컴퓨터의 동작 원리
개요
프로그래밍이 무엇인지에 대해 알았다. 그런데, 단순히 문제를 해결하는 절차만을 생각하는 것만으로는 부족하다. 잘하는 프로그래머가 되려면 소프트웨어 엔지니어(Software Engineer)로서의 역량을 길러야 한다. 즉, 현실적인 제약(컴퓨터의 물리적인 자원)을 고려하면서 문제를 해결할 줄 알아야 한다. 이를 위해서 컴퓨터 과학에 대해 공부하겠다. 그래야 여러 예외 상황을 예방할 수 있고, 효율적인 구현이 가능하다. 컴퓨터 과학에 대해서 최소한의 내용을 공부해보자.
컴퓨터의 구성 요소
현대적 컴퓨터는 매우 복잡하지만 단순하게 메모리(Memory), 입출력장치(I/O), CPU로 나눌 수 있다. 그리고 이런 장치들은 버스(Bus)를 통해 연결된다. 각 부품은 각자만의 역할이 있다.
메모리
메모리(Memory)는 데이터를 저장하는 부품이다. 메모리는 여러 단독 주택이 모인 주택 복합 단지에 비유할 수 있는데, 각 집에는 주소(Address)가 있고, 메모리를 사용하려면 주소와 크기를 알아야 한다. (각각의 집에 우리의 데이터가 저장된다고 생각하겠다.)
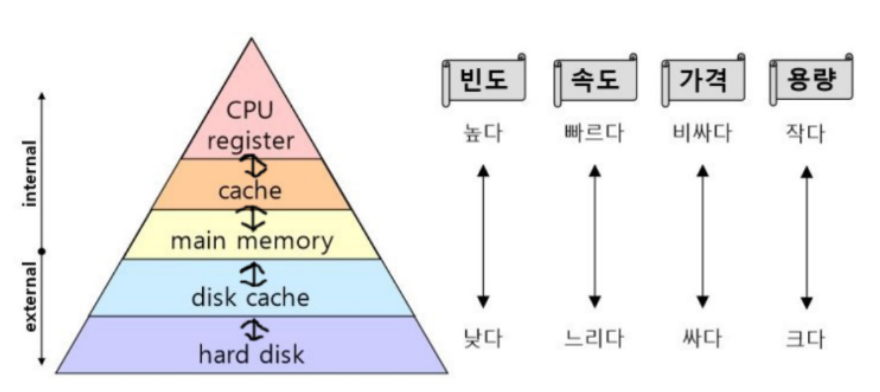
메모리 계층 구조
메모리의 종류에는 여러 가지가 있고, 각각의 쓰임새가 있다. 이를 표현한 계층도를 메모리 계층 구조(Memory Hierarchy)라고 한다. 그림에서 위쪽에 위치할수록 접근 빈도 수가 높으며 속도도 빠르지만, 가격이 비싸고 용량이 매우 작다.
비트에 대한 이해
살펴본 것처럼 메모리는 데이터를 저장하는 부품이다. 컴퓨터가 사용하는 모든 데이터는 비트(Bit)로 저장된다. 비트는 Binary와 Digit의 합성어로, 2가지 상태를 나타낼 수 있는 수이다.
비트에 저장할 수 있는것은 무엇이든지 상관없다. 그냥 수로서 0과 1이 될수도 있고 잠을 잔다 / 잠을 안잔다, 고양이를 만진다 / 고양이를 만지지 않는다 등의 추상적인 의미도 저장할 수 있다. 즉, 메모리에는 비트가 저장된다고 할 수 있다. 하지만 비트가 나타낼 수 상태는 오직 2가지이기 때문에 비트 하나만으로는 많은 데이터를 저장할 수 없다. 그래서 컴퓨터는 비트를 여러개 묶어 바이트(Byte)라는 단위로 데이터를 다룬다.
*1byte = 8bit이다.
엔디안
엔디안(Endian)은 비트를 저장하는 방식이다. 다른 컴퓨터로 데이터를 전송할 때는 이를 염두해둬야 하는데, 데이터 순서가 뒤섞일 수 있기 때문이다. 첫 번째 바이트가 LSB(Least Significant Bit)쪽에 위치하면 리틀 엔디안(Little Endian), MSB(Most Significant Bit)쪽에 위치하면 빅 엔디안(Big Endian)이라고 한다.
*LSB는 최하위 비트, MSB는 최상위 비트를 의미한다.
빅 엔디안은 큰 수부터 읽어나가는 방식으로 사람이 읽고 쓰는 순서와 동일하게 저장되어 메모리값을 보기 편하기 때문에 소프트웨어의 디버그가 편하다는 장점이 있다. 반대로, 리틀 엔디안은 작은 수부터 읽어나가는 방식으로 컴퓨터 친화적인 방식이기 때문에 수학적인 연산이 쉽다는 장점이 있다.
CPU
CPU(Central Processing Unit)는 우리가 입력한 명령어의 처리를 담당하는 부품이다. CPU도 컴퓨터처럼 여러 부품으로 구성되는데, 크게 산술 논리 장치와 레지스터 및 제어 장치로 구성된다.
산술 논리 장치
산술 논리 장치(ALU : Arithmetic Logic Unit)는 CPU의 핵심 부품으로 연산을 담당하는 장치다. 산술 논리 장치는 연산을 의미하는 명령코드(Opcode)와 피연산자를 갖고 결과를 산출하게 된다.
명령코드는 CPU의 종류에 따라 다른데 이는 미리 정의되어 있다. 명령코드의 집합을 명령어 집합(Instruction Set)이라고 하며, 우리가 흔히 쓰는 x86이란 x86 명령어 집합 아키텍처를 의미한다.
x86 아키텍처의 명령어 개수는 매우 많고 복잡하다. 이런 컴퓨터를 CISC(Complex Instruction Set Computer)라고 한다. 반대로 모바일 칩셋에 들어가는 ARM 아키텍처의 경우 CISC에서 주로 사용되는 명령어만 남겼는데, 이를 RISC(Reduced Instruction Set Computer)라고 한다.
레지스터
레지스터(Register)는 CPU에 있는 메모리다. ALU가 사용할 데이터, 명령코드, 결과 데이터 등 모두 레지스터에 저장된다. 다시 말해 메모리에 있는 데이터를 조작하기 위해서는 그 데이터를 레지스터로 가져와야 한다는 것이고, 메모리에 데이터를 저장하고 싶을 때도 레지스터에서 메모리로 보내는 과정이 필요하다.
*명령코드가 저장되는 레지스터를 프로그램 카운터(PC : Program Counter)라고 한다.
제어 장치
제어 장치(Control Unit)는 실행 장치(Execution Unit)라고도 하며, 메모리에서 명령코드와 피연산자들을 가져와서 ALU에게 어떤 연산을 수행할지 알려주고, 결과를 메모리에 돌려준다.
입력과 출력
컴퓨터로 데이터를 주는 것을 입력(Input)이라고 하고, 컴퓨터가 우리에게 데이터를 주는 것을 출력(Output)이라고 한다. 입출력 장치는 여러 가지가 있으며 우리가 그 중 흔히 사용하는 입력 장치로는 키보드와 마우스가 있고, 출력 장치는 모니터가 있다.
폴링 레이트
각 입력 장치는 특정한 주기를 가지고 입력 여부를 감지해 컴퓨터로 보낸다. 이를 폴링 레이트(Polling rate)라고 한다. 폴링(Polling)은 주기적으로 무언가를 처리하는 기법을 의미하는데, 예시로 어떤 입력장치의 폴링 레이트가 1000Hz라고 한다면 1000분의 1초마다 입력을 감지한다는 것을 의미한다.
리프레시 레이트
모니터의 경우 폴링 레이트와 비슷하게 리프레시 레이트(Refresh rate)가 있다. 모니터는 특정 주기마다 새로운 화면을 그리는데, 이를 리프레시(Refresh)라고 한다. 어떤 모니터의 리프레시 레이트가 75Hz라면 1초에 75번 화면을 그려주는 것이다.
게임의 프레임과 모니터의 리프레시 레이트가 일치하지 않는다면 테어링(Tearing) 현상이나 스터터링(Stuttering) 현상이 발생할 수 있다. 이를 해결하기 위한 방법이 수직 동기화(Vertical Synchronization)이다.
*테어링 현상은 게임의 프레임이 느릴 때, 스터터링은 모니터가 느릴 때 발생한다. 해결 방안으로 만들어진 수직 동기화는 모니터가 그림을 다 그릴때까지 기다린 후 가져오는 기술이다.
컴퓨터 아키텍처
컴퓨터 아키텍처(Computer Architecture)에는 폰 노이만(Von Neumann)구조와, 하버드(Harvard)구조 등이 있다. 폰 노이만 아키텍처와 하버드 아키텍처의 차이는 메모리의 수와 배열의 차이다. 폰 노이만 구조는 하나의 메모리를 가지고 있고, 하버드 구조는 2개의 메모리를 가지고 있다. 하버드 구조가 1개의 메모리를 더 가지고 있기 때문에 속도가 더 빠르지만 버스도 더 필요하므로 CPU코어에서 폰 노이만 구조보다 많은 공간을 차지하게 된다.
운영체제
각 부품을 전체적으로 관리해줄 프로그램이 운영체제(Operating System)이다. 운영체제는 프로그램을 실행하기 위해서 메모리, CPU와 같은 여러 가지 물리적인 자원을 관리한다. 모든 응용 프로그램은 운영체제위에서 동작한다.
프로세스
프로그램을 실행하면 프로세스(Process)가 된다. 프로세스는 운영체제로부터 자원을 할당 받은 개체를 의미한다. 프로세스는 프로그램을 실행하기 위한 여러 가지 데이터를 갖고 있으며, 4가지 영역이 존재한다.
코드(Code) : 명령어가 저장되는 공간
데이터(Data) : 정적데이터가 저장되는 공간
힙(Heap) : 동적 할당 영역
스택(Stack) : 정적 할당 영역
스레드
스레드(Thread)는 프로세스 내에서 실행 흐름의 단위이다. 프로세스는 데이터만을 관리하고, 이 데이터를 가지고 실행을 담당하는 것은 스레드다. 스레드는 프로세스 내에서 각각 스택만 따로 할당받고 코드, 데이터, 힙 영역은 공유한다. 운영체제의 입장에서 작업의 최소 단위는 프로세스이고, CPU의 입장에서 작업의 최소단위는 스레드다. 프로세스는 하나 이상의 스레드를 가질 수 있는데, 이를 멀티스레드(Multi-thread)라고 한다. 스레드가 여러개면 여러개의 실행 흐름을 가지므로, 여러가지 일을 동시에 병렬적으로 수행할 수 있다.
