Downloading Dataset
!wget http://crowley-coutaz.fr/HeadPoseDataSet/HeadPoseImageDatabase.tar.gz
!tar -xvzf HeadPoseImageDatabase.tar.gz
from google.colab import output
output.clear()
import os
import glob
import numpy as np
import cv2
import torch
import torch.nn as nn
import torch.optim as optim
import torch.backends.cudnn as cudnn
from torch.utils.data.dataset import Dataset
import torch.utils as utils
from google.colab.patches import cv2_imshow
import random
import numpy as np
import torchvision
import torchvision.transforms as transforms
from PIL import Image
import matplotlib.pyplot as plt
device = 'cuda' if torch.cuda.is_available() else 'cpu'
person_list = sorted(glob.glob('Person*')) # search the folders starting with 'Person'
img_list = []
train_img_list = []
val_img_list = []
test_img_list = []
H = 288
W = 384Choose dataset for validation and training
# Train & Validation Select
train_person = [0,1,3,5,7,9,4,6,8]
val_person = [2]
test_person = [10,11,12,13,14]
for i in range(len(person_list)):
if i in train_person:
train_img_list.extend(glob.glob(os.path.join(person_list[i], '*.jpg')))
if i in test_person:
test_img_list.extend(glob.glob(os.path.join(person_list[i], '*.jpg')))
if i in val_person:
val_img_list.extend(glob.glob(os.path.join(person_list[i], '*.jpg')))Dataset augmentation
# Transformation with data augmentation
image_train_transform = transforms.Compose([
transforms.ToTensor(),
transforms.GaussianBlur(kernel_size = 3),
transforms.Normalize((0.5612, 0.5684, 0.5908),(0.2566,0.2496, 0.2446)),
])
image_test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5612, 0.5684, 0.5908),(0.2566,0.2496, 0.2446)),
])
image_inverse_transform = transforms.Compose([
transforms.Normalize((-2.1868,-2.2768,-2.4146),(3.8966,4.0052,4.0869)),
])
Observe and custom dataset
############################################################################
#
# Data set and dataloader
#
############################################################################
class custom_dataset():
def __init__(self, img_list, is_train):
self.img_list = img_list
self.is_train = is_train
def __getitem__(self,index):
img_file = self.img_list[index]
image = cv2.imread(img_file) # read the image file
image = Image.fromarray(image)
txt_file = img_file[:-4] + '.txt' # take the txt file address from the image file address
with open(txt_file,'r') as f:
line = f.read().splitlines()
center_x = int(line[3])/W
center_y = int(line[4])/H
width = int(line[5])/W
height = int(line[6])/H # open the text file and take the face box information from it
if self.is_train:
image = image_train_transform(image)
else:
image = image_test_transform(image)
label = torch.tensor([center_x, center_y, width, height])
return image, label
def __len__(self):
return len(self.img_list)
train_datasets = custom_dataset(train_img_list, is_train=True)
val_datasets = custom_dataset(val_img_list, is_train=False)
test_datasets = custom_dataset(test_img_list, is_train=False)
trainloader = torch.utils.data.DataLoader(train_datasets, batch_size=8, shuffle=True, num_workers=2)
valloader = torch.utils.data.DataLoader(val_datasets, batch_size=8, shuffle=False, num_workers=2)
testloader = torch.utils.data.DataLoader(test_datasets, batch_size=1, shuffle=False, num_workers=2)
############################################################################
#
# Sample visualization
#
############################################################################
sample_image, sample_label = next(iter(trainloader))
sample_image = sample_image[0]
sample_label = sample_label[0]
sample_image = image_inverse_transform(sample_image)
sample_cx = sample_label[0] * W
sample_cy = sample_label[1]* H
sample_w = sample_label[2]* W
sample_h = sample_label[3] * H
# calculate the left-top & right-down coordinates from the box info( x, y, w, h)
sample_x1 = sample_cx - torch.div(sample_w, 2, rounding_mode='floor')
sample_y1 = sample_cy - torch.div(sample_h, 2, rounding_mode='floor')
sample_x2 = sample_cx + torch.div(sample_w, 2, rounding_mode='floor')
sample_y2 = sample_cy + torch.div(sample_h, 2, rounding_mode='floor')
sample_image = sample_image.numpy().transpose(1,2,0).copy() * 255
print(' ( X, Y)')
print('Top Left : (%3d,%3d)'%(sample_x1,sample_y1))
print('Bottom Right : (%3d,%3d)'%(sample_x2,sample_y2))
sample_image = cv2.rectangle(sample_image, (int(sample_x1), int(sample_y1)), (int(sample_x2),int(sample_y2)), (255,0,0), (1)) # draw blue rectangle on the image
# sample_image = cv2.UMat.get(sample_image)
cv2_imshow(sample_image) # print the image
Make Architecture for training
import torchvision.transforms.functional as F
cfg = [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M', 1024, 1024, 'A']
class FaceNet(nn.Module):
def __init__(self):
super(FaceNet, self).__init__()
#self.linear = nn.Linear(288*384*3, 4)
#331776 = 288*384*3
self.features = self._make_layers(cfg)
self.classifier = nn.Sequential(
nn.Linear(1024*3*4, 512),
nn.ReLU(inplace=True),
nn.Dropout(0.13),
nn.Linear(512, 128),
nn.ReLU(inplace=True),
nn.Dropout(0.15),
nn.Linear(128, 4),
)
def forward(self, x):
#x = x.view(x.size(0), -1)
#x = self.linear(x)
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
def _make_layers(self, cfg):
layers = []
in_channels = 3
for x in cfg:
if x == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
elif x == 'A':
layers += [nn.AvgPool2d(kernel_size=3, stride=3)]
else:
layers += [nn.Conv2d(in_channels, x, kernel_size=3, padding=1),
nn.BatchNorm2d(x),
nn.ReLU(inplace=True)]
in_channels = x
return nn.Sequential(*layers)
print('Building Network!')
net = FaceNet()
net = net.to(device)
if device == 'cuda':
net = torch.nn.DataParallel(net)
cudnn.benchmark = True
criterion = nn.MSELoss()
optimizer = optim.Adam(net.parameters(), lr=0.0001, weight_decay=5e-6)
epochs = 20
def horizontal_flip(images, targets, p=0.5):
flipped_images, flipped_targets = [], []
for i, image in enumerate(images):
target = targets[i]
if torch.rand(1) < p:
image = F.hflip(image)
target[0] = 1.0 - target[0]
flipped_images.append(image)
flipped_targets.append(target)
flipped_images = torch.stack(flipped_images, dim = 0)
flipped_targets = torch.stack(flipped_targets, dim = 0)
return flipped_images, flipped_targets
def flip_augmentation(images, targets):
images, targets = horizontal_flip(images, targets, p=0.5)
return images, targets
def train(epoch):
print('\nTrain_flip:')
net.train()
train_loss = 0
for batch_idx, (images, targets) in enumerate(trainloader):
optimizer.zero_grad()
###
images, targets = flip_augmentation(images,targets)
images, targets = images.to(torch.float32), targets.to(torch.float32)
images, targets = images.to(device), targets.to(device)
###
#images, targets = images.to(device), targets.to(device)
outputs = net(images)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
train_loss += loss.item()
if ((batch_idx+1) % (len(trainloader)/3) == 1) or batch_idx+ 1 == len(trainloader):
print('[%3d/%3d] | Loss: %.5f'%(batch_idx+1, len(trainloader), train_loss/(batch_idx+1)))
# print('[%3d/%3d] | Loss: %.5f'%(batch_idx+1, len(trainloader), train_loss/(batch_idx+1)))
def val(epoch):
print('\nValidation:')
net.eval()
val_loss = 0
with torch.no_grad():
for batch_idx, (images, labels) in enumerate(valloader):
optimizer.zero_grad()
images, labels = images.to(device), labels.to(device)
outputs = net(images)
loss = criterion(outputs, labels)
val_loss += loss.item()
#scheduler.step()
if ((batch_idx+1) % (len(valloader)/3) == 1) or batch_idx+ 1 == len(valloader):
print('[%3d/%3d] | Loss: %.5f'%(batch_idx+1, len(valloader), val_loss/(batch_idx+1)))
# print('[%3d/%3d] | Loss: %.5f'%(batch_idx+1, len(valloader), val_loss/(batch_idx+1)))
for epoch in range(epochs):
print('\nEpoch %d'%(epoch))
train(epoch)
val(epoch)Building Network!
Epoch 0
Train_flip:
[ 1/210] | Loss: 0.17272
[ 71/210] | Loss: 0.02142
[141/210] | Loss: 0.01551
[210/210] | Loss: 0.01292
Validation:
[ 1/ 24] | Loss: 0.00413
[ 9/ 24] | Loss: 0.00498
[ 17/ 24] | Loss: 0.00540
[ 24/ 24] | Loss: 0.00582
Epoch 1
Train_flip:
[ 1/210] | Loss: 0.00605
Finetuning Resnet18(feature extractor freeze)
import torchvision.transforms.functional as F
import torchvision.models as models
class FaceNet(nn.Module):
def __init__(self):
super(FaceNet, self).__init__()
#self.linear = nn.Linear(288*384*3, 4)
#331776 = 288*384*3
self.resnet = models.resnet18(pretrained=True)
self.features = nn.Sequential(*list(self.resnet.children())[:-2]).requires_grad_(False)
dummy_input = torch.randn(1, 3, 288, 384) # Example input (adjust size if needed)
with torch.no_grad(): # No need to calculate gradients here
dummy_output = self.features(dummy_input)
feature_size = dummy_output.view(-1).size(0) # Get the flattened size
self.classifier = nn.Sequential(
nn.Linear(feature_size, 512),
nn.ReLU(inplace=True),
nn.Dropout(0.13),
nn.Linear(512, 128),
nn.ReLU(inplace=True),
nn.Dropout(0.15),
nn.Linear(128, 4),
)
def forward(self, x):
#x = x.view(x.size(0), -1)
#x = self.linear(x)
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
print('Building Network!')
net = FaceNet()
net = net.to(device)
if device == 'cuda':
net = torch.nn.DataParallel(net)
cudnn.benchmark = True
criterion = nn.MSELoss()
optimizer = optim.Adam(net.parameters(), lr=0.0001, weight_decay=5e-6)
epochs = 20
def horizontal_flip(images, targets, p=0.5):
flipped_images, flipped_targets = [], []
for i, image in enumerate(images):
target = targets[i]
if torch.rand(1) < p:
image = F.hflip(image)
target[0] = 1.0 - target[0]
flipped_images.append(image)
flipped_targets.append(target)
flipped_images = torch.stack(flipped_images, dim = 0)
flipped_targets = torch.stack(flipped_targets, dim = 0)
return flipped_images, flipped_targets
def flip_augmentation(images, targets):
images, targets = horizontal_flip(images, targets, p=0.5)
return images, targets
def train(epoch):
print('\nTrain_flip:')
net.train()
train_loss = 0
for batch_idx, (images, targets) in enumerate(trainloader):
optimizer.zero_grad()
###
images, targets = flip_augmentation(images,targets)
images, targets = images.to(torch.float32), targets.to(torch.float32)
images, targets = images.to(device), targets.to(device)
###
#images, targets = images.to(device), targets.to(device)
outputs = net(images)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
train_loss += loss.item()
if ((batch_idx+1) % (len(trainloader)/3) == 1) or batch_idx+ 1 == len(trainloader):
print('[%3d/%3d] | Loss: %.5f'%(batch_idx+1, len(trainloader), train_loss/(batch_idx+1)))
# print('[%3d/%3d] | Loss: %.5f'%(batch_idx+1, len(trainloader), train_loss/(batch_idx+1)))
def val(epoch):
print('\nValidation:')
net.eval()
val_loss = 0
with torch.no_grad():
for batch_idx, (images, labels) in enumerate(valloader):
optimizer.zero_grad()
images, labels = images.to(device), labels.to(device)
outputs = net(images)
loss = criterion(outputs, labels)
val_loss += loss.item()
#scheduler.step()
if ((batch_idx+1) % (len(valloader)/3) == 1) or batch_idx+ 1 == len(valloader):
print('[%3d/%3d] | Loss: %.5f'%(batch_idx+1, len(valloader), val_loss/(batch_idx+1)))
# print('[%3d/%3d] | Loss: %.5f'%(batch_idx+1, len(valloader), val_loss/(batch_idx+1)))
for epoch in range(epochs):
print('\nEpoch %d'%(epoch))
train(epoch)
val(epoch)Epoch 0
Train_flip:
[ 1/210] | Loss: 0.18219
[ 71/210] | Loss: 0.18959
[141/210] | Loss: 0.10675
[210/210] | Loss: 0.07677
Validation:
[ 1/ 24] | Loss: 0.00971
[ 9/ 24] | Loss: 0.00854
[ 17/ 24] | Loss: 0.00884
[ 24/ 24] | Loss: 0.00896
Epoch 1
Train_flip:
[ 1/210] | Loss: 0.00976
plot outcome
fig = plt.figure()
visualize_idx = np.random.randint(len(testloader), size=4)
cnt = 0
test_loss = 0
with torch.no_grad():
print('\nTest:')
net.eval()
for batch_idx, (images, labels) in enumerate(testloader):
optimizer.zero_grad()
images, labels = images.to(device), labels.to(device)
outputs = net(images)
loss = criterion(outputs, labels)
test_loss += loss.item()
if batch_idx+1 == len(testloader):
print('[%3d/%3d] | final_MSE: %f'%(batch_idx+1, len(testloader), test_loss/(batch_idx+1)))
print('\033[31m' + '[GT □]' + '\033[30m' +' | ' + '\033[34m' +'[Pred □]' + '\033[0m')
if batch_idx in visualize_idx: # visualize for selected images
subplot = fig.add_subplot(2,2, cnt+1)
sample_image = images[0]
sample_outputs = outputs[0]
sample_label = labels[0]
sample_image = image_inverse_transform(sample_image)
sample_image = sample_image.cpu().numpy().transpose(1,2,0) * 255
# Draw for predicted box
sample_cx = sample_outputs[0] * W
sample_cy = sample_outputs[1] * H
sample_w = sample_outputs[2] * W
sample_h = sample_outputs[3] * H
sample_x1 = sample_cx - torch.div(sample_w, 2, rounding_mode='floor')
sample_y1 = sample_cy - torch.div(sample_h, 2, rounding_mode='floor')
sample_x2 = sample_cx + torch.div(sample_w, 2, rounding_mode='floor')
sample_y2 = sample_cy + torch.div(sample_h, 2, rounding_mode='floor')
sample_image = cv2.rectangle(sample_image.copy(), (int(sample_x1), int(sample_y1)), (int(sample_x2),int(sample_y2)), (255, 0, 0), (3))
# sample_image = cv2.UMat.get(sample_image)
# Draw for groundtruth box
sample_cx = sample_label[0] * W
sample_cy = sample_label[1] * H
sample_w = sample_label[2] * W
sample_h = sample_label[3] * H
sample_x1 = sample_cx - torch.div(sample_w, 2, rounding_mode='floor')
sample_y1 = sample_cy - torch.div(sample_h, 2, rounding_mode='floor')
sample_x2 = sample_cx + torch.div(sample_w, 2, rounding_mode='floor')
sample_y2 = sample_cy + torch.div(sample_h, 2, rounding_mode='floor')
sample_image = cv2.rectangle(sample_image.copy(), (int(sample_x1), int(sample_y1)), (int(sample_x2),int(sample_y2)), (0, 0, 255), (3))
subplot.set_xticks([])
subplot.set_yticks([])
subplot.set_title('%f'%loss.item())
subplot.imshow(cv2.cvtColor(sample_image.astype('uint8'), cv2.COLOR_BGR2RGB))
cnt += 1
plt.show()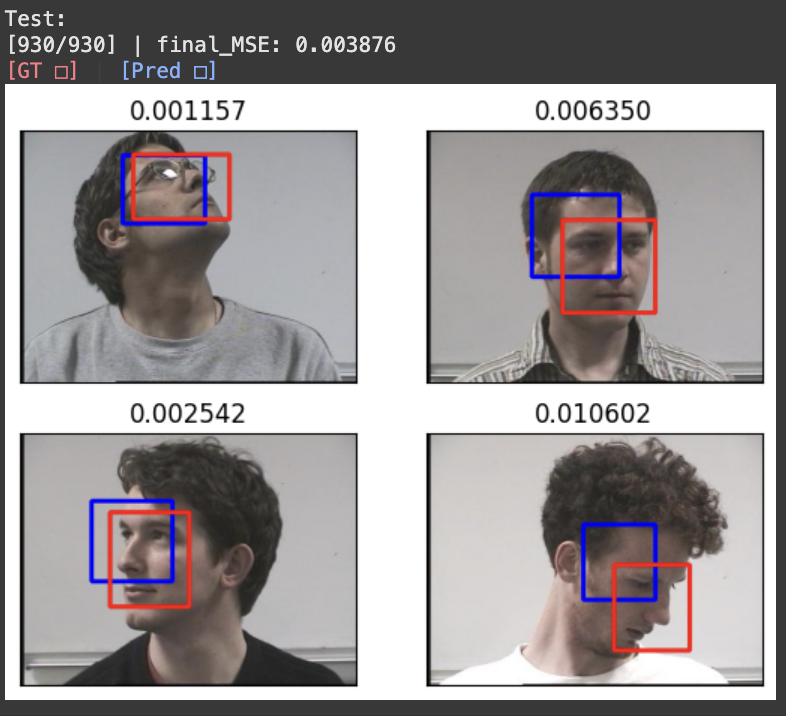

AI, Graphics, Medical Imaging