Tableau_CH3-17~CH4-01
CH3-17~CH4-01: 태블로(Tableau) 연산 처리 순서
1. TABLEAU 연산 처리 순서
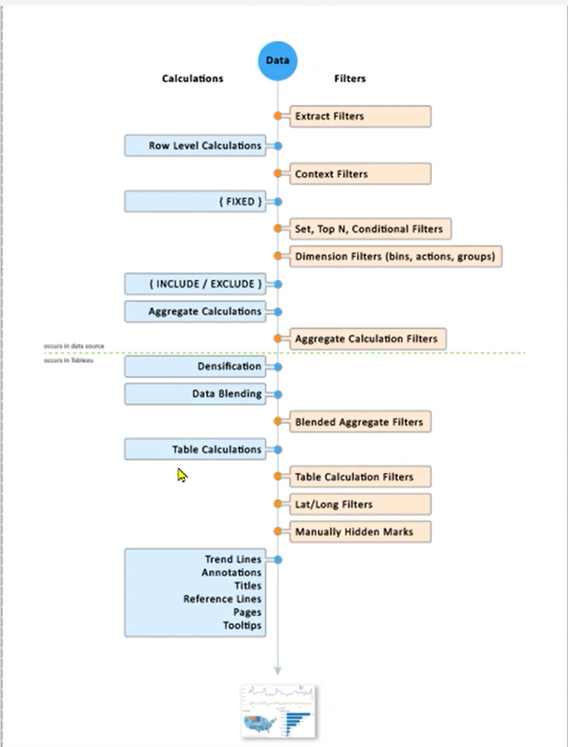
- Data: 데이터 처리의 시작점입니다. 이 단계에서는 Tableau가 데이터 소스와 연결되고 원시 데이터가 불러와집니다.
- Calculations and Filters: 데이터에 대한 계산과 필터가 적용되기 시작합니다. 이는 두 가지 주요 경로로 진행됩니다.
- Row Level Calculations: 각 행에 대한 계산이 수행되며, 이는 데이터가 불러와진 직후 바로 적용됩니다. 이 계산들은 데이터가 집계되기 전에 적용되므로, 각 행의 값을 변경할 수 있습니다.
- Extract Filters: 데이터를 추출할 때 적용되는 필터로, 데이터 세트의 크기를 줄이는 데 도움이 됩니다.
- FIXED: FIXED LOD(Expression of Detail) 계산이 적용됩니다. 이는 다른 필터들이 적용되기 전에 특정 차원에 대해 고정된 집계 수준을 설정합니다.
- Context Filters: 이 필터는 다른 필터들이 적용되기 전에 설정되어, 그 이후의 모든 필터링이 해당 컨텍스트 내에서만 작동하도록 합니다.
- Set, Top N, Conditional Filters: 이들 필터는 데이터를 더 세부적으로 필터링합니다. 예를 들어, 상위 N개의 항목이나 특정 조건을 충족하는 데이터만 선택할 수 있습니다.
- Dimension Filters: 차원에 기반한 필터로, 사용자가 특정 차원의 값을 기준으로 데이터를 필터링할 수 있게 합니다.
- INCLUDE/EXCLUDE: 이 LOD 계산은 특정 차원을 포함하거나 제외하면서 데이터를 집계합니다. 이는 뷰의 기본 집계 수준을 변경합니다.
- Aggregate Calculations: 이 단계에서는 데이터가 집계되며, 여기에는 INCLUDE/EXCLUDE 계산이 포함됩니다.
- Aggregate Calculation Filters: 집계된 계산에 대한 필터가 적용되며, 이는 집계 수준에서 계산된 데이터에 기반합니다.
- Densification: 데이터의 '덴스화'가 발생하여, 누락된 데이터 포인트를 생성하거나 기존 포인트를 보간할 수 있습니다.
- Data Blending: 여러 데이터 소스를 조합하여 단일 뷰에서 사용할 수 있도록 합니다.
- Blended Aggregate Filters: 데이터 블렌딩 후에 적용되는 집계 필터입니다.
2. LOD 함수의 세부적 설명
FIXED 함수
설명:
- FIXED 함수는 지정된 차원에 대해 데이터를 고정된 수준으로 집계합니다. 이는 필터링과 상관없이 일정한 집계 수준을 유지하며, 결과는 뷰의 다른 차원이나 집계에 영향을 받지 않습니다.
- 적용 시점: FIXED 계산은 데이터 소스의 집계 수준에서 수행됩니다. 즉, 필터링 전에 적용되며, 결과는 대시보드에서 사용되는 모든 필터의 영향을 받지 않습니다(단, 컨텍스트 필터 제외).
예시:
제품 카테고리별로 평균 판매액을 계산하고, 이 평균 값이 각 주문에 불문하고 동일하게 유지되기를 원할 때, FIXED [제품 카테고리] : AVG([판매액]) 공식을 사용할 수 있습니다. 이렇게 하면 각 제품 카테고리에 대한 평균 판매액이 계산되고, 이 값은 모든 관련 시각화에서 일정하게 유지됩니다.
INCLUDE 함수
설명:
- INCLUDE 함수는 지정된 차원을 뷰의 기본 집계 수준에 추가하여, 더 상세한 수준에서 데이터를 집계합니다. 이는 특정 차원을 분석의 컨텍스트에 포함시키고자 할 때 유용합니다.
- 적용 시점: INCLUDE 계산은 뷰의 기본 집계 수준보다 더 상세한 데이터를 필요로 할 때 사용됩니다. 이 계산은 뷰에 사용된 차원에 의해 결정된 집계 수준 이후에 적용됩니다.
예시:
만약 사용자가 각 지역별로 제품 카테고리에 따른 평균 판매액을 알고 싶을 때, INCLUDE [제품 카테고리] : AVG([판매액]) 공식을 사용할 수 있습니다. 이 경우, 각 지역 내에서 제품 카테고리별 평균 판매액이 계산되며, 지역 차원이 뷰에 이미 포함되어 있다면 제품 카테고리 차원이 추가적인 상세 수준을 제공합니다.
EXCLUDE 함수
설명:
- EXCLUDE 함수는 뷰의 기본 집계 수준에서 하나 이상의 차원을 제외하고 데이터를 집계합니다. 이는 특정 차원을 분석에서 제외하고 싶을 때 사용됩니다.
- 적용 시점: EXCLUDE 계산은 특정 차원을 집계에서 제외하여 더 일반적인 수준에서 데이터를 집계할 필요가 있을 때 사용됩니다. 이 계산은 뷰에 사용된 차원에 의해 결정된 집계 수준 이후에 적용됩니다.
예시:
각 지역별 전체 평균 판
매액을 계산하되, 이때 각 주문의 세부 사항은 고려하지 않으려 할 때, EXCLUDE [주문 ID] : AVG([판매액]) 공식을 사용할 수 있습니다. 이렇게 하면 주문 ID 차원이 분석에서 제외되며, 지역별로 더 일반적인 평균 판매액이 계산됩니다.
LOD 표현식의 적용과 영향
LOD 표현식은 Tableau에서 매우 강력한 도구로, 사용자가 데이터를 다양한 수준에서 분석하고자 할 때 유연성을 제공합니다. FIXED, INCLUDE, 및 EXCLUDE 함수를 사용함으로써, 사용자는 필터링, 집계, 및 시각화 단계에서 데이터를 보다 정밀하게 제어할 수 있습니다. 이러한 기능은 복잡한 데이터 분석 요구 사항을 충족시키고, 더 깊이 있는 인사이트를 얻을 수 있도록 돕습니다.
3. 대략적인 시각화 순서
1. 데이터 소스 연결과 준비
상세 설명:
- 데이터 연결 설정: Tableau는 다양한 유형의 데이터 소스에 연결할 수 있는 유연성을 제공합니다. 사용자는 데이터베이스, 파일, 웹 데이터 커넥터 등을 선택하고 연결 세부 정보를 구성합니다. 이 단계에서의 설정은 데이터의 접근성과 성능에 영향을 미칩니다.
- 초기 데이터 탐색: 데이터를 처음 불러온 후, Tableau의 데이터 소스 탭에서 기본적인 데이터 구조와 필드 유형을 검토할 수 있습니다. 사용자는 이를 통해 데이터의 전체적인 개요를 파악하고 분석 계획을 세울 수 있습니다.
- 데이터 클린징: Tableau Prep Builder와 같은 도구를 사용하여 데이터를 클린징하고 준비할 수 있습니다. 이 과정에는 결측치 처리, 중복 제거, 데이터 형식 변환 등이 포함됩니다.
예시:
예를 들어, 사용자가 Excel 파일에 저장된 판매 데이터를 분석하기 위해 Tableau에 연결합니다. 연결 후, 사용자는 날짜 필드의 형식이 일관되지 않음을 발견하고, 모든 날짜를 'YYYY-MM-DD' 형식으로 통일하는 작업을 수행합니다.
2. 계산 필드 생성
상세 설명:
- 계산 필드의 구성: 계산 필드는 사용자가 정의한 수식을 기반으로 새로운 데이터를 생성합니다. Tableau에서는 다양한 수학적, 논리적, 날짜 및 문자열 함수를 제공하여 복잡한 데이터 변환을 지원합니다.
- 계산 컨텍스트 이해: 계산 필드를 생성할 때는 계산의 컨텍스트를 명확히 이해해야 합니다. 예를 들어, 집계 수준(로우 레벨, 요약 레벨)과 필터링이 계산 결과에 어떤 영향을 미치는지 고려해야 합니다.
예시:
판매 데이터에서 '순이익'을 계산하기 위해 '총매출'에서 '비용'을 빼는 계산 필드를 생성합니다. 사용자는 SUM([총매출]) - SUM([비용])이라는 수식을 사용하여 '순이익' 필드를 정의합니다.
3. 데이터 집계와 요약
상세 설명:
- 다양한 집계 수준: 사용자는 데이터를 다양한 차원(예: 시간, 지역, 제품 카테고리)에 따라 집계할 수 있습니다. 이를 통해 고차원적인 데이터 분석이 가능해집니다.
- 고급 분석 기능: Tableau는 추세선, 예측, 백분위 수 계산 등 고급 분석 기능을 제공합니다. 이러한 기능은 복잡한 데이터 집계 및 분석 요구사항을 충족시키기 위해 사용될 수 있습니다.
예시:
월별로 '순이
익'을 집계하여 시간에 따른 이익 변화를 분석합니다. 사용자는 '판매일자' 필드를 월별로 집계하고, 각 월에 대한 '순이익'의 합계를 계산하여 선 그래프로 시각화합니다.
4. 필터링
상세 설명:
- 필터링 전략: Tableau에서 필터링은 데이터의 특정 부분을 탐색하거나, 분석 대상을 제한하는 데 사용됩니다. 데이터 소스 필터, 컨텍스트 필터, 차원 및 측정값 필터 등 다양한 필터 유형을 전략적으로 사용할 수 있습니다.
- 동적 필터링: 파라미터와 대화형 컨트롤을 사용하여, 사용자의 입력에 따라 필터 조건이 동적으로 변경되도록 설정할 수 있습니다. 이를 통해 대시보드의 상호작용성을 크게 향상시킬 수 있습니다.
예시:
사용자가 '2023년' 데이터만 분석하기를 원한다면, '판매일자' 필드에 연도별 필터를 적용하고 '2023'년만 선택합니다. 추가로, 사용자는 제품 카테고리별로 데이터를 더 세분화하기 위해 대화형 필터를 구성할 수 있습니다.
5. 시각화 생성 및 조정
상세 설명:
- 시각화 유형의 선택: 데이터의 특성과 분석 목적에 맞는 시각화 유형을 선택하는 것은 중요합니다. Tableau는 사용자가 데이터를 효과적으로 전달할 수 있도록 다양한 시각화 옵션을 제공합니다.
- 맞춤형 시각화: 사용자는 시각화의 색상, 크기, 축, 레이블 등을 맞춤 설정하여 데이터의 이해도를 높이고, 시각적 매력을 강화할 수 있습니다.
예시:
월별 '순이익' 데이터를 선 그래프로 시각화한 후, 사용자는 추세선을 추가하여 장기적인 이익 변화를 강조합니다. 또한, 특정 월에 대한 데이터 포인트에 주석을 추가하여 주목할 만한 이벤트나 변동 사항을 설명합니다.
6. 대시보드 및 스토리텔링
상세 설명:
- 대시보드 구성 요소: 대시보드는 여러 시각화, 텍스트 상자, 이미지, 웹 페이지 등을 조합하여 만들 수 있습니다. 사용자는 이러한 구성 요소들을 활용하여 데이터 스토리를 효과적으로 전달할 수 있는 대시보드를 구성합니다.
- 상호작용성 추가: 대시보드에는 액션(예: 필터, 하이라이트, URL 액션)을 추가하여 사용자의 상호작용을 유도하고, 데이터 탐색 경험을 향상시킬 수 있습니다.
예시:
'2023년 판매 분석' 대시보드를 구성하면서, 사용자는 월별 '순이익' 선 그래프, 지역별 매출 분포 맵, 제품 카테고리별 매출 바 차트를 포함시킵니다. 각 시각화는 상호작용적 필터를 통해 연결되어, 사용자가 한 시각화에서 선택을 변경할 때 다른 시각화도 동시에 업데이트되도록 설정합니다.
