PPO는 크게 3가지로 부분을 나누어서 설명할 수 있다.
- 예전 가중치와 데이터로 현재 목적함수를 계산하는 방법과 조건
- 조건을 지키기 위한 방법
- GAE
예전 가중치와 데이터로 현재 목적함수를 계산하는 방법과 조건
업데이트 하기 전 가중치를 theta_old라고 하고, 현재 가중치를 theta라고 하자.
정책을 개선한다는 의미는 J(theta) - J(theta_old) > 0을 만족하도록 정책을 변화시키는 것이다.
J(theta) - J(theta_old)의 식을 전개해보자.

식을 천천히 읽으면서 내려오면 크게 막히는 부분은 없을 것이다.
6번째 줄에서 7번째 줄로 넘어갈 때 tau가 st와 a_t로 범위가 줄어드는 이유는 한계밀도함수 때문에 그렇다.
7번째 줄에서 8번째 줄로 넘어갈 때 p_theta_old로써 얻어진 s_t와 a_t로 표현을 하기 위하여 importance sampling 기법을 이용하였다.
또한 gamma^t가 사라진 이유는 시간스텝이 뒤로 갈수록 미분값이 무시되는 정도가 커지기 때문에 없애준 것이다.
7번째 줄에서 8번째 줄로 넘어갈 때 \frac{p\theta(s_t)}{p_theta_OLD(s_t)}이 1과 근사한 값을 갖을 것이라고 전제를 하기 때문에, 정리된 것이다.
이렇게 J(theta) - J(theta_old)를 새로운 목적함수로써 사용할 수 있게 되었다.
데이터도 p_theta_old에서 도출된 데이터로 표현할 수 있기에 이전 데이터로 현재 가중치를 update 할 수 있다.
하지만, p_theta와 p_theta_old의 비(ratio)가 1과 비슷할 것이라고 전제조건을 지켜야 한다.
조건을 지키기 위한 방법
조건을 지키기 위해서는 정책의 비(ratio)도 서로 비슷해야 한다.
(p_theta와 p_theta_old가 비슷하다는 것은 pi_theta와 pi_theta_old가 비슷하다는 것을 의미한다.)
참고문헌: https://arxiv.org/pdf/1607.04614.pdf
그렇다면 p_theta와 p_theta_old가 비슷해야 한다는 조건은 다음의 조건으로 변경하여 생각할 수 있다.
TRPO에서는 복잡한 수학적 개념을 통해 이 문제를 해결하였지만, PPO는 간단하면서 좋은 성능을 내는 clipping 방법을 사용하였다.
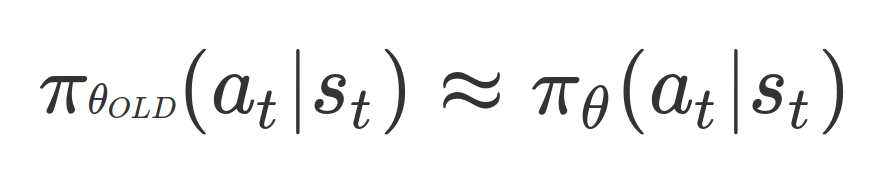
ratio를 의미하는 함수 r을 다음과 같이 정의해보자.
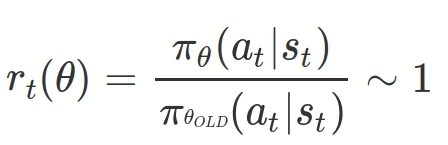
허용되는 오차범위를 eps이라고 한다면, clip함수를 다음과 같이 작성할 수 있다.

새롭게 정의된 목적함수를 다음과 같이 정의할 수 있다.
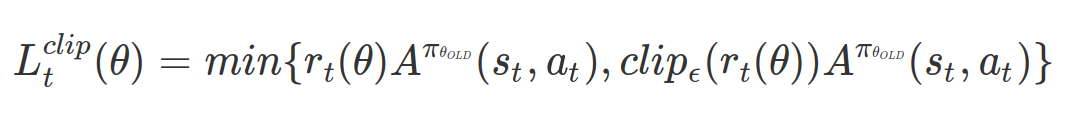
위의 목적함수를 최적화하면 정책의 ratio인 r_t(theta)는 [1-eps, 1+eps]로 범위가 한정된다. 이로써 조건을 간접적으로 지킬 수 있게 되었다.
GAE
- A3C에서는 기존의 1-step 가치 추정에서 n-step 가치 추정으로 확장하였다. PPO에서는 n-step 가치 추정의 가중합을 의미하는 GAE를 사용하였다.
n-step 가치 추정을 다음과 같이 정의하자.
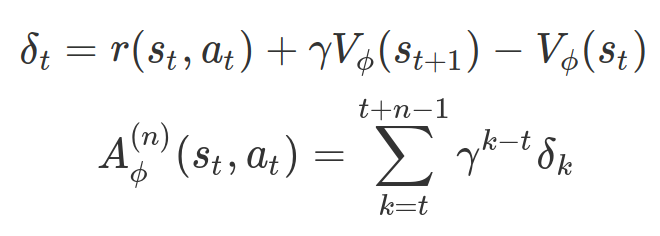
그리고 n-step GAE는 다음과 같다.

이렇게 PPO에 대해서 간략하게 알아보았다.
PPO는 간단하지만, 좋은 성능을 내어 많이 쓰이고 있는 강화학습 알고리즘 중에 하나로써, 강화학습에서 매우 중요한 개념이다.
