개요
현재 부스트캠프 그룹 프로젝트로 상품의 가격을 추적하는 앱을 개발하고 있습니다. 각 상품에 대한 가격 변동 그래프 데이터를 자주 조회하기 때문에 쿼리의 성능을 최적화 할 필요가 있었습니다. 따라서 MongoDB에서 쿼리 성능을 분석할 수 있는 방법에 대해 학습하고 이를 적용해봤습니다.

EXPLAIN이란?
EXPLAIN은 특정 쿼리가 데이터베이스에서 어떻게 실행되는 지 보여줍니다. 따라서 쿼리의 성능을 분석하고 최적화하는 데 도움이 됩니다. 이를 통해 쿼리의 성능을 분석해보겠습니다.
현재 MongoDB Collection에 저장되어 있는 Document들의 형식은 아래와 같습니다.
{
_id: ObjectId('656748901c18f5ce561c814c'),
productId: 'f1b0ad91-9b64-41a8-ae61-9ef8e1df18d1',
price: 172910,
isSoldOut: false,
__v: 0,
time: ISODate('2023-11-29T14:20:00.367Z')
},
{
_id: ObjectId('656827381c18f5ce561c81bb'),
productId: 'f1b0ad91-9b64-41a8-ae61-9ef8e1df18d1',
price: 168640,
isSoldOut: false,
__v: 0,
time: ISODate('2023-11-30T06:10:00.242Z')
},
{
_id: ObjectId('656913f0f26e9b9bb4358b6e'),
productId: 'f1b0ad91-9b64-41a8-ae61-9ef8e1df18d1',
price: 168600,
isSoldOut: false,
__v: 0,
time: ISODate('2023-11-30T23:00:00.643Z')
},
(생략)time(시간대), price(가격), isSoldOut(품절 여부), 그리고 각 상품에 대한 ID인 productId가 존재합니다.
인덱스를 사용하지 않았을 때
db.productprices.find({
productId: "f1b0ad91-9b64-41a8-ae61-9ef8e1df18d1",
time: {
$gte: new Date("2023-12-01"),
$lte: new Date("2023-12-09")
},
})
.hint({$natural: 1})
.explain("executionStats");결과
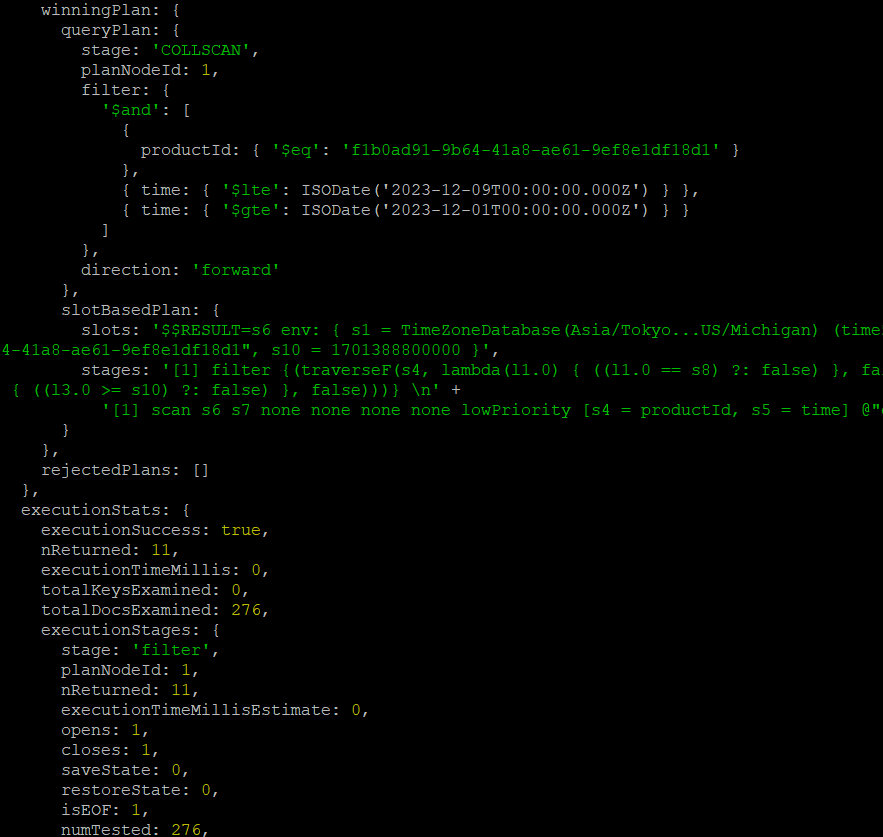
인덱스를 사용하지 않았을 때는, query를 실행했을 때 'COLLSCAN' 방식을 사용하여 진행하고 있는 것을 알 수 있습니다. 또한 executionStats에 있는 nReturned와 totalDocsExamined를 보면 총 11개의 문서를 얻기 위해 276개의 문서를 확인했다는 것을 알 수 있습니다.
단일 인덱스를 사용했을 때
db.productprices.find({
productId: "f1b0ad91-9b64-41a8-ae61-9ef8e1df18d1",
time: {
$gte: new Date("2023-12-01"),
$lte: new Date("2023-12-09")
},
})
.hint({productId: 1})
.explain("executionStats");결과
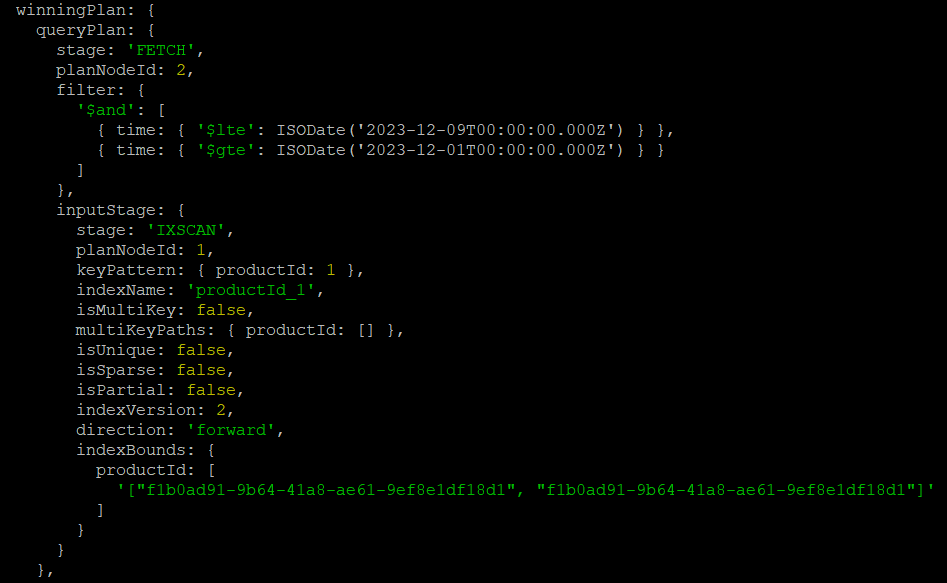
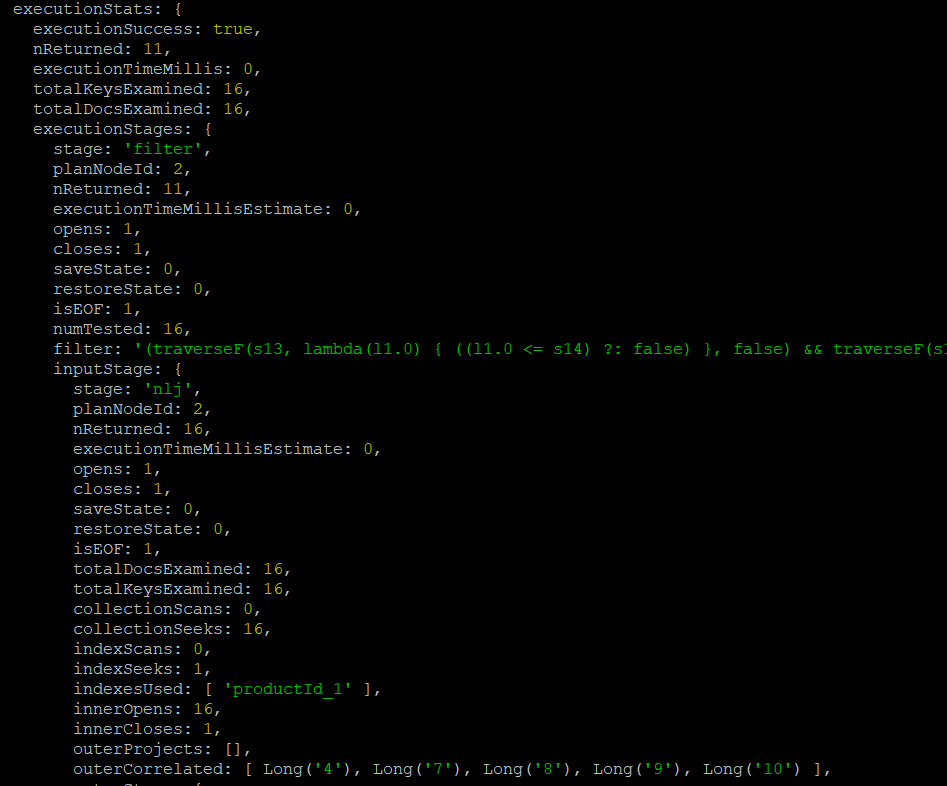
productId로 단일 인덱스를 생성하여 적용해봤습니다. 인덱스를 사용하지 않았을 때랑은 다르게 query를 실행했을 때 'IXSCAN' 방식을 사용하여 진행하고 있는 것을 알 수 있습니다. executionStats에 있는 nReturned는 총 11개로 동일합니다. 하지만 totalDocsExamined가 16개이며, 아까 전의 결과에 비해 문서를 확인한 횟수가 현저히 줄어든 것을 확인할 수 있었습니다.
복합 인덱스를 사용했을 때
db.productprices.find({
productId: "f1b0ad91-9b64-41a8-ae61-9ef8e1df18d1",
time: {
$gte: new Date("2023-12-01"),
$lte: new Date("2023-12-09")
},
})
.hint({productId: 1, time: 1})
.explain("executionStats");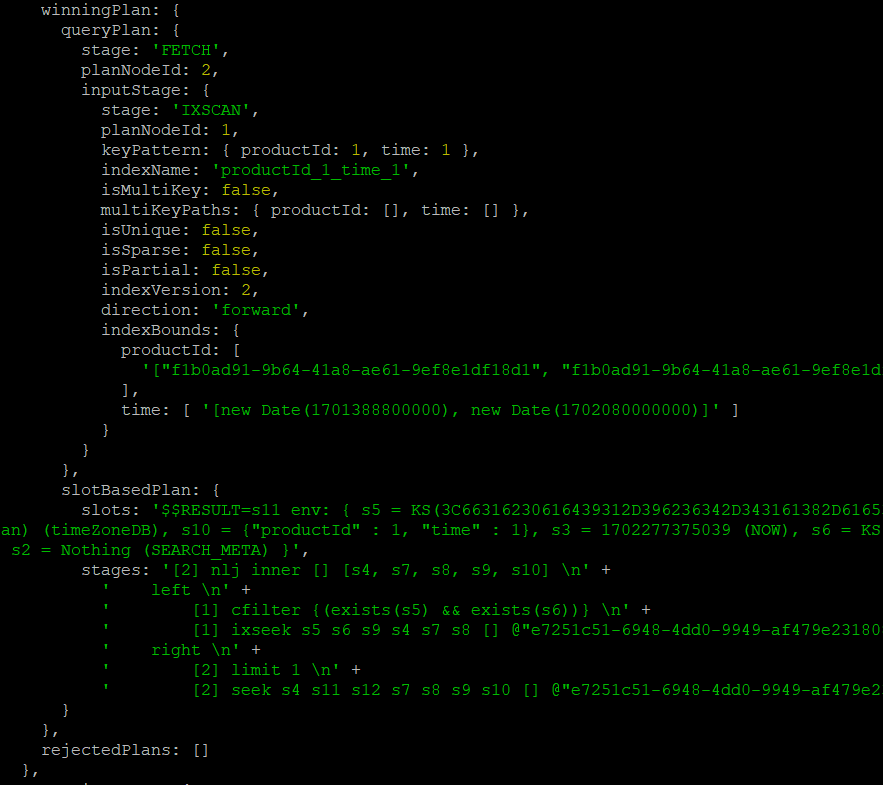
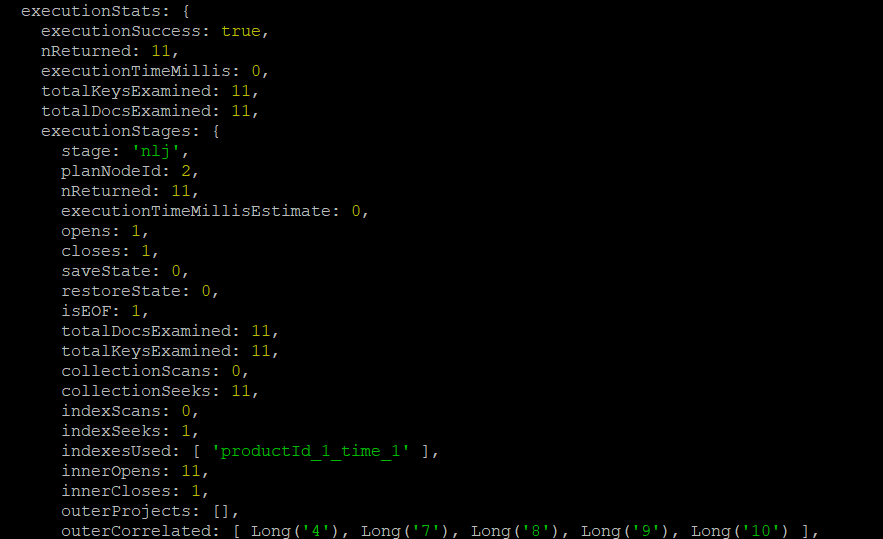
이번에는 (productId, time) 으로 복합 인덱스를 생성해서 적용했습니다. explain 결과는 인덱스를 사용했을 때와 비슷하지만 totalDocsExamined 값이 11개로 줄어든 것을 확인할 수 있었습니다.
최종적으로 복합 인덱스를 사용했을 때, 성능이 가장 좋을 것 같다고 판단 하였습니다. 하지만 실제 서비스 상에서 인덱스를 적용했을 때 성능 차이가 얼마나 있을 지 궁금했습니다. 따라서 부하 테스트를 통해 상품 조회 API를 여러번 호출해서 성능에 차이가 있는지 측정했습니다.
Artillery란?
Node.js로 작성된 부하 테스트 도구입니다. 사용 방법이 간단하고, 가볍다는 장점이 있습니다. API를 여러 번 호출할 때, Index 유무에 따라서 응답 시간이 얼마나 차이가 나는 지 측정했습니다.
설치 및 확인
npm install -g artillery@latest
npx artillery dino테스트 설정
artillery.yaml
config:
target: [API 서버 주소]
phases:
- duration: 60
arrivalRate: 1
rampTo: 5
name: One ~ People
- duration: 60
arrivalRate: 5
rampTo: 10
name: Five ~ People
- duration: 30
arrivalRate: 10
rampTo: 20
name: Ten ~ People
defaults:
headers:
User-Agent: Artillery
Authorization: Bearer [JWT 토큰]
scenarios:
- flow:
- get:
url: "/product/recommend"
- get:
url: "/product/tracking"위와 같이 테스트 설정을 한 뒤, 부하 테스트를 했습니다.
target: 테스트 할 서버 주소
phases: 가상 사용자 생성 정의
duration: 테스트 할 시간 (초)
arrivalRate: 초당 요청 횟수
rampTo: arrivalRate를 duration 동안 rampTo 값으로 증가
ex)
phases:
- duration: 100
arrivalRate: 1
rampTo: 50
(아래와 동일한 의미)
phases:
- arrivalRate: 1
duration: 2
- arrivalRate: 2
duration: 2
- arrivalRate: 3
duration: 2
-
# ... etc ...
- arrivalRate: 50
duration: 2scenarios: 하나 이상의 테스트를 포함하기 위해 사용
flow: 가상 유저가 어떤 행동을 수행할 지 설정
위 파일에서는 가상 유저가 /product/recommend와 /product/tracking으로 GET 요청을 보냅니다.
테스트 시작
테스트 결과를 json으로 저장
artillery run artillery.yaml -o ./test.json json 파일을 그래프로 변경
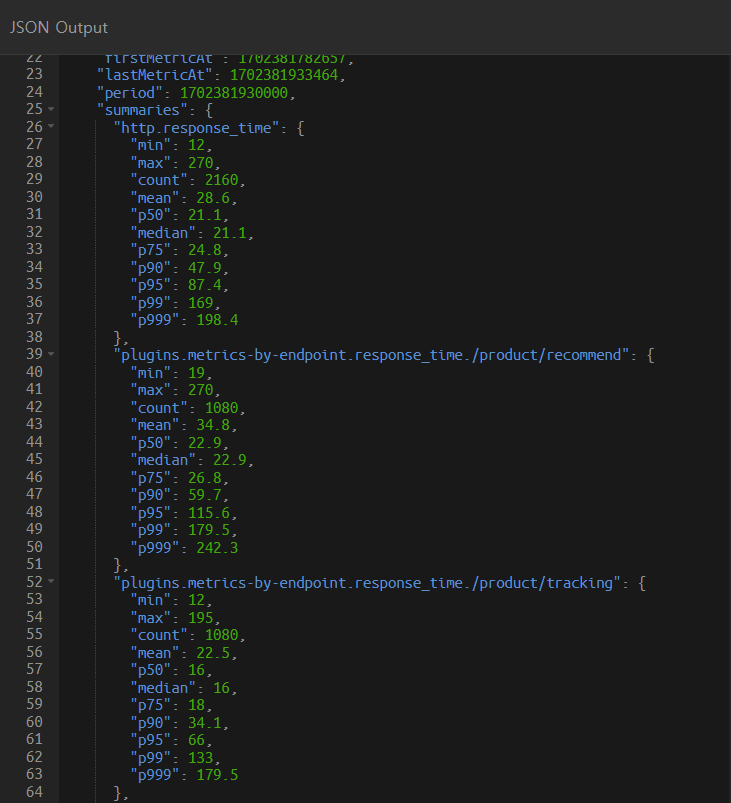
artillery report test.json인덱스를 사용하지 않았을 때
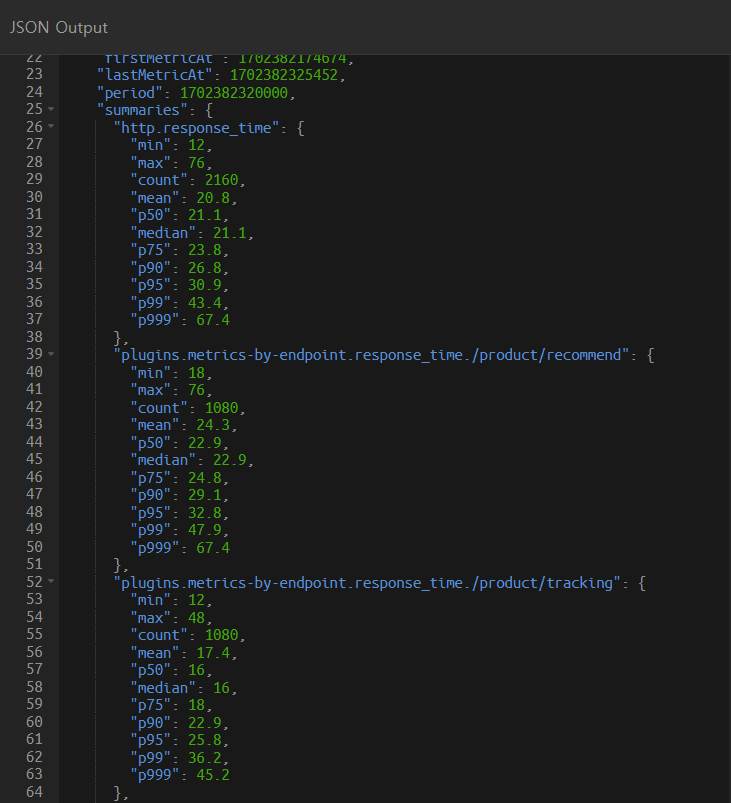
복합 인덱스를 사용했을 때
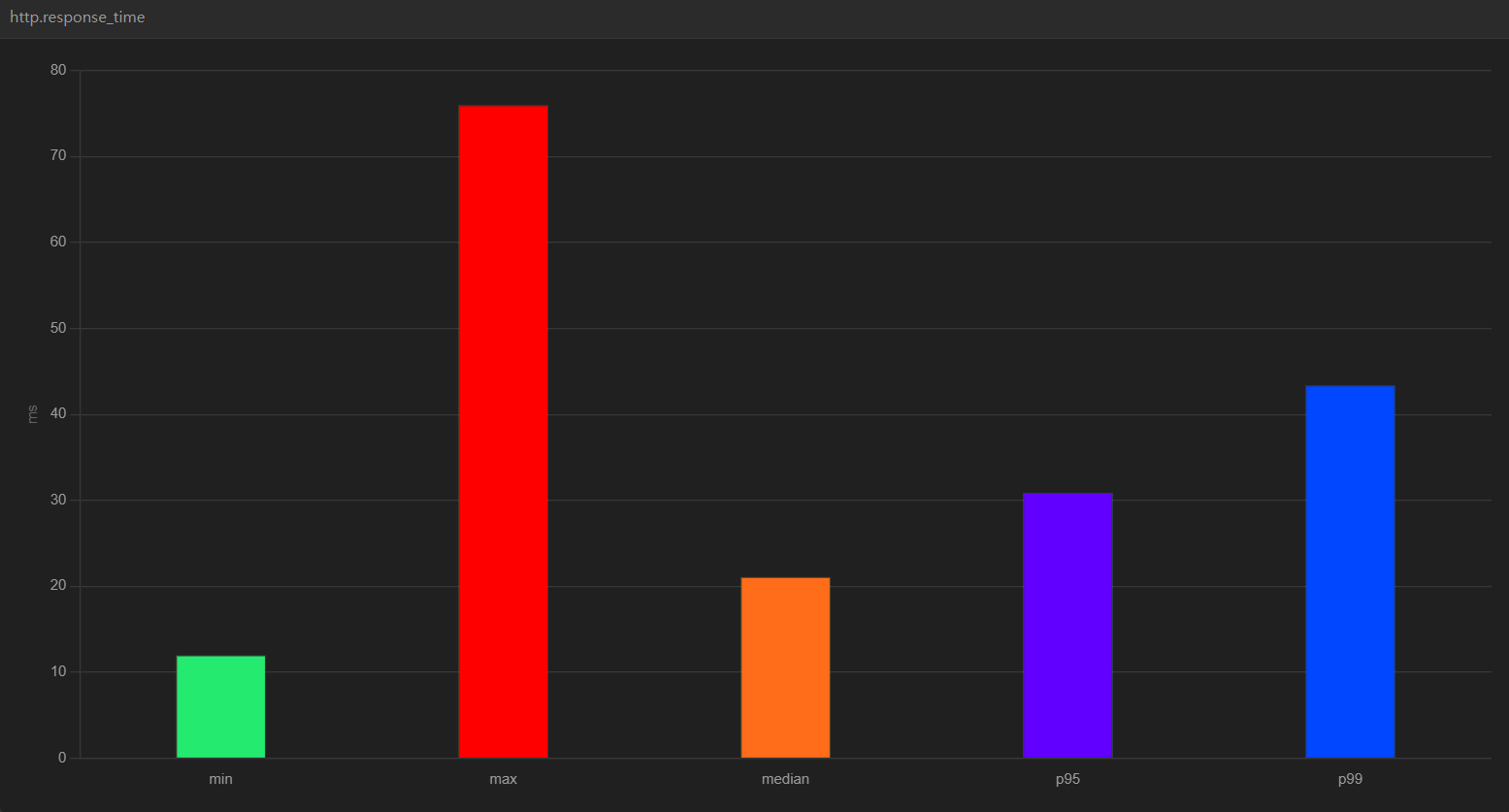
실제로 artillery로 위와 동일한 테스트 설정으로 인덱스를 적용했을 때와, 적용하지 않았을 때 response time이 얼마나 차이가 날 지 테스트했습니다.
결과에서 중요하게 봐야하는 지표는 median, p95, p99입니다.
median: 중앙값
p95: 가상 사용자의 95%에 대한 시간
p99: 가상 사용자의 99%에 대한 시간
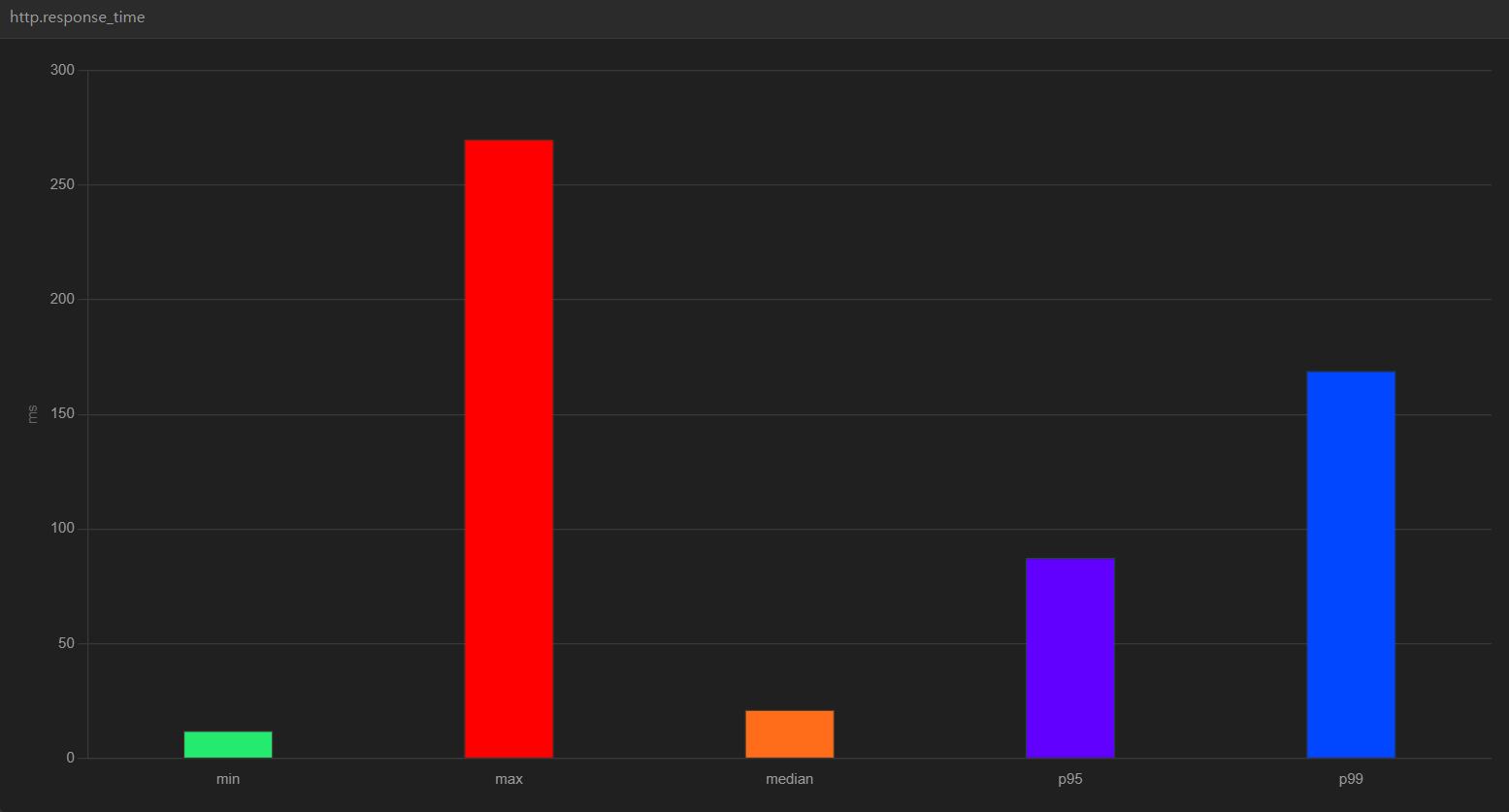
인덱스를 사용하지 않을 시,
median 값은 21.1, p95 값은 87.4, p99 값은 169가 나옵니다.
복합 인덱스 사용 시,
median 값은 21.1, p95 값은 30.9, p99 값은 43.4가 나옵니다.
복합 인덱스 사용 시, p95와 p99 값이 많이 감소한 것을 확인했습니다. 따라서 인덱스 적용 시 서버의 성능이 많이 향상된 것을 직접 테스트할 수 있었습니다.
참고 자료
