File system Implementation
파일접근 방법

순차접근과 직접접근
a,b,c라는 내용이 있다면
순차접근은 a, b, c 순서데로 접근을 해야한다.
직접접근은 c로 a로 직접 접근이 가능하다.
다시말해, 파일에 접근하는 방법에는 순차접근과 직접접근이 있다.
순차접근은 파일이 저장된 시작위치부터 시작해서 차례차례 따라가면서 해당 위치에 해당하는 데이터를 읽는 방법이고, 직접접근은 특정 위치를 바로 찾아서 데이터를 읽는 방법이다.
파일저장 방법 3가지

디스크에다가 파일을 저장하는 방법은 크게 3가지가 있다.
모든 파일은 같지 않다. 그러다보니다 파일의 크기는 균일하지 않다.
균일하지 않는 파일의 일정한 크기로 나누게 된다.
디스크에 파일을 저장할 때는 동일한 크기의 섹터를 둔다. 동일크기의 블록단위로 나누어서 저장한다.
- 연속할당
- 링크할당
- 인덱스할당
연속할당
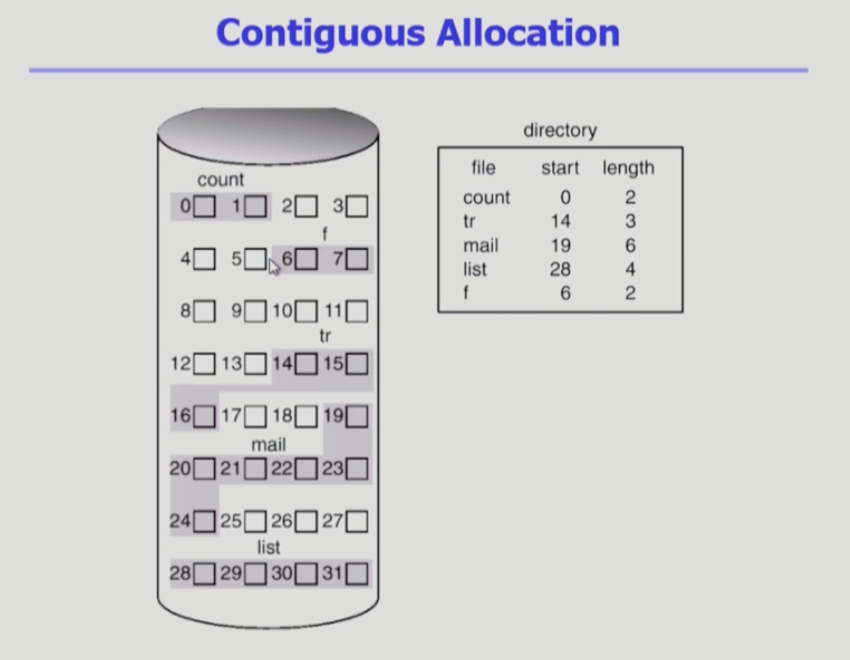
하나의 파일이 블록으로 쪼개진뒤 디스크에 연속적으로 저장된다.

연속적으로 저장하는 방법의 단점은 외부조각이 발생한다는 점이다.
또한 한번 저장된 파일은 변경될 수 있다. 그러면 파일의 크기가 바뀔 수 있는데, 연속적 할당을 하게 되면 크기 변환에 제약이 생길 수 있다.
이를 해결하기 위해서 뒤에 미리 빈 공간을 확보해 두는 방법을 생각할 수 있지만, 디스크의 낭비(내부조각)가 발생할 수 있다. 그리고 확보해둔 공간만큼만 크기가 커질 수 있다.
연속할당방법은 파일의 크기가 균일하지 않기 때문에 중간중간에 hole이 생긴다.
단, 빠른 I/O가 가능하다는 장점이 있다.
I/O시 대부분의 접근시간이 head가 이동하는 시간이다.
연속할당을 한 경우 파일을 통쨰로 읽고 싶다면, 한번의 이동(탐색)으로 연속적으로 파일을 읽으면 되기 때문에 빠른 시간에 많은 것을 읽어 올 수 있다.
파일시스템 용도이외에 프로세스의 swap area 용으로 사용시 좋다.
swap은 공간이용률보다는 속도 측면이 중요하기 때문에 연속할당이 좋다.
직접접근이 가능하다는 장점이 있다. 해당 위치를 접근하고서 그 이후로 쭉 읽어 들이거나 그 앞을 읽어 들여도 해당 파일에 대한 데이터이므로 직접접근이 가능하다. 중간부터 시작해도 쭉 읽을 수 있기 때문에 직접접근이 가능하다.
링크할당
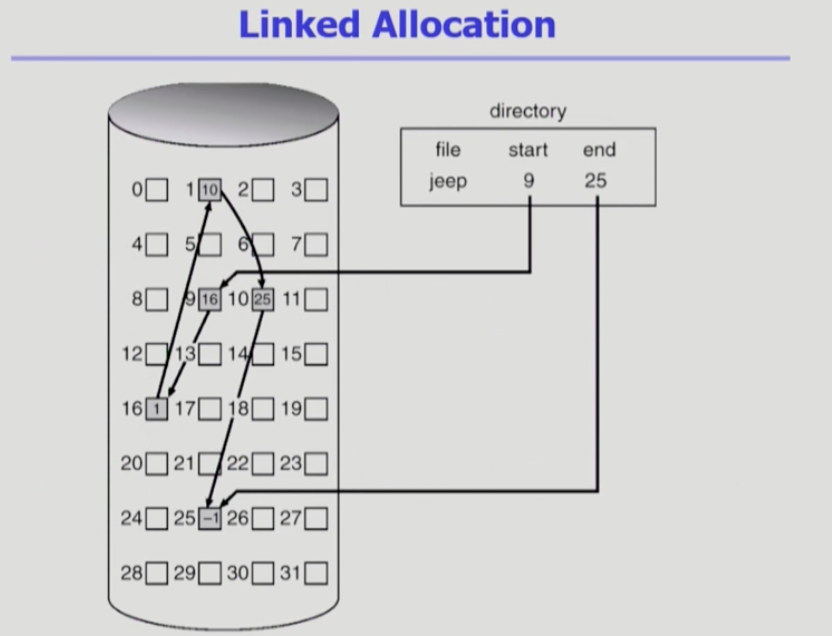
빈위치가 있다면 어디든 할당 될 수 있게 하는 것이다.
파일의 시작위치를 가지고 있고, 다음 위치를 표시하고 있다.

외부조각이 발생하지 않는 장점이 있다.
그러나, 직접접근이 가능하지 않다.
앞에서 부터 4번째 블록에 해당하는 데이터를 볼려고 하면, 앞에서부터 순차적으로 확인을 해서 보아야한다. 앞에서 부터 탐색을 해야지만 볼수 있다.
디스크 자체는 직접접근이 가능한 매체이지만, 파일시스템을 관리하는 방법이
linked allocation이라면, 직접접근이 불가능해진다.
위치가 떨어져 있다면, 디스크의 head가 이동을 해야 한다. 그렇기 때문에 순차접근을 위한 head의 이동시간이 오래걸린다는 단점이 있다.
한 sector가 고장나면 뒤에 부분을 모두 잃을 수 있다는 단점이 있다.
pointer를 위한 저장공간이 필요해서 효율성이 떨어진다.
인덱스 할당
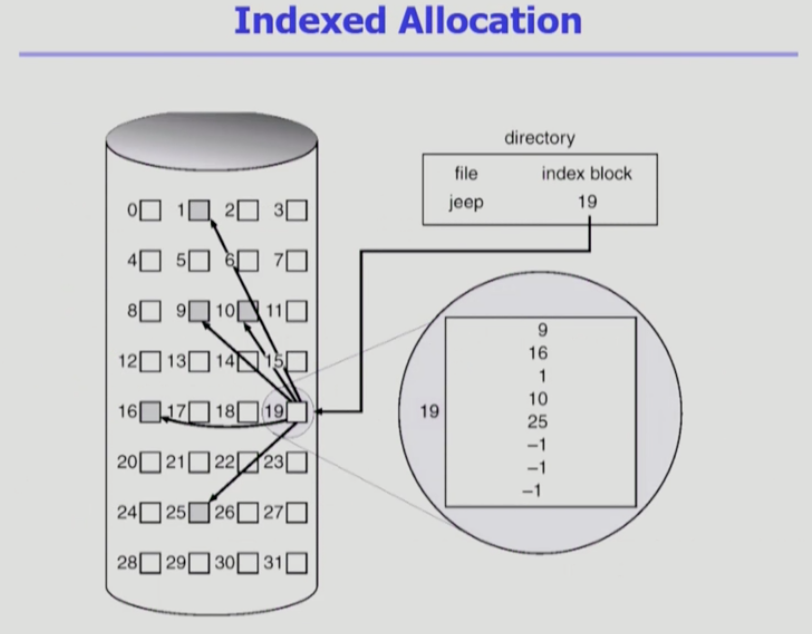
직접접근이 가능하기 위해서 디렉토리에 파일의 위치정보를 바로 저장하는 것이 아니라, 인덱스를 저장하게 한다.
인덱스블록은 파일의 위치가 어디어디어디에 있는지 저장해둔 인덱스 블록으로 직접접근이 가능하게 한다.
인덱스블록을 보고서 몇번째에 있는지 확인 후 접근하게 한다.

외부조각이 생기지 않으면서 직접접근이 가능하다.
아무리 작은 파일이라고 해도 블록이 2개가 필요하다. 인덱스를 위한 블록과 실제 데이터를 저장하기 위한 블록이다.
작은 파일을 위해서 블록이 2개 필요하기 때문에 공간 낭비가 발생할 수 있다.
큰 파일의 경우는 하나의 블록으로 인덱스를 모두 표현할 수 없다.
파일을 디스크에 저장하는 기본적인 방법 3가지 연속할당, 링크할당, 인덱스 할당이다
실제파일시스템
UNIX 파일시스템
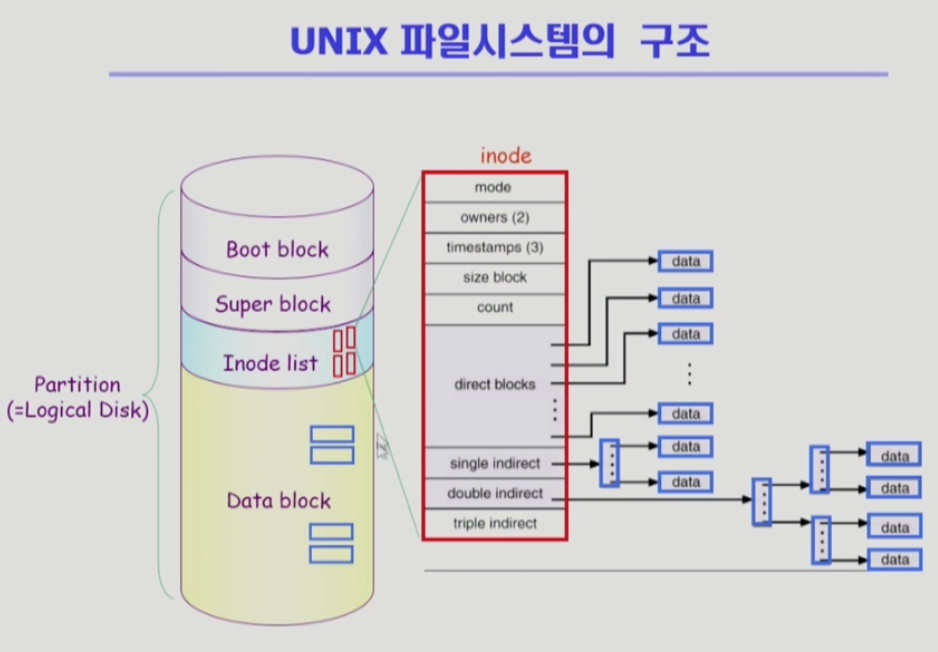
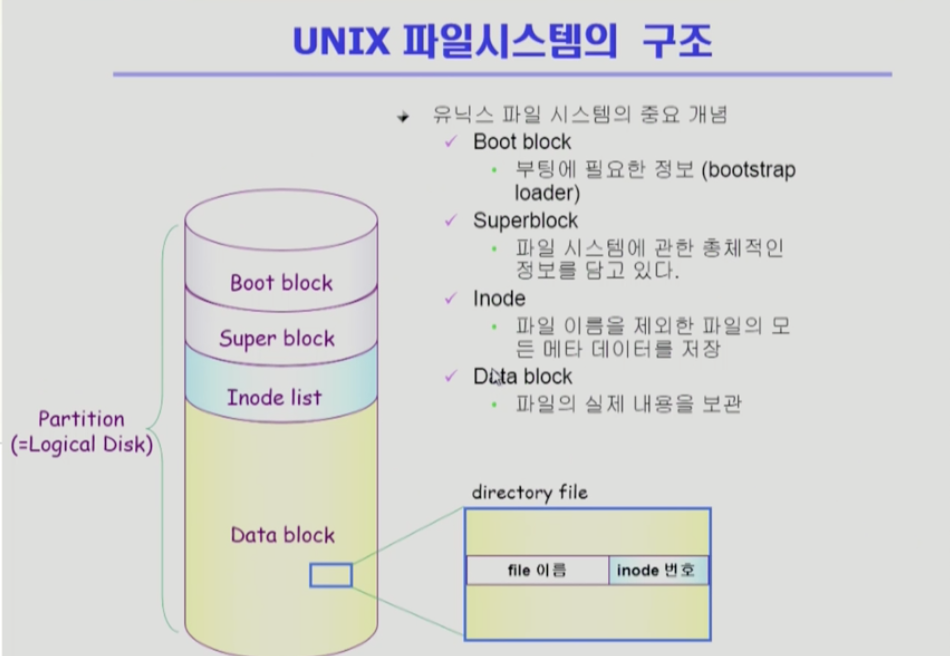
boot block은 어떤 파일시스템이든 boot block이 먼저 나온다.
부팅에 필요한 정보를 가진다. 운영체제의 커널의 위치가 어딘지 찾아서 제대로 부팅되게 한다.
super block은 파일시스템에 대한 총체적인 정보를 담고 있다. 어디가 빈블록이고, 어디가 사용중인 블록인지 등의 정보를 가진다.
실제 파일시스템에서는 디렉토리가 파일의 모든 meta데이터를 가지고 있지 않고, inode list에 가지고 있다.
파일 하나당 inode가 하나 할당된다. inode는 파일의 메타데이터를 가지고 있는 구조이다.
유닉시 파일시스템은 boot block, super block, inode list data block으로 나뉘고, 파일의 메타데이터를 inode list에 저장한다. 파일의 크기가 크면은 direct노드를 통해서 접근한다.
FAT 파일시스템
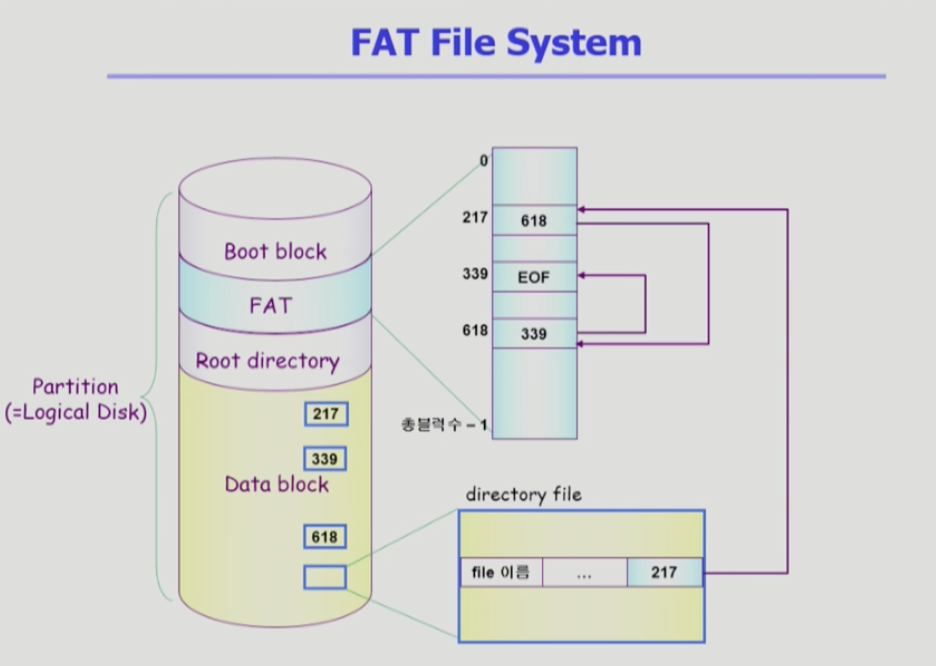
bootblock, fat, root directory, datablock
파일의 메타데이터 중 일부를 fat에 보관한다. 지극히 제한적인 위치정보를 fat에 저장한다. 나머지 정보는 디렉토리가 가지고 있다.
파일의 이름을 포함한 접근권한등을 모두 디렉토리가 가지고 있다.
데이터 블록에 n개의 파일이 있으면 배열은 n개 만큼 있다. 배열에는 다음 위치를 가키는 블록을 가지고 있다.
217번 다음에 618번이 있다. fat에는 다음 위치가 저장되어 있다.
실제블록을 접근해야 하는 것이 아니라 fat을 알면 된다. 직접접근이 가능하다.
빈 데이터 관리
bit map or bit vector


linked list 비어있는 블럭들을 연결해둔다.
grouping 연속적인 빈 블록을 찾기에는 효과적이지 않다.
빈블록을 관리하는 방법에 대해서 알아 보았다.
디렉토리 구현

디렉토리는 파일의 메타데이터를 가지고 있다. 메타데이터를 어떻게 저장할 것인가.
linear list
순차적저장방법 크기를 고정시킨다. 구현은 간단하나 비효율적이다.
hash table
file의 이름을 hash함수를 적용해서 엔트리에다가 결과값을 저장한다.
순차적으로의 탐색이 아니라 해시함수를 적용해서 해시함수에 결과값에 해당하는 엔트리를 찾아보면된다. 해시를 사용하면 collision이 발생한다.

VFS and NFS

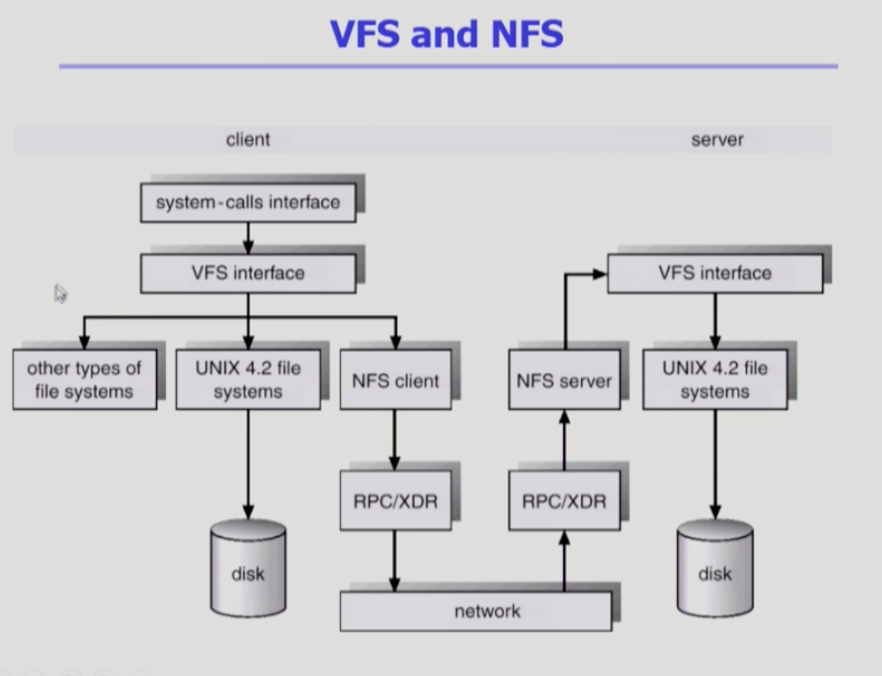
vfs는 가상파일시스템
사용자가 파일시스템에 접근할 때는 개별 파일시스템에 접근하는 것이 아닌 동일한 가상파일시스템에 접근하는 것이 가능하게 한다.
nfs는 파일시스템이 원격에 저장된 것에 접근할 수 있는데, 이때 nfs를 이용해서 접근한다.
client가 server가 network로 연결되어있다
로컬의 파일시스템에 접근이 가능하고, 원격에 존재하는 파일시스템에 접근이 가능하기도 하다. 이때 사용하는 것이 nfs이다.
분산시스템에서 네트워크를 통해서 파일시스템에 접근하게 할 수 있는 것이 nfs이다.
Page Cache & Buffer Cache

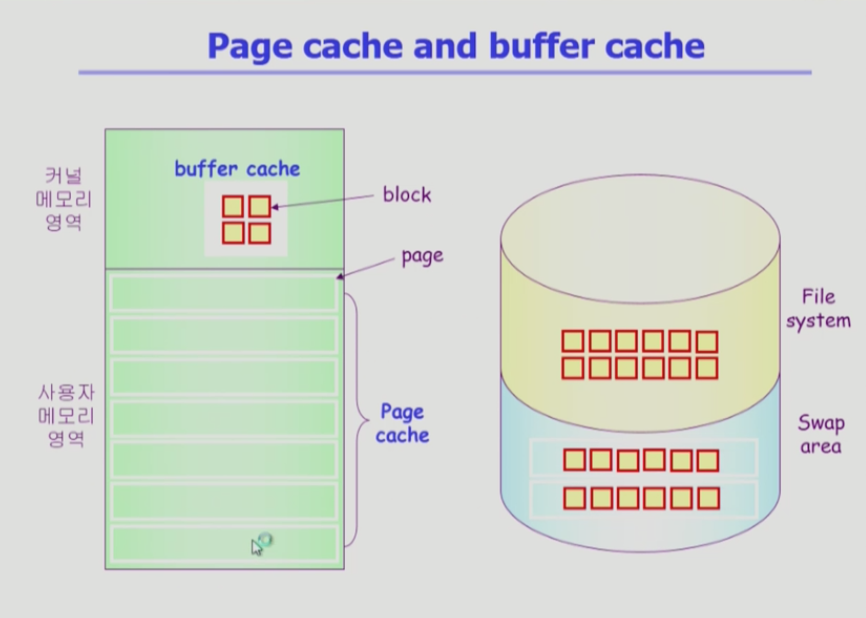
페이지캐시
앞서 메모리 관리시 페이지프레임을 두고 페이지프레임에다가 필요한것을 두고, 아닌 거를 쫒아냈다. 이를 캐시의 관점에서 페이지캐시라고 부른다.
버퍼캐시
버퍼캐시는 파일입출력시 디스크에 있는 파일시스템에서 운영체제가 파일을 읽어서 메모리영역에 읽어 두고서 사용자프로그램에게 카피해서 전해준다. 사용자프로그램의 요청을 받아서 읽어 들인 후 사용자프로그램에게 카피해서 넘겨주기 때문에 동일한 요청이 오면 디스크에서 읽어오는 것이 아니라 버퍼캐시에서 전해준다.
페이지캐시는
- 프로그램의 주소공간을 구성하는 페이지가 swap area에 내려가 있는가?
- 또는 페이지캐시에 올라와 있는가? 를 판단한다.
- 페이지캐시의 단위는 페이지가 된다.
버퍼캐시는
- 파일데이터가 파일시스템 storage에 저장되어 있는가?
- 운영체제의 버퍼캐시에 올라가 있는가? 를 판단한다.
- 버퍼캐시의 단위는 섹터 단위가 된다.
unified buffer cache
최근에는 버퍼캐시가 페이지캐시와 통합이되서 버퍼캐시에서 사용하는 단위도, 페이지단위를 쓴다.
별도의 구분을 하지 않고, 똑같이 페이지 단위로 관리를 하면서, 파일입출력이 필요하면 버퍼캐시용도로 사용하고, 주소공간으로서 필요하면 페이지단위로 쓴다.
memory mapped io
파일의 내용을 시스템콜을 해서 운영체제한테 요청을 해서 운영체제 메모리에 저장해두고 카피해서 전해주는 것이 아니라 프로세스의 주소공간의 일부를 파일에 맵핑해두고서, 메모리 접근하는 식으로 파일처리를 할 수 있는 것이다.
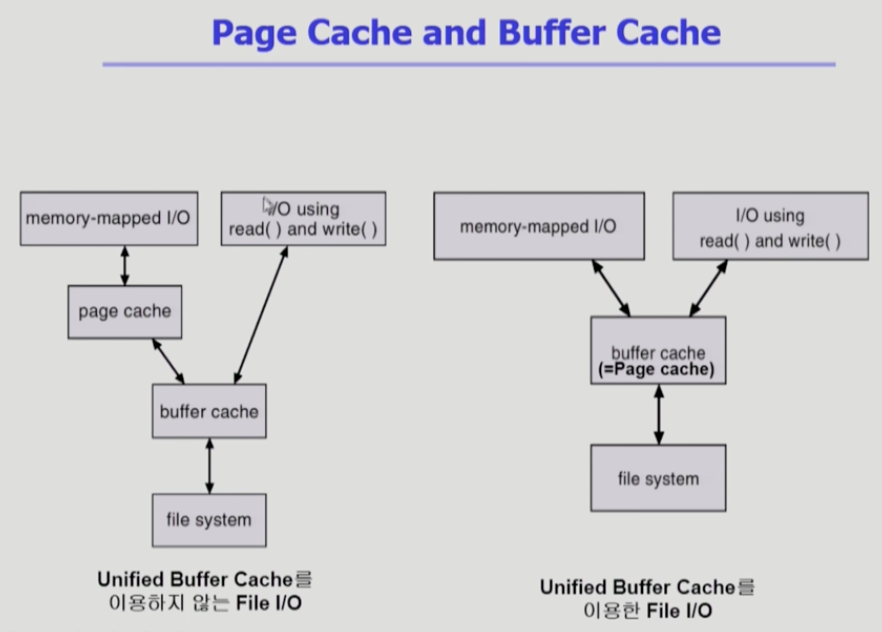
Unified Buffer Cache를 이용하지 않는 경우
- I/O using read() and write(오른쪽)
파일을 open하고 read/write는 시스템 콜을 하는 것이다.
운영체제가 해당하는 파일의 내용이 버퍼캐시에 있는지 확인 후 없으면 디스크에서 읽어서 전해준다. 사용자 프로그램은 자신의 페이지에다가 버퍼캐시에 있는 내용을 카피해서 사용한다.
- memory-mapped I/O(왼쪽)
시스템콜을 한다. 자신의 주소공간 중 일부를 파일에 맵핑을 한다.
맵핑을 해도 디스크에서 읽어오는 것을 같다. 읽어서 버퍼캐시에 읽어온다.
그 내용을 페이지캐시에 카피를 해서 준다.
사용자프로세스가 메모리 영역에 접근하는 식으로 I/O를 할 수 있게 된다.
이미 메모리에 올라온 내용은 커널의 도움없이 자신이 직접 자신의 메모리에 접근하는 식으로 처리할 수 있다.
I/O using, memory-mapped I/O 중 어떤 것을 쓰던 간에 파일 입출력을 위해서는 버퍼캐시를 사용해야 한다.
Unified Buffer Cache를 이용하는 경우
-
I/O using read() and write(오른쪽)
시스템콜을 운영체제에 한다. 메모리에 올라왔있으면 그대로 주고, 아니면 디스크에서 읽어서 준다. -
memory-mapped I/O(왼쪽)
주소영역에 페이지캐시가 맵핑이 된다.
페이지 캐시 자체가 사용자프로세스의 논리적 주소에 맵핑되므로 페이지캐시에 읽고 쓰고 할 수 있다. 버퍼캐시가 별도로 존재하지 않는다.
