COMMENT
테이블과 컬럼에 주석(설명) 만드는 SQL문으로 DDL문이다
테이블 주석생성
COMMNET ON TABLE 소유자.테이블 IS '주석내용';
COMMENT ON TABLE hr.emp IS '사원정보테이블';테이블 주석내용 확인
SELECT * FROM user_tab_comments WHERE table_name = 테이블명
SELECT * FROM user_tab_comments WHERE table_name = 'EMP';테이블 주석 삭제
COMMENT ON TABLE 소유자.테이블 IS '';
컬럼 주석생성
COMMENT ON COLUMN 소유자.테이블.컬럼 IS '주석내용';
컬럼 주석내용 확인
SELECT * FROM user_col_comments WHERE table_name = 테이블명;
컬럼 주석 삭제
COMMENT ON COLUMN 소유자.테이블.컬럼 IS '';
TRUNCATE
- 테이블의 행을 전부 삭제하는 SQL문,DDL문
- DELETE문과 비슷하지만 TRUNCATE은 저장공간을 초기 상태로 만든다.
- DELETE 시 undo에 데이터 저장
- TRUNCATE문은 ROLLBACK 할 수 없다.
- 테이블 구조는 남아있음
TRUNCATE TABLE 테이블명;
SELECT * FROM hr.emp;
DELETE FROM hr.emp; --undo 공간에 이전 값이 저장된다.
ROLLBACK; -- undo 공간에 이전값을 원래의 위치에 저장해준다.
SELECT * FROM hr.emp;
TRUNCATE TABLE hr.emp; -- 내부적으로 extent를 해지하기 때문에 영구히 데이터 지운다.
ROLLBACK -- 의미없는 행위
SELECT * FROM hr.emp;WITH
- 두번 이상 반복되는 SELECT문을 QUERY BLOCK(가상테이블)를 만들어서 사용된다.
- 성능을 향상시킬수 있다.
SELECT... FROM (SELECT ...) e, (SELECT..FROM e..)
- inline view에서 생성된 가상 테이블을 다시 호출할 수 없다.
- 이런 제약을 해결한 구문이 WITH문이다.
WITH
가상테이블1(QUERY BLOCK) AS(SELECT..(SUBQUERY)),
가상테이블2(QUERY BLOCK) AS(SELECT..(SUBQUERY)),
가상테이블3(QEURY BLOCK) AS (SELECT..FROM 가상테이블1(SUBQUERY))
SELECT *
FROM 가상테이블1, 가상테이블2
WHERE 조인조건 술어[문제]
자신의 부서 평균 급여보다 더 많은 급여를 받는 사원?
<풀이>
WITH
temp_01 AS(
SELECT department_id, avg(salary) as avg_sal
FROM hr.employees
GROUP BY department_id
)
SELECT b.*
FROM temp_01 a
join hr.employees b on a.department_id = b.department_id
WHERE b.salary > a.avg_sal;[문제]
사원의 급여를 소속되어 있는 부서의 사원수로 나누어서 출력해주세요.
<JOIN 풀이>
WITH
temp_01 AS (
SELECT department_id, count(*) as cnt
FROM hr.employees
GROUP BY department_id
)
SELECT b.employee_id, b.salary, round(b.salary/a.cnt) as re_sal
FROM temp_01 a
JOIN hr.employees b on a.department_id = b.department_id;<Scalar Subqeury 풀이>
WITH
temp_01 AS (
SELECT department_id, count(*) as cnt
FROM hr.employees
GROUP BY department_id
)
SELECT a.employee_id,salary, round(a.salary/(SELECT cnt
FROM temp_01
WHERE department_id = a.department_id)) as re_sal
FROM hr.employees a
ORDER BY 1;[문제]
부서별 급여의 합이 전체 급여의 합의 몇 퍼센트인지 출력해주세요.
<풀이>
WITH
temp_01 AS (
SELECT department_id , sum(salary) as sum_sal
FROM hr.employees
GROUP BY department_id
),
temp_02 AS(
SELECT sum(sum_sal) as total_sum
FROM temp_01
)
SELECT department_id, sum_sal, round(100.0 * sum_sal/total_sum,2) as pct_sal
FROM temp_01, temp_02
ORDER BY 3 desc;EXTRACT
날짜형을 숫자형으로 추출하는 날짜 함수
- timezone 을 가지고 있을 경우 dbtimezone을 기준으로 추출한다.
SELECT EXTRACT(year from sysdate) FROM dual; -- 년도 추출
SELECT EXTRACT(month FROM sysdate) FROM dual; --달 추출
SELECT EXTRACT(day FROM sysdate) FROM dual; -- 일 추출
SELECT EXTRACT (hour FROM localtimestamp) FROM dual; -- 시 추출
SELECT EXTRACT (minute FROM localtimestamp) FROM dual; -- 분 추출
SELECT EXTRACT (second FROM localtimestamp) FROM dual; -- 초 추출
SELECT EXTRACT (timezone_hour FROM current_timestamp) FROM dual; -- time zone 시 추출
SELECT EXTRACT (timezone_minute FROM current_timestamp) FROM dual; -- time zone 분 추출
SELECT
current_timestamp,
EXTRACT(timezone_region FROM current_timestamp), -- time zone region 추출
EXTRACT(timezone_abbr FROM current_timestamp)
FROM dual;분석 함수
분석함수 over (partion by 컬럼명 order by 컬럼명)
SELECT
department_id,
employee_id,
salary,
sum(salary) over () as "전체합",
sum(salary) over (order by employee_id ) as "누적합",
sum(salary) over (partition by department_id) as "부서별 합",
sum(salary) over (partition by department_id order by employee_id) as "부서별 누적합"
FROM hr.employees
ORDER BY 1;TOP-N
예) 최고 급여를 받는 사원중에 10위까지 출력
1) 급여를 기준으로 내림차순 정렬
SELECT employee_id , salary
FROM hr.employees
ORDER BY salary desc;2) 정렬한 결과를 가지고 10위까지 출력
ROWNUM 가상컬럼 : SELECT 결과를 화면에 출력할때 FETCH 번호
SELECT rownum, employee_id , salary
FROM hr.employees;3) RANK 함수를 활용한 10위까지 출력
WITH
temp_01 AS (
SELECT employee_id,
salary,
rank() over (order by salary desc) as rnum
FROM hr.employees
)
SELECT *
FROM temp_01
WHERE rnum <= 10;
- RANK : 순위를 구하는 함수, 동일한 순위가 있을 경우 다음 순위의 갭이 생긴다.
- DENSE_RANK : 순위를 구하는 함수, 동일한 순위가 있더라도 연이은 순위를 구한다.
- ROW_NUMBER : 동일한 값이더라도 연이은 순위를 나타낸다.
전체 사원들중 급여별 순위
SELECT employee_id,
salary,
rank() over (order by salary desc) as 순위1,
dense_rank() over (order by salary desc) as 순위2,
rank() over (order by salary ) as 순위3,
dense_rank() over (order by salary ) as 순위4
FROM hr.employees;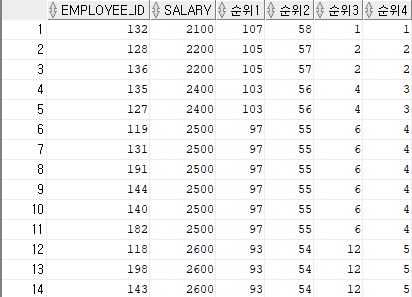
부서별 사원들 중 급여 순위
SELECT employee_id,
salary,
department_id,
rank() over (partition by department_id order by salary desc) as 부서별순위1,
dense_rank() over (partition by department_id order by salary desc) as 부서별순위2
FROM hr.employees;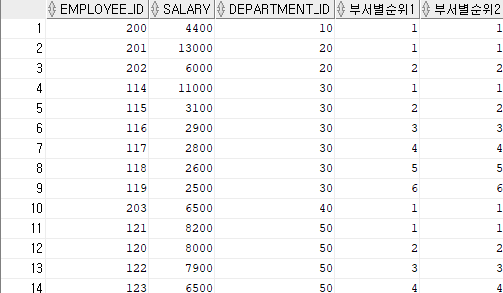
listagg
데이터를 가로로 출력
SELECT
department_id,
listagg(employee_id, ',')within group(order by employee_id) as 사번
FROM hr.employees
GROUP BY department_id;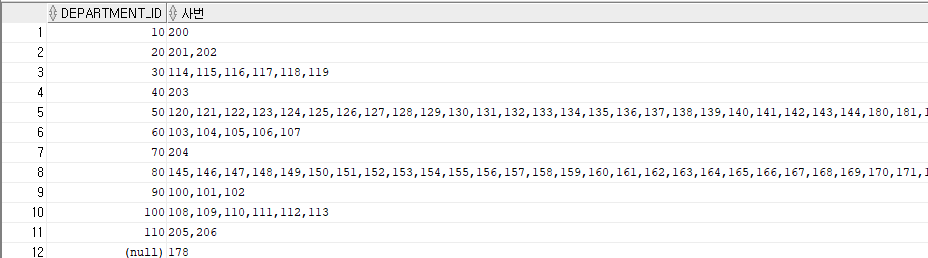
윈도우 단위로 출력
SELECT
employee_id,
last_name,
department_id,
listagg(employee_id, ',')within group(order by employee_id) over(partition by department_id) as 사번
FROM hr.employees;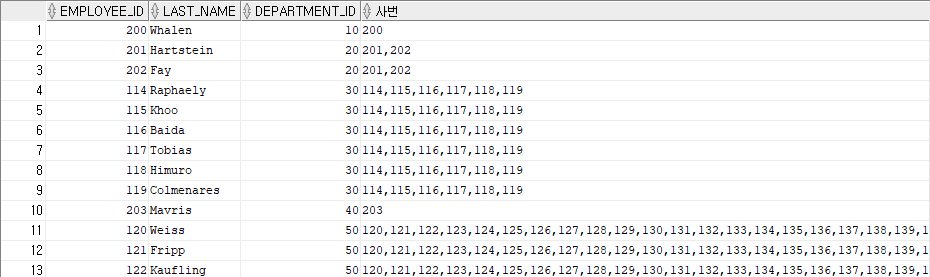
[15일후기]
오늘은 별로 배운것도 없는거 같은데 시간이 빨리 흘러간 것 같다. 역시 금요일이라 그런가.. 오전에는 COMMENT와 TRUNCATE 까지 배워 DDL문을 끝냈고, 오후에는 EXTRACT, WITH절,분석함수 를 배우며 SQL 수업이 끝났다. 그동안 SQL을 하면서 주석은 --을 써가지고 설명을 남기는게 다인줄 알았는데 따로 DB안에 주석을 기록으로 남길수 있는 COMMENT문이 있는줄은 오늘 처음 알았다.주석을 테이블 뿐만 아니라 컬럼별로도 남길 수 있어 나중에 입사를 하고 업무파악을 할때 유용한 기능인 것 같다. TRUNCATE 같은 경우 DROP은 집을 부스는 거라고 생각하면 TRUNCATE는 집안의 물건을 전부 버리는 거라고 생각하면 편했다. 그럼 DELETE를 하면 되지 않냐고 생각이 들수도 있지만, DELETE는 데이터를 행별로 삭제를 해도 바로 삭제가 되는게 아니라 undo라는 스토리지로 옮겨지는데, TRUNCATE는 영구히 삭제가 된다. 그 뒤 EXTRACT 함수를 배웠는데 이건 date 타입을 to_char 후 to_number로 이뤄지는 과정을 한번에 수행하는 함수였다. 다만 막판에 다른학생 질문으로 알게된 사실은 timezone이 들어있는 date 타입을 extract 하게 되면 dbtimezone(즉 그리니치 시간)으로 추출하기 때문에 timezone이 있는 값에는 사용을 하지 않도록 하자. WITH절과 분석 함수는 전에 배워둔 내용이 있기 때문에 이해하는데 어려움은 없었다. 다만 이 window fuction도 자세히 보면 window크기를 이해를 하면서 배워야 하는데 역시 수업시간이 촉박해서 그런지 자세히 다루지 않아 처음 배웠다면 이해하기 어려웠을 것 같다. 가장 중요하다고 생각하는 rows와 range의 차이 그리고 rows between unbounded preceding and current row 이건 정말 중요하다고 생각한다 다음주 월요일에 SQL 단원 시험을 본다고 하는데 전체적인 큰틀은 알지만 세부적으로 외워야 할 부분들이 있다고 생각해 요번 주말에는 시험대비를 좀 해야할 것 같다.
