데이터의 압축
- 데이터 압축 : 파일 정보를 더 작은 공간에 저장되도록 인코딩
for 저장공간의 절약, 전송시간의 단축
✅ 방법 1 : 다른 표기법의 사용( ex) Los Angeles -> LA )
ex) 미국의 50개주 : 16비트 -> 6비트로 50개 주 표현가능
50개의 주를 2진수로 나타냄 => 2^6 = 64 (6bit)
-
장점 :
인코딩이나 디코딩 알고리즘이 매우 단순하다. -
문제점 :
- 인코딩 부분을 사람이 읽을 수 없다.
- 인코딩, 디코딩을 위한 시간소비
- 주소파일을 처리하는 모든 S/W가 인코딩, 디코딩 모듈 포함
✅ 방법 2 : 반복되는 열의 삭제 : 진행-길이 인코딩(Run-Length Encoding)
- triple 로 표현 <ff, value, count>
ex) 22 23 24 24 24 24 24 24 24 25 26 26 26 26 26 26 25 24
▶ 압축 ▶
22 23 ff 24 07 25 ff 26 06 25 24
- 희소 행렬, 기기 데이터, 텍스트를 포함하는 많은종류의 데이터에 적용
- 특정한 양의 공간 절약을 보장하지 않음(원래 데이터보다 더 커질 수도 있음)
❗❗❗ ✅ 방법 3 : 가변 길이 코드의 대입 (Huffman code)
- 파일 내에서의 출현 빈도가 문자마다 다르다는 사실에 착안
- 데이터 집합에 나타나는 값의 확률을 결정
- 각 값에 대한 탐색 경로가 그 값에 대한 코드를 이진트리로 구성
- 빈도가 높은 문자에 적은 자리수의 코드 부여

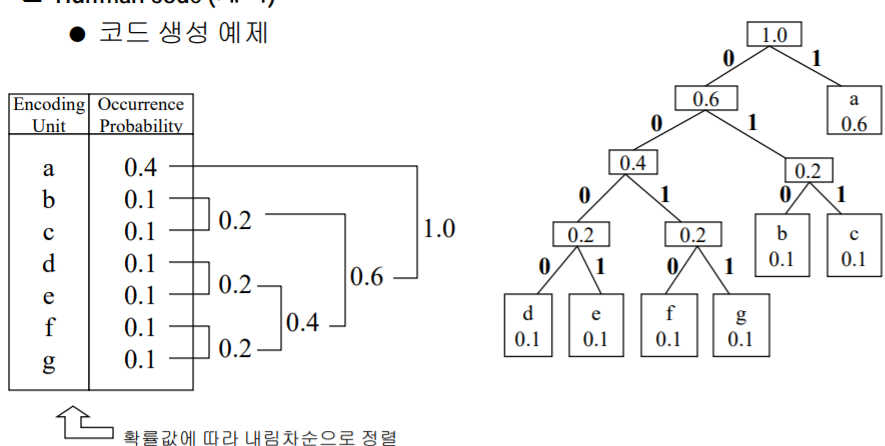
a : 1
b : 010
c : 011
d : 0000
e : 0001
f : 0010
g : 0011
