DataBase5 - Relational Database Modeling
Relational Database
데이터모델링이란 무었일까?
모델링이란 현실에 존재하는 것을 목적에 부합하게 모방하는 것을 의미하며, 우리가 하려는 데이터모델링은 관계형데이터베이스에서 사용되는 테이블을 만들기 위해서 테이블에 필요한 요소들을 파악해 구조를 만드는 것이다.
데이터모델링을 과정
- 업무파악 & 기획
- 개념적 데이터모델링
- 논리적 데이터모델링
- 물리적 데이터모델링
앞서 업무파악&기획의 단계에선 클라이언트와 개발자간의 대화를 통해서 서로의 생각을 맞추는 작업을 하고 기획서라는 산출물을 만들었다.
다음 개념적 데이터모델링을 통해 기획서 내의 개념들을 찾아내서
Entity, Attribute, Relation에 대해서 정리하였다.
다음 단계는 논리적 데이터모델링과 물리적 데이터모델링이다.
논리적 데이터모델링
개념적 데이터모델링에서 뽑아낸 개념을 관계형데이터모델의 패러다임에 맞게 구현하는 것을 의미한다.
Mapping Rule
개념적 데이터모델링에서 나온 E-R 다이아그램을 관계형데이터모델에 맞게 바꾸기
Entity ==> Table
Attribute ==> Column
Relation ==> PK, FK
테이블과 컴럼 생성
- Entity ==> Table
- Attribute ==> Column
1:1 관계 설정
1:1관계에서는 어떤테이블이 어떤테이블에 의존하는 가를 고려해보자.
혼자서도 사용가능한 테이블이면 부모테이블
그렇지 않으면 자식테이블로서 1:1 관계를 만들어 주고, 외래키를 설정해 준다.
기본키는 부모테이블에 외래키는 자식테이블에 설정한다.
1:N 관계 설정
1:N관계에서는 관계 설정이 어렵지 않다.
기본키는 1에 해당하는 테이블에
외래키는 N에 해당하는 테이블에 설정한다.
N:M 관계 설정
맵핑테이블이 필요하다.

N:M의 관계는 맵핑테이블로 중간에서 중재자 역할을 하는 테이블이 필요하다.
맵핑테이블에 관계를 연결해서 기본키와 맵핑키를의 관계를 설정해준다.
정규화 Normalization
정제되지 않는 테이블을 관계형 데이터베이스의 테이블에 맞게 바꾸는 것을 의미한다.
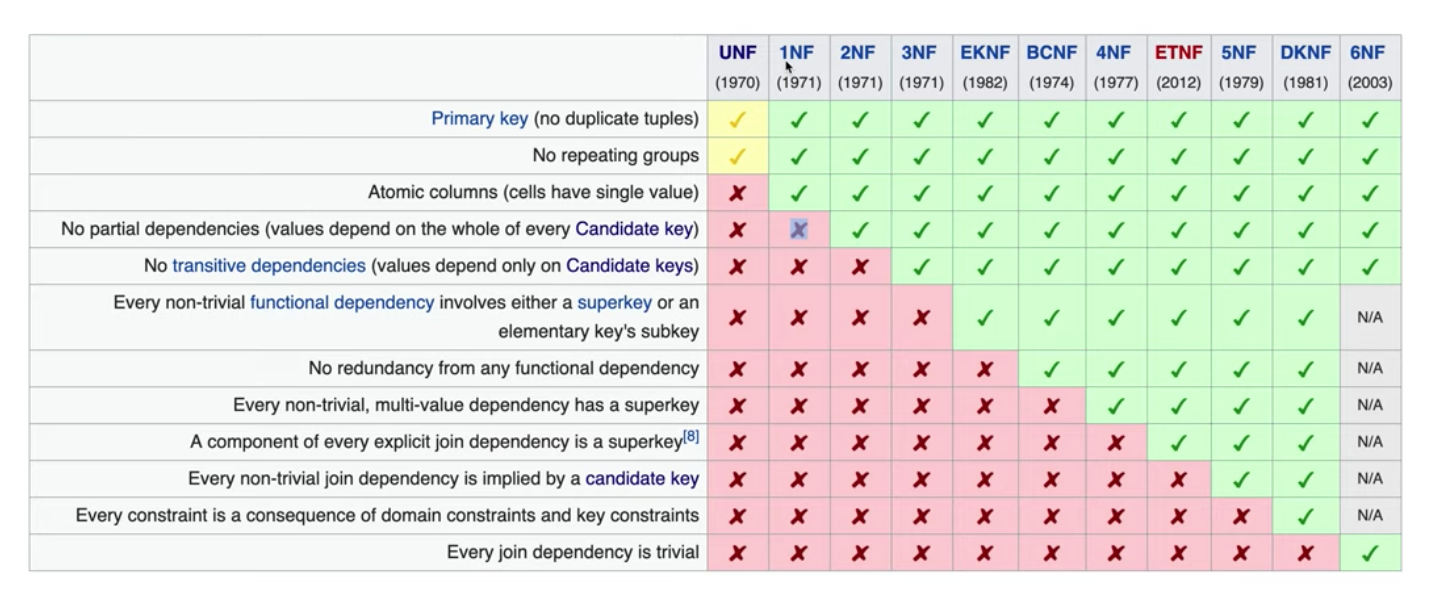
상업적으로는 3정규형까지 이루어진다.
제 1 정규화
Atomic columns
각각의 컬럼의 값들이 값을 하나만 가져야 한다.
컬럼의 요소가 하나 이상이라면 SQL에서 데이터 가공이 어렵다.
제 2 정규화
No partial dependencies
부분 종속성이 없어야한다.
키가 중복키가 아니면 된다.
제 3 정규화
No transitive dependencies
이행적 종속성이 없어야 한다.
물리적 데이터모델링
논리적 데이터모델링이 관계형데이터모델에 이상적인 표를 만드는 거이라면,
물리적 데이터모델링은 이상적인 표를 현실적인 표로 만드는 것이다.
물리적 데이터모델링은 성능에 초점을 맞춘다.
성능을 빠르게 하는 방법
-
index
데이터를 읽는 것을 획기적으로 빠르게 한다.
하지만 데이터를 쓰는데 비약적인 단점이 있다.
경우에 따라서는 메모리를 많이 차지한다.
그럼에도 index를 사용하는 이유는 잘 정리해서 넣어두면, 읽기가 빠르다는 장점이 있기 때문이다.
-
application
입력에 대한 실행 결과를 저장했다가
동일한 입력에 대해서 저장했던 데이터를 사용함으로써 데이터베이스에 부하를 줄인다. -
denormalization
위의 방법으로도 성능에 문제가 있다면 테이블의 구조를 바꾸는 역정규화를 시도한다.
denormalization 역정규화 반정규화
정규화를 통해 만들어진 이상적인 표를 성능과 개발의 편의성을 위해 표의 구조를 바꾸는 것을 의미한다.
컬럼을 조작해서 JOIN을 줄이기
중복을 허용해서 테이블의 구조를 바꾼다.
중복이 있지만 JOIN을 하지 않아도 된다는 장점이 있다.
컬럼을 조작해서 계산을 줄이기
데이터를 처리하는 비용을 줄이는 역정규화
컬럼을 기준으로 테이블을 분리
행을 기준으로 테이블을 분리
관계의 역정규화
