내가 사용하는 useCallBack, useMemo가 진짜 성능 최적화를 진행중인걸까?

개발을 하면서 한동안은 성능 최적화라는 단어에 매몰되어, “어떻게 하면 최적화를 잘할 수 있을까?“라는 생각에 사로잡혀 있었습니다. 그 시점에서 시도할 수 있는 가장 가까운 방법은 useCallback과 useMemo를 사용하는 것이었는데요. 계산 결과나 함수 정의를 캐싱해두면 불필요한 연산이나 리렌더링을 줄일 수 있지 않을까 하는 기대가 있었기 때문입니다.
하지만 사용하면서도 계속해서 다음과 같은 의문이 들었습니다.
“내가 정말 최적화를 하고 있는 걸까?”
“이 단순한 훅 하나로 과연 얼마나 성능이 좋아지는 걸까?”
그 의심은 점점 커졌고, 오히려 과도한 사용이 악영향을 주는 건 아닐지 고민하게 되었습니다.
특히, 모든 곳에 useCallback이나 useMemo를 적용하면서 생길 수 있는 메모리 누수(leak)를 사전에 방지하는 것이 나을지, 아니면 일단은 단순하고 명확하게 코드를 유지하다가 실제 문제가 생겼을 때 성능 최적화를 도입하는 것이 더 나을지에 대해 많은 생각을 했습니다.
오늘은 이러한 고민 끝에 제가 나름대로 설정하게 된 기준과, 그에 따른 제 시각에 대해 이야기해보려고 합니다.
실제로 useCallback, useMemo를 사용 여부에 따라 비교해봅시다.
이번 실험에서는 리액트 최적화 기법의 역설적인 결과를 확인할 수 있었습니다. 모든 함수에 useCallback, 모든 값에 useMemo를 적용한 버전과, 이러한 최적화 없이 평범하게 작성한 버전을 비교해 Profiler로 성능을 측정해 보았는데요. (단, useEffect 내부에서 사용하는 함수나 값은 기존처럼 useCallback 또는 useMemo를 유지했습니다.)
그 결과는 예상과 달리, 최적화를 적용한 쪽이 오히려 성능이 떨어지는 현상이 나타났습니다.
모든 곳에 useCallback, useMemo를 사용한 코드
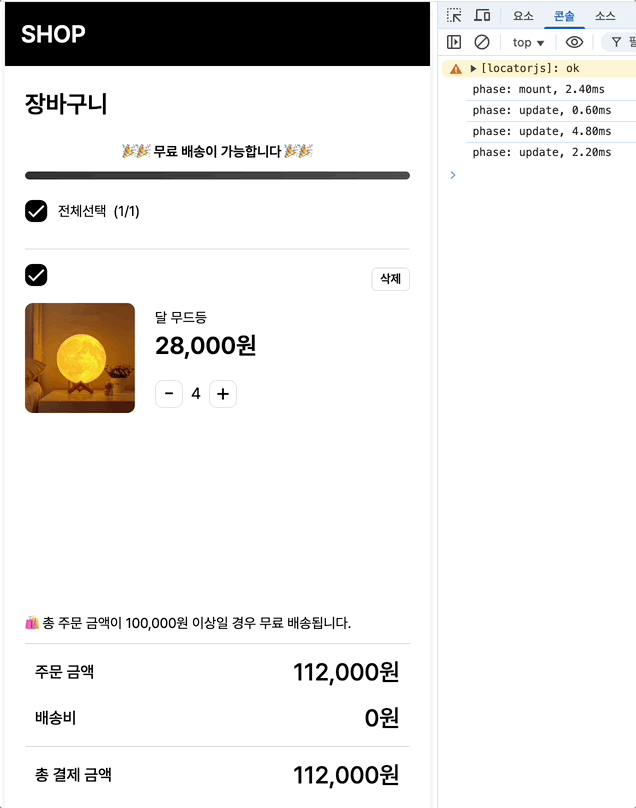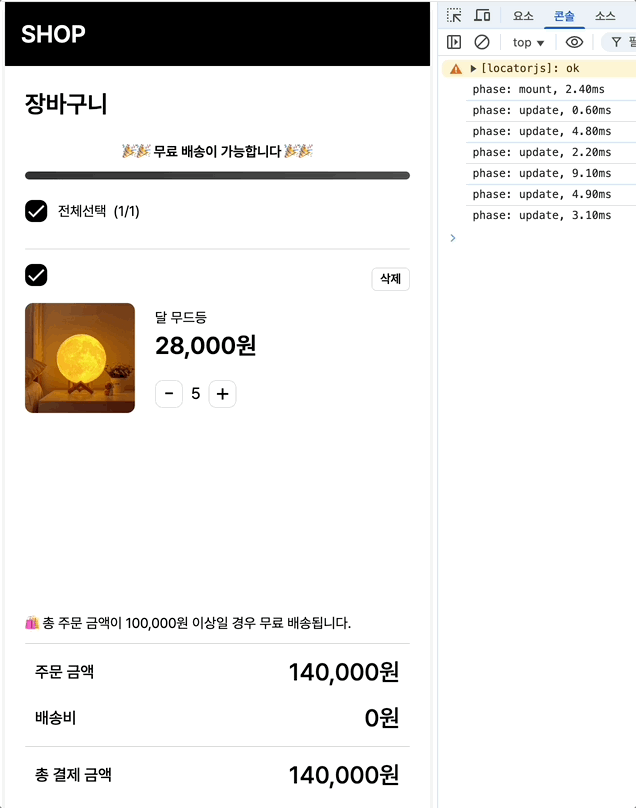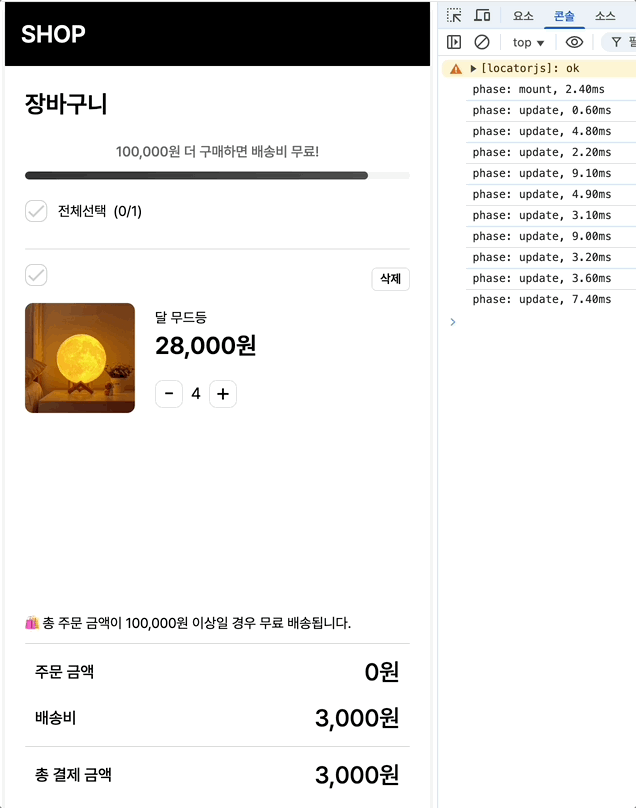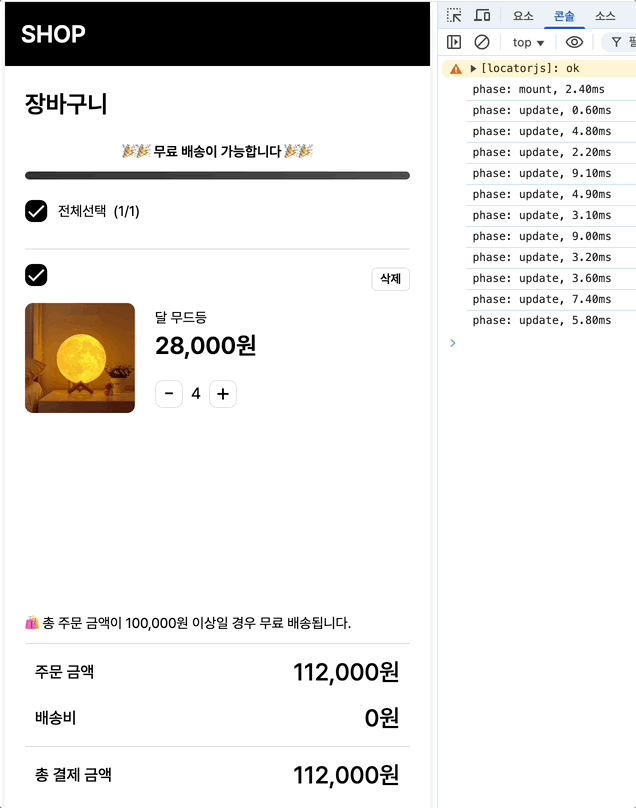
최초 마운트시에는 2.4, 수량 증가에는 평균 18.7/12.9/8.9 체크박스에는 7.4/5.8이 나옵니다.
useCallback, useMemo를 제거한 코드
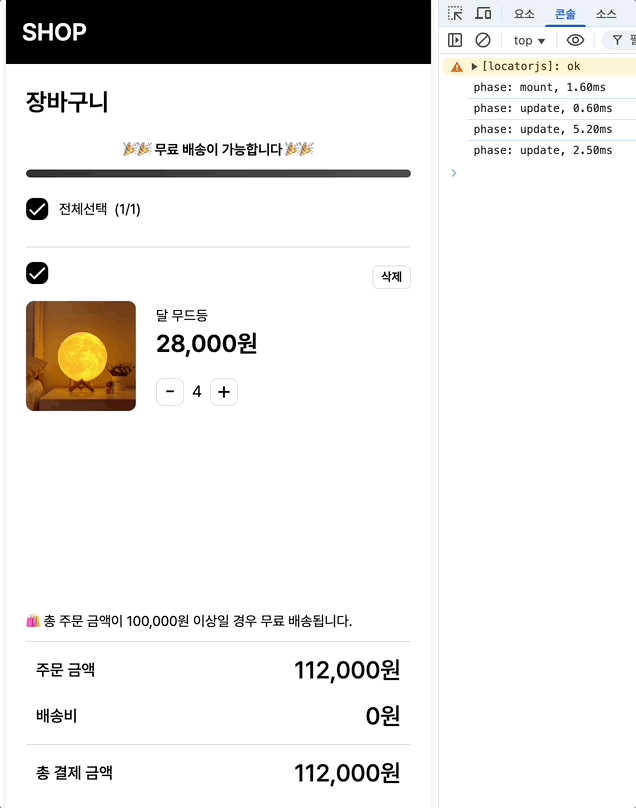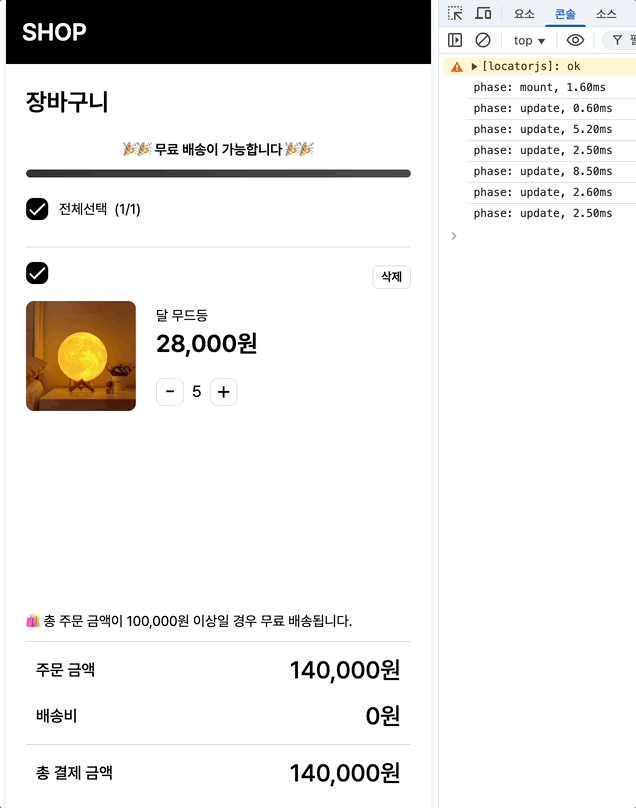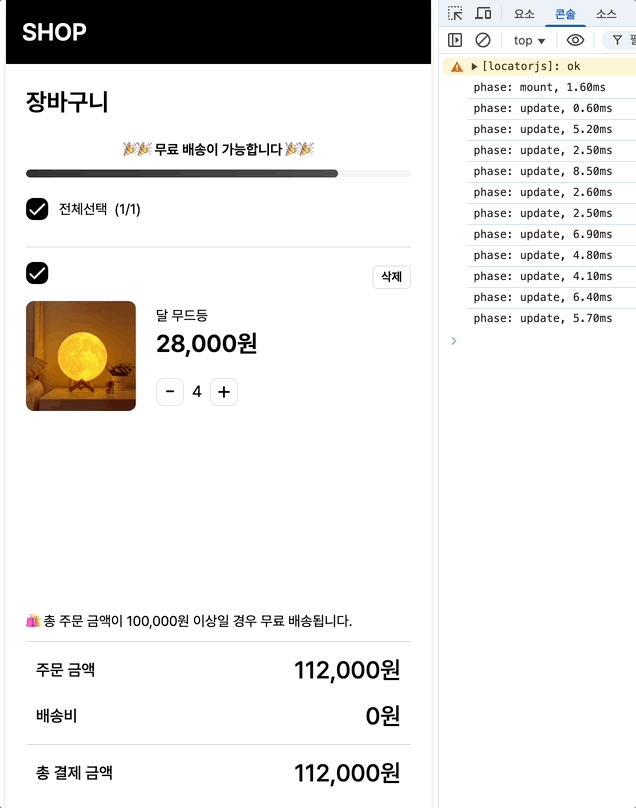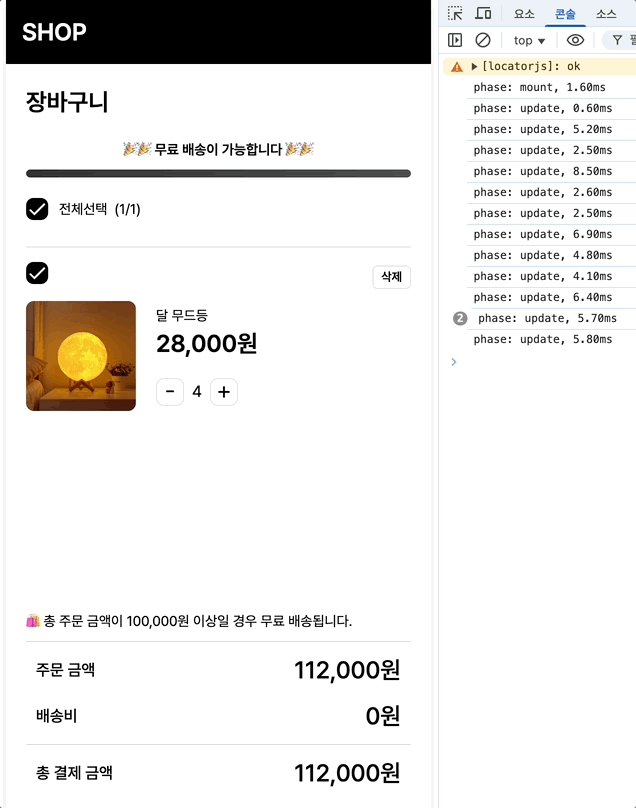
최초 마운트시에는 1.6, 수량 증가에는 평균 16/12.6/9.1 체크박스에는 6.4/5.8이 나옵니다.
(수량 변경시 콘솔이 3번 출력되는 이유는, 수량 증가 버튼 클릭 → 상태 변경 발생 → 관련된 자식 컴포넌트들 최소 3개가 재렌더링되며 각각의 렌더링마다 onRender가 호출되고 있는 것입니다.)
최초 마운트: 2.4ms → 1.6ms (33% 개선)
수량 증가: 18.7ms → 16ms (14% 개선)
체크박스: 7.4ms → 6.4ms (13% 개선)
저는 처음에 제가 잘못 측정한 줄 알았습니다. 캐싱을 하면 오히려 좋아야 하는 것 아닌가요?
왜 이런일이 일어났을까요?
이 현상을 이해하려면 리액트의 useCallback과 useMemo같은 최적화 기법이 실제로 어떻게 동작하는지를 살펴볼 필요가 있습니다.
const memoizedCallback = useCallback(() => {
// 실제 함수 로직
}, [dependency]);
const memoizedValue = useMemo(() => {
// 실제 값
}, [data]);이 Hook들이 실행될 때 리액트는 다음과 같은 작업을 수행합니다.
- 이전 의존성 배열과 현재 의존성 배열을 비교합니다.
- 메모이제이션된 값을 캐싱하고 재사용합니다.
- 클로저 새로 생성하거나 재활용합니다.
제가 테스트한 프로젝트는 상당히 단순했습니다. 컴포넌트 개수도 그리 많지 않고, 상태 변화도 단순한 구조였고, 연산량 자체도 크지 않았습니다. 이런 상황에서 결과적으로 최적화를 위한 추가 작업이 오히려 성능을 떨어뜨리는 결과를 낳았습니다.
- 실제 연산 비용: 0.5ms (간단한 배열 필터링, 상태 업데이트)
- 최적화 오버헤드: 2ms (의존성 검사, 메모 비교, 클로저 관리)
이 결과는 리액트 공식 문서의 지침과도 일치합니다. 물론, 일부에서는 “지금은 단순하더라도, 추후 데이터가 많아지면 도움이 될 수 있지 않을까?”라는 의문을 가질 수 있습니다. 그러나 명확한 병목 구간이 확인되지 않은 상황에서의 이러한 최적화는, 사실상 ‘추측에 의한 선제 조치’일 뿐이며, 오히려 유지보수 복잡도를 높이는 결과를 초래할 수도 있지 않을까요?
리액트 공식 문서가 알려주는 불편한 진실
리액트 공식문서에서는 명확한 경우에만 useCallback과 useMemo를 사용할 것을 권장합니다.
useCallback으로 함수를 캐싱하는 것은 몇 가지 경우에만 가치 있습니다
공식문서에서는 몇가지 경우에만 가치가 있음을 이야기하면서 두가지를 이야기 하고 있습니다.
memo로 감싸진 컴포넌트에 prop으로 넘깁니다. 이 값이 변하지 않으면 리렌더링을 건너뛰고 싶습니다. memoization은 의존성이 변했을 때만 컴포넌트가 리렌더링하도록 합니다.- 넘긴 함수가 나중에 어떤 Hook의 의존성으로 사용됩니다. 예를 들어,
useCallback으로 감싸진 다른 함수가 이 함수에 의존하거나,useEffect에서 이 함수에 의존합니다.
다른 경우에서 useCallback으로 함수를 감싸는 것은 아무런 이익이 없습니다. 라고 공식문서에서는 단언합니다.
useMemo로 최적화하는 것은 몇몇 경우에만 유용합니다.
마찬가지로 useMemo를 사용함이 유의미한 곳은 다음 3가지라는 것을 이야기해주고 있습니다.
useMemo에 입력하는 계산이 눈에 띄게 느리고 종속성이 거의 변경되지 않는 경우memo로 감싸진 컴포넌트에 prop로 전달할 경우. 값이 변경되지 않았다면 렌더링을 건너뛰고 싶을 것입니다. 메모이제이션을 사용하면 의존성이 동일하지 않은 경우에만 컴포넌트를 다시 렌더링할 수 있습니다.- 전달한 값을 나중에 일부 Hook의 종속성으로 이용할 경우. 예를 들어, 다른
useMemo의 계산 값이 여기에 종속되어 있을 수 있습니다. 또는useEffect의 값에 종속되어 있을 수 있습니다.
역시 마지막에 못을 박습니다. 이것을 제외하면 이득이 거의 없다라고요.
공통적으로, useEffect 의존성 배열에 존재하는 경우 혹은 memo로 감싸진 컴포넌트에 전달되는 경우에만 최적화가 의미있다고 보고 있습니다.
개발 환경 vs 프로덕션 환경의 함정
공식 문서에서는 또 한 가지 중요한 점을 지적합니다.
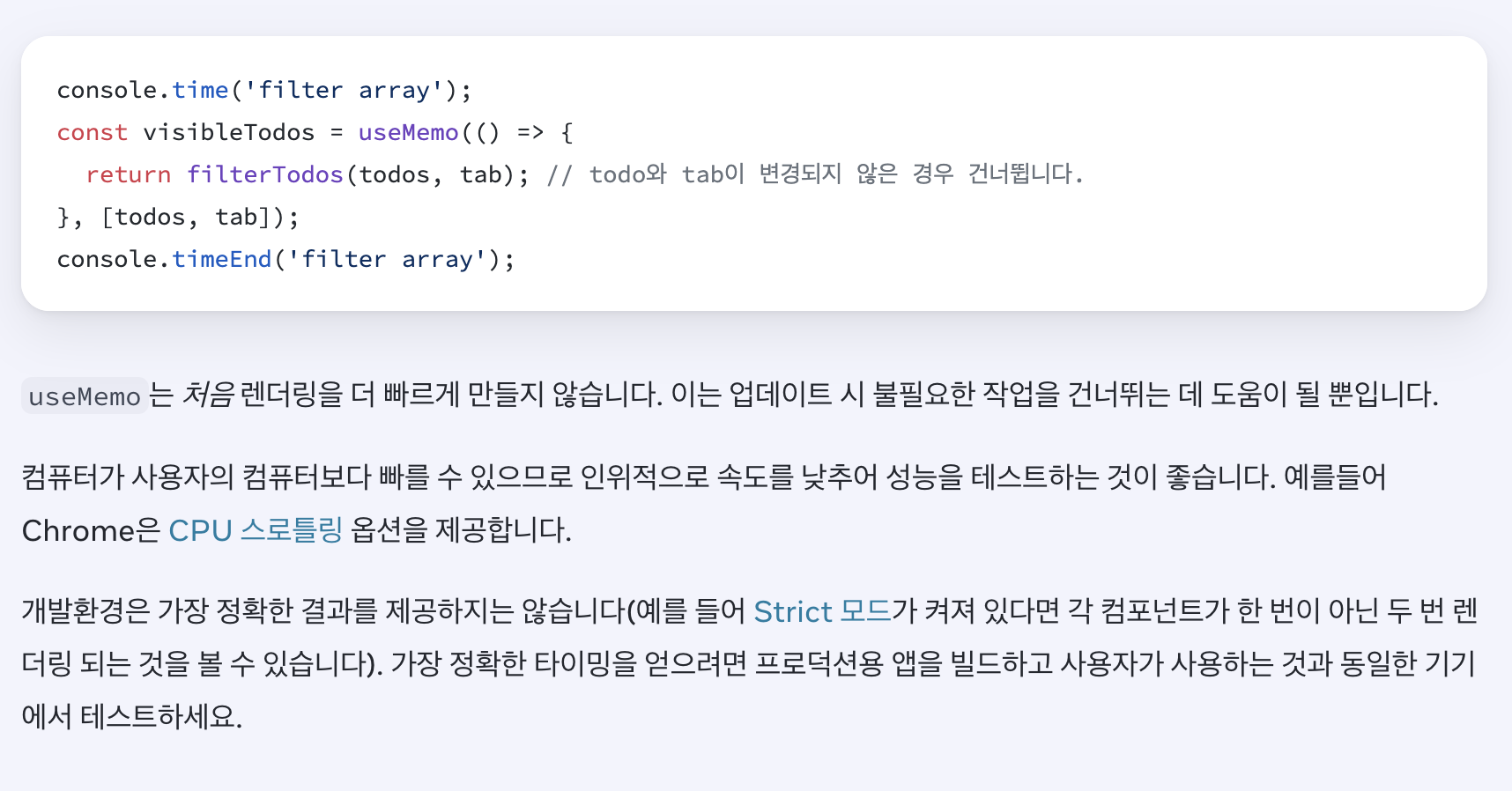
개발 환경에서의 측정 결과가 프로덕션과 다를 수 있다는 뜻입니다. StrictMode로 인해 의도적으로 초기 렌더링을 두 번 수행하기 때문입니다. 개발자의 코드가 순수하고 안전하게 동작하는지 검증하기 위한 목적이지만, 이로 인해 useMemo나 useCallback의 성능 효과를 제대로 체감하기 어렵습니다.
반면, 프로덕션 빌드에서는 StrictMode가 제거되고, 코드 압축 및 최적화가 적용되므로 실제 성능을 제대로 반영합니다. 따라서 공식문서에서는 개발환경의 측정 결과가 정확하지 않을 수 있음을 이야기하고 있습니다.
그럼 어느 경우에 useCallback, useMemo를 사용하실 건가요?
저는 함수나 계산이 실제로 성능에 영향을 준다는 명확한 정량적 근거가 없거나, useEffect의 의존성 관리의 목적이 아니라면, useCallback과 useMemo사용을 지양하려고 합니다. 다음은 이를 좀 더 구체화한 기준입니다.
useCallback
- 자식 컴포넌트에서 React.memo를 사용하고 있으며, 함수 props가 자주 새로 생성되어 불필요한 리렌더링을 유발하는 경우
- 해당 함수가 useEffect의 의존성 배열에 포함되어 있고, 함수 참조 변경으로 인해 의도치 않은 effect 재실행이 발생할 수 있는 경우
onScroll,onResize,onDrag등 성능에 민감한 DOM 이벤트 핸들러를 props로 자식 컴포넌트에 전달하는 경우
useMemo
- 데이터 배열이 20개 이상이고, 연산이 정렬/필터/맵핑 등으로 중첩되어 있을 때
- 불변성을 유지해야 하는 객체를 의존성 배열에 넣어야 하는 경우
- 복잡한 객체를 생성하여 자식 컴포넌트에 prop으로 전달할 경우 (객체 주소 변경에 의한 리렌더 방지 목적)
- 동일한 계산이 여러 위치에서 반복적으로 사용될 경우
정량화된 기준
공식문서에서 이야기하는 눈에 띄게 느린 계산이라는 표현이 저는 너무 모호하게 느껴졌습니다. 그래서 저만의 구체적인 수치 기반 기준을 정의했습니다.
1. 시간 기준 (console.time, performance.now(), Profiler 사용)
- 0.1ms 미만: 최적화 불필요
- 0.1ms - 1ms: 데이터 크기와 복잡도에 따라 판단
- 1ms 이상: 반드시 최적화 고려
2. 데이터 크기 기준
- 배열 길이 < 20: 최적화 보류
- 배열 길이 20-100: 복잡한 연산만 최적화
- 배열 길이 > 100: 적극적 최적화
3. 연산 복잡도 기준
이러한 연산 복잡도 예시는 제 개인적인 판단 기준입니다. 단순한 연산은 메모이제이션의 이점을 누리기 어렵기 때문에 제외하고, 중간 이상의 연산과 데이터 크기가 커질 경우 최적화를 고려하려 합니다.
단순
.filter(item => item.active)
.map(item => item.name)중간
.filter(item => complexCondition(item))
.map(item => ({ ...item, computed: calculation(item) }))복잡
.filter(item => item.tags.some(tag =>
searchTerms.every(term => tag.includes(term))
))
.map(item => ({
...item,
score: calculateRelevanceScore(item, filters),
highlights: generateHighlights(item.content, searchTerms)
}))
.sort((a, b) => complexSortAlgorithm(a, b))그 이상의 경우에는 오히려 혼란을 초래할 수 있고, 실제로 유의미하지 않은 최적화일 수 있다는 점을 느꼈습니다. 정말로 useCallback 하나로 성능 최적화가 이뤄질까?라는 질문에 대해, 실제로 성능을 측정하고 수치적으로 유의미한 차이가 입증되지 않는 한, 사용을 자제하는 것이 더 나은 선택이라는 생각이 들었습니다.
공식문서에서도 “함수를 useCallback으로 감싸는 것은 특정한 경우에만 가치가 있다.”고 명시하고 있습니다. 이 문장을 접하면서 저 역시도 무조건적인 사용보다는 맥락과 수치 기반 기준에 따라 제한적으로 적용하는 것이 바람직하다고 생각하게 되었습니다.
마치며
이번 비교를 통해 저는 useCallback과 useMemo는 단순히 “성능 최적화 도구”로서가 아니라, 명확한 조건과 맥락 속에서만 의미 있는 전략이라는 점을 다시 한 번 실감했습니다. 오히려 무분별한 사용은 코드 복잡도와 유지보수 비용만 높일 수 있음을 확인했습니다.
실제로 성능 병목은 예상 밖의 단순한 부분에서 발생하는 경우가 많습니다. 그렇기에 직관보다는 측정 가능한 수치와 정량적 기준을 우선시하며, 필요한 경우에만 최적화를 시도하는 접근이 바람직하다고 생각합니다. 결국 중요한 질문은 “이 최적화가 정말 사용자 경험에 유의미한가?”, “향후 이 코드를 읽을 개발자가 쉽게 이해할 수 있는가?”일 것입니다.
앞으로도 저는 성능 최적화를 시도하기 전, 명확한 정량적 기준과 맥락 분석을 먼저 수행하고, 직관보다 근거에 기반한 선택을 하려 합니다. 이러한 기준을 토대로, 단순히 기술을 사용하는 개발자가 아니라, 기술의 맥락을 이해하고 선택할 수 있는 개발자로 성장하고 싶습니다. 👽
번외: 진짜 성능 병목은 어디에 있을까요??
사실 제가 실제 프로젝트에서 가장 많이 맞닥뜨린 병목은 다음과 같은 부분이었습니다.
- 이미지 최적화 부족
- 크기 조절 없이 업로드된 원본 이미지, WebP 미지원, lazy loading 미적용 등
- Lighthouse에서 TTI(Time To Interactive)와 LCP(Largest Contentful Paint)에 큰 영향
- 불필요하게 커진 번들 크기
- lodash, moment 등 무거운 라이브러리를 tree shaking 없이 import
- route-based code splitting 미적용
- 불필요한 API 호출
- 컴포넌트 리렌더링 시마다 발생하는 fetch 요청
- useEffect cleanup 미흡
- 불필요한 useEffect 호출
- 의존성 배열을 정확히 설정하지 않아 매 렌더마다 실행됨
- 리팩토링하면 제거 가능한 side effect들이 다수 존재
- Re-render 트리거 과다
- 상태 구조가 비효율적으로 설계되어 하위 컴포넌트가 자주 불필요하게 리렌더됨
- Context 사용 시 memoization 누락
오히려 이런 부분들이 성능을 개선시킨다고 생각합니다. 따라서 성능 최적화를 하고 싶다면, useMemo/useCallback보다는 위 다섯가지에 집중하는 것이 좋지 않을까 생각합니다!
Profiler를 사용하는 방법은 현버전 리액트 공식문서보다는 전버전이 훨 잘 설명해줍니다!
https://legacy.reactjs.org/blog/2018/09/10/introducing-the-react-profiler.html


좋은 글 감사합니다~