Chapter 14
Basic functional dependecies and normalization for relational databases
핵심 내용 : 정규화
Redundant information in Tuple and Update Anomalies
중복되는 정보과 업데이트 되는 이상치 문제
-
anomalies 종류
- insert anomalies : 불필요한 정보를 함께 저장하지 않고서는 어떤 정보를 저장하는 것이 불가능하다.
- delete anomalies : 필요한 정보를 함께 삭제하지 않고서는 어떤 정보를 삭제하는 것이 불가능하다.
- modification anomalies : 반복된 데이터 중에 일부를 갱신 할 시 데이터의 불일치가 발생한다.
-
예시
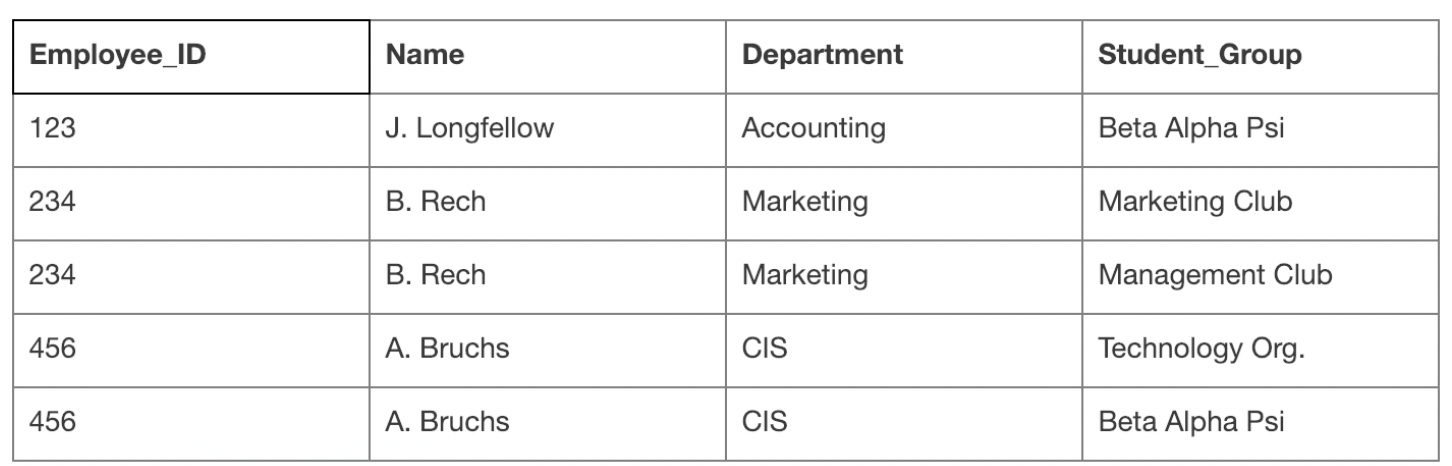
- insertion : 새로운 부서가 신설되었지만 직원이 없을 때 해당 DB에는 junk data를 넣지 않는 이상 해당 부서를 삽입 할 수 없다.
- deletion : accounting 부서에 직원이 한명일때 해당 정보를 지우면 해당 부서의 대한 정보도 사라진다.
- modification : 중복되는 인원인 A.Brushs의 정보를 변경할 때 모든 A.Brushs에 대한 정보를 바꾸어야한다.
이를 피하기 위해 NULL을 쓰면 되는거 아닌가? 많이 쓰면 쓸 수록 performance가 줄어든다.
이를 정규화를 통해 해결 할 수 있다.
정규화의 과정은 테이블을 쪼개는 과정, 가능한 join 연산을 줄이려 하는것
실행적인 측면에서는 쪼갤수록 안좋고, 데이터 저장 관리 측면에서 쪼갤 수록 좋다
Functional Dependency
관계형 데이터베이스의 설계에서 중복된 데이터가 최소화되도록 데이터베이스의 구조를 결정하는 것을 정규화 (normalization)라고 한다.
함수 종속성은 수학에서의 함수와 같이 두 필드의 집합이 many-to-one 관계로 사상되는 것을 말한다. 즉, 함수와 같이 어떠한 값을 통해 종속 관계에 있는 다른 값을 유일하게 결정할 수 있다는 것이다. 데이터베이스에서의 함수 종속성을 더욱 명확하게 정의하면 다음과 같다.
어떤 테이블 R에 존재하는 필드들의 부분집합을 각각 X와 Y라고 할 때, X의 한 값이 Y에 속한 오직 하나의 값에만 사상될 경우에 "Y는 X에 함수 종속 (Y is functionally dependent on X)"이라고 하며, X→Y라고 표기한다.
- 예시
'나이'는 '생일'에 dependency하다.

X는 SSN(social security number), Pnumber(project number)
FD 1에 따르면 해당 노동자의 작업 시간을 알 수 있다.
SSN을 통해 Ename(employee name)을 알 수 있고
Pnumber를 통해 Pname(project name), Plocation(project location)을 알 수 있다.
FD를 확인할 수 있는 방법은 무엇일까?
특정 attribute를 groupby해서 해당 attribute에 대해 일정한 dependency를 갖는 attribute가 존재하는지 확인한다.
함수 종속성과 암스트롱의 공리, closure 개념을 이용하여 super key를 판별할 수 있다.
정규화
-
제 1형 : all attributes depend on the key
제1 정규화란 테이블의 컬럼이 원자값(Atomic Value, 하나의 값)을 갖도록 테이블을 분해하는 것 -
제 2형 : all attributes depend on the whole key
제2 정규화란 제1 정규화를 진행한 테이블에 대해 완전 함수 종속을 만족하도록 테이블을 분해하는 것 -
제 3형 : all attributes depend on nothing but the key
제2 정규화를 진행한 테이블에 대해 이행적 종속을 없애도록 테이블을 분해하는 것 -
BCNF :
제3 정규화를 진행한 테이블에 대해 모든 결정자가 후보키가 되도록 테이블을 분해하는 것 -
제 4형 : 이상현상의 원인이 되는 중복값을 없애 데이터 중복성을 제거하는 것
-
제 5형도 존재 하지만 4이후는 거의 사용하지 않음
