
이 글의 목적은 유튜브 API와 Pandas 라이브러리를 활용해 문제를 해결한 과정을 기록하기 위함입니다.
본문의 API Test시 파라미터로 넘겨준 Youtube channelId와 playlistId는 Amazon Web Services 유튜브 채널을 예시로 들었습니다!
💻 인턴생활
지난 4월 전역을 하고 어쩌다보니 5월부터 처음으로 인턴을 하게되었다. 사실 직원분들에 비해 잘 할수 있는 일이 많지 않았기에 내게 주어진 테스크들은 크리티컬 하지는 않았다. 그럼에도 아무리 작은 사이즈의 업무일지라도 의미를 찾고자 했다. 이 업무를 왜 하는지, 어떻게 하면 효율적이게 처리할지, 어떻게 하면 의미있게 처리할 수 있을지 고민을 했다.
그러던 중 인턴 패널을 담당하시는 상무님께서 내게 작은 Task를 맡기셨다. 어떤 Task였냐 하면...
본사 유튜브채널에 올라와있는 동영상을 엑셀 파일로 리스트업 하기
- 제목
- 날짜
- 간략한내용(description)
- 재생목록명(없으면 None)
- 링크
너무 단순한 업무였지만 동영상 개수를 확인해보니 600개가 넘어갔다. 또 특정 재생목록에 속한 동영상은 재생목록 태그도 달아줘야 했다. 수작업으로 600개가 넘는 동영상을 하나하나 클릭해가며 엑셀에 복사 붙여넣기를 할 수 있지만... 분명 지치고 현타가 올 것 같았다 🥺
좀 더 쉽게 해결할 수 있는 방법이 없을까?
📺 Youtube Data API
처음에 생각한 방법은 크롤링이었다. 하지만 아직 크롤링을 해본 경험이 없고 단순한 업무를 처리하는데 공부시간이 더 걸릴 것 같아서 패스.
조금 더 구글링을 해보니 Google Developers에 Youtube API가 있었다! 유튜브 관련 검색이나 채널 정보를 얻는 등 다양한 기능을 지원한다.
그 중에서 요 아래 두가지 REST API를 적절히 활용하면 금방 리스트업을 할 수 있을 것 같다.
Search:list API
파라미터로 channelId를 넘겨주면 채널에 업로드된 동영상 정보를 얻을 수 있다
GET https://www.googleapis.com/youtube/v3/search
PlaylistItems: list API
파라미터로 playlistId를 넘겨주면 재생목록에 업로드된 동영상 정보를 얻을 수 있다
GET https://www.googleapis.com/youtube/v3/playlistItems
먼저 Postman을 사용해서 API Test를 해보려 했다. 하지만 예상대로 바로 원하는 응답을 받지는 못했다.
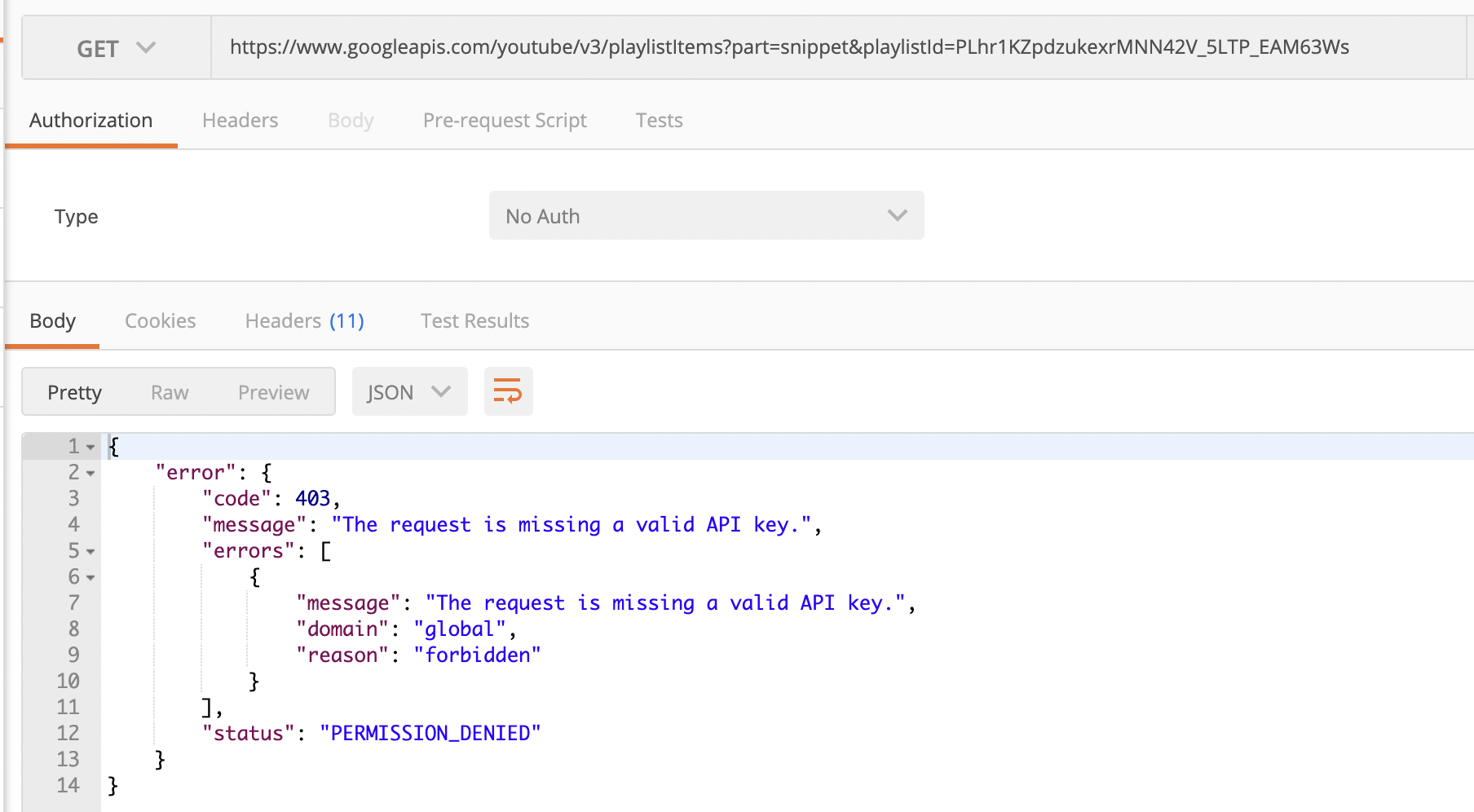
에러 메세지를 보니 API Key가 필요하다고 나온다. 바로 구글링을 했고 API Key를 발급받는 방법을 찾아냈다.
Youtube API를 제공하는 Google의 Google Cloud Platform에 접속해 YouTube Data API v3 사용을 위한 사용자 API Key를 손쉽게 발급받을 수 있다.
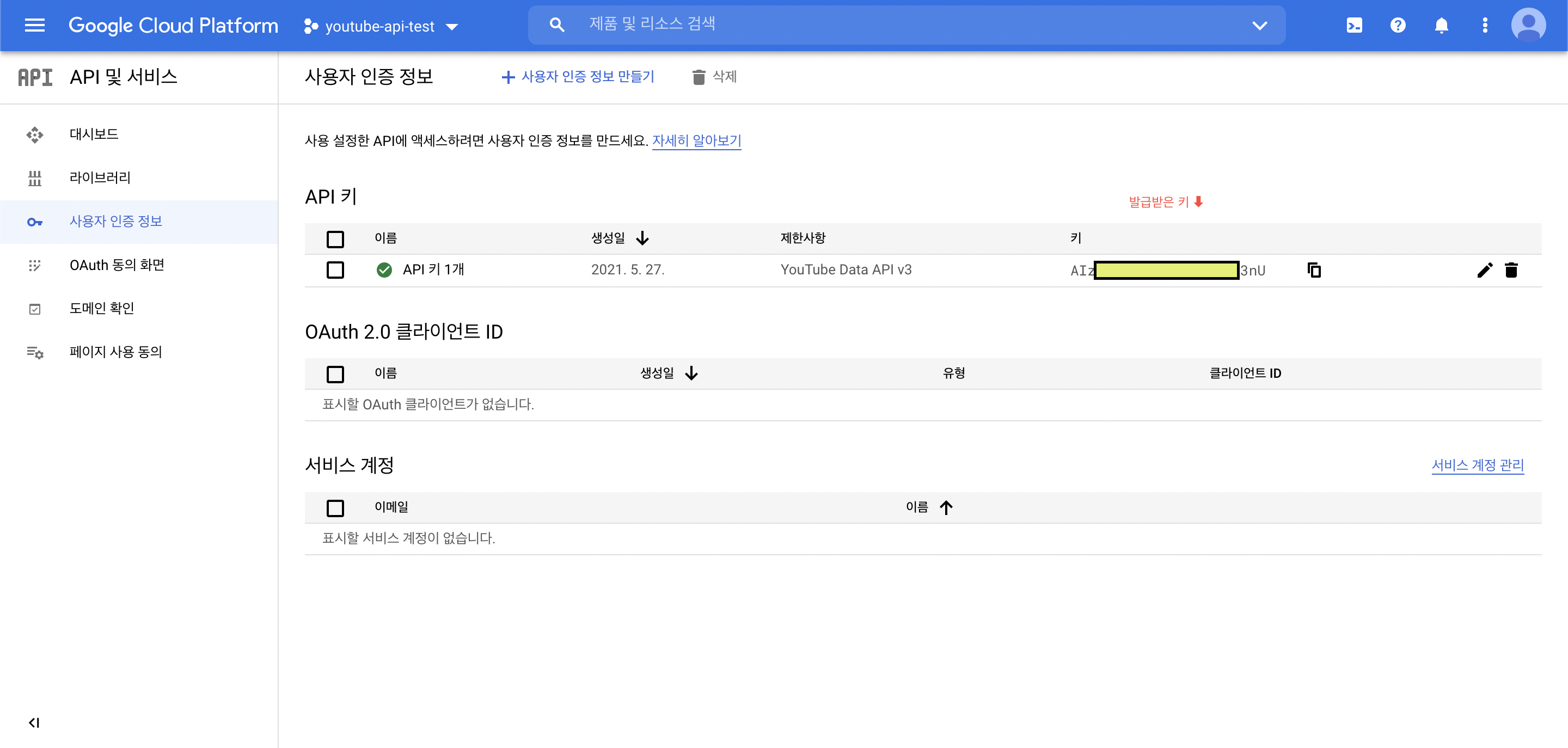
API Key값을 복사해서 파라미터로 추가하여 Request를 날려보면?
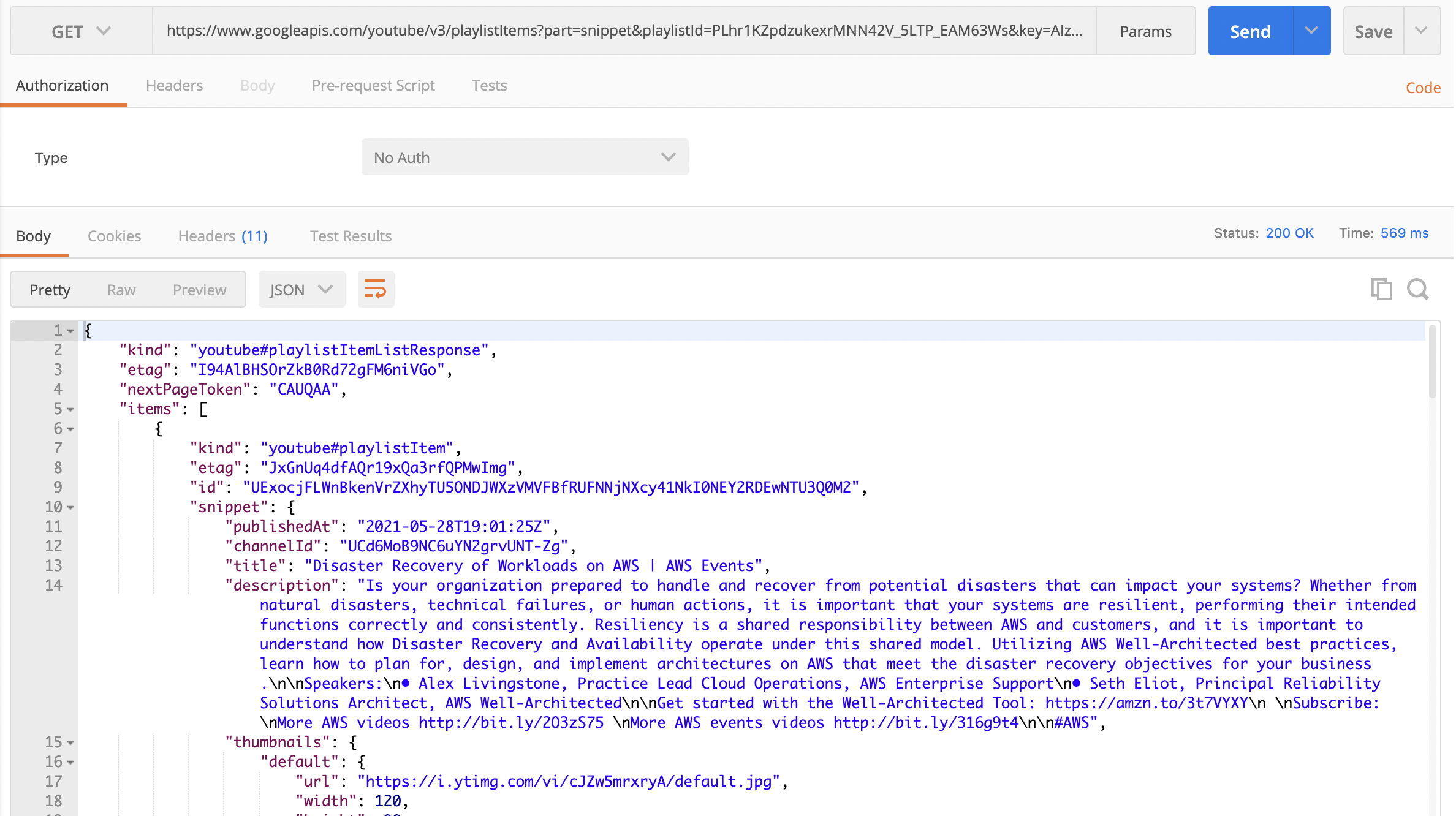
보이는 것과 같이 Status Code 200과 함께 기깔나게 Response를 받게 된다. 그렇다면 이 JSON Response를 어떻게 엑셀로 정리하지...?
📊 Python의 Pandas를 이용한 데이터 처리
군생활을 할 때 프론트엔드, 백엔드, 앱개발, 머신러닝, 딥러닝 등등... 이것 저것 수박 겉핥기 식으로 공부한 기억이 있다. 머신러닝 공부를 하면서 Python을 처음 접하게 되었는데, Jupyter 환경에서 Pandas와 같은 데이터 분석 라이브러리를 사용하면 간단한 코드 몇줄로 효과적인 데이터 처리를 할 수 있다는 것을 알게 되었다. 최근에는 블록체인, 클라우드 기술에 관심이 생겨 공부를 하는 중이라 머신러닝, 데이터분석&처리 공부를 후순위로 뒀는데... 공부했던 내용을 복기하며 손에 익힐 겸 좋은 기회라 생각해서 Jupyter을 실행시켰다!
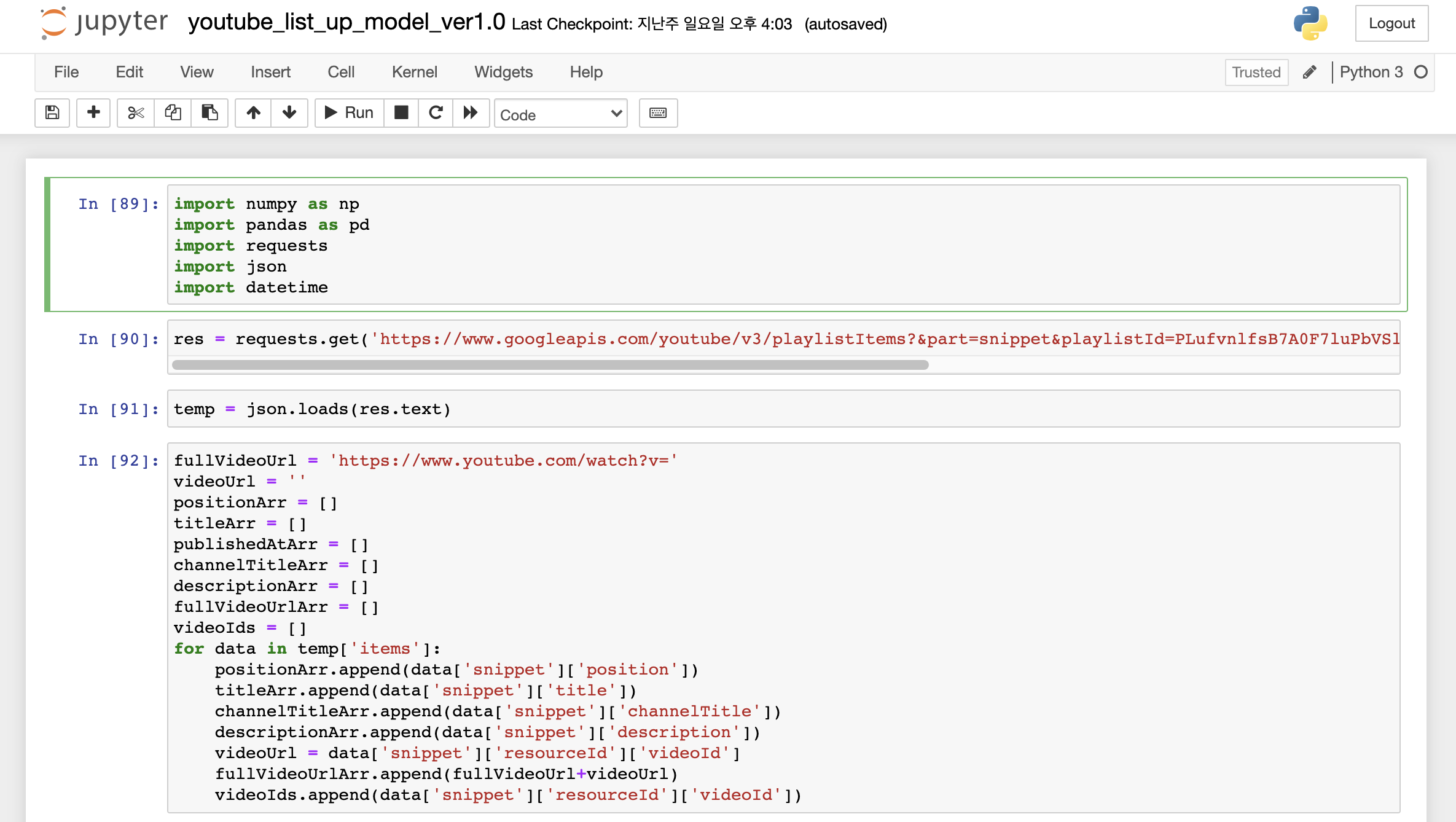
첫 시도에서 정말 간단한 로직으로 리스트업 하는 모델을 만들었다.
- Playlist API를 호출해 JSON Response를 받는다
- for문으로 JSON내 배열을 순회하여 필요한 정보를 Array에 Append한다
- Pandas Dataframe을 만들고 column별로 Array를 넣는다
- csv or excel 파일로 저장한다
- 끝
생성된 재생목록의 playlistId를 가져온 뒤, 재생목록 개수만큼 API를 호출하여 엑셀 파일을 만든 뒤 나중에 합치려고 했다. 그러나 몇가지 문제점이 보였다.
문제점
1. 업로드 날짜에 해당하는 publishedAt은 동영상 업로드 날짜가 아닌 재생목록에 추가된 날짜다
2. publishedAt은 iso8601 형식의 String이라 yyyy-mm-dd로 바꿔야한다.
3. 재생목록에 없는 동영상은 처리할 수 없다
💡 문제해결 과정
1. 업로드 날짜 파악하기
Playlist API 문서를 살펴보니 snippet.publishedAt은 영상 업로드 날짜가 아닌 재생목록에 추가된 날짜 및 시간 라고 나와있다. API 문서와 JSON Response를 아무리 살펴봐도 영상이 업로드된 날짜는 나와있지 않다. 이 API만으로는 원하는 정보를 얻을 수 없다... 😂
대신 Search API 문서를 살펴보니 채널에 올라온 모든 영상에 대한 snippet.publishedAt은 리소스의 작성 날짜 및 시간 이라고 나와 있었다. 실제로 API 테스트를 해보니 업로드 날짜 및 시간과 일치했다. 어쨋든 두 가지 API를 사용해야 한다. 남은 문제도 살펴보고 로직을 수정하기로 했다.
2. iso8601 -> yyyy-mm-dd
iso8601
iso8601은 날짜와 시간과 관련된 데이터 교환을 다루는 국제 표준이다.
형식 : YYYY-MM-DDThh:mm:ss.sZ
조금 삽질해대며 구글링 한 끝에 yyyy-mm-dd 형식으로 바꾸는 코드를 찾아내 적용했다.
# input
publishedAtStr = '2014-03-19T17:42:42Z'
temp = publishedAtStr[:-1] #뒤의 Z는 제거해야한다더라...
datetime.datetime.fromisoformat(temp).strftime('%Y-%m-%d')
# output
'2014-03-19'원하는 형식으로 잘 변환 된 줄 알았는데 한가지 문제가 더 생겼다. Z가 붙으면 UTC 시간대여서 한국 시간대 기준으로 업로드 날짜가 나타나지 않았다. 그 말은 2014-03-19T17:42:42Z가 아닌 2014-03-19T17:42:42+09:00 을 처리해 줘야 한다는 뜻이다. 그래서 또다시 코드를 수정했다.
# input
publishedAtStr = '2014-03-19T17:42:42Z'
temp = publishedAtStr[:-1]
tempDate = datetime.datetime.fromisoformat(temp)
tempTimeStamp = tempDate.timestamp() + 32400 # 한국 시간대 +09:00
datetime.datetime.fromtimestamp(tempTimeStamp).strftime('%Y-%m-%d')
# output
'2014-03-20'여기서 32400은 9x60x60으로 시차에 해당하는 9시간을 초로 나타낸 것이다. 좀 지저분하게 코딩하긴 했는데 결과는 제대로 나왔다 😎
3. 재생목록에 없는 동영상 처리
재생목록이 없는 영상들은 따로 묶여있는 리스트가 있을 줄 알았는데 없는 것 같다...
그 말은 Playlist API 로는 모든 동영상을 리스트업 할 수 없다. 따라서 Search API 를 통해 모든 동영상을 1차적으로 불러와야 한다. 그렇다면 Playlist API를 이용해서 재생목록을 구분해주는 작업은 어떻게 할까?
이를 해결하기 위해 다음과 같은 로직을 떠올렸다.
- Search API로 채널 내 모든 동영상을 불러와 Dataframe에 저장
- 재생목록에 대한 정보는 없기 때문에 모든 행마다 재생목록명에 대한 값을 'None'으로 입력
- 생성된 재생목록의 PlaylistId를 가지고 PlaylistId API 호출
- Response로 부터 재생목록에 속한 영상의 videoId들을 배열에 저장
- videoId가 방금 생성한 배열에 속하는 모든 행들을 Dataframe에서 검색, 재생목록명 값을 수정
- 생성된 모든 재생목록에 대해 3~5의 과정을 반복
🛠 로직 수정
1. Search API로 채널 내 모든 동영상을 불러오기
Search API를 사용하기 위해선 channelId를 url 파라미터로 넘겨줘야한다. 하지만 본사 유튜브 채널은 자체적으로 설정한 채널 url을 사용해 channelId를 바로 확인하기 어려웠다. 구글링을 통해 알아낸 방법은 유튜브 RSS URL 생성 서비스 였다. 채널 url을 입력하면 간편하게 channelId를 얻을 수 있다.
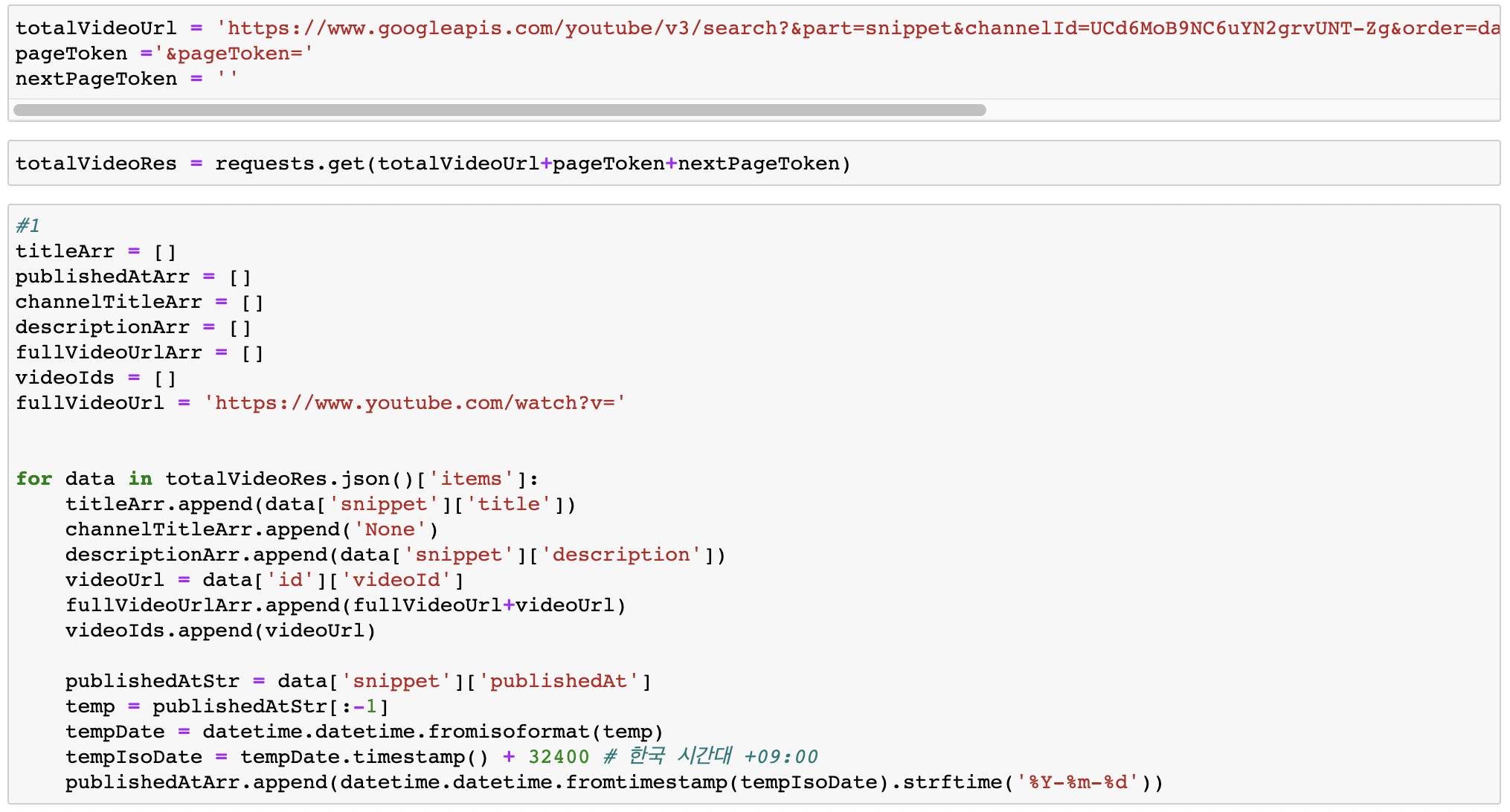
한가지 문제는 API를 한 번 호출할 때 최대로 받을 수 있는 동영상의 수가 50개다. 따라서 API Response중 nextPageToken이라는 값이 있는데, url 파라미터로 pageToken의 value로 이 값을 넘겨주면 51번째 동영상부터 해당하는 정보를 얻을 수 있다.
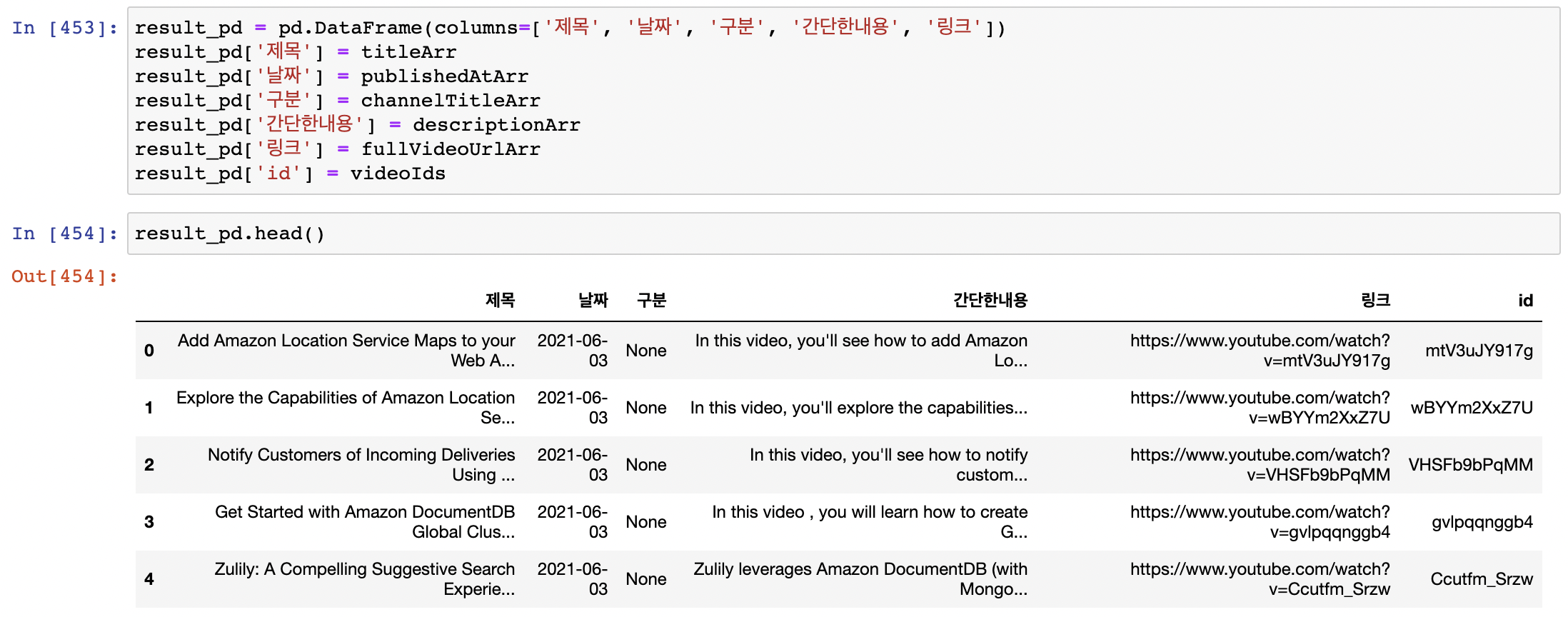
마지막 페이지에 도달할 때 까지 50개씩 끊어서 API를 호출하고, 필요한 정보들을 Array에 전부 append한 뒤 dataframe에 저장했다. 이 때, 구분(재생목록명)에 해당하는 값은 1차적으로 None으로 입력했다.
2. Playlist API호출 후 videoId 저장
채널상에 생성된 모든 재생목록의 playlistId를 모아놓고, playlistId url 파라미터로 넘겨 playlist API를 호출한다. 모든 재생목록 playlistId를 한번에 얻을 수 있는 방법이 있을 것 같은데, 나는 단순하게 재생목록을 클릭해서 id를 복사 붙여넣기 했다,,ㅎㅎ

어쨋든 가져온 playlistId를 위와 같이 파라미터로 넘겨 호출한 뒤, 해당 재생목록에 속한 videoId를 Array에 전부 append 했다.
3. Dataframe 조회 후 재생목록명 수정

요렇게 dataframe상에서 videoId Array의 값들과 일치하는 행들만 조회하여 재생목록명을 수정했다. 모든 재생목록들에 대해 위와 같은 방법들을 반복하면 작업이 끝난다 🎉
4. 엑셀로 저장
바로 엑셀파일로 저장을 했더니 일부 string이 이상하게 저장되었다. 따옴표(')같은 string이 &#number 형태로 표시되었다. 구글링을 해보니 몇몇 특정 캐릭터들은 표기의 혼란을 막기 위해 HTML상에서 특정한 규칙대로 표현이 된다고 나와있었다. 이를 HTML entity라고 한다. 이를 원래 캐릭터로 돌려놓는 코드는 구글링을 통해 여기를 참고하였다.
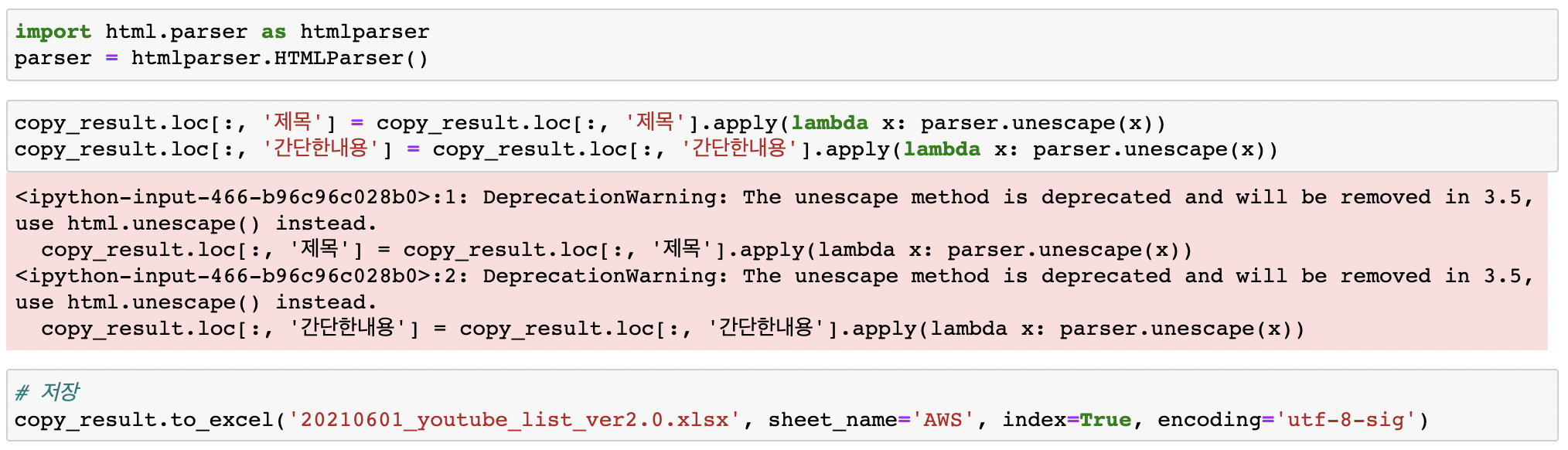
마지막 코드로 작업이 완료된 dataframe을 엑셀 파일로 저장한다. 이 때, encoding값을 위와 같이 지정해야지 한글이 깨지지 않고 정상적이게 보인다.
마무리
마무리한 엑셀파일을 상무님께 넘겨드렸다. 여기까지 하는데 투자한 시간을 보면 생각보다 오래 걸리긴 했지만 그래도 모르는 것도 알아가고 많은 것을 스스로 공부할 수 있었다. 다음에 비슷한 일을 할 순간이 온다면 그때는 좀더 빠르고 효율적이게 처리를 할 수 있을 것 같다. 이 글은 단순히 내가 문제를 해결한 과정을 기록한 글이지만, 이 글을 읽는 분들에게도 여러모로 도움이 되었으면 한다 🙃


작은 사이즈의 업무일지라도 의미를 찾고 쉽게 문제를 바꾼 부분이 정말 멋있네요