배달 서비스 가게 노출 시스템 설계
- 리아님 감사합니다.
목차
1. 들어가며
시스템 디자인 스터디에서 "배달의민족 가게 노출 시스템"을 주제로 선정했습니다. 대규모 트래픽을 처리하는 검색 시스템 설계 경험을 쌓고, 실무에서 마주칠 수 있는 다양한 기술적 트레이드오프를 고민해보기 위함이었습니다.
배민의 가게 검색은 단순해 보이지만, 실제로는 많은 고민이 필요한 시스템입니다:
- 대규모 트래픽: DAU 1,000만, Peak 시 초당 10만 건의 요청
- 복잡한 검색: 지역 + 카테고리 + 필터링 + 정렬
- 실시간성: 가게 영업 상태 반영
- 개인화: 사용자별 맞춤 결과
이 글에서는 어떤 고민을 했고, 어떤 기술적 선택을 했는지 공유하겠습니다.
2. 요구사항 정의
2.1 기능적 요구사항
핵심 기능:
- 가게 리스트 조회 (지역 기반)
- 복잡한 필터링 (카테고리, 배달팁, 별점, 최소주문금액 등)
- 정렬 (별점, 거리, 배달시간)
- 비정형 텍스트 검색 ⭐ (가게 설명, 메뉴 설명)
- 광고 노출
- 개인화 (찜한 가게, 최근 주문)
- 실시간 상태 반영 (영업 중/종료)
2.2 비기능적 요구사항
규모:
- DAU: 1,000만 명
- 평균 QPS: 579
- Peak QPS: 10만 ⭐
- 등록 가게 수: 100만 개
성능:
- 응답 시간: 200ms 이하
- 가용성: 99.999% (연간 5분 다운타임)
확장성:
- 3,000만 DAU까지 확장 가능
2.3 Use Case 분석
트래픽 분석 결과 다음과 같은 패턴을 발견했습니다:
전체 요청 분포:
├─ 인기 지역 검색: 20% (강남, 홍대, 잠실 등)
├─ 상세 필터링: 30% (여러 조건 조합)
├─ 개인화: 일부
└─ 실시간 상태 변경: 중요핵심 인사이트:
- 인기 지역에 트래픽이 집중됨 (70% 정도)
- → 인기 지역을 동적으로 감지하고 집중 캐싱하면 효율적!
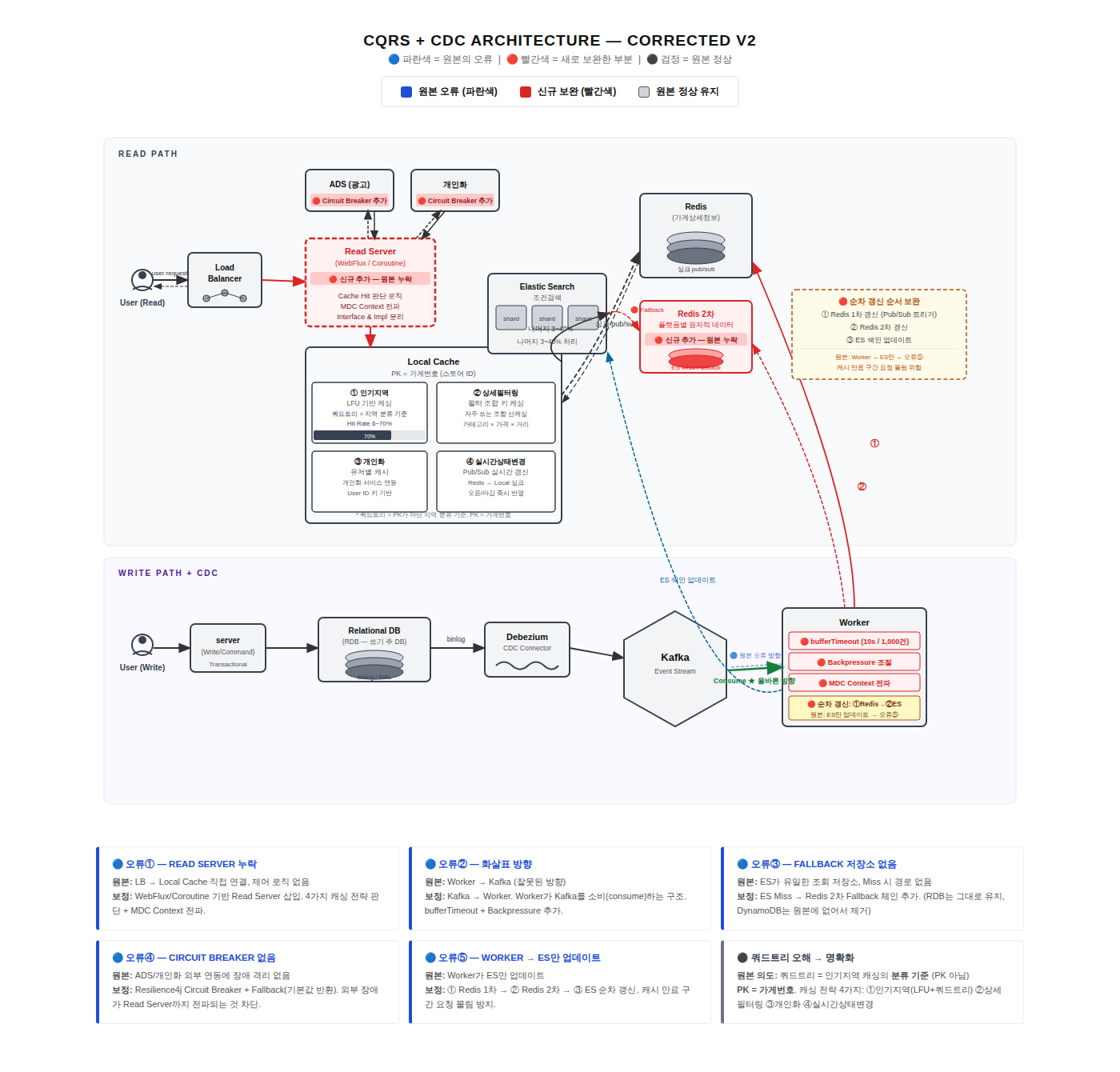
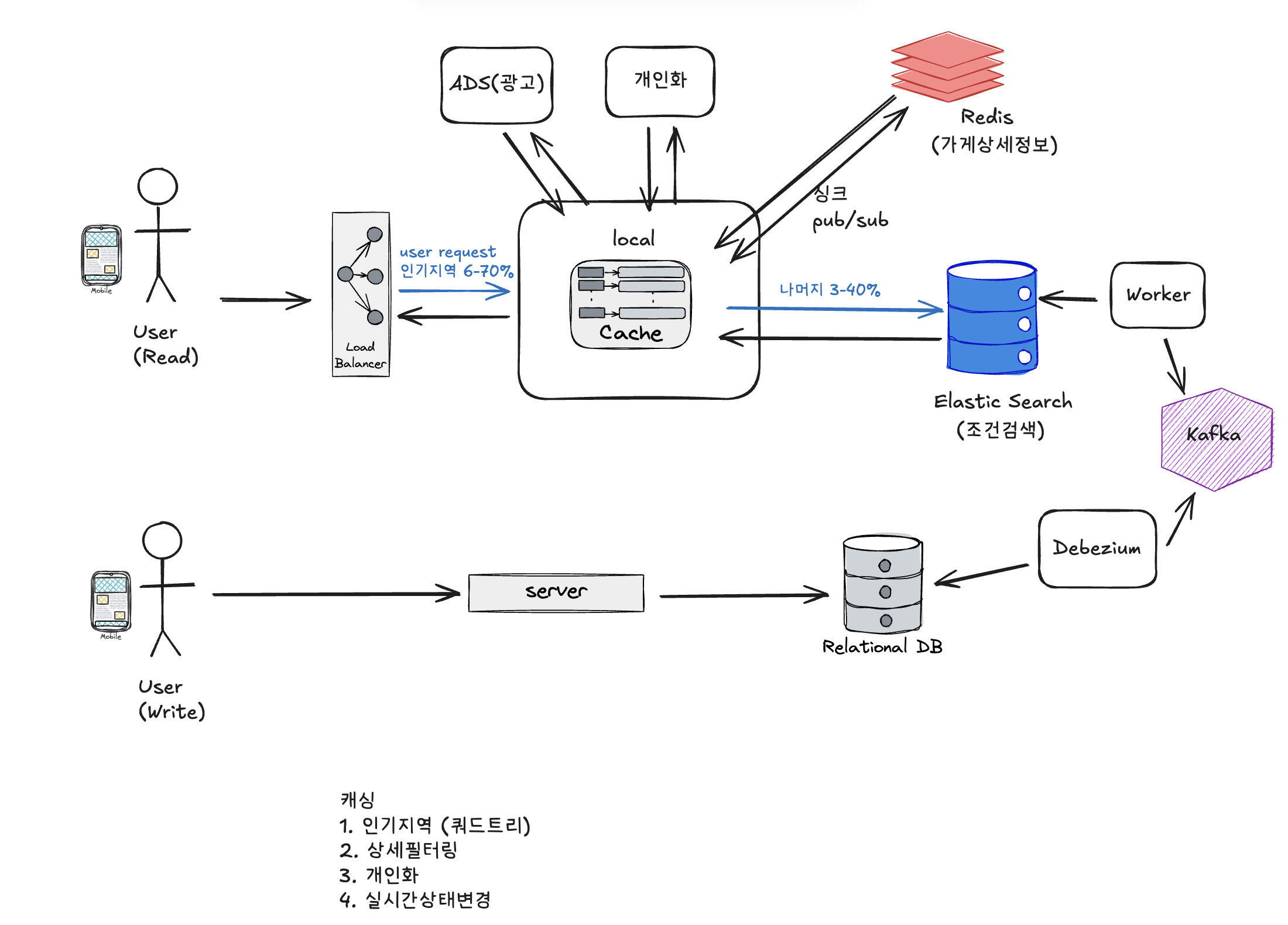
3. 전체 아키텍처
3.1 High-Level Architecture
[사용자 - Peak QPS 10만]
↓
[Load Balancer]
↓
[API Servers (15대, Auto Scaling)]
↓
┌────┴─────┬──────────┬──────────┐
↓ ↓ ↓ ↓
[로컬캐시] [Redis] [ES] [RDB]
70% 15% 15% Source of
1-2ms 5-10ms 30-50ms Truth3.2 핵심 컴포넌트
1. API Servers (멀티 서버 + LB)
- 15대 서버 (Auto Scaling)
- 각 서버는 독립적인 로컬 캐시 보유
- Load Balancer로 분산
2. 3-Tier 캐싱
- L1: 로컬 캐시 (인메모리) - 인기 지역만
- L2: Redis (분산 캐시) - 전체 검색 결과
- L3: ElasticSearch - 캐시 Miss만
3. ElasticSearch
- 검색/필터링 엔진
- 최소 데이터만 저장 (재색인 최소화)
- store_id + 검색 필드만
4. PostgreSQL
- Source of Truth
- 트랜잭션 보장
- 관계형 데이터 관리
5. Redis
- 분산 캐시 (검색 결과)
- Materialized View (가게 상세 정보)
- 실시간 상태 저장
6. CDC 파이프라인
- Kinesis Streams
- Lambda Worker (실시간 동기화)
- 배치 Server (Fallback)
3.3 데이터 흐름
읽기 경로 (검색):
Client 요청
↓
로컬 캐시 확인 (인기 지역이면)
↓ Hit (70%) → 1-2ms 응답
↓ Miss
Redis 확인
↓ Hit (15%) → 5-10ms 응답
↓ Miss
ElasticSearch 쿼리 (15%)
↓
store_id 리스트 반환
↓
Redis Materialized View에서 상세 정보 조회
↓
최종 응답 (30-100ms)쓰기 경로 (가게 정보 변경):
사장님이 가게 정보 변경
↓
PostgreSQL 업데이트
↓
Binary Log (CDC)
↓
Kinesis Streams
↓
Lambda Worker
├─ ElasticSearch 재색인
├─ Redis View 갱신 (배치)
└─ Redis Pub/Sub 발행
↓
모든 API 서버
↓
로컬 캐시 무효화4. 캐싱 전략
4.1 왜 3-Tier 캐싱인가?
문제 인식:
Peak QPS 10만을 ElasticSearch가 직접 받으면?
- ES 클러스터 18대 이상 필요
- 월 $3,000+ 비용
- 운영 복잡도 증가
해결책:
캐싱으로 85% 트래픽 차단 → ES는 1.5만 QPS만 처리
10만 QPS 중:
├─ 로컬 캐시: 7만 (70%) ← 인기 지역
├─ Redis: 1.5만 (15%)
└─ ElasticSearch: 1.5만 (15%)4.2 L1: 로컬 캐시 (인메모리)
대상:
- 인기 지역 Top 20만 캐싱
- QuadTree로 동적 선정 (10분마다 갱신)
구조:
각 API 서버 메모리:
local_cache = {
"wydm6:치킨:rating:page:1": {...}, // 강남역
"wydjx:중식:distance:page:1": {...}, // 홍대
...
}
메모리 사용: 5-10MB (서버당)
TTL: 2-3분성능:
- 응답 시간: 1-2ms ⚡
- 네트워크 I/O 없음
- 70% 트래픽 처리
동기화 문제:
서버가 여러 대인데, 어떻게 동기화?
→ Redis Pub/Sub 사용
가게 정보 변경 시:
↓
Lambda Worker
↓
Redis Pub/Sub 발행
"wydm6 지역 캐시 무효화"
↓
모든 API 서버 수신
↓
로컬 캐시 해당 키 삭제
↓
다음 요청 시 다시 캐싱메시지 유실은?
- TTL 2-3분이므로 최악의 경우 3분 지연
- 허용 가능 (가게 정보는 실시간 변경 필수 아님)
Eviction 정책: LFU (Least Frequently Used)
메모리 초과 시:
- 사용 빈도 가장 낮은 캐시 삭제
- 단, QuadTree Top 20은 보호 (삭제 금지)4.3 L2: Redis 분산 캐시
대상:
- 모든 검색 결과 캐싱
- 지역별 × 카테고리별 × 필터별 × 페이지
Key 설계:
stores:list:{geohash}:{category}:{filters_hash}:page:{page}
예시:
stores:list:wydm6:치킨:a3f2d8:page:1
filters_hash = MD5(카테고리+배달팁+별점+정렬)성능:
- 응답 시간: 5-10ms
- 15% 트래픽 처리
- TTL: 3-5분
Redis Cluster:
구성:
- 3 Master Shards
- 3 Replica Shards
- 총 6 nodes
메모리: 각 16GB (총 48GB)4.4 L3: ElasticSearch
역할:
- 캐시 Miss 시에만 조회
- 복잡한 검색/필터링 수행
- 15% 트래픽만 처리 (1.5만 QPS)
응답 시간:
- 30-50ms
- 충분히 빠름 (목표 200ms 이내)
4.5 Redis Materialized View
개념:
가게 상세 정보를 미리 조합해서 Redis에 저장
배경:
ElasticSearch에서 store_id만 받아옴
→ 상세 정보는 어디서?
→ Redis Materialized View!
구조:
Key: store:detail:{store_id}
Value (JSON, 10-50KB):
{
"store_id": 123,
"name": "맛있는 치킨",
"description": "...",
"menus": [...],
"reviews": [...],
"business_hours": {...},
"statistics": {...}
}
TTL: 10-30분갱신:
- 배치 작업 (10분마다)
- 변경된 가게만 재조합
- RDB 여러 테이블 JOIN → Redis 저장
장점:
- RDB 부하 감소 (복잡한 JOIN 미리 수행)
- 빠른 응답 (5-10ms)
5. 인기 지역 감지
5.1 문제 정의
질문:
어떤 지역을 로컬 캐시에 넣어야 하나?
옵션:
- 정적 선정: 강남, 홍대, 잠실 등 미리 지정
- 동적 선정: 실시간 트래픽 분석
선택: 동적 선정 (QuadTree)
5.2 QuadTree 알고리즘
개념:
지도를 재귀적으로 4분할하여 트래픽 밀집 영역 자동 감지
[서울 전체 - 10만 요청]
↓ 4분할
┌────┴────┐
↓ ↓
[강남 7만] [강북 3만]
↓ 강남이 많네? 더 분할
┌────┴────┐
↓ ↓
[강남역 5만] [삼성 2만]
↓ 강남역이 핫스팟!vs Geohash 정적 분할:
QuadTree: 트래픽에 따라 크기 변동
Geohash: 고정 크기 격자
QuadTree가 더 효율적!5.3 구현 전략
실용적 접근:
- "진짜" QuadTree 구현은 복잡
- Geohash 집계로 단순화
- QuadTree 개념만 차용
10분마다:
1. 모든 요청의 Geohash 집계
예: wydm6(강남역) → 5만 건
wydjx(홍대) → 3만 건
2. Top 20 Geohash 추출
3. Redis Pub/Sub 발행
"Top 20 목록 업데이트"
4. 모든 API 서버 수신
→ 로컬 캐시 대상 갱신시간대별 변화 반영:
점심 시간 (12시):
- 업무 지구: 강남, 여의도 🔥
- 주거 지역: 낮음
저녁 시간 (19시):
- 주거 지역: 노원, 송파 🔥
- 업무 지구: 낮음
→ 10분마다 자동 조정!5.4 Geohash 활용
Geohash란?
위도/경도를 문자열로 인코딩
강남역: (37.498, 127.028) → "wydm6"
정밀도:
- 5자리 (wydm6): 약 2.4km × 2.4km
- 6자리 (wydm6g): 약 610m × 610m캐시 키에 활용:
기존: stores:list:37.498:127.028:치킨
→ 좌표 조금만 달라도 다른 캐시 (비효율)
개선: stores:list:wydm6:치킨
→ 같은 영역 사용자는 캐시 공유! ⭐
→ 캐시 히트율 대폭 증가
경계 문제 해결:
사용자가 wydm6 경계 근처
- 인접 8개 Geohash도 검색
- wydm3, wydm4, wydm7, wydm9 등
6. 데이터베이스 설계
6.1 역할 분담
핵심 원칙: 각 DB를 적재적소에 활용
PostgreSQL (RDB)
└─ Source of Truth
- 가게, 메뉴, 리뷰 등
- 트랜잭션
- 관계형 데이터
ElasticSearch
└─ 검색 전용
- 최소 데이터만 (500 bytes)
- 검색/필터링에 필요한 필드만
- 재색인 최소화
Redis
└─ 캐시 + View
- 검색 결과 캐싱
- Materialized View (상세 정보)6.2 ElasticSearch 데이터 최소화
문제:
모든 데이터를 ES에 저장하면?
ES 문서에 포함:
- 가게 기본 정보
- 메뉴 전체 (10-50개)
- 영업시간
- 리뷰 (최근 10개)
→ 문서 크기: 10-20KB
메뉴 1개 추가 → 전체 문서 재색인
리뷰 1개 추가 → 전체 문서 재색인
→ 재색인 폭탄! 💸해결: 최소 데이터만 저장
ES 문서 (500 bytes):
{
"store_id": 123,
"name": "맛있는 치킨",
"category": "치킨",
"location": {"lat": 37.498, "lon": 127.028},
"geohash_5": "wydm6",
"rating": 4.5,
"review_count": 1234,
"delivery_fee": 2000,
"min_order": 15000,
"is_open": true,
"thumbnail": "https://..."
}재색인 트리거:
✅ 재색인 필요:
- 가게명 변경
- 카테고리 변경
- 위치 변경 (이사)
- 배달팁, 별점 변경
❌ 재색인 불필요:
- 메뉴 추가/수정
- 상세 설명 변경
- 영업시간 변경
- 리뷰 개별 추가
→ RDB만 업데이트, ES 영향 없음별점 업데이트:
리뷰 100개 추가 (10분 동안)
→ 배치 작업 (10분마다)
→ 영향받은 가게만 ES 업데이트
→ 재색인 1번만!6.3 CDC 파이프라인
[PostgreSQL]
↓ Binary Log
[Debezium / AWS DMS]
↓ Change Event
[Kinesis Streams]
↓ 실시간 스트리밍
[Lambda Worker] ←─── [배치 Server (Fallback)]
↓
┌───┴────┬──────────┬──────────┐
↓ ↓ ↓ ↓
[ES] [Redis [Redis [로컬캐시
재색인 View] Pub/Sub] 무효화]Lambda Worker:
역할:
1. ES 재색인 (중요 필드만)
2. Redis Pub/Sub 발행 (즉시)
3. 변경 이벤트 큐잉 (배치용)배치 Server (Fallback):
역할:
1. Redis View 재조합 (10분마다)
2. Lambda 놓친 것 보정
3. 데이터 일관성 검증
트리거:
- 주기적 (1시간마다)
- Lambda 장애 시 (5분으로 단축)6.4 데이터 조회 플로우
검색 결과 조회:
1. ES 검색 → store_id 리스트
[123, 456, 789, ...]
2. Redis MGET로 상세 정보 조회
MGET store:detail:123 store:detail:456 ...
3. 병합해서 응답
각 가게의 전체 정보 포함Redis Miss 시:
Redis에 없으면?
→ PostgreSQL 직접 조회
→ 여러 테이블 JOIN
→ Redis에 저장 (다음 요청 대비)
→ 느리지만 (20-50ms) 드물게 발생7. 검색 기능
7.1 비정형 검색의 중요성
배민의 실제 검색 패턴:
구조화 검색 (50%):
"강남 치킨"
→ 지역(구조) + 카테고리(구조)
키워드 검색 (30%):
"바삭한 치킨"
"매운 떡볶이"
→ 형용사(비정형) + 명사(구조)
자연어 검색 (20%):
"야식으로 좋은 치킨집"
"혼자 먹기 좋은 중식"
→ 완전 비정형검색 대상:
- 가게명
- 가게 상세 설명 (비정형 텍스트)
- 메뉴명
- 메뉴 설명 (비정형 텍스트)
- 태그 (#야식 #혼술 등)
- 리뷰 키워드
7.2 ElasticSearch Full-text Search
강력한 텍스트 분석:
검색어: "바삭한 치킨"
Analyzer:
1. 형태소 분석 (nori)
"바삭한" → "바삭", "하다"
"치킨" → "치킨", "닭"
2. 유사어 확장
"바삭" → "크리스피", "바사삭"
3. Fuzzy Search (오타 허용)
"바사삭" → "바삭"
결과:
1. "바삭바삭 후라이드" ⭐⭐⭐
2. "크리스피 치킨" ⭐⭐
3. "바사삭 닭강정" ⭐Inverted Index:
일반 DB:
전체 문서 Scan → "바삭" 포함 찾기 (느림)
ElasticSearch:
Inverted Index:
"바삭" → [doc123, doc456, doc789]
→ 즉시 찾음! ⚡복합 쿼리:
{
"query": {
"bool": {
"must": [
{"match": {"description": "바삭한"}}, // 비정형
{"term": {"category": "치킨"}} // 구조
],
"filter": [
{"geo_distance": {...}}, // 지역
{"range": {"delivery_fee": {"lte": 3000}}}
]
}
},
"sort": [
{"_score": "desc"}, // 검색 점수
{"rating": "desc"} // 별점
]
}7.3 DynamoDB는 왜 안 되는가?
이 부분이 가장 중요한 의사결정 포인트였습니다!
DynamoDB 검토 배경:
- AWS Serverless 통합
- 운영 편의성
- 비용 효율 가능성
치명적 한계: 비정형 검색 불가능
DynamoDB FilterExpression:
- "바삭한" 정확히 매칭만 가능
- 형태소 분석 ❌
- 유사어 검색 ❌
- 오타 허용 ❌
- Scan 필요 (전체 테이블) → 💸💸💸비용 문제:
"바삭한" 검색:
→ 100만 개 가게 모두 Scan
→ FilterExpression으로 필터링
→ 100만 개에 대한 RCU 과금!
→ Peak 시 10만 QPS × 100만 개
→ 재앙... 💸💸💸결론:
❌ DynamoDB로는 비정형 검색 불가능
✅ ElasticSearch 필수!8. 광고 & 개인화
8.1 문제 정의
요구사항:
- 일반 가게 + 광고 가게 + 개인화 조합
- 하나의 리스트로 응답
아키텍처:
[사용자 요청]
↓
API Server (Orchestration)
↓
┌──────────┬──────────┬──────────┬──────────┐
↓ ↓ ↓ ↓ ↓
[캐시/ES] [광고 [개인화 [실시간 [RDB]
일반가게 서비스] 서비스] 상태] 필요시
↓
병렬 조회 (Promise.all)
↓
[조합 & 정렬]
↓
최종 리스트 (20개)8.2 광고 서비스
별도 Microservice:
Input:
- 사용자 위치 (geohash)
- 카테고리
- 검색 조건
Output:
- 광고 가게 리스트
- 우선순위 순 (입찰가, CTR 기반)
API:
GET /ads/search?geohash=wydm6&category=치킨&limit=5광고 데이터 저장소:
DynamoDB 또는 별도 RDB:
- campaign_id
- store_id
- target_region
- target_category
- bid_amount (입찰가)
- budget (예산)
- ctr (클릭률)8.3 개인화 서비스
개인화 데이터 (DynamoDB):
사용자별:
- favorites: [store_123, store_456]
- recent_orders: [store_789]
- preference_category: "치킨"
- preference_price_range: [15000, 25000]
API:
GET /personalization/user/{user_id}8.4 조합 로직
1단계: 병렬 조회 (50-100ms)
const [stores, ads, personalization, statuses] =
await Promise.all([
getStores({geohash, category}), // 캐시/ES
getAds({geohash, category}), // 광고 서비스
getPersonalization({userId}), // 개인화 서비스
getRealtimeStatuses() // Redis
]);2단계: 점수 계산 (5-10ms)
stores.forEach(store => {
// 기본 점수 (ES에서)
let score = store._score;
// 개인화 점수 추가
if (personalization.favorites.includes(store.store_id)) {
score += 50; // 찜한 가게
}
if (personalization.recent_orders.includes(store.store_id)) {
score += 30; // 최근 주문
}
// 실시간 상태 병합
store.is_open = statuses[store.store_id]?.is_open ?? store.is_open;
store.final_score = score;
});3단계: 정렬 & 광고 삽입 (1-2ms)
// 점수 순 정렬
stores.sort((a, b) => b.final_score - a.final_score);
// 광고 삽입 (1, 6, 11, 16번 위치)
const result = [];
const adPositions = [0, 5, 10, 15];
for (let i = 0; i < 20; i++) {
if (adPositions.includes(i) && ads[adIndex]) {
result.push({...ads[adIndex], is_sponsored: true});
adIndex++;
} else if (stores[storeIndex]) {
result.push(stores[storeIndex]);
storeIndex++;
}
}총 응답 시간: 60-120ms ✅ (목표 200ms 이내)
8.5 캐싱 전략
일반 가게 리스트:
- 로컬 캐시 or Redis에 캐싱
- 개인화 제외한 순수 검색 결과
광고:
- 짧은 TTL (30초)
- 예산 소진 시 빠르게 반영
개인화:
- 사용자별이므로 캐싱 효과 낮음
- DynamoDB DAX로 자동 캐싱
9. 기술 의사결정
9.1 DynamoDB 검토 과정
우리 팀은 DynamoDB를 두 가지 용도로 검토했습니다.
9.1.1 RDB 대신 DynamoDB?
고려 이유:
- Serverless, 무한 확장
- 관리 편의성
- 빠른 Key-Value 조회
결론: ❌ 부적합
이유:
1. 복잡한 관계형 데이터
- 가게 ↔ 메뉴 (1:N)
- 가게 ↔ 리뷰 (1:N)
- JOIN 필수
2. Materialized View 생성 복잡
- 여러 테이블 조합 어려움
- RDB 쿼리 하나면 끝날 것을
여러 번 조회 + 애플리케이션 병합
3. 트랜잭션 제약
- 가게 등록 시: 가게+메뉴+영업시간 (원자성)
- DynamoDB 트랜잭션은 제한적
4. 데이터 무결성
- Foreign Key 없음
- 애플리케이션에서 보장 → 버그 위험9.1.2 ElasticSearch 대신 DynamoDB?
고려 이유:
- ES 운영 부담 제거
- AWS 통합
- 비용 절감 가능성
결론: ❌❌❌ 절대 불가능
치명적 한계:
1. 비정형 검색 불가능 (핵심!)
- "바삭한 치킨" 검색 불가
- Full-text Search 없음
- 형태소 분석 불가
2. 복잡한 필터링 제약
GSI 구조:
PK: geohash#category
SK: rating
Query:
- PK + SK 범위 조건만 가능
- 다른 조건은 FilterExpression
→ 쿼리 후 필터링 (비용 폭탄)
예: "강남 치킨, 배달팁 3000원 이하"
- geohash#category로 쿼리 → 500개
- FilterExpression 적용 → 20개만 남음
- 500개에 대한 RCU 과금! 💸
3. GSI 제한
- 최대 20개
- 필터 조합 수백 가지 → 불가능
4. 정렬 제약
- SK 하나만 정렬 가능
- 복합 정렬 불가
(별점 DESC + 배달시간 ASC 동시 불가)비용 비교:
ElasticSearch:
- 고정 비용: 월 $1,500
- 실제 조회: 1.5만 QPS (캐시 85%)
DynamoDB:
- FilterExpression 사용 시
- 평균 500개 읽고 20개 반환
- 1.5만 QPS × 500개 = 750만 RCU/초
- 💸💸💸 재앙적 비용9.1.3 최종 결론: DynamoDB 사용 범위
✅ 적합:
- 개인화 데이터 (찜, 최근 주문)
- 세션 관리
- 실시간 상태 (배달 가능 여부)
- Key-Value 조회만 필요한 경우
❌ 부적합:
- 검색 엔진 (ElasticSearch 필수)
- Source of Truth (RDB 필수)
- 복잡한 관계형 데이터9.2 지역 샤딩 미채택
검토:
ElasticSearch Shard를 지역별로 분산?
Shard 1: 강남 지역 가게
Shard 2: 홍대 지역 가게
Shard 3: 잠실 지역 가게
...
장점:
- 같은 지역 검색 시 Single Shard Query
- 성능 향상 가능미채택 이유:
1. QuadTree와 맞지 않음
- QuadTree: 동적 영역 (시간대별 변화)
- 지역 샤딩: 정적 영역
→ 불일치
2. 캐시 효율이 높음
- 85% 캐시 히트
- ES 조회 자체가 적음 (15%)
→ 샤딩 최적화 효과 미미
3. Hot Shard 우려
- 강남 Shard에 부하 집중
- 불균형 발생
4. Round-Robin이 더 적합
- 인기 지역도 여러 Shard에 분산
- 균등한 부하 분산
- 단순함최종 선택: Round-Robin 샤딩
store_id 해싱으로 균등 분산
→ 6 Shards에 고르게 배치
→ 안정적인 성능9.3 로컬 캐시 동기화 방법
Redis Pub/Sub vs Redis Streams
Redis Pub/Sub:
✅ 간단, 빠름
✅ Redis 기본 기능
❌ 메시지 유실 가능 (구독자 오프라인 시)
❌ At-most-once
Redis Streams:
✅ 메시지 저장됨
✅ Consumer Group
✅ At-least-once
❌ 복잡도 증가
❌ Consumer 관리 필요선택: Redis Pub/Sub
이유:
1. TTL 백업 (2-3분)
- 메시지 놓쳐도 TTL 만료 시 자동 삭제
2. 허용 가능한 지연
- 최악 3분 동안 오래된 데이터
- 가게 정보는 실시간 필수 아님
3. 단순함
- 운영 부담 최소화10. 성능 & 비용
10.1 성능 목표 달성 검증
응답 시간 분석:
Use Case별:
├─ 인기 지역 (70%): 1-2ms (로컬 캐시) ⭐
├─ Redis Hit (15%): 5-10ms
├─ ES 조회 (15%): 30-50ms
└─ 광고/개인화 추가: +20-50ms
평균 응답 시간: 50-100ms
Peak 응답 시간: 100-150ms
목표 200ms: ✅ 달성QPS 처리 능력:
Peak 10만 QPS 분산:
├─ 로컬 캐시: 7만 (서버당 4,667)
├─ Redis: 1.5만 (Cluster 분산)
└─ ElasticSearch: 1.5만 (6 shards, 각 2,500)
ES 처리 여유:
- ES 노드당 처리량: 1,000-3,000 QPS
- 현재 부하: 833 QPS/node
→ ✅ 여유 있음캐시 히트율:
목표: 85% 이상
├─ 로컬 캐시: 90-95% (인기 지역)
├─ Redis: 70-80%
└─ 전체: 85% ✅10.2 비용 산정 (월 기준)
인프라 비용:
ElasticSearch (18 nodes):
- 6 Data nodes (각 r5.xlarge) × 3 (Master+2 Replica)
- 월 $1,500
PostgreSQL RDS:
- db.r5.xlarge (Master)
- db.r5.large (Read Replica 2대)
- 월 $600
Redis Cluster:
- 6 nodes (각 cache.r5.large)
- 월 $400
Kinesis Streams:
- 3 Shards
- 월 $30
Lambda:
- 월 실행 시간 기준
- 월 $50
배치 서버 (ECS Fargate):
- 월 $100
DynamoDB (개인화):
- On-Demand 모드
- 월 $100
CloudWatch 모니터링:
- 월 $50
총 예상 비용: $2,830/월비용 대비 효과:
캐싱 없이 ES만으로 10만 QPS 처리:
- ES 노드 50대 이상 필요
- 월 $5,000+
현재 설계 (캐싱 포함):
- 월 $2,830
→ 약 50% 절감 💰10.3 확장 시나리오 (3,000만 DAU)
예상 부하:
Peak QPS: 30만 (현재의 3배)
캐싱 비율 유지 시:
├─ 로컬 캐시: 21만 (70%)
├─ Redis: 4.5만 (15%)
└─ ES: 4.5만 (15%)필요 리소스:
API Servers:
- 현재 15대 → 45대 (Auto Scaling)
ElasticSearch:
- 18 nodes → 54 nodes (3배)
- 월 $4,500
Redis Cluster:
- 6 nodes → 18 nodes
- 월 $1,200
PostgreSQL:
- Read Replica 추가 (2대 → 6대)
- 월 $1,200
총: $7,000/월 (약 2.5배 증가)
→ 트래픽은 3배인데 비용은 2.5배
→ 캐싱 효과로 비용 효율 증가 ⭐11. 마치며
11.1 핵심 배운 점
1. 캐싱 계층의 중요성
단순히 "캐싱을 한다"가 아니라
"어떻게 효율적으로 캐싱할 것인가"가 핵심
3-Tier 캐싱으로:
- 85% 트래픽 차단
- ES 부하 대폭 감소
- 비용 50% 절감2. 적재적소 기술 선택
"만능 기술"은 없다!
ElasticSearch:
- 검색/필터링에 최적
- 하지만 Source of Truth로는 부적합
PostgreSQL:
- 관계형 데이터 관리 최적
- 하지만 대규모 검색은 부적합
DynamoDB:
- Key-Value 조회 최적
- 하지만 복잡한 쿼리는 부적합
→ 각각의 강점을 활용하는 조합이 최선!3. 동적 최적화의 가치
정적 설정:
- 강남, 홍대 등 고정
동적 감지 (QuadTree):
- 시간대별 변화 반영
- 효율성 증가
비용은 조금 증가하지만
효과는 훨씬 크다!4. 트레이드오프 경험
모든 선택에는 장단점이 있다:
DynamoDB 검토:
- 운영 편의 vs 기능 제약
→ 기능 제약이 너무 커서 포기
로컬 캐시:
- 복잡도 증가 vs 성능 향상
→ 성능 효과가 커서 채택
지역 샤딩:
- 최적화 vs 복잡도
→ 캐시로 충분해서 미채택11.2 실무 적용 가능성
이 설계는 이론이 아닙니다. 실제 대규모 서비스에서 사용되는 패턴들입니다:
우버, 에어비엔비:
- PostgreSQL + ElasticSearch 조합
- 3-Tier 캐싱
넷플릭스:
- DynamoDB (개인화)
- ElasticSearch (검색)
아마존:
- DynamoDB (장바구니, 세션)
- 검색은 별도 엔진11.3 아쉬운 점
1. 더 깊은 논의 부족
- ES 튜닝 (Refresh Interval, Merge Policy 등)
- Redis 고급 최적화
- 장애 시뮬레이션
2. 비용 검증 부족
- 실제 비용은 더 복잡
- 네트워크, 스토리지 등 추가 비용
- 정확한 계산 필요
11.4 마무리
2시간동안 진행된 시스템 디자인 스터디였습니다. 처음에는 단순해 보였던 "가게 검색"이 얼마나 복잡하고 흥미로운 문제인지 깨달았습니다.
특히 DynamoDB를 검토하면서 "비정형 검색의 중요성"을 체감했고, ElasticSearch가 왜 필수인지 명확히 이해하게 되었습니다.
캐싱 전략 설계는 가장 재미있었던 부분입니다. 단순히 Redis를 쓰는 것이 아니라, QuadTree로 동적으로 인기 지역을 감지하고, 로컬 캐시까지 활용하는 3-Tier 전략은 실무에서도 충분히 활용 가능한 패턴입니다.
이 경험을 바탕으로 다음에는 더 깊이 있는 주제로 도전해보고 싶습니다:
- 결제 시스템 설계
- 실시간 채팅 시스템
- 추천 시스템
긴 글 읽어주셔서 감사합니다! 🙏
참고 자료
시스템 디자인 참고:
- System Design Interview (Alex Xu)
- Designing Data-Intensive Applications (Martin Kleppmann)
기술 스택 공식 문서:
- ElasticSearch Documentation
- Redis Documentation
- AWS Kinesis Developer Guide
- PostgreSQL Documentation
스터디: 시스템 디자인 스터디, 테크다이브 2기 2회차
스터디 진행일: 2026년 2월 19일
태그: 시스템디자인 ElasticSearch 캐싱전략 대규모트래픽 아키텍처
