O(n log n)인 정렬 알고리즘들
이 알고리즘은 최선으로나 평균적으로나 O(n log n)의 성능을 나타낸다.
최악의 상황에서도 병합정렬이나 힙정렬은 O( n log n)을 유지하는 반면 순수한 퀵 정렬은 오히려 O(n^2)로 뒤진다. 그래서 실제로는 퀵 정렬을 조금 개량해서 최악의 경우가 발생하지 않도록 코드를 짠다.
📌 병합정렬
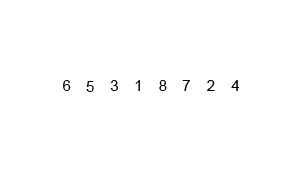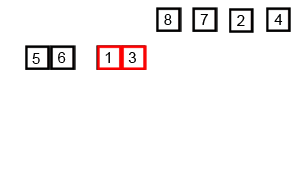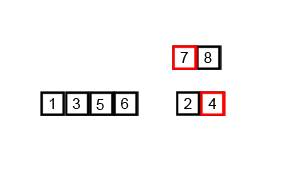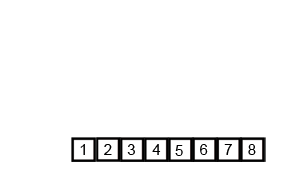
-
대표적인 분할정복(Divide and Conquer) 알고리즘.
-
분할정복이란 말 그대로 문제를 분할 한 다음, 분할한 문제들 (sub-program)을 해결하고, 그 결과를 합쳐서 원래의 문제를 해결하는 것을 말한다.
-
마찬가지로 합병 정렬은 원소의 개수가 1 또는 0이 될 때 까지 두 부분으로 쪼개고 그 결과들을 크기를 비교하며 정렬하는 방식으로 병합해나간다.
-
성능은 퀵정렬보다 전반적으로 뒤떨어지고, 데이터 크기만한 메모리가 더 필요하지만, 최대의 장점은 데이터의 상태에 별 영향을 받지 않는다는 점이다.
-
정렬되어있는 두 배열을 더할 때 이 알고리즘을 사용하면 가장 빠르게 정렬된 상태로 합칠 수 있다.
📌 퀵 정렬

-
여기서 힙은 힙트리로, 여러개의 값 들 중 가장 크거나 작은 값을 빠르게 찾기 위해 만든 이진 트리이다. 짧게 힙이라고 부른다.
-
힙은 항상 완전 이진 트리의 형태를 띈다. 부모의 값은 항상 자식들의 값보다 크거나 (Max Heap) 작아야 (Min Heap) 한다는 규칙이 있다. 따라서 루트(뿌리) 노드에는 항상 데이터들 중 가장 큰 값 혹은 작은 값이 저장되어 있다.
-
힙 정렬의 방법은 아래와 같다.
- 배열의 원소들을 전부 힙에 삽입
- 가장 부모노드에 있는 값은 최댓값 혹은 최솟값이므로 루트를 출력하고 힙에서 제거
- 힙이 빌 때 까지 2의 과정을 반복
-
힙정렬은 추가적인 메모리를 전혀 필요로하지 않는다는 점과 최악의 경우에도 항상 O(n log n) 의 성능을 발휘한다는 장점이 있다.
📌 힙정렬
-
퀵정렬은 배열에 있는 수 중 사용자가 지정한 규칙대로 임의의 pivot을 잡고, 해당 pivot을 기준으로 작거나 같은 수를 왼쪽 파티션, 큰 수를 오른쪽 파티션으로 보낸다. 다시 왼쪽 파티션 구간에 한하여 pivot을 잡고 파티션을 나누고 오른쪽 파티션 구간에서도 pivot을 잡고 파티션을 나누는 과정을 반복하여 정렬시킨다.
-
이 알고리즘의 핵심은 pivot을 잡는 것인데, pivot을 해당 구간의 중앙값으로 잘 설정하면 시간복잡도 O(n log n)에 수행할 수 있지만, 만약 매 케이스마다 구간의 최댓값이나 최솟값으로 나눠버리면 O(n^2)의 수행시간을 갖게 된다.
-
현존하는 컴퓨터 아키텍처 상에서 비교연산자를 사용하여 구현된 정렬 알고리즘 중 가장 고성능인 알고리즘이다. 단, 데이터에 접근하는 시간이 오래 걸리는 외부 기억장소(하드디스크 등)에서 직접 정렬을 수행할 경우에는 병합 정렬이 더 빠른 것으로 알려져 있다.
🧩 Reference
