DB
1.📒 관계형 데이터베이스(Relational DataBase)

📌 관계형 데이터베이스(Relational DataBase) 데이터를 행과 열로 이루어진 테이블로 구성하고, 테이블 간의 관계를 정의하는 DB이다. 장고에서는 Model이라는 개념을 활용하여 RDB와의 연동을 구현한다. Model은 DB에서 Table에 해당하며 각 모델은 필드를 가지고 있다. 📌 Table DB에서 행과 열로 구성되어 있는 데이터의 ...
2.📒 SQL(1)
📌 데이터 직군 데이터 엔지니어 파이썬, 자바, 스칼라 SQL, DB ETL, ELT(Airflow, DBT) Spark, Hadoop 데이터 분석가 SQL, 비즈니스 도메인에 대한 지식 통계(AB테스트 분석) 데이터 과학자 머신러닝, 딥러닝(모델 구현) SQL, 파이썬 통계 데이터 요약과 데이터 분석을 위한 SQL을 학습해보자. 📌 관계형 Data...
3.📒 클라우드(Cloud)(1)
📌 클라우드 컴퓨팅 자원을 네트워크를 통해 서비스 형태로 사용하는 것이다. 키워드 No Provisioning Pay As You Go 자원(서버 등)을 필요한 만큼 실시간으로 할당하여 사용한 만큼 지불한다. 탄력적으로 필요한 만큼의 자원을 유지하는 것이 중요하다. 📌 클라우드의 중요성 클라우드 컴퓨팅이 없다면? 서버, 네트워크, 스토리...
4.📒 클라우드(Cloud)(2)
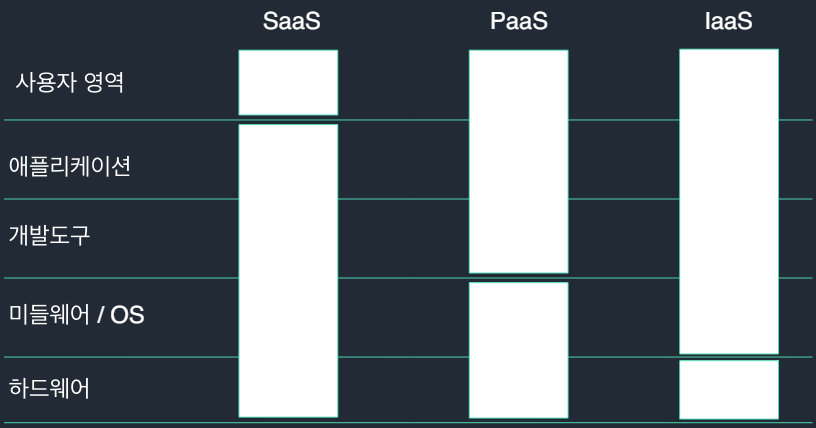
이전에 클라우드 컴퓨팅 및 AWS에대해서 알아보았다. 사실 내용이 조금 부족하다. 클라우드 및 클라우드 컴퓨팅의 기본 개념을 알아보자. 📌 클라우드 컴퓨팅 인터넷 너머에 존재하는 클라우드 사업자의 컴퓨터에서 처리하는 서비스 -> 공유 구성이 가능한 컴퓨팅 리소스(네트워크, 서버, 스토리지, APP 서비스)의 통합을 통해 어디서나 간편하게, 요청에 따라 ...
5.📒 SQL(2)
📌 관계형 데이터베이스 예제 - 웹서비스 사용자/세션 정보 사용자 ID : 보통 웹서비스에서는 등록된 사용자마다 부여하는 유일한 ID 세션 ID : 세션마다 부여되는 ID 세션 : 사용자의 방문을 논리적인 단위로 나눈 것 사용자가 외부 링크(광고)를 타고 오거나 직접 방문해서 올 경우 세션을 생성 사용자가 방문 후 30분간 Interac...
6.📒 SQL(3)
📌 GROUP BY & Aggregate 테이블의 레코드를 그룹핑하여 그룹별로 다양한 정보를 계산한다. 이는 두 단계로 이루어져있다. 그룹핑할 필드를 결정 -> Group by로 지정(필드 이름 or 필드 일련번호 사용) 다음 그룹별로 계산할 내용을 결정 -> Aggregate함수 사용 -> COUNT, SUM, AVG, MIN, MAX...
7.📒 SQL(4)
📌 JOIN SQL에서 JOIN이란 두 개 또는 그 이상의 테이블들 통합하는 것을 말한다. JOIN은 6가지가 존재하는데 각각 INNER, FULL, CROSS, LEFT, RIGHT, SELF 가 있다. 📙 JOIN 📌 주의 중복 레코드가 없고 Primary Key의 uniqueness가 보장됨을 체크해야 한다. JOIN하는 테이블들 간의 관계...
8.📒 SQL(5)
📌 트랜잭션 SQL들을 묶어서 하나의 작업처럼 처리하는 방법 더 이상 쪼갤 수 없는 업무 처리의 최소 단위이다. 거래내역이라고도 한다. 이는 DDL이나 DML중에서 레코드를 수정/추가/삭제한 것에만 의미가 있다. SELECT에는 트랜잭션을 사용할 이유가 없다. BEGIN, END 혹은 BEGIN, COMMIT 사이에 해당 SQL들을 사용한다. ...
9.📒 AWS(1)
📌 EC2 인스턴스 : 가상 컴퓨터 환경 Amazon 머신 이미지(AMI) : 서버에 필요한 운영체제와 여러 SW들이 적절히 구성된 상태로 제공되는 템플릿으로 인스턴스를 쉽게 만들 수 있다. 인스턴스 유형 : 인스턴스를 위한 CPU, 메모리, 스토리지, 네트워킹 용량의 여러 가지 구성 제공 키페어를 사용하여 인스턴스 로그인 정보 보호(AWS는 퍼블...
10.📒 AWS(2)
📌 RDS DB인스턴스는 클라우드에서 실행하는 격리된 DB환경이다. DB인스턴스에는 여러 사용자가 만든 DB가 포함될 수 있다. 독립 실행형 DB인스턴스에 액세스할 때 사용하는 도구 및 애플리케이션을 사용하여 액세스할 수 있다. AWS 명령줄 도구, Amazon RDS API 작업 또는 AWS Management Console을 사용하여 간단하게 DB인스...
11.📒 AWS(2) - RDS실습
📌RDS - 테스트 후 삭제 RDS 대시보드 DB 인스턴스 DB 생성 엔진 옵션 선택 -> 오라클, MS SQL은 오픈소스가 아니다. 탬플릿 
📌IAM AWS Identity & Access Management(IAM)은 AWS 리소스에 대한 액세스를 안전하게 제어할 수 있는 웹 서비스이다. 리소스를 사용하도록 인증(로그인) 및 권한 부여(권한 있음)된 대상을 제어한다. AWS 계정을 생성할 때는 해당 계정의 모든 AWS 서비스 및 리소스에 대한 완전한 액세스 권한이 있는 단일 로그인 ID로 시...
13.📒 AWS(3) - 실습
📌 백엔드 모듈 구성 Spring과 gradle을 이용해서 백엔드 서버를 간단하게 하나 만들어보자 이클립스를 이용한 백엔드 구성의 경험이 없기 때문에 간편한 인텔리제이를 사용해서 실습한다. 먼저 Spring boot를 기준으로 JAVA-Gradle-Groovy로 환경을 만들어준다. 이 후 아래와 같이 코들를 작성해주면 끝이다. 📙 src\main\ja...
14.📒 AWS(4)
📌 CLI AWS 서비스를 관리하는 통합 도구이다. pip install awscli pip3 install awscli 참고 CLI 설정 IAM에서 사용자 계정을 받은 후 설정을 해야한다. aws configure 입력 액세스 키 입력(복붙) 비밀 액세스 키 입력(복붙) region 입력 -> ap-northeast-NUM json -> Enter...
15.📒 AWS(5) - RedShift
📌 RedShift  - RedShift(2)
📌 사용자 그룹 권한 설정 ||analyticsauthors|analayicsusers|pii_users|admin| |:-:|:-:|:-:|:-:|:-:| |raw_data Tables|Read|Read|X|Read, Write| |analytics Tables|Read, Write|Read|X|Read, Write| |adhoc Tables|Read...
17.📒 Snowflake
📌 Snowflake 2014년 클라우드 기반 데이터웨어하우스로 시작 지금은 데이터 클라우드라고 부를 수 있을 정도로 발전 글로벌 클라우드위에 모두 동작 -> 멀티 클라우드 데이터 판매를 통한 매출을 가능하게 해주는 Data Sharing/Marketplace 제공 ETL과 다양한 데이터 통합 기능 제공 특징 스토리지와 컴퓨팅 인프라가...
18.📒 Docker
📌 Linux 설정 일단 Docker는 Linux를 기반으로 한다. 이말인 즉 Linux 또는 Mac을 기준으로 한다는 것이다. 이를 윈도우에서 사용하는 방법은 2가지이다. PowerShell에서 설정을하여 사용하는 방법 가상컴퓨터를 사용하는 방법 가상 컴퓨터롤 Linux는 자주 사용해 보았으니까 이번에는 Window 환경에서 진행해보자. 먼저 Pow...
19.📒 Superset
📌 Superset setting 먼저 리눅스에 폴더를 하나 만든 뒤 리눅스 터미널에서 해당 폴더로 접속한다. 폴더 생성 명령어 : mkdir 이후 아래 코드를 작성하여 superset을 git에서 받아온다. 이 후 Docker Desktop을 실행하여 아래 명령어를 추가로 터미널에 입력해준다. pull은 이미 알고있다싶이 당겨온다는 것이다. up의 ...
20.📒 ETL
📌 ETL(Data pipeline) ETL : Extract, Transform, Load Data Pipeline, ETL, Data Workflow, DAG ETL Called DAG(Directed Acyclic Graph) in Airflow 📕 ETL vs. ELT ETL : 데이터를 데이터 웨어하우스 외부에서 내부로 가져오는 프로...
21.📒 Docker(2)
📌 Docker가 필요한 이유 1. 라이브러리 충돌 라이브러리/모듈의 충돌 이슈 발생 DAG에 따라 실행에 필요한 라이브러리/모듈이 달라지기 시작했다. -> Python Version Issue -> 3.7, 3.8등등에서 사용가능한 라이브러리/모듈이 갈린다. 이로 인하여 DAG 혹은 Task별로 별도의 독립공간을 만들어주는 것이 필요하다. Docke...
22.📒 Docker(3)
📌 Docker 명령어 1. Image 이미지 빌드 docker build --platform=linux/amd64 -t urface0411/hangman 이미지 검색 docker images docker image ls 이미지 삭제 (Imageid or Imagename) docker rmi docker image rm 2. Doc...
23.📒 Docker(4)
📌 Docker 정리 1. Docker 관련 용어 Dcoekr Image -> 경량화 되어있고 간편하게 분리된 환경에서 사용가능하다는 장점을 가졌다. Dockerfile : SW의 세팅파일 Docker Container Docker Hub(hub.docker.com) Docker Compose 다수의 Docker Container들을 관리 do...
24.📒 Docker(5)
📌 Google Sheet 연동 먼저 구현의 절차를 알아보자. Sheet API 활성화 Google Service Account 생성 JSON 파일로 다운로드 Email을 Sheet에 공유 Airflow DAG에서 해당 JSON 파일로 인증하고 Sheet 조작 이렇게 구현을 진행 해보자. 📌 Google Service Account 생성 구글 클라우...
25.📒 Docker(6)
📌 Airflow API 활성화 API airflow.cfg의 api 섹션에서 auth_backend의 값을 변경 docker-compose.yaml에는 이미 설정이 되어 있음 (environments) AIRFLOWAPIAUTHBACKENDS: 'airflow.api.auth.backend.basicauth,airflow.api.auth.backend...
26.📒 End-to-End 데이터 파이프라인
📌 전체적인 방향 Small Data -> Big Data Panddas -> Spark Data Warehouse -> Data Lake ETL -> ELT 배치 처리 -> 실시간 처리(Kafka) 의사 결정 -> 제품/서비스 품질 개선 서비스별 전용 서버 -> K8s 등의 컨테이너 기술 사용 -> 모든 Service가 Docker로 ...
27.📒 Data Catalog
📌 데이터 카탈로그 데이터 자신 메타 정보 중앙 저장소 데이터 거버넌스의 첫 걸음 많은 회사에서 데이터 카탈로그를 데이터 거버넌스 툴로 사용하거나 데이터 카탈로그 위에 커스텀 기능을 구현한다. 데이터 카탈로그의 중요한 기능 (반)자동화된 메타 데이터 수집 데이터 보안, 보통 메타 데이터만 읽어온다. 📌 데이터 자산의 종류 테이블 (...
28.📒 Big-Data
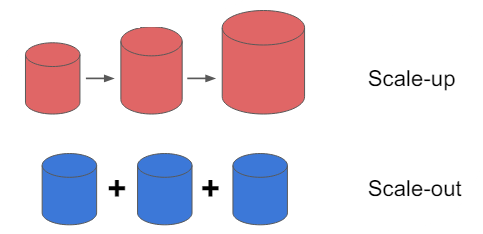
📌 빅데이터 정의 "서버 한대로 처리할 수 없는 규모의 데이터" Pandas -> Spark "기존의 SW로는 처리할 숭벗는 규모의 데이터" 대표적인 기존SW Oracle이나 MySQL과 같은 관계형 DB 분산환경을 염두에 두지 않는다. Scale-up 접근방식(vs. Scale-out) -> 메모리추가, CPU추가, 디스크 추가) 4V...
29.📒 Hadoop (1)

📌 Hadoop 상용 HW로 구축된 컴퓨터 클러스터에서 매우 거대한 데이터셋의 분산 스토리지와 분산 처리를 위한 오픈소스 SW 플랫폼이다. An open source software platform for distributed storage and distribu
30.📒 Hadoop (2)

📌 Hadoop Install 의사 분산 모드는 Hadoop 관련 프로세스들을 개별 JVM으로 실행한다. AWS Ubuntu EC2 t2.medium 인스턴스 추천 Java8이 필요하다. 1. 설치 있다면 버전 확인 없다면 설치한다. 안내해준 명령어를 복붙하면 그만이다. -> 여기서는 java8 사용 만약 아래 오류가 발생한다면 apt 버전 오류...
31.📒 SQL - 문제풀이 Day1
📙 데이터 그룹으로 묶기 Table에서 data1과 data2의 평균과 표준편차를 구하는 문제이다. -> 결과값은 3자리에서 반올림. 📙 복수 국적 메달 수상한 선수 찾기 2000년도 이상의 수상기록 2개 이상의 국적으로 수상한 선수 주의 -> 선수의 이름으로 GROUP BY를 하면 이름이 겹치는 경우를 무시하는것임 -> GROUP BY는 Uni...
32.📒 빅데이터 처리
📌 데이터 처리 데이터 처리의 일반적인 단계 데이터 수집 (Data Collection) 데이터 저장 (Data Storage) 데이터 처리(Data Processing) -> 이 과정에서 서비스 효율을 높이거나 의사결정을 더 과학적으로 하게 된다. 데이터 처리의 고도화 처음에는 배치로 시작 -> 이 경우 처리할 수 있는 데이터의 양이 중요하다. 서비...
33.📒 SQL - 문제풀이 Day2
📙 쇼핑몰의 일일 매출액과 ARPPU dt - 매출 날짜 (예: 2018-01-01) pu - 결제 고객 수 revenue_daily - 해당 날짜의 매출액 arppu - 결제 고객 1인 당 평균 결제 금액 주의할 점은 주문 고객이 해당 날짜에 중복될 수 있다는 점이다. -> DISTINCT 사용해야함 📙 멘토링 짝꿍 리스트 mentee : ‘202...