chapter 17 Index Structure
why index?
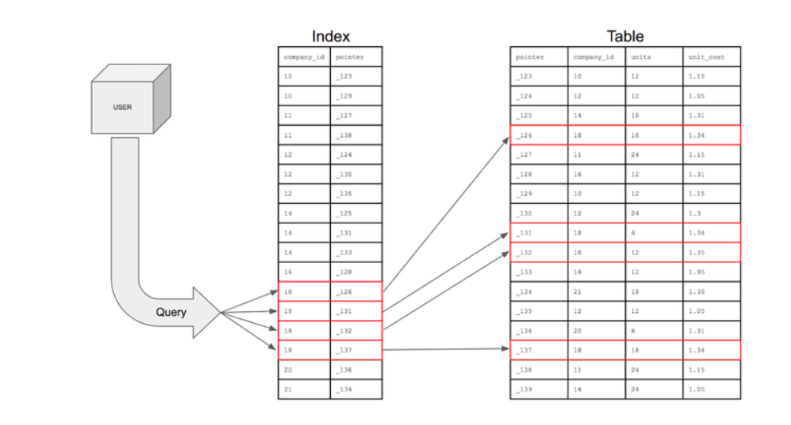
인덱스(Index)는 데이터베이스의 테이블에 대한 검색 속도를 향상시켜주는 자료구조이다.
테이블의 특정 컬럼(Column)에 인덱스를 생성하면, 해당 컬럼의 데이터를 정렬한 후 별도의 메모리 공간에 데이터의 물리적 주소와 함께 저장된다. 컬럼의 값과 물리적 주소를 (key, value)의 한 쌍으로 저장한다.
인덱스는 책에서의 목차 혹은 색인이라고 생각하면 된다. 책에서 원하는 내용을 찾을 때 목차나 색인을 이용하면 훨씬 빠르게 찾을 수 있는데, 마찬가지로 테이블에서 원하는 데이터를 찾기 위해 인덱스를 이용하면 빠르게 찾을 수 있다.
그러므로 데이터 = 책의 내용, 인덱스 = 책의 목차, 물리적 주소 = 책의 페이지 번호라고 생각할 수 있다.
<장점>
인덱스의 장점으로는 앞에서 말했듯이 테이블을 검색하는 속도와 성능이 향상된다. 또 그에 따라 시스템의 전반적인 부하를 줄일 수 있다.
핵심은 인덱스에 의해 데이터들이 정렬된 형태를 갖는다는 것이다. 기존엔 Where문으로 특정 조건의 데이터를 찾기 위해서 테이블의 전체를 조건과 비교해야 하는 '풀 테이블 스캔(Full Table Scan)' 작업이 필요했는데, 인덱스를 이용하면 데이터들이 정렬되어 있기 때문에 이진 탐색등과 같은 기법으로 빠른 검색 가능.
<단점>
인덱스가 항상 정렬된 상태로 유지되어 오는 장점도 있지만, 그에 따른 여러 단점도 존재한다.
- 인덱스를 관리하기 위한 추가 작업이 필요
- 추가 저장 공간 필요
- 잘못 사용하는 경우 오히려 검색 성능 저하
예시
storatage
ram : 성능이 좋은 하지만 가장 비싸고 휘발성이 있음
ssd : 빠르고 좋지만 쓰기에 제안을 가짐
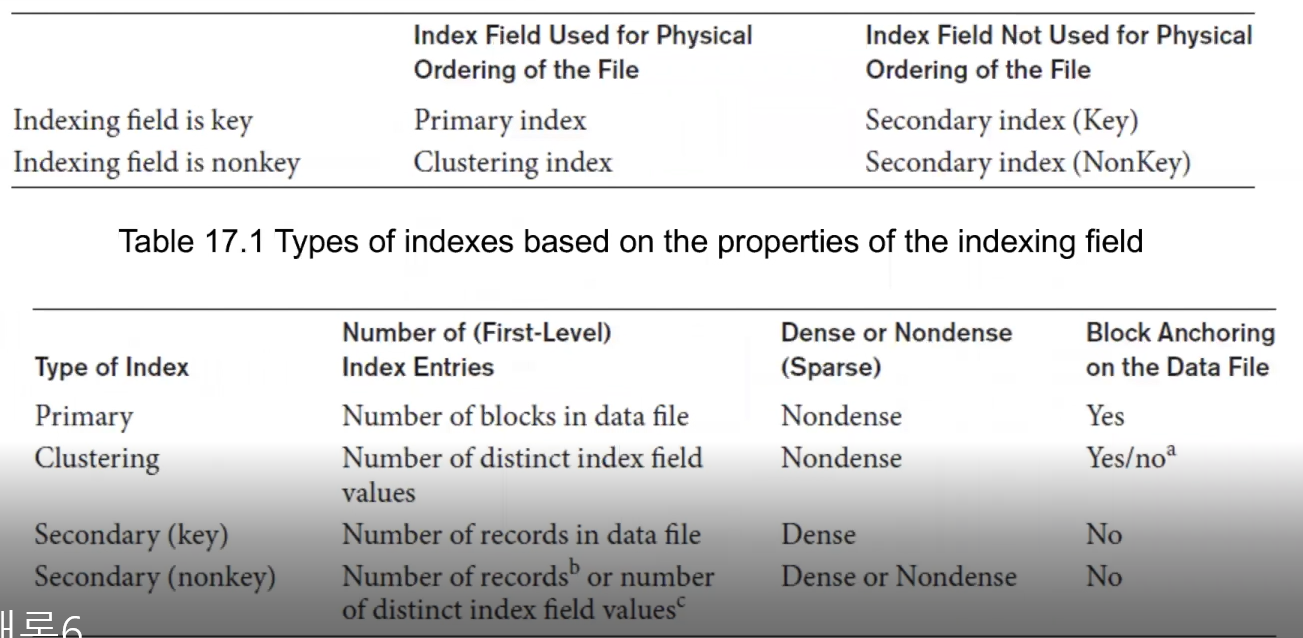
Index Type
Single-Level
-
primary :
key간에 중복이 없으며 키가 정렬 되어 있으며 file or record 또한 정렬되어 있다.
예시) 부서, 학생 데이터베이스등
-
clustering :
key간에 중복이 있다. 이 외는 primary와 같다 -
secondary :
key는 정리되어 있지만 feild가 정렬되어 있지 않다.
primary index

primary index에서의 문제점은 record의 insert와 delete일 때 발생
각 인덱스에 해당하는 블록에서 overflow가 발생하면 index를 수정하거나 블록크기를 변경해야 한다.
clustering index

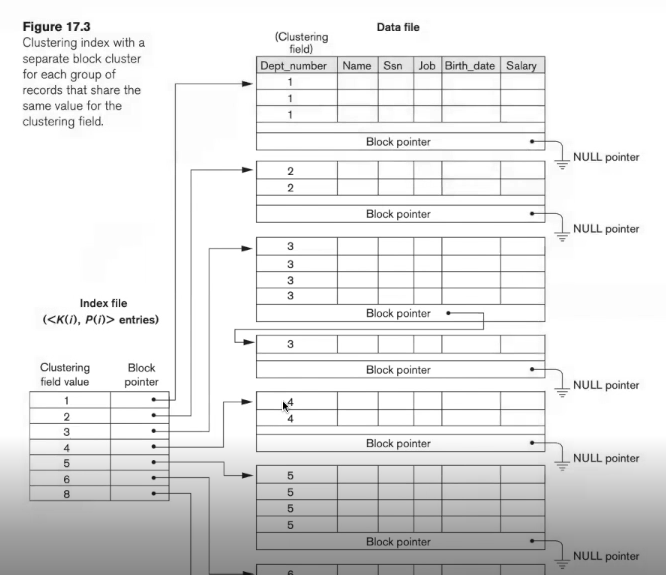
block pointer을 이용해서 새로운 블록을 만들어 overflow을 해결할 수 있다
하지만 deletion에 대한 문제를 해결 할 수 없다.
secondary index
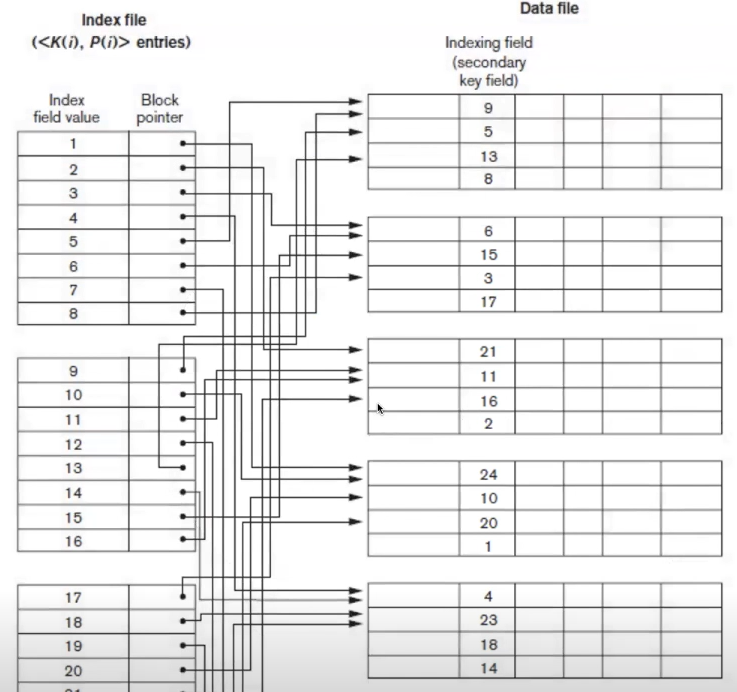
indexing field가 정렬되어 있지 않은것이 포인트
주로 자주 검색되는 것을 기준으로 인덱싱이 이루어짐
정리
Multi-Level
index table이 이려개
index table의 data structure
주로 B-Tree, B+-Tree
SEARCH TREE
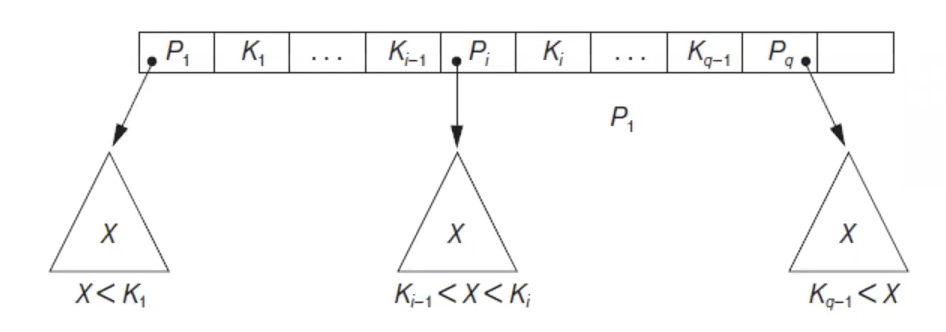
p는 sub index k는 key index값
각 sub index의 balance를 유지하게 만든 트리가 B트리
B tree
B Trees는 이진트리에서 발전되어 모든 리프노드들이 같은 레벨을 가질 수 있도록 자동으로 밸런스를 맞추는 균형이진트리의 확장판입니다.
- tree is always balanced
- each node is at least half-full (적어도 절반은 차있어야함)
- each node in a B-tree of order p can have at most p-1 search
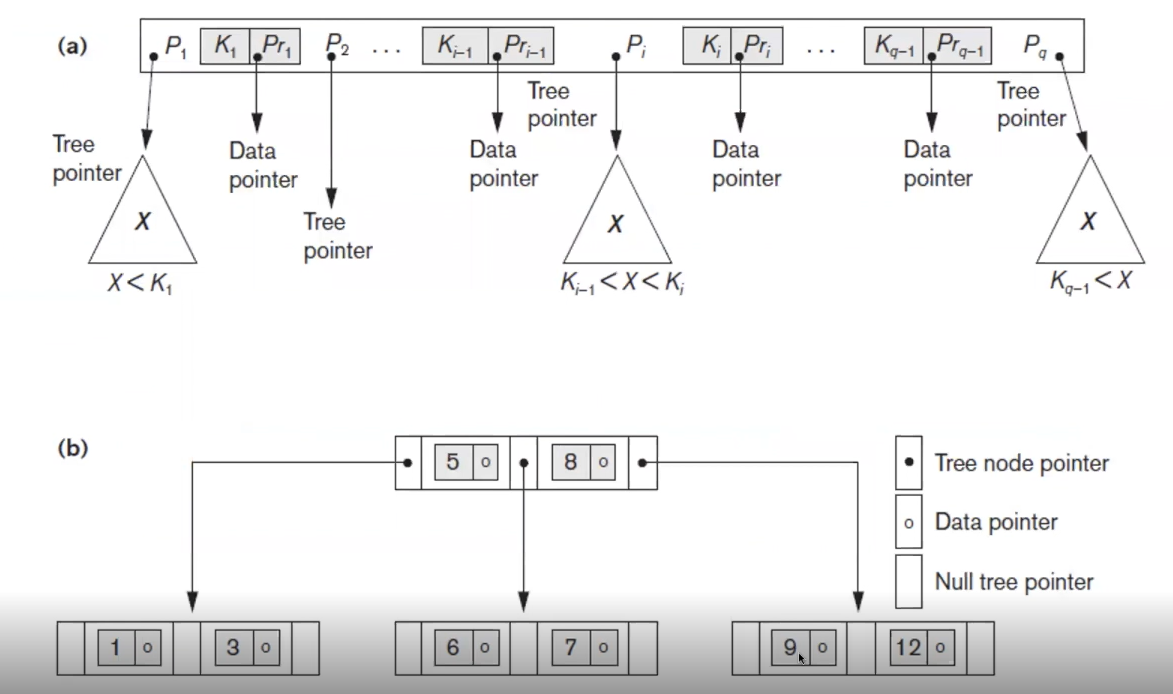
search key는 key 값과 data pointer로 이루어져 있다. 각 key에 해당하는 정보를 쉽게 access 할 수 있다.
B+ tree
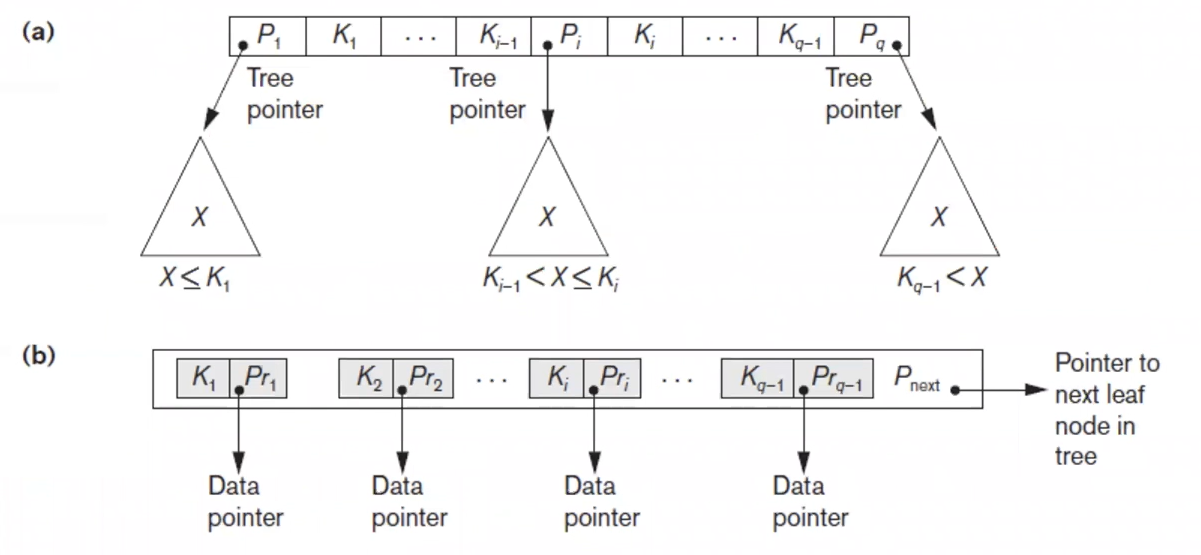
key에 대한 data pointer가 사라지고 leaf node에 data pointer가 모여있으며 서로 연결되어 있다.
비트리 작동 과정

hash index
hash function을 통해 얻은 hash 값이 같은 record끼리 모아 블록 형성
function based index
function 자체를 인덱싱으로 이용
Reference
