Q1. API란 무엇인가?
-
API는 정의 및 프로토콜 집합을 사용하여 두 소프트웨어 구성 요소가 서로 통신할 수 있게 하는 매커니즘입니다. 예를 들어, 기상청의 소프트웨어 시크템에는 일일 기상 데이터가 들어 있습니다. 휴대폰의 날씨 앱은 API를 통해 이 시스템과 "대화"하고 휴대폰에 매일 최신 날씨 정보를 표기합니다.
-
API는 Application Programming Interface(애플리케이션 프로그램 인터페이스)의 줄임말입니다. API의 맥락에서 애플리케이션이라는 단어는 고유한 기능을 가진 모든 소프트웨어를 나타냅니다. 인터페이스는 두 애플리케이션 간의 서비스 계약이라고 할 수 있습니다. 이 계약은 요청과 응답을 사용하여 두 애플리케이션이 서로 통신하는 방법을 정의합니다. API 문서에는 개발자가 이러한 요청과 응답을 구성하는 방법에 대한 정보가 들어 있습니다.
-
API 아키텍처는 일반적으로 클라이언트와 서버 측면에서 설명됩니다. 요청을 보내는 애플리케이션을 클라이언트라고하고 응답을 보내는 애플리케이션을 서버라고 합니다. 따라서 날씨 예에서 기상청의 날씨 데이터베이스는 서버이고 모바일 앱은 클라이언트입니다.
-
API가 생성된 시기와 이유에 따라 API는 네 가지 방식으로 작동할 수 있습니다.
SOAP API
이 API는 단순 객체 접근 프로토콜을 사용합니다. 클라이언트와 서버는 XML을 사용하여 메세지를 교환합니다. 과거에 더 많이 사용되었으며 유연성이 떨어지는 API입니다.
RPC API
이 API를 원격 프로시저 호출이라고 합니다. 클라이언트가 서버에서 함수나 프로시저를 완료하면 서버가 출력을 클라이언트로 다시 전송합니다.
Websocket API
Websocket API는 JSON 객체를 사용하여 데이터를 전달하는 또 다른 최신 웹 API 개발입니다. Websocket API는 클라이언트 앱과 서버 간의 양방향 통신을 지원합니다. 서버가 연결된 클라이언트에 콜백 메세지를 전송할 수 있어 REST API보다 효율적입니다.
REST API
오늘날 웹에서 볼 수 있는 가장 많이 사용되고 유연한 API입니다. 클라이언트가 서버에 요청을 데이터로 전송합니다. 서버가 이 클라이언트 입력을 사용하여 내부 함수를 시작하고 출력 데이터를 다시 클라이언트에 반환합니다.
출처: https://aws.amazon.com/ko/what-is/api/
Q2. Client와 Server란 무엇인가?
먼저 네트워킹(Networking)이란?
IT계열에서 네트워킹의 개념은 '두 대 이상의 컴퓨터를 케이블로 연결하여 네트워크를 구성하는 것'을 네트워킹이라고 한다.
현재에는 셀 수도 없을 만큼 많은 수의 컴퓨터가 인터넷이라는 하나의 거대한 네트워크를 구성하고 있고 인터넷을 통해 다양하고 방대한 양의 데이터를 공유하는 것이 가능해진 것이다. 이러한 네트워킹에 따라 메신저나 온라인게임과 같은 인터넷을 이용해 다양한 네트워크 어플리케이션이 많이 생겨난 것이다.
클라이언트와 서버
서버(server): 서비스를 제공하는 컴퓨터(service provider)
- 다수의 클라이언트에게 서비스를 제공하기 때문에 고사양의 하드웨어를 갖춘 컴퓨터이지만, 하드웨어의 사양으로 서버와 클라이언트를 구분하는 것은 절대 아니며, 사양과 관계없이 서비스를 제공하는 소프트웨어가 실행되는 컴퓨터를 서버라고 한다.
클라이언트(client): 서비스를 사용하는 컴퓨터(service user)
- 서버와 이어진 모든 기기(컴퓨터의 경우 WIFI / 모바일은 모바일 네트워크)와 단말기에서 이용하는 웹에 접근하는 SW이며, 주로 서버에 요청을 보내고 응답을 받는 역할을 한다.
서비스(Service)
-
위에서 본 것 처럼 서버는 클라이언트로부터 요청을 받아 응답을 내려주고 클라이언트는 서버에 데이터를 요청하고 응답을 받는다. 재화와 서비스의 개념에서 가져와 서비스라고 일컫는다.
-
서비스의 종류에 따라 파일 서버/메일 서버/어플리케이션 서버 등으로 나눠진다.
서버와 클라이언트는 어떻게 연결하지?
- 앞에서 보았던 개념처럼, 서버가 서비스를 제공하기 위해서는 서버 프로그램이 있어야하고, 클라이언트가 서비스를 제공받기 위해서는 서버 프로그램과 연결할 수 있는 클라이언트 프로그램이 존재해야 한다.
그러면 연결하는 방식은 한가지뿐인가?
-
기본적으로 서버 프로그램을 따로 두는지 또는 하나로 합친것인지 나뉜다.
-
서버기반 모델(server-based model) : 전용서버를 두는 것
- 안정적인 서비스 제공 가능
- 공유 데이터의 관리와 보안이 용이
- 서버구축비용과 관리비용이 든다는 단점
- P2P 모델(peer-to-peer model) : 별도의 전용 서버없이 각 클라이언트가 서버 역할을 동시에 수행하는 것
- 서버구축 및 운용비용을 아낄 수 있는 장점
- 자원의 활용을 극대화 할 수 있음
- 자원의 관리가 어려움
- 보안이 취약하다는 단점
Q3. WAS란 무엇인가? Web Server와 차이점은 무엇인가?
정적 페이지와 동적 페이지
정적 페이지 (Static Page)
데이터베이스에서 정보를 가져오거나 별도의 서버에서의 처리가 없어도, 사용자들에게 보여줄 수 있는 페이지. 어떠한 사용자가 오던간에 동일한 페이지를 보여줍니다.

정적인 요소에는 HTML, CSS, JS, IMAGE 같은 요소들이 있습니다. JS는 클라이언트 단에서 HTML과 CSS와 같은 요소들을 컨트롤하는데 쓰입니다. 파일의 형태로 보내기 때문에 정적인 요소로 봐도 무방하다고 생각합니다.
동적 페이지 (Dynamic Page)
서버에서 데이터베이스에서 정보를 가져와서 처리하는 것처럼, 어떠한 요청에 의하여 서버가 일을 수행하고 해당 결과가 포함된 파일을 보여주는 페이지. 사용자들마다 다른 페이지가 보여질 수 있습니다.
웹 서버와 컨테이너, WAS
웹 서버 (Web Server)
흔히 웹 서버라고 하면 초기에 Django, Node.js와 같은 것들을 떠올릴 수 있지만, 엄밀하게 따지면 이들은 WAS라고 보는 것이 맞는 것 같습니다. 그렇다면 웹 서버는 무엇일까요?
웹 서버의 역할은 크게 2가지 입니다.
-
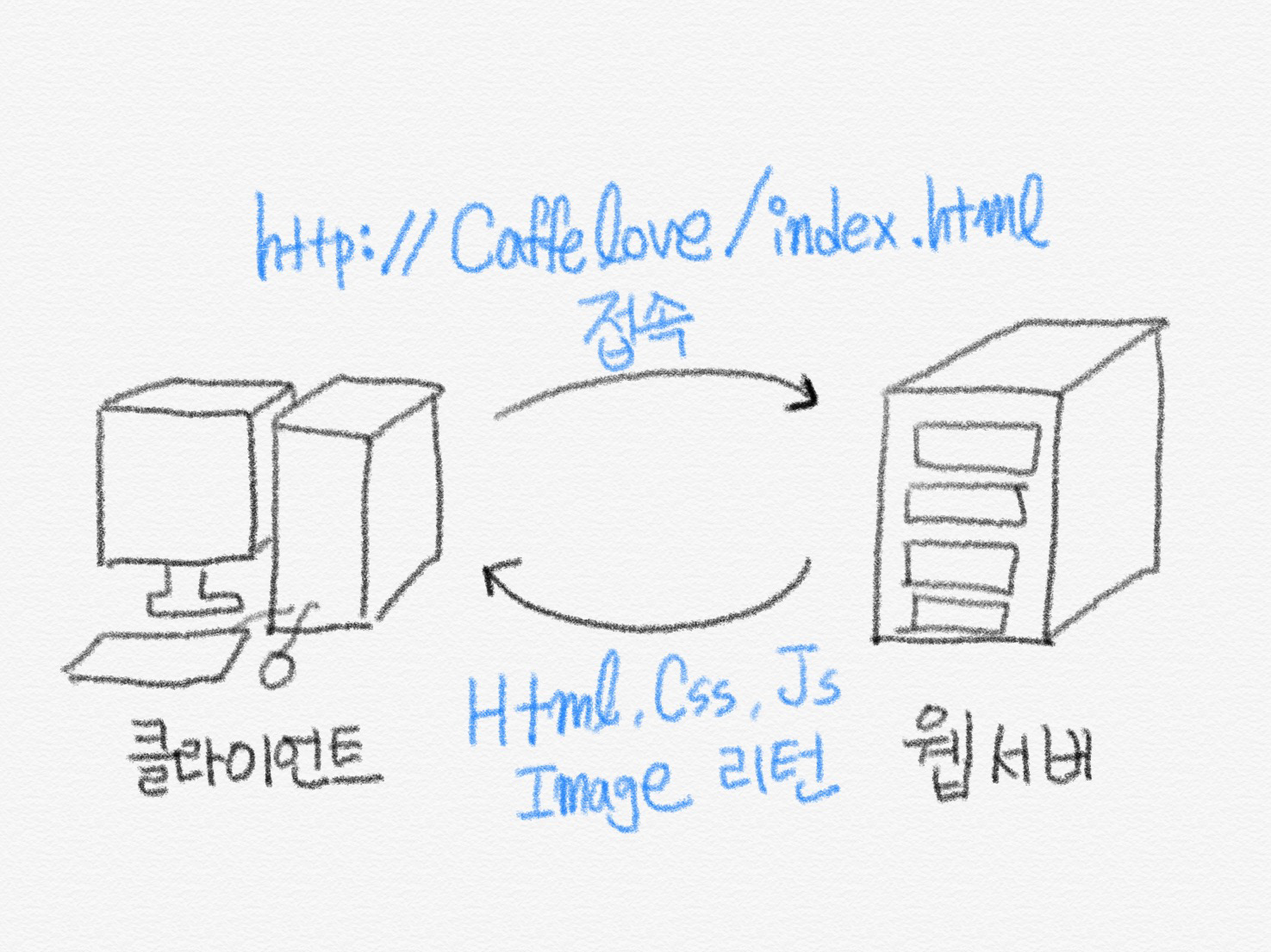
웹 서버는 클라이언트가 요청한 정적인 콘텐츠를 HTTP 프로토콜을 통하여 제공해주는 서버입니다. 위에서 언급한 정적 페이지를 보내줍니다.
정적인 콘텐츠 제공이 가장 큰 역할입니다. -
다른 역할로는 동적인 요청이 클라이언트로부터 들어왔을 때, 해당 요청을 웹 서버에서 처리할 수 없기 때문에 컨테이너(Container)로 보내주는 역할을 합니다.
웹 서버에는 Nginx, Appach HTTP Server, IIS가 있습니다.
컨테이너 (Container)
컨테이너는 동적인 데이터들을 처리하여 정적인 페이지로 생성해주는 소프트웨어 모듈 입니다. 사용자가 로그인해서 MyPage 메뉴에 들어간다고 가정해보겠습니다. 이 메뉴에서는 각자 사용자에 따라 보여질 정보가 다릅니다. 사용자의 요청이 들어오면 웹 서버는 정적인 요소만 클라이언트 측에 보낼 수 있고, 동적으로 처리해야 하는 부분은 처리할 수 없습니다. 컨테이너는 이러한 부분을 대신 처리해서 웹 서버에 정적인 파일로 만들어서 보내주는 모듈이라고 생각하면 될 것 같습니다.
클라이언트 측에서 크롬 개발자 도구를 이용하여 파일을 살펴보면 php, ejs 파일도 만든 소스코드도 전부 html로 전송됩니다. 이는 해당 파일에서 처리해야할 부분을 처리하고 정적 파일로 만든 후에 클라이언트에게 보냈다고 생각하면 좋을 것 같습니다.
php나 js 코드 등으로 처리한 코드 부분도 클라이언트 측에서는 볼 수 없습니다.
자바 기반의 서버에서는 서블렛이라는 용어도 많이 사용하는 것 같습니다.
WAS (Web Application Server)
웹 서버로부터 오는 동적인 요청을 처리하는 서버를 말합니다. 웹 서버와 컨테이너를 붙여놓은 서버 라고 보시면 될 것 같습니다.
위키백과에서는 아래와 같이 정의하고 있습니다.
웹 애플리케이션 서버(Web Application Server, 약자 WAS)는 웹 애플리케이션과 서버 환경을 만들어 동작시키는 기능을 제공하는 소프트웨어 프레임워크이다.[1] 인터넷 상에서 HTTP 를 통해 사용자 컴퓨터나 장치에 애플리케이션을 수행해 주는 미들웨어 (소프트웨어 엔진)으로 볼 수 있다. 웹 애플리케이션 서버는 동적 서버 콘텐츠를 수행하는 것으로 일반적인 웹 서버와 구별이 되며, 주로 데이터베이스 서버와 같이 수행이 된다. 일반적으로 "WAS" 또는 "WAS S/W"로 통칭하고 있으며 공공기관에서는 "웹 응용 서버"로 사용되고, 영어권에서는 "Application Server" (약자 AS)로 불린다.
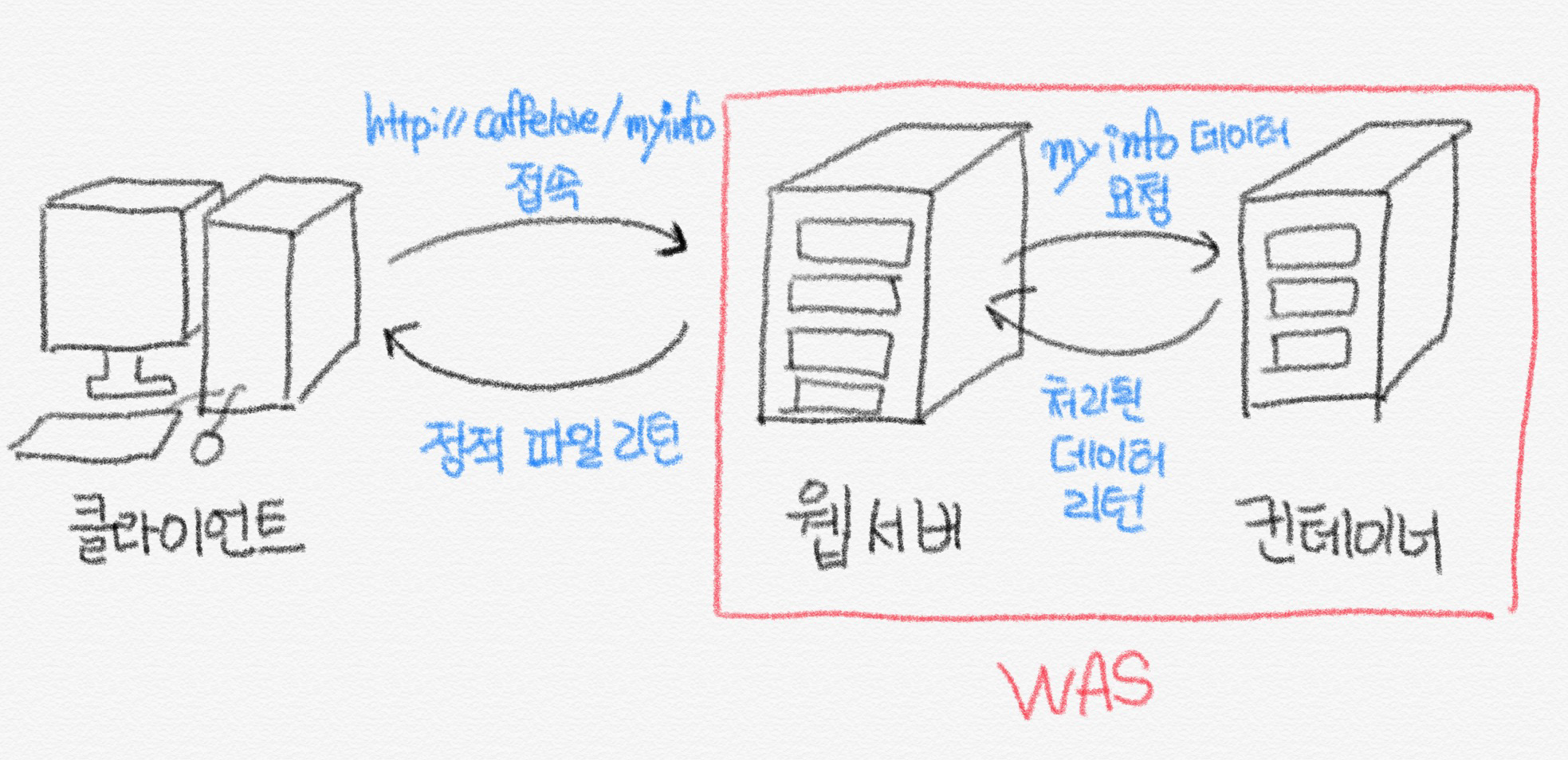
예를 들어서, 클라이언트에서 http://caffelove.com 이라는 도메인을 가진 서버에서 '내 정보'를 눌러 http://caffelove.com/myinfo 라는 경로에 들어간다고 가정해보겠습니다. 내 정보를 볼 수 있는 홈페이지라고 하겠습니다. 환경은 node.js라고 가정하겠습니다.
/myinfo 라는 경로로 요청하면 WAS는 자신의 라우팅 정보를 통하여 어떤 처리를 해야 될지 살펴봅니다. 이 때, myinfo를 라우팅할 때, 'myinfo.html이라는 파일을 보여줘!' 라는 요청을 하게된다면 정적인 요소이기 때문에, 웹 서버에서 클라이언트에게 myinfo.html 파일을 보내주기만 하면 됩니다. 관련된 CSS, JS, IMAGE 파일도 함께요.
하지만, myinfo는 자신의 정보를 보여주는 페이지이니 위처럼 반응하지 않겠죠. WAS에서는 대게 먼저 데이터베이스에서 데이터를 가져옵니다. 그 다음에 원하는 데이터를 가공하여, myinfo.ejs 파일로 해당 데이터를 보내줍니다. .ejs 파일에서는 node.js 에서의 변수나 정보를 사용할 수 있게 만들어 놓았습니다. 정보를 넣어야할 곳에 데이터베이스에서 가져온 정보를 넣고, ejs 파일을 html로 바꿔준 다음에 웹 서버로 전송합니다. (node.js의 Javascript와 클라이언트의 UI를 동적으로 보여주는 Javascript는 다른 것이니 유의해서 봐주세요!)
웹 서버는 위의 html 요소를 클라이언트에게 다시 보내주는 것이죠, WAS에 Tomcat, Jeus 같은 것들이 있다고 합니다.
출처: https://melonicedlatte.com/web/2019/06/23/210300.html
Q4. HTTP 프로토콜이란 무엇인가?
HTTP 프로토콜이란?
HTTP(Hypertext Transfer Protocol)는 인터넷상에서 데이터를 주고 받기 위한 서버/클라이언트 모델을 따르는 프로토콜이다.
애플리케이션 레벨의 프로토콜로 TCP/IP 위에서 작동한다.
HTTP는 어떤 종류의 데이터든지 전송할 수 있도록 설계되어있다.
HTTP로 보낼 수 있는 데이터는 HTML 문서, 이미지, 동영상, 오디오, 텍스트 문서 등 여러 종류가 있다.
하이퍼텍스트 기반으로(Hypertext) 데이터를 전송하겠다(Transfer)=링크기반으로 데이터에 접속하겠다는 의미이다.
작동방식
HTTP는 서버/클라이언트 모델을 따른다.
클라이언트에서 요청(request)를 보내면 서버는 요청을 처리해서 응답(response)한다.

클라이언트:
서버에 요청하는 클라이언트 소프트웨어(IE, Chrome, Firefox, Safari..)가 설치된 컴퓨터를 이용한다.
클라이언트는 URI를 이용해서 서버에 접속하고, 데이터를 요청할 수 있다.
서버:
클라이언트의 요청을 받아서, 요청을 해석하고 응답을 하는 소프트웨어가 설치된 컴퓨터(Apache, nginx, IIS, lighttpd) 등이 서버 소프트웨어다.
웹 서버는 보통 표준포트인 80번 포트로 서비스한다.
Connectionless & Stateless
HTTP는 Connectionless 방식으로 작동한다.
서버에 연결하고, 요청해서 응답을 받으면 연결을 끊어버린다.
기본적으로는 자원 하나에 대해서 하나의 연결을 만든다.
이런 작동방식은 각각 아래의 장점과 단점을 가진다.
장점:
불특정 다수를 대상으로하는 서비스에 적합한 방식이다.
수십만명이 웹 서비스를 사용하더라도 접속유지는 최소한으로 할 수 있기 때문에, 더 많은 유저의 요청을 처리할 수 있다.
단점:
연결을 끊어버리기 때문에, 클라이언트의 이전 상태를 알 수가 없다.
이러한 HTTP의 특징을 Stateless라고 하는데, Connectionless로 부터 파생되는 특징이라고 할 수 있다.
클라이언트의 이전 상태 정보를 알 수 없게되면, 웹 서비스를 하는데 당장에 문제가 생긴다.
클라이언트가 과거에 로그인을 성공하더라고 로그 정보를 유지할 수가 없다. HTTP는 cookie를 이용해서 이 문제를 해결하고 있다.
Cookie는 클라이언트와 서버의 상태 정보를 담고있는 정보조각이다.
로그인을 예로 들자면, 클라이언트가 로그인에 성공하면, 서버는 로그인 정보를 자신의 데이터베이스에 저장하고, 동일한 값을 cookie 형태로 클라이언트에 보낸다.
첫 요청 시:
클라이언트 로그인 성공 then 서버 로그인 정보를 자신의 DB에 저장
(서버는 cookie를 키로하는 값을 데이터베이스에 저장하는 방식으로 "세션"을 유지한다)
and then return 쿠키 to 클라이언트
클라이언트는 다음 번 요청 때 cookie를 서버에 보내는데, 서버는 cookie 값으로 자신의 데이터베이스를 조회해서 로그인 여부를 확인할 수 있다.
두번째 요청 시:
클라이언트 request(cookie) to server then 서버는 자신의 DB 조회 and then 로그인 여부 확인
UR(Uniform Resource Identifiers)
클라이언트 소프트웨어(IE, Chrome, Firefox, Safari...)는 URI를 이용하여 자원의 위치를 찾는다.
URI는 HTTP와 독립된 다른 객체다.
HTTP는 전송 프로토콜이고, URI는 자원의 위치를 알려주기 위한 프로토콜이다.
Uniform Resource Identifiers의 줄임말로, World Wide Web 상에서 접근하고자 하는 자원의 위치를 나타내기 위해서 사용한다.
자원은 HTML 문서, 이미지, 동영상, 오디오, 텍스트 문서 등 모든 것이 될 수 있다.
Method (메소드)
메소드는 요청의 종류를 서버에게 알려주기 위해서 사용한다.
다음은 요청에 사용할 수 있는 메소드들이다.
GET: 정보를 요청하기 위해서 사용한다. (SELECT)
POST: 정보를 밀어넣기 위해서 사용한다. (INSERT)
PUT: 정보를 업데이트하기 위해서 사용한다. (UPDATE)
DELETE: 정보를 삭제하기 위해서 사용한다. (DELETE)
HEAD: (HTTP)헤더 정보만 요청한다. 해당 자원이 존재하는지 혹은 서버에 문제가 없는지를 확인하기 위해서 사용한다.
OPTIONS: 웹 서버가 지원하는 메소드의 종류를 요청한다.
TRACE: 클라이언트의 요청을 그대로 반환한다. 예컨데 echo 서비스로 서버 상태를 확인하기 위한 목적으로 주로 사용한다.
각 용도에 맞는 메소드가 준비되어 있음에도 GET과 POST만으로도 모든 종류의 요청을 표현할 수 있다.
명시적으로 메소드를 사용하지 않아도 웹 서비스 개발에 큰 문제가 없지만 Restful API 서버의 경우에는 GET, POST, PUT, DELETE를 명시적으로 구분한다.
자원의 위치 뿐만 아니라 자원에 할 일 까지 명확히 명시할 수 있기 때문에, Open API 서버를 만들기 위해서 널리 사용한다.
요청데이터 포맷
- 요청 메소드: GET, PUT, POST, DELETE, OPTIONS 등의 요청 방식이 온다.(GET)
- 요청 URI: 요청하는 자원의 위치를 명시한다. (URI)
- HTTP 프로토콜 버전: 웹 브라우저가 사용하는 프로토콜 버전이다. (HTTP/1.1)
응답헤더 포맷
프로토콜과 응답코드: (HTTP/1.1 200 OK)
날짜: (Date:SUN, 12 Aug 2018 11:30:00 GMT)
서버 프로그램 및 스크립트 정보: (Apache/2.2.4(Unix)PHP/5.2.0)
응답헤더에는 다양한 정보를 추가할 수 있다.
컨텐츠의 마지막 수정일
캐쉬 제어 방식.
컨텐츠 길이.
Keep Alive기능 설정
응답코드
2xx 성공
서버가 요청을 성공적으로 처리했음을 의미한다.
| 코드번호 | 설명 | 비고 |
|---|---|---|
| 200 | 성공 | 서버가 요청을 제대로 처리했다. |
4xx 요청 오류
클라이언트 요청에 오류가 있음을 의미한다.
| 코드번호 | 설명 | 비고 |
|---|---|---|
| 400 | 잘못된 요청 | 주로 헤더 포맷이 HTTP 규약에 맞지 않을 경우 |
| 403 | 금지 | 서버가 요청을 거부하고 있다. |
| 404 | 찾을 수 없음 | 요청한 자원이 서버에 존재하지 않는다. |
Keep Alive
HTTP 1.1 부터는 keep-alive 기능을 지원한다.
HTTP는 하나의 연결에 하나의 요청을 하는 것을 기준으로 설계가 됐다.
요즘 웹 서비스의 경우 간단한 페이지라고해도 수십개의 데이터(문서, image, css, js)가 있기 마련인데, HTTP의 원래 규격대로라면 웹 페이지를 하나 표시하기 위해서는 연결을 맺고 끊는 과정을 수십번 반복해야한다.
당연히 비효율적일 수 밖에 없다.
연결을 맺고 끊는 것은 TCP 통신 과정에서 가장 많은 비용이 소비되는 작업이기 때문이다.
예를들어 HTML로 표현된 문서를 다운받는다고 가정해보자.
이 문서에는 20개 정도의 image, css, js 파일이 있다.
Keep-alive를 지원하지 않을 경우 다음과 같은 과정을 거친다.
- 웹 서버에 연결 -> HTML 문서를 다운로드 -> 웹 서버 연결 해제
- HTML 문서의 image, css, js 링크들을 읽어서 다운로드해야할 경로를 저장 -> 웹 서버에 연결 -> 첫번째 이미지 다운로드 -> 연결 해제
- 웹 서버 연결 -> 두번째 이미지 다운로드 -> 연결 해제
keep-alive 설정을 하면, 지정된 시간동안 연결을 끊지 않고 요청을 보낼 수 있다.
- 웹 서버 연결 -> HTML 문서 다운로드 -> image, css, js 다운로드 -> 모든 문서를 다운로드 받았다면 연결 해제
keep-alive는 하나의 연결로 여러 요청을 처리하기 때문에 효율적이긴 하지만, 연결이 그만큼 길어지기 때문에 동시간대 연결이 늘어난다. 운영체제에 있어서 연결은 "유한한 자원"이다. 연결을 다 써버리면, 서버는 더이상 연결을 받을 수 없게된다.
Max 값을 이용해서 keep-alive 연결을 제한하는 이유이다.
출처: https://shlee0882.tistory.com/107
Q5. Restful API는 무엇인가?
-
RESTful API는 두 컴퓨터 시스템이 인터넷을 통해 정보를 안전하게 교환하기 위해 사용하는 인터페이스입니다. 대부분의 비즈니스 애플리케이션은 다양한 태스크를 수행하기 위해 다른 내부 애플리케이션 및 서드 파티 애플리케이션과 통신해야합니다. 예를 들어 월간 급여 명세서를 생성하려면 인보이스 발행을 자동화하고 내부의 근무 시간 기록 애플리케이션과 통신하기 위해 내부 계정 시스템이 데이터를 고객의 뱅킹 시스템과 공유해야 합니다. RESTful API는 안전하고 신뢰할 수 있으며 효율적인 소프트웨어 통신 표준을 따르므로 이러한 정보 교환을 지원합니다.
-
REST는 Representational State Transfer의 줄임말입니다. REST는 클라이언트가 서버 데이터에 액세스하는 데 사용할 수 있는 GET, PUT, DELETE 등의 함수 집합을 정의합니다. 클라이언트와 서버는 HTTP를 사용하여 데이터를 교환합니다.
-
REST API의 주된 특징은 무상태입니다. 무상태는 서버가 클라이언트 데이터를 저장하지 않음을 의미합니다. 서버에 대한 클라이언트 요청은 웹 사이트를 방문하기 위해 브라우저에 입력하는 URL과 유사합니다. 서버의 응답은 웹 페이지의 일반적인 그래픽 렌더링이 없는 일반 데이터입니다.
