE LINK TO "HR";
-- 객체권한
GRANT EXECUTE ON "SYS"."DBMS_STATS" TO "HR";
-- 쿼타 부여
DECLARE
TEMP_COUNT NUMBER;
SQLSTR VARCHAR2(200);
BEGIN
SQLSTR := 'ALTER USER "HR" QUOTA UNLIMITED ON "SYSAUX"';
EXECUTE IMMEDIATE SQLSTR;
EXCEPTION
WHEN OTHERS THEN
IF SQLCODE = -30041 THEN
SQLSTR := 'SELECT COUNT(*) FROM USER_TABLESPACES
WHERE TABLESPACE_NAME = ''SYSAUX'' AND CONTENTS = ''TEMPORARY''';
EXECUTE IMMEDIATE SQLSTR INTO TEMP_COUNT;
IF TEMP_COUNT = 1 THEN RETURN;
ELSE RAISE;
END IF;
ELSE
RAISE;
END IF;
END;
/
-- ROLE 부여
GRANT "RESOURCE" TO "HR";-
dump 파일 import 받기
imp userid=system/oracle file=clone_hr.dmp fromuser=hr -
복구받은 유저 확인

