
22일차
벌써 SKT FLYAI 과정을 진행한지 1달이 지났다.
시간이 너무 빠르다는건 그만큼 열심히 하루하루 달려왔다는거겠지?
22일차에는 머신러닝에 대한 설명과, 분류 / 회귀에 대한 수업을 진행하였다.
대학원 수업에서 이미 들었던 내용들이었지만, 깊게 배우지 못해 수박 겉핥기 식으로만 알고 있던 내용들이었는데 다시배우니 이렇게 재밌을 수가 없었다.
23일차
머신러닝을 직접 실습해보았다. 유명한 Iris Datasets으로 KNN알고리즘도 구현 해 보고, 분류/회귀에 대해 확실하게 배웠다. 여기서 아나콘다의 필요성과 Jupyter Notebook, Jupyter Lab을 많이 사용하게 되었는데, 나는 개인적으로 Jupyter Lab이 사용하기에 더 편했다.
24일차
다시 뒤로 돌아와, 인공지능에 대해 배우게 되었다.
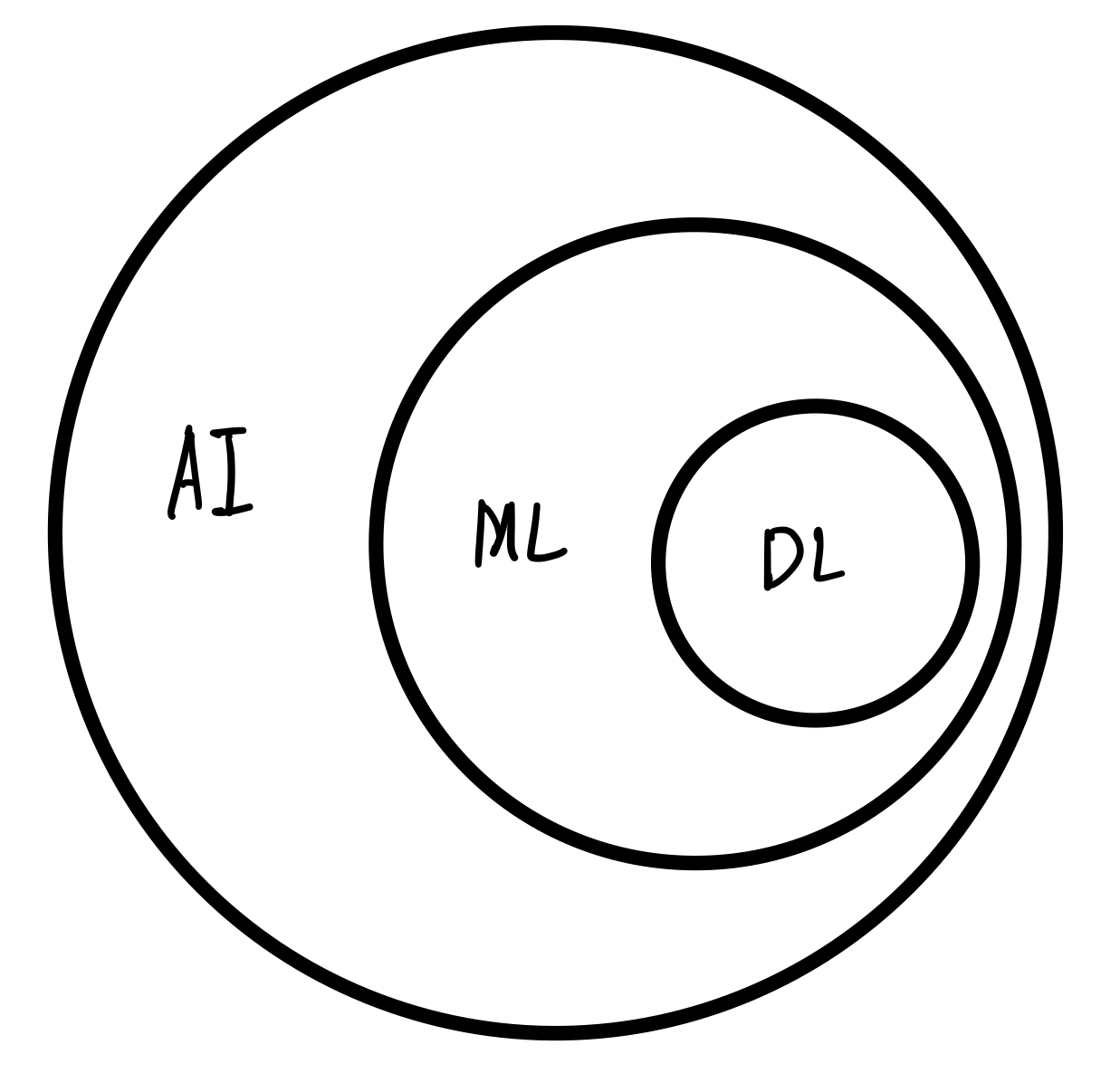
간단하게 설명하면 비전공자들이 보는 인공지능의 시점은 AI이다.
알고리즘을 자동화한 것도 인공지능이고 냉장고의 현재 온도를 조정하거나, 에어컨이 온도를 상황에 맞게 자동으로 바꾼다던지.. 이런 것도 AI 인공지능이다.
ML(머신러닝)은 이보다 더 심화된, 학습을 통해 정확도를 낼 수 있는 인공지능이다.
단, ML은 사람이 HyperParameter를 계속 수정해줘야 하는 반면에, DL(딥러닝)은 그렇지 않다.
DL은 인공신경망을 통해 정확도를 내는데, 처음에 모델을 구성하고 적당한 HyperParameter값을 주면 더이상 사람의 개입이 필요 없어진다.
그럼 무조건 Deep-Learning이 좋은거 아닌가?
나도 처음엔 그렇게 생각했다.
근데 아니다. 각자 필요한 분야가 있다.
간단히 구현할 수 있는 부분은 ML로 구현하는것이 좋고, 이 또한 ML안에서 라벨링이 잘 되어있는 데이터셋이 많다면 ML이 압도적으로 빠르고 높은 결과물을 내기도 한다.
도저히 ML만으로 정확도를 판단하기 어려운 문제에 직면했을 때 Deep-Learning을 사용하는 것이다.
-> 라고 강의해주셨던 한양대 교수님이 말씀 해 주셨지만, 실습을 통해 이것저것 구현하다보니 나도 이 말에 동의한다.
25일차
퍼셉트론과 손실함수, GAN에 대해 깊게 배우는 시간이었다.
위에서 데이터셋이 많을수록 ML을 사용함이 시간적으로도 비용적으로도 높은 결과물을 내기도 한다고 했는데,
그럼 데이터셋 모아서 ML 사용하면 되지, 왜 DL을 사용하나?에 대해 생각 해 볼수 있다.
이미지에 라벨링을 한다는 것이 컴퓨터가 자동으로 해주는 것이 아니라, 사람이 직접 해주어야 하는데,
아래 사진과 같이 누구나 할 수 있는 이런 라벨링은 문제가 되지 않는다.

예를들어, 엑스레이 사진을 통해 이 환자가 암인지 아닌지 판단하려면 어떻게 해야할까?
당연히 전문가가 필요하다. 근데 그 전문가들이 시간이 남아돌아서 라벨링을 하루종일 해줄 수 있을까?
그렇지 않기 때문에 데이터를 모으는데엔 천문학적인 시간과 비용이 들어감으로, 모든 데이터를 모을 수 없다.
애초에 라벨링을 할 데이터 자체가 없으면 어떡할까?
이게 무슨소리인가 하면, 전 세계에서 엑스레이 데이터를 가장 많이 가지고있는 나라는 대한민국, 우리나라다.
외국에서는 엑스레이를 한번 촬영하려면 수십, 수백만원이 들기 때문에 애초에 데이터가 많이 없다.
하지만 우리나라는?
환자: 의사선생님.. 저 다리를 삔거같은데요..
의사: 아 그럼 엑스레이부터 찍어보시죠!
ㅋㅋ 이렇게 때문에 우리나라에 엑스레이 데이터를 달라고 해외에서 요청하는 경우가 굉장히 많다고 한다.
이처럼, 다른 나라에서는 라벨링을 할 데이터 자체가 많이 없기 때문에 이런경우 딥러닝을 많이 사용한다.
머신러닝에서 비지도학습이라는게 있는데, 이걸 딥러닝하고 헷갈리는 사람들이 많다. (맞다. 내 얘기다.)
ML의 비지도학습은 이미지는 있는데, 라벨링이 되어있지 않은 데이터들을 알아서 학습시키는 것을 의미하고,
DL은 그냥 이미지랑 라벨링된 데이터조차 얼마 없을 때 사용한다.
그래서 Deep-Learning은 데이터가 많으면 많을수록 정확도 부분에서 매우 유리하게 작용한다.
하지만, 엄청나게 많은 데이터를 때려박기만 한다고 무조건 정확도가 높을까?
그것도 아니다. 이걸 과적합이라고 하는데, 물론 이 과적합에 대해서 해결방안도 있다.
이 내용은 나중에 따로 다시 다루도록 하겠다.
팀프로젝트

GAN에 대해서도 많이 배우는 시간이었는데, 항상 궁금했던 내용들이 다 수업에 나오고, 이걸 팀프로젝트로 각자 원하는 주제로 정리하여 발표하는 시간이 있어 매우 유용한 시간이었다.
우리팀이 발표한 내용은 SRGAN, Super Resolution GAN이다.
- 짧게 얘기하면, SRGAN은 저해상도 이미지를 고해상도 이미지로 변환하는 기술이다.
다른 팀들이 재치있고 잘 정리된 내용으로 발표한 것을 보니 더 이해가 잘 됐던 부분들도 있고,
항상 재미있게 수업을 들을 수 있는 것 같다.
26일차
다층 퍼셉트론에 대해서 배우는 시간이었다.
딥러닝에서 다루는 주제인데, 사실 너무 어려워서 다시 공부하고 블로그에 정리해보려한다.
일기
팀 회식
SKT 운영진분들과 점심시간에 간단한 회식을 진행했다. 내 인생 첫 편백찜인데, 정말 맛있었다.
고생한다고, 더 힘내달라고 이런 맛있는 밥도 사주시고... SKT분들은 날개없는 천사분들만 임직원이 될 수 있나보다..

스타벅스 써머 캐리백

스타벅스 프리퀀시를 열심히 모아 캐리백을 받았다.
출처 중앙일보
어..?
콩빵.. 사랑하시죠?
ㅋㅋㅋ 전 게시물보고 콩빵 드시러가심.. 같은학교 동문님이신데 너무 귀엽삼
보라매공원 산책

팀원들과 점심먹고 근처 보라매공원으로 산책을 갔다.
이렇게 뷰 좋은 곳에 안와봤다니.. 이건 손해야...
그림

ㅋㅋ 블로그 보고 반성하는 개발자라는 내 1줄 소개에 한줄 더 추가해주셨다.
우리팀원분들 넘 귀여워요
아래는 팀원들과 그린 그림들~~



내 트레이드 마크가 꿀벌이라서 팀원분께 꿀벌 그려달라했더니 진짜 고퀄로 그려주셨다 ㄷㄷ..
위에 보이는 꿀벌인데 넘 사랑스럽지않나요..
빠지

주말에 친구들과 캠프통 아일랜드로 놀러갔다.
인생 첫 빠지였는데, 재미는 둘째치고 이 회사의 예약페이지에서 보안관련 이슈를 하나 찾아 무제한 이용권 2개를 무료로 받았다. 아마 내가 개발자가 아니었다면 찾지 못했을 개인정보와 관련된 크리티컬한 문제였어서 좀 더 보람을 느끼는 하루(?)였다.


콩빵 맛있죠~