개요
| 항목 | 내용 |
|---|---|
| 기간 | 2024.04 ~ 2024.08 |
| 역할 | 백엔드 개발 |
개발 목표
- RDB 데이터 지원: RDB 테이블 데이터를 Graph DB로 자동 변환
- 데이터 통합: CSV + RDB 데이터를 통합하여 하나의 그래프로 모델링
- 시스템 통합: Admin-CMS와 Graphizer 통합으로 운영 효율화
아키텍처
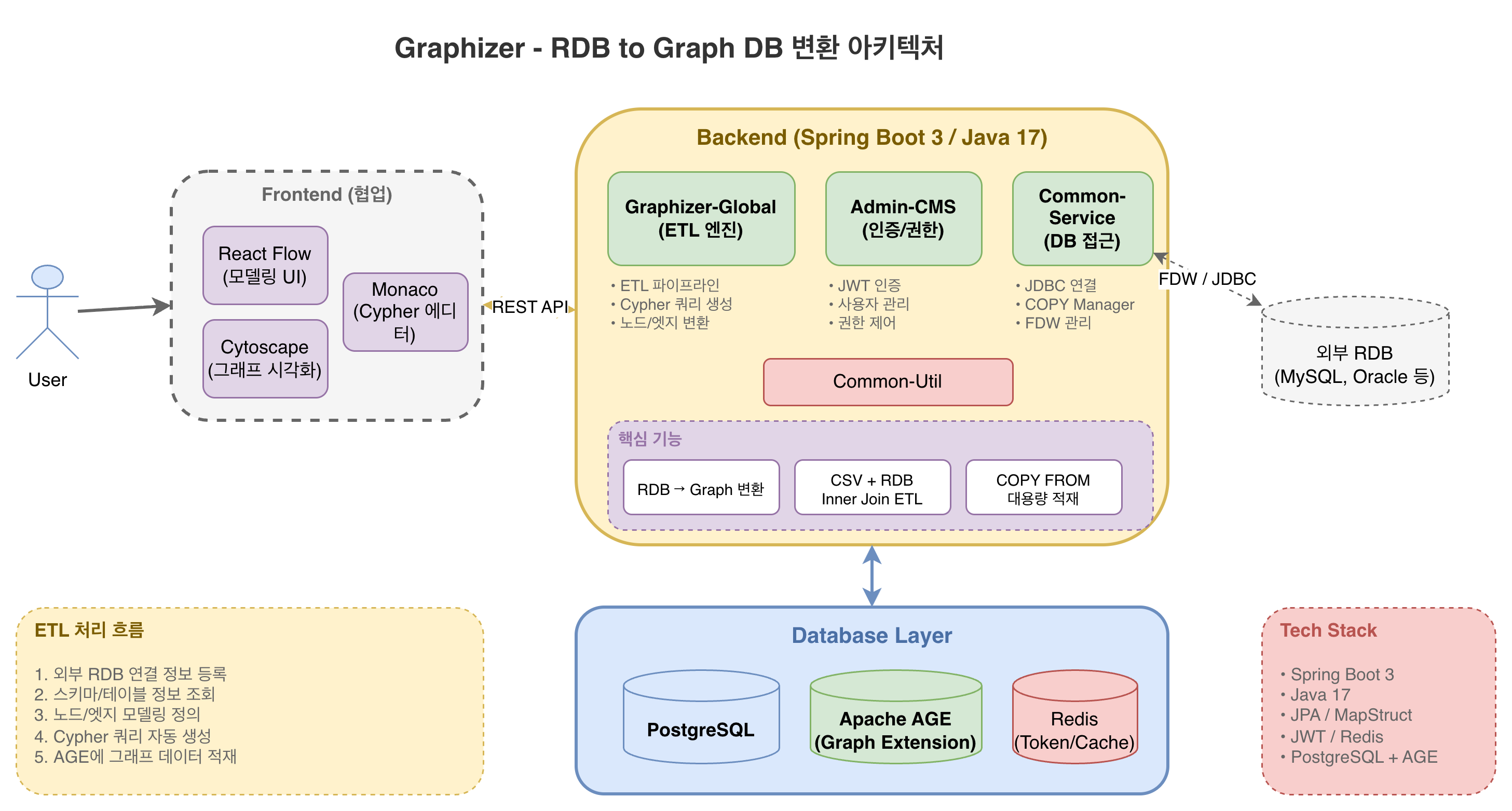
클릭하면 크게 볼 수 있습니다
내가 한 일
1. Gradle Multi-module 아키텍처 설계
Graphizer-Global(메인 ETL), Admin-CMS(인증/사용자), Common-Service(DB/파일), Common-Util(공통 유틸)로 모듈 분리
- 모듈 간 의존성 구조화로 코드 재사용성 향상
- 독립적 빌드/배포 가능한 구조
2. RDB → Graph DB 변환 ETL 파이프라인
Foreign Data Wrapper(FDW)로 원격 RDB 연결 → 스키마 분석 → 노드/엣지 메타데이터 생성 → Cypher 쿼리 자동 생성 → Apache AGE로 Property Graph 생성
3. 이기종 데이터 통합
CSV 데이터와 RDB 데이터를 Inner Join으로 병합, 프로퍼티 매핑으로 유연한 스키마 처리
4. 대용량 데이터 고속 적재
PostgreSQL CopyManager + BatchPreparedStatementSetter로 bulk insert 성능 최적화
5. 데이터 저장 구조 개선
Cytoscape JSON을 JPA @JdbcTypeCode(SqlTypes.JSON)로 DB에 직접 저장, RDB 파싱 오버헤드 제거
기술적 의사결정
Why Apache AGE?
| 선택지 | 장점 | 단점 |
|---|---|---|
| Neo4j | 성숙한 생태계 | 라이선스 비용, 별도 인프라 |
| ArangoDB | 멀티모델 | 학습 곡선 |
| Apache AGE ✓ | PostgreSQL 확장, 무료, 기존 인프라 활용 | 상대적으로 신규 |
→ 기존 PostgreSQL 인프라 활용 + 비용 절감 + Cypher 쿼리 지원
Why FDW (Foreign Data Wrapper)?
외부 DB 데이터를 PostgreSQL로 직접 덤프하지 않고, 실시간으로 접근하면서 ETL 처리를 하기 위해 사용했습니다.
| 방식 | 과정 | 단점 |
|---|---|---|
| 덤프 방식 | 외부 DB → CSV 추출 → PostgreSQL import → 변환 | 데이터 복제, 시간 소요, 동기화 문제 |
| API 방식 | 외부 DB → API 호출 → 데이터 가져오기 → 변환 | 네트워크 오버헤드, 구현 복잡 |
| FDW 방식 ✓ | 외부 DB ← PostgreSQL에서 직접 SELECT | 한 번에 처리 가능 |
FDW의 장점:
1. 데이터 중복 제거 - 외부 DB 데이터를 별도로 복사할 필요 없음
2. 실시간성 - 항상 최신 데이터 기반으로 그래프 변환 가능
3. SQL 통합 - PostgreSQL 문법으로 외부 DB 조회 + AGE 변환을 한 트랜잭션에서 처리
4. 구현 단순화 - 별도 ETL 도구(Spark, Airflow 등) 없이 DB 레벨에서 해결
-- 외부 MySQL 서버 등록
CREATE SERVER mysql_server
FOREIGN DATA WRAPPER mysql_fdw
OPTIONS (host 'xxx.xxx.xxx.xxx', port '3306');
-- 원격 테이블 생성
CREATE FOREIGN TABLE remote_customers (...)
SERVER mysql_server;
-- 이제 로컬처럼 조회 가능
SELECT * FROM remote_customers;FDW 단점:
- 네트워크 의존성이 있어 외부 DB가 느리면 쿼리도 느려짐
- 대용량 데이터는 한 번에 가져오기보다 배치 처리 필요
Why Gradle Multi-module?
- 공통 코드(
Common-Util,Common-Service) 중복 제거 - 모듈별 독립적 테스트/배포 가능
- 의존성 명확화로 순환 참조 방지
문제 해결 경험
문제 1: 대용량 CSV 적재 시 OutOfMemory
상황: 수백만 건 CSV 파일 로드 시 메모리 부족
해결:
// 스트리밍 방식으로 변경
try (BufferedReader reader = new BufferedReader(new FileReader(file))) {
copyManager.copyIn("COPY table FROM STDIN", reader);
}- 파일 전체를 메모리에 올리지 않고 스트리밍 처리
- PostgreSQL COPY의 파이프라인 활용
문제 2: 복잡한 FK 관계 → 엣지 변환
상황: 다중 FK, 복합 키를 가진 테이블의 관계 추출 어려움
다중 FK 문제 예시
-- 주문 테이블에 FK가 4개
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT REFERENCES customers(customer_id), -- 누가 샀는지
seller_id INT REFERENCES sellers(seller_id), -- 누가 팔았는지
shipper_id INT REFERENCES shippers(shipper_id), -- 누가 배송하는지
product_id INT REFERENCES products(product_id) -- 뭘 샀는지
);이 경우 엣지가 4개 필요:
Customer ──[PURCHASED]──> Order
Seller ──[SOLD]──> Order
Shipper ──[SHIPS]──> Order
Order ──[CONTAINS]──> Product문제점:
- FK 컬럼명만 보고는 엣지 라벨(
PURCHASED,SOLD등)을 자동 판단 불가 - 엣지 방향도 FK만으로는 알 수 없음
- 하드코딩하면 테이블마다 로직이 달라져 유지보수 불가
해결: 메타데이터 레이어 분리
기존: 테이블 스키마 → 바로 Cypher 생성 (예외 처리 복잡)
개선: 테이블 스키마 → 메타데이터 저장 → Cypher 동적 생성// 각 FK별 엣지 정보를 메타데이터로 저장
LabelInfoDto.builder()
.labelName("PURCHASED") // 엣지 라벨명
.sourceLabel("Customer") // 시작 노드
.targetLabel("Order") // 끝 노드
.fkColumn("customer_id") // 어떤 FK인지
.direction("INCOMING") // 방향
.build();-- 메타데이터 기반으로 동적 생성된 Cypher
MATCH (source:Customer), (target:Order)
WHERE source.customer_id = target.customer_id
CREATE (source)-[:PURCHASED]->(target)장점:
- 새로운 FK 패턴이 와도 메타데이터만 추가하면 됨
- UI에서 사용자가 라벨명, 방향 커스터마이징 가능
- 디버깅 시 메타데이터 테이블 조회로 매핑 상태 확인 가능
성과
- 데이터 소스 확장: CSV only → CSV + RDB (MySQL, PostgreSQL, Oracle)
- 처리 속도: Cytoscape 파싱 오버헤드 제거로 저장/로드 시간 단축
- 운영 효율: 2개 시스템 → 1개 통합 시스템으로 배포/관리 단순화
Tech Stack
| 분류 | 기술 |
|---|---|
| Backend | Spring Boot 3, Java 17, JPA, JWT, MapStruct |
| Database | PostgreSQL, Apache AGE, Redis |
| Build | Gradle (Multi-module) |
회고
잘한 점
- Multi-module 구조로 코드 재사용성과 유지보수성 확보
- AGE + FDW 조합으로 인프라 비용 절감 및 구현 단순화
아쉬운 점
- 해당 제품에 온전히 몰두할 수 없는 환경이었음. 더 집중할 수 있었다면 더 좋은 퀄리티의 제품을 만들 수 있었을 것
- WebSocket으로 ETL 진행률 전송은 구현했으나, ETL 작업 자체를 Kafka 등 메시지 큐로 비동기 처리하지 못한 점. 대용량 작업 시 서버 부하 분산과 작업 재시도 처리가 가능했을텐데 구현할 수 없었다.
배운 점
- Graph DB 모델링과 Cypher 쿼리
- PostgreSQL 확장 기능 활용 (AGE, FDW, COPY)
- 대용량 데이터 처리 최적화 기법
