-
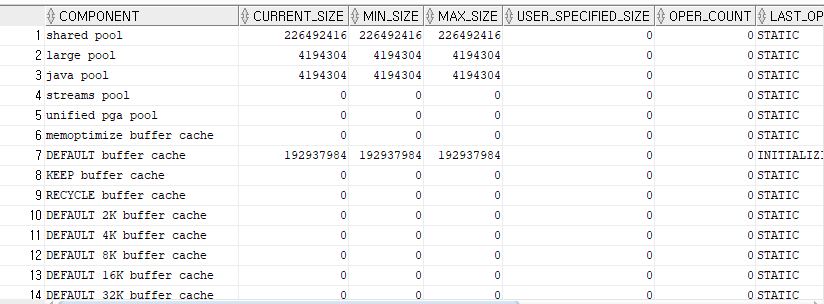
SGA에 할당 되어있는 동적 구성요소 크기 확인
SELECT * FROM v$sga_dynamic_components;
-
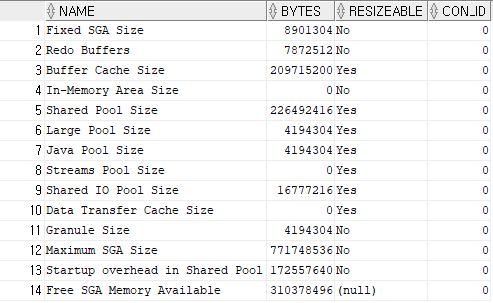
SGA에 구성되어 있는 POOL 크기 간단 확인
- RESIZEABLE은 동적으로 크기가 변하는 파라미터
SELECT * FROM v$sgainfo;
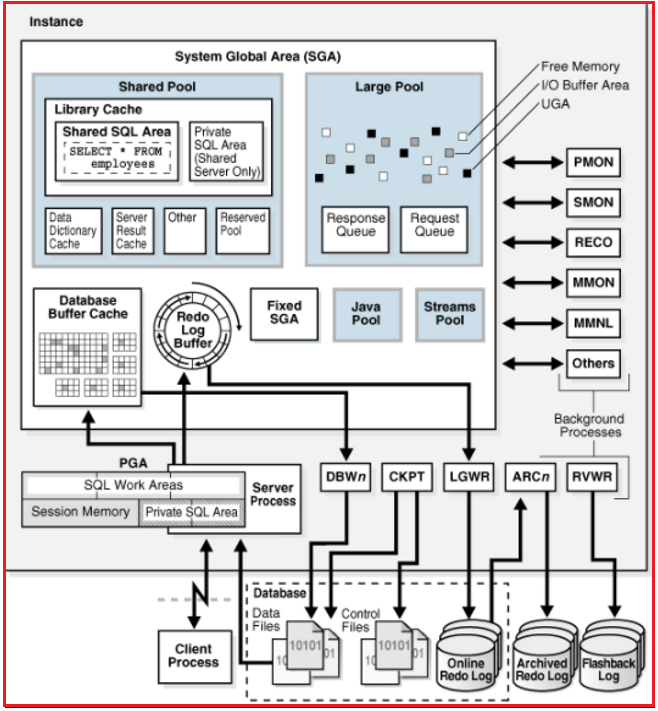
PGA(Program Global Area)
-
서버프로세스 또는 백그라운드 프로세스의 데이터 및 제어 정보를 포함하는 메모리 영역입니다.
-
비공유 메모리 입니다.
-
PGA 영역에 있는 SQL 작업 영역 관리는 8i 버전까지는 수동관리
-
sort_area_size
-
hash_area_size
-
bitmap_merge_area_size
-
create_bitmap_area_size
-
확인방법
SELECT * FROM v$parameter WHERE name IN ('sort_area_size', 'hash_area_size', 'bitmap_merge_area_size', 'create_bitmap_area_size'); ```` -

SHOW PARAMETER PGA;

자동 PGA 메모리 관리
- 9i 버전에 출시
- pga_aggregate_target 파라미터 기반으로 SQL 작업 영역에 할당되는 PGA 메모리양이 동적으로 조정관리 된다.
- workarea_size_policy = auto로 되어 있으면 자동 PGA 메모리 관리를 할 수 있다.
SELECT * FROM v$parameter WHERE name = 'pga_aggregate_target';

SELECT * FROM v$parameter WHERE name = 'workarea_size_policy';

❗ PGA 메모리 수동관리(지금은 하지 않는다)
ALTER SYSTEM SET workarea_size_policy = manual;
ALTER SYSTEM SET pga_aggregate_target = 0;
- PGA 메모리 세션 레벨에서 수동 관리
ALTER SESSION SET workarea_size_policy = manual;
ALTER SESSION SET sort_area_size = 1g;
AMM(Automatic Memory Management)
-
11g에서 새롭게 나온 기능
-
SGA 및 PGA 의 크기 조정을 작업 로드에 따라 자동으로 수행한다.
-
AMM 기능을 사용하려면 MEMORY_TARGET값을 설정해야 한다.
-
오라클이 사용할 수 있는 최대 메모리 설정은 MEMORY_MAX_TARGET 값으로 설정하면 된다.
-
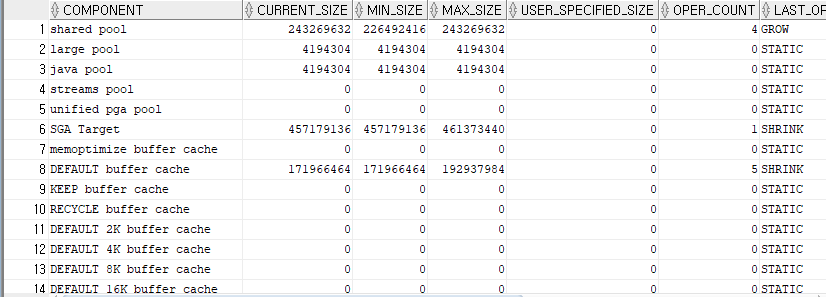
메모리의 동적 구성요소 크기 확인
SELECT * FROM v$memory_dynamic_componenets;
-
AMM 설정 파라미터
- memory_target : SGA + PGA 합한 전체 메모리 크기
- memory_max_target : 동적으로 최대 할당 메모리 크기
-
memory_target 값이 설정되어 있더라도 수동으로 sga_target, pga_aggregate_target 값을 설정할 수 있다.
-
지금까지 발생한 RESIZE 작업에 대한 정보
SELECT * FROM v$memory_resize_ops;
-
현재 메모리 크기 조정 작업 진행 상황
SELECT * FROM v$memory_current_resize_ops;
Background Process
- 데이터베이스 인스턴스의 일부이며, 데이터베이스 운영하고 유지보수 작업을 수행하는 프로세스
- 인스턴스 시작할때 자동으로 백그라운드 프로세스를 생성한다.
DBWn(DataBase Writer)
-
n은 프로세스 갯수 , 최대 100개 까지 가능
-
data buffer cache에 수정된(dirty) block을 데이터 파일(디스크)에 기록하는 프로세스
-
DBWn 은 서버 프로세스의 요청을 받아 free block 스캔을 통해 free block을 search 한다.
-
DBWn가 작동되는 시점
1) free block을 찾지 못했을 경우(free buffer wait event발생 aging out 시킴), physical I/O 발생
2) checkpoint event 발생할때 -
DBWn 갯수 확인 방법
SHOW PARAMETER db_writer_process; -
DBWn 프로세스 확인

LGWR(Log Writer)
- Redo log buffer에 있는 redo entry(변경된 이력 정보)를 redo log file에 기록하는 프로세스
- LGWR 작동시점
1) COMMIT, ROLLBACK을 수행하는 경우
2) redo log buffer 가 1/3 찼을 경우
3) 1MB 이상 redo entry가 들어오면
4) 3초마다
5) DBWn가 기록하기 전에 - LGWR 프로세스 확인

- Redo log buffer 에서 redo log file로 이동 과정
SELECT * FROM v$log;

- STATUS 상태가 CURRENT인 GROUP#번호의 파일에 Redo log buffer에 있는 redo entry를 내린다.
SELECT * FROM v$logfile;

- current한 그룹 번호가 1번 그룹이여서 MEMBER에 있는 주소로 작성한다.
CKPT(Checkpoint)
-
checkpoint event를 담당하는 프로세스
-
checkpoint event 발생 시점에 DBWR에게 알린다.
-
checkpoint 정보를 데이터파일 헤더에 갱신작업을 수행한다.
-
checkpoint 정보를 컨트롤 파일에 갱신작업을 수행한다.
-
ckpt 프로세스 확인 방법

checkpoint
-
data buffer cache에 있는 dirty buffer(block)을 정기적으로 디스크에 기록함으로 시스템이나 데이터베이스에 instance failure가 발생한 경우 데이터가 손실되지 않도록 한다.
-
instance recovery에 필요한 시간을 줄인다. 즉 마지막 체크포인트 다음에 나오는 redo log file의 redo entry에 대해서 recovery를 수행하면 된다. instance recovery는 오라클이 open시점에 자동으로 수행한다.
-
체크포인트 정보에는 체크포인트 시간, SCN(System Commit Number), recovery를 시작할 redo log 파일의 위치, redo log에 정보를 가지고 있다.
-
체크포인트가 발생하는 시점
-
FULL CHECKPOINT
SHUTDOWN NORMAL | TRANSACTIONAL | IMMEDIATE(DB 정상적인 종료)ALTER SYSTEM CHECKPOINT;
-
PARTIAL CHECKPOINT
ALTER TABLESPACE 테이블스페이스이름 OFFLINE NORMAL;ALTER TABLESPACE 테이블스페이스이름 READ ONLY;ALTER TABLESPACE 테이블스페이스이름 BEGIN BACKUP;DROP TABLE 테이블이름;TRUNCATE TABLE 테이블이름;- SELECT /*+ full(e) parallel(e,2) */ FROM hr.employees e; 병렬처리작업
- Log Switch 발생시점(자동 발생)
- Log Switch 발생시점(수동 발생, ALTER SYSTEM SWITH LOGFILE)
Log Switch : log를 기록하는 그룹의 용량이 꽉 차 다음 그룹으로 넘어가는 행위
-
INCREMENTAL CHECKPOINT
- fast_start_mttr_target을 설정한 경우
- 증가분해 체크포인트
- 파라미터의 값은 초단위
- 최대값은 3600초 = 1시간
-

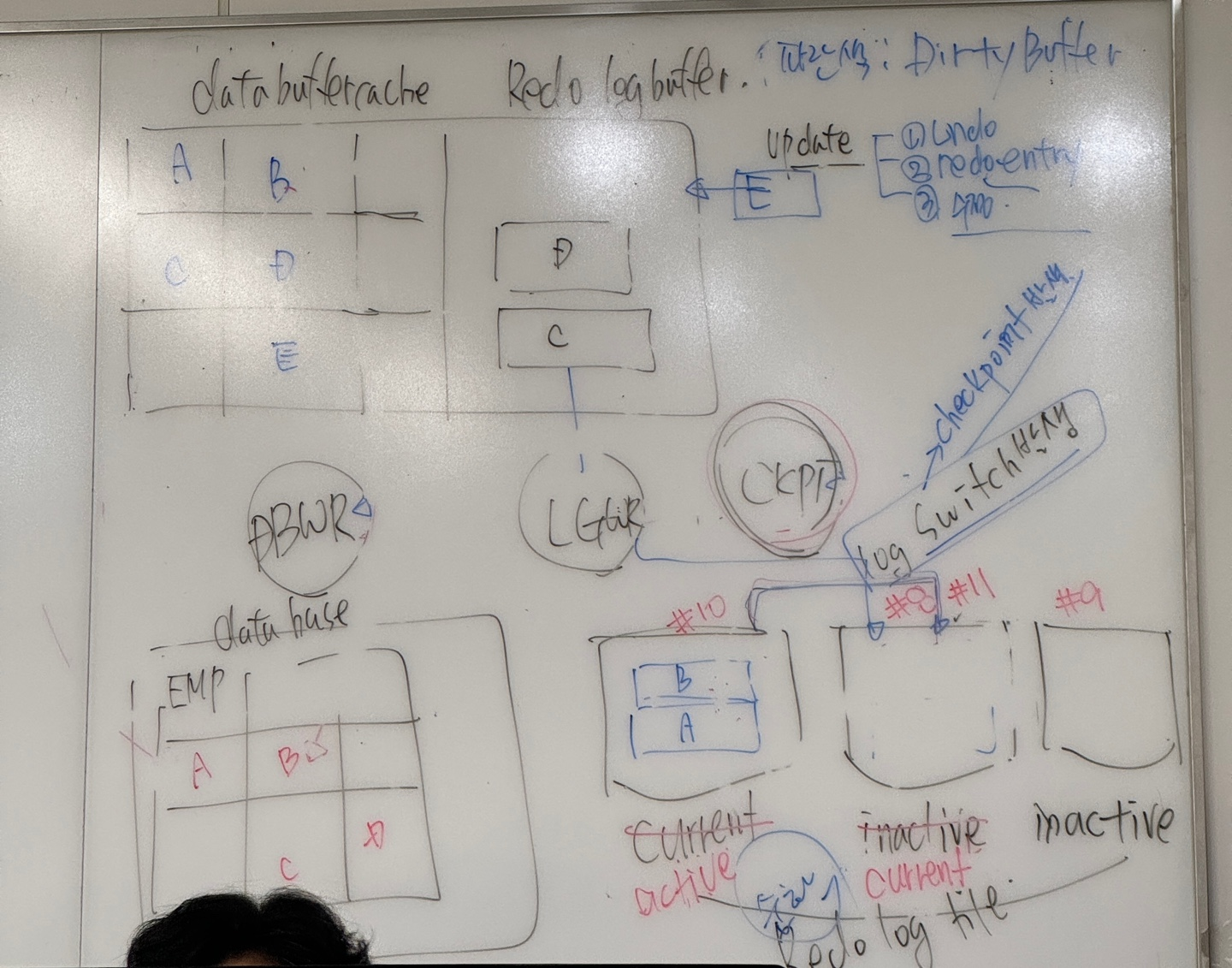
리두 로그 파일은 순환형식이기 때문에 2개 이상이여야 한다.
시퀀스 번호가 가장 큰 그룹이 current 상태이다.
로그 스위치가 발생되면 다음 그룹의 시퀀스 번호는 이전 current 그룹의 시퀀스 번호에서 1 추가번호로 바뀐다.
이전 current 그룹은 active 상태로 변경되고 로그 스위치가 발생했기 때문에 partion checkpoint가 발생한다.
그럼 CKPT는 active 상태의 그룹을 보고 변경된 블록을 알수 있어 DBWR에 시그널을 보낸다.
DBWR는 시그널을 받은 dirty block에 대해 disk로 내리는 작업을 수행한다.
DBWR 작업이 끝나면 active 상태의 리두로그파일 그룹은 inactive 상태로 변경된다.
inactive 상태의 그룹에는 오버라이트를 해도 상관이 없다.
추가로 너무 많은 트랜잭션이 발생하여 잦은 로그 스위치가 발생하여 다른 active 상태의 그룹들이 아직 체크포인트가 진행중이면 다른 inactive 상태의 그룹에 오버라이트를 할수가 없어 checkpoint not complete wait event가 발생한다.
잦은 로그스위치는 잦은 체크포인트를 의미하고 따라서 잦은 DBWR이 작업을 하기 때문에 성능상으로는 좋지 않다. 왜냐하면 힘들게 BUFFER CACHE로 올린 데이터를 쉽게 DISK로 내리기 때문이다.
