ANSI(American National Standards Institue) - SQL(Structured Qury Language)
NATURAL JOIN
- equi join
- 조인조건 술어를 자동으로 만들어준다.
- 양쪽 테이블의 동일한 이름의 모든 컬럼을 기준으로 조인조건술어를 만들어준다.
- 양쪽 테이블의 동일한 이름의 컬럼이 타입이 틀린 경우 오류가 발생
SELECT employee_id, department_name
FROM hr.employees NATURAL JOIN hr.departments;
내부적으로는 아래 방식으로 작동된다.
SELECT e.employee_id, d.department_name
FROM hr.employees e, hr.departments d
WHERE e.deaprtment_id = d.department_id
AND e.manager_id = d.manager_id;JOIN USING
- equiu join
- 조인조건의 기준 컬럼을 지정한다. 단 양쪽 테이블의 컬럼이름이 동일한 경우 사용된다.
- USING 절에 사용된 기준컬럼은 어느 테이블이라고 지정하면 오류 발생한다.
SELECT
e.employee_id,
d.department_name,
department_id,
location_id,
l.city
FROM
hr.employees e
JOIN hr.departments d USING ( department_id )
JOIN hr.locations l USING ( location_id )
WHERE
department_id IN (10,20,30);JOIN ON, INNER JOIN
- equi join
- ON절을 이용해서 조인조건 술어를 직접 만들어서 사용한다.
SELECT e.employee_id, d.department_id, d.department_name
FROM hr.employees e
JOIN hr.departments d ON e.department_id = d.department_id -- 조인조건술어;두개가 동일한 결과를 보여준다
SELECT e.employee_id, d.department_id, d.department_name
FROM hr.employees e
INNER JOIN hr.departments d ON e.department_id = d.department_id;OUTER JOIN
- left outer join, right outer join, full outer join이 있다.
LEFT JOIN
SELECT e.employee_id, d.department_id, d.department_name
FROM hr.employees e
LEFT OUTER JOIN hr.departments d
ON e.department_id = d.department_id;FULL OUTER JOIN
SELECT e.employee_id, d.department_id, d.department_name
FROM hr.employees e
FULL OUTER JOIN hr.departments d
ON e.department_id = d.department_id;CATESIAN PRODUCT
- cross join을 사용
SELECT a.employee_id, b.department_name
FROM hr.employees a
CROSS JOIN hr.departments b;[문제37]
2006년도에 입사한 사원들의 부서이름별 급여의 총액, 평균을 출력해주세요.
1) 오라클 전용
SELECT
b.department_name,
SUM(a.salary) AS total_salary,
round(AVG(a.salary)) AS avg_salary
FROM
hr.employees a,
hr.departments b
WHERE
a.department_id = b.department_id
AND to_char(a.hire_date, 'yyyy') = '2006'
GROUP BY
b.department_name;2) ANSI 표준
SELECT
b.department_name,
SUM(a.salary) AS total_salary,
round(AVG(a.salary)) AS avg_salary
FROM
hr.employees a
JOIN hr.departments b ON a.department_id = b.department_id
WHERE
to_char(a.hire_date, 'yyyy') = '2006'
GROUP BY
b.department_name;[문제38]
2006년도에 입사한 사원들의 도시이름별 급여의 총액, 평균을 출력해주세요.
1) 오라클 전용
SELECT
c.city,
SUM(a.salary) AS total_salary,
round(AVG(a.salary)) AS avg_salary
FROM
hr.employees a,
hr.departments b,
hr.locations c
WHERE
a.department_id = b.department_id
AND b.location_id = c.location_id
AND to_char(a.hire_date, 'yyyy') = '2006'
GROUP BY
c.city;2) ANSI 표준
SELECT
c.city,
SUM(a.salary) AS total_salary,
round(AVG(a.salary)) AS avg_salary
FROM
hr.employees a
JOIN hr.departments b ON a.department_id = b.department_id
JOIN hr.locations c ON b.location_id = c.location_id
WHERE
to_char(a.hire_date, 'yyyy') = '2006'
GROUP BY
c.city;[문제39]
2007년도에 입사한 사원들의 도시이름별 급여의 총액, 평균을 출력해주세요.
단 부서 배치를 받지 않은 사원들의 정보도 출력해주세요.
1) 오라클 전용
SELECT
c.city,
SUM(a.salary) AS total_salary,
round(AVG(a.salary)) AS avg_salary
FROM
hr.employees a,
hr.departments b,
hr.locations c
WHERE
a.department_id = b.department_id (+)
AND b.location_id = c.location_id (+)
AND to_char(a.hire_date, 'yyyy') = '2007'
GROUP BY
c.city
ORDER BY
1;2) ANSI 표준
SELECT
c.city,
SUM(a.salary) AS total_salary,
round(AVG(a.salary)) AS avg_salary
FROM
hr.employees a
LEFT JOIN hr.departments b ON a.department_id = b.department_id
LEFT JOIN hr.locations c ON b.location_id = c.location_id
WHERE
to_char(a.hire_date, 'yyyy') = '2007'
GROUP BY
c.city
ORDER BY
1;[문제40]
사원들의 last_name,salary,grade_level, department_name을 출력하는데 last_name에 a문자가 2개 이상 포함되어 있는 사원들을 출력하세요.
1) 오라클 전용
SELECT
a.last_name,
a.salary,
c.grade_level,
b.department_name
FROM
hr.employees a,
hr.departments b,
hr.job_grades c
WHERE
a.department_id = b.department_id
AND a.salary BETWEEN c.lowest_sal AND c.highest_sal
AND length(last_name) - length(replace(last_name, 'a', '')) >= 2;2) ANSI 표준
SELECT
a.last_name,
a.salary,
c.grade_level,
b.department_name
FROM
hr.employees a
JOIN hr.departments b ON a.department_id = b.department_id
JOIN hr.job_grades c ON a.salary BETWEEN c.lowest_sal AND c.highest_sal
WHERE
instr(a.last_name, 'a', 1, 2) >= 2;SUBQUERY(서브쿼리)
- SQL문안에 SELECT문을 서브쿼리 라고 한다.
- SELECT문의 서브쿼리는 괄호() 묶어야 한다.
중첩서브쿼리(nested subquery)
- 처리순서
1)inner query(sub query) 먼저수행
2)1번 수행한 값을 가지고 main query(outer query) 수행한다.
-- main query, outer query
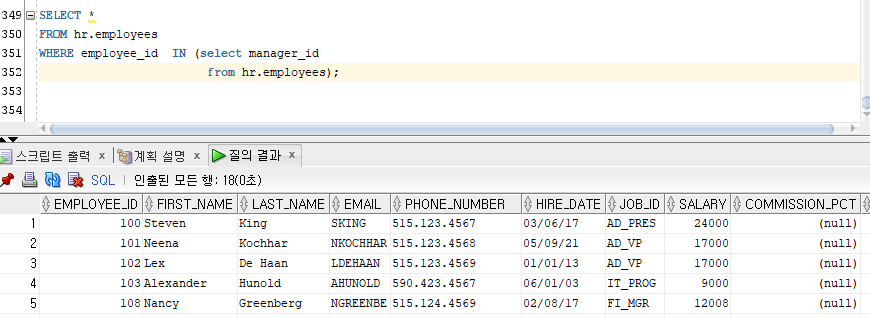
SELECT *
FROM hr.employees
WHERE salary > (SELECT salary
FROM hr.employees
WHERE employee_id = 110);
-- subquery, inner query단일행 서브쿼리
- 서브쿼리의 결과가 단일값이 나오는 서브쿼리
- 단일행 비교연산자(=, >, >=, <, <=, <>, !=, ^=)
SELECT *
FROM hr.employees
WHERE salary > (SELECT salary
FROM hr.employees
WHERE last_name = 'King');
--단일행 비교 연산자를 이용할때는 서브쿼리에 결과가 단일값만 나와야 한다.
--서브쿼리에 결과가 여러개 나오면 오류 발생where 절
- 행을 제한하는 절
- 조인 조건 술어를 표현하는 절
- 서브쿼리 가능
having절
- 그룹함수의 결과를 제한하는 절
- having절에도 서브쿼리 가능
SELECT department_id , sum(salary)
FROM hr.employees
GROUP BY department_id
having sum(salary) > (SELECT min(salary)
FROM hr.employees
WHERE department_id = 40);SELECT department_id,avg(salary)
FROM hr.employees
GROUP BY department_id
HAVING avg(salary) = (SELECT min(avg(salary))
FROM hr.employees
GROUP BY department_id);[문제41]
최대 평균값을 가지고 있는 job_id,평균급여를 출력해주세요.
<풀이>
SELECT job_id,avg(salary)
FROM hr.employees
GROUP BY job_id
HAVING avg(salary) = (SELECT max(avg(salary))
FROM hr.employees
GROUP BY job_id);여러행 서브쿼리
- 서브쿼리의 결과가 여러개의 값이 나오는 서브쿼리
- 여러행 비교연산자(IN, ANY, ALL)
IN 연산자
SELECT *
FROM hr.employees
Where salary IN (SELECT min(salary)
FROM hr.employees
GROUP BY department_id);ANY 연산자
- ANY의 속성은 OR의 범주를 가지고 있다.
- > ANY : 최소값 보다 크다 의미
- < ANY : 최대값 보다 작다 의미
- = ANY : IN 의미
SELECT *
FROM hr.employees
Where salary > ANY(SELECT salary
FROM hr.employees
WHERE job_id = 'IT_PROG');두 쿼리의 결과가 동일하다.
SELECT *
FROM hr.employees
WHERE salary > 9000
OR salary > 6000
OR salary > 4800
OR salary > 4200;ALL 연산자
- ALL의 속성은 AND의 범주를 가지고 있다.
- > ANY : 최대값 보다 크다 의미
- < ANY : 최소값 보다 작다 의미
SELECT *
FROM hr.employees
Where salary > ALL (SELECT salary
FROM hr.employees
WHERE job_id = 'IT_PROG');두 쿼리의 결과가 동일하다.
SELECT *
FROM hr.employees
WHERE salary > 9000
AND salary > 6000
AND salary > 4800
AND salary > 4200;OR 진리표
| 관계 | 결과 |
|---|---|
| TRUE OR TRUE | TRUE |
| TRUE OR FALSE | TRUE |
| FALSE OR FALSE | FALSE |
| TRUE OR NULL(결측치 T/F) | TRUE |
| FALSE OR NULL(결측치 T/F) | NULL |
AND 진리표
| 관계 | 결과 |
|---|---|
| TRUE AND TRUE | TRUE |
| TRUE AND FALSE | FALSE |
| FALSE AND FALSE | FALSE |
| TRUE AND NULL(결측치 T/F) | NULL |
| FALSE AND NULL(결측치 T/F) | FALSE |
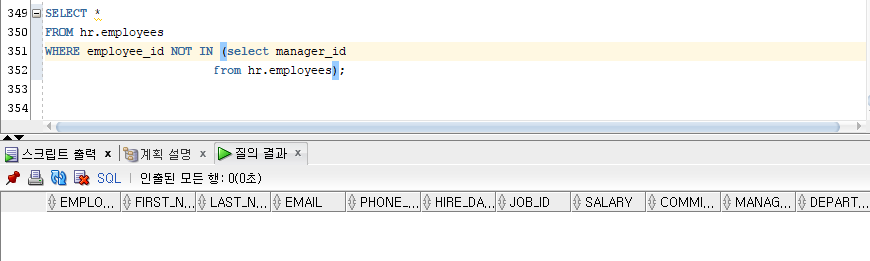
SELECT *
FROM hr.employees
WHERE employee_id <> null
and employee_id <> 100
and employee_id <> 101
...- 서브쿼리 데이터 속 null이 존재하기 때문에 NOT IN을 하게 될 경우 True AND NULL은 NULL이다.
[7일차 후기]
오늘은 크게 ANSI표준 JOIN과 서브쿼리절 2가지를 배웠다. 기존에 내가 하는 JOIN을 하는 방식이 ANSI표준을 따랐기 때문에 배우는데 있어 크게 어려운 점은 없었지만, 몇몇 다른 분들은 ORACLE JOIN과 ANSI표준 JOIN을 한꺼번에 같이 배우다 보니 헷갈려 하는 것 같았다. 그리고 SQL의 편리하다면 편리하고 이해 하기는 어려운 서브쿼리도 배웠는데, 이게 정말 잘만 쓰면 어떠한 조건에서도 데이터를 추출하는게 도움을 줄수 있다. 오늘 가장 인상깊었던 부분은 OR진리표, AND진리표 였는데 막상 아는 내용이라고 생각했는데 NULL과 같이 생각하다보니 좀더 깊게 생각해야 하는 부분이라고 느껴졌다. 이해가 안됬던 부분은 NULL값이 있는 데이터에 NOT IN을 사용했을때 강사님은 = 이 <>으로 바뀌고 OR가 AND로 바뀌면서 TRUE AND NULL 은 NULL이기 때문에 공백으로 나온다고 하셨는데, 시간이 지나 다시 한번 생각해보니 = NULL 도 <> NULL 로 바뀌면 NULL이 아닌 데이터가 있기 때문에 TRUE 가 되어 TRUE AND TRUE가 되어야 하는게 아닌가 싶어졌다. 그래서 강사님께 질문을 해보니 IS NOT NULL 인 데이터 값이 있어도 NULL이라는 결측치와 <> 비교 연산자는 NULL이 결측치 이기 때문에 비교 대상이 안된다고 하셨다.
