
0902 실습 복습
Regression: 출력층에 따로 activation function을 지정해주지 않는다.
🤔 Regression에서 activation function을 지정해주지 않으면?
default값인 linear가 사용되고 linear는 입력받은 값을 그대로 반환한다.
🤔 아래 사진을 보고 회귀 모델이라는 것을 어떻게 알 수 있을까?

loss 에 손실함수를 작성하게 되면 회귀인지 분류인지 알 수 있다.
💡
분류에서도 activation 지정하지 않아도 loss 를 보고 판단하게 됩니다.분류 문제는 binary, 멀티클래스인지 명시적으로 지정해 주는게 좀 더 코드를 읽고 해석하기 좋습니다. 되도록이면 혼란을 줄이기 위해 명시적으로 지정해 주세요.
✅ optimizer는 문자열로 지정해서 사용할 수도 있지만 메서드를 불러 사용하면 learning rate를 지정해서 사용할 수 있다.
optimizer = tf.keras.optimizers.Adam(0.001) # learning rate 지정합성곱 신경망 (Convolutional Neural Network, CNN) 실습
실습파일: https://www.tensorflow.org/tutorials/images/cnn
CNN explainer: https://poloclub.github.io/cnn-explainer/
💡 핵심 키워드: Conv, Pooling(Max), CNN + DNN
🤔 DNN을 사용할 때의 입력과 CNN을 사용할 때 입력의 차이?
input_shape(이미지 높이, 이미지 너비, 컬러 채널)
DNN은 1차원을 입력하는 반면 CNN은 3차원을 입력해 flatten이 필요없다.
📌 합성곱 층 만들기
model = models.Sequential()
model.add(layers.Conv2D(filters=32, kernel_size=(3, 3),
activation='relu', input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
model.add(layers.Conv2D(filters=64, kernel_size=(3, 3), activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
model.add(layers.Conv2D(filters=64, kernel_size=(3, 3), activation='relu'))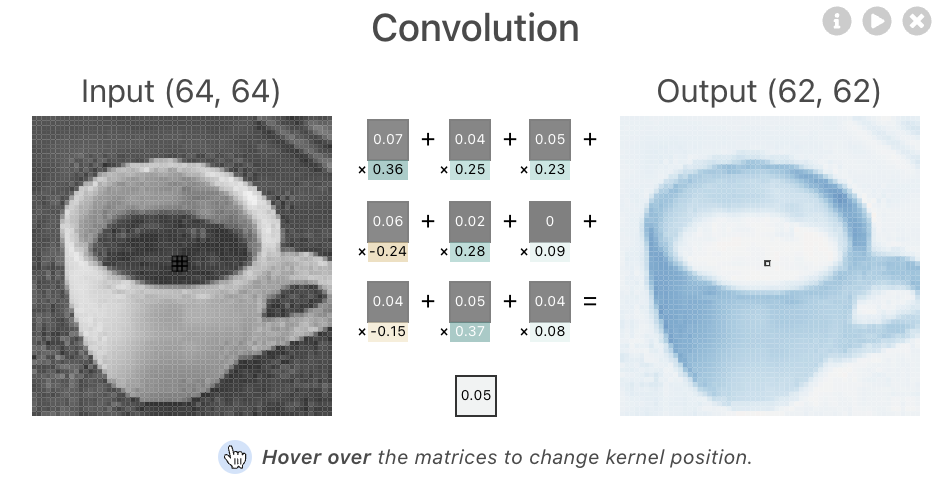
출처: https://poloclub.github.io/cnn-explainer/
🤔 위 사진에서 알 수 있는 kernel_size는?
(3, 3)
🤔 합성곱 신경망의 별명은 피처 자동 추출기인데, 어떻게 피처를 자동으로 추출할까?
필터(filters)를 랜덤하게 여러 장 만든다. 각 필터의 사이즈는 kernel_size로 정한다. 필터를 이미지에 통과시켜서 합성곱 연산을 하여 결과가 나오면 그 결과로 특징을 추출한다.
필터에는 랜덤하게 만들다 보면 1자 모양도 있을 수 있고 대각선 모양도 있을 수 있고 ㅇ, ㅁ 이런 여러 패턴을 랜덤하게 만들 수 있다. 그리고 그 패턴을 통과시켜서 그 패턴이 얼마나 있는지 확인해 볼 수 있다.
- 이런 패턴을 여러 장 만든다 == filters
- 각 필터의 사이즈 == kernel_size
📌 하이퍼 파라미터
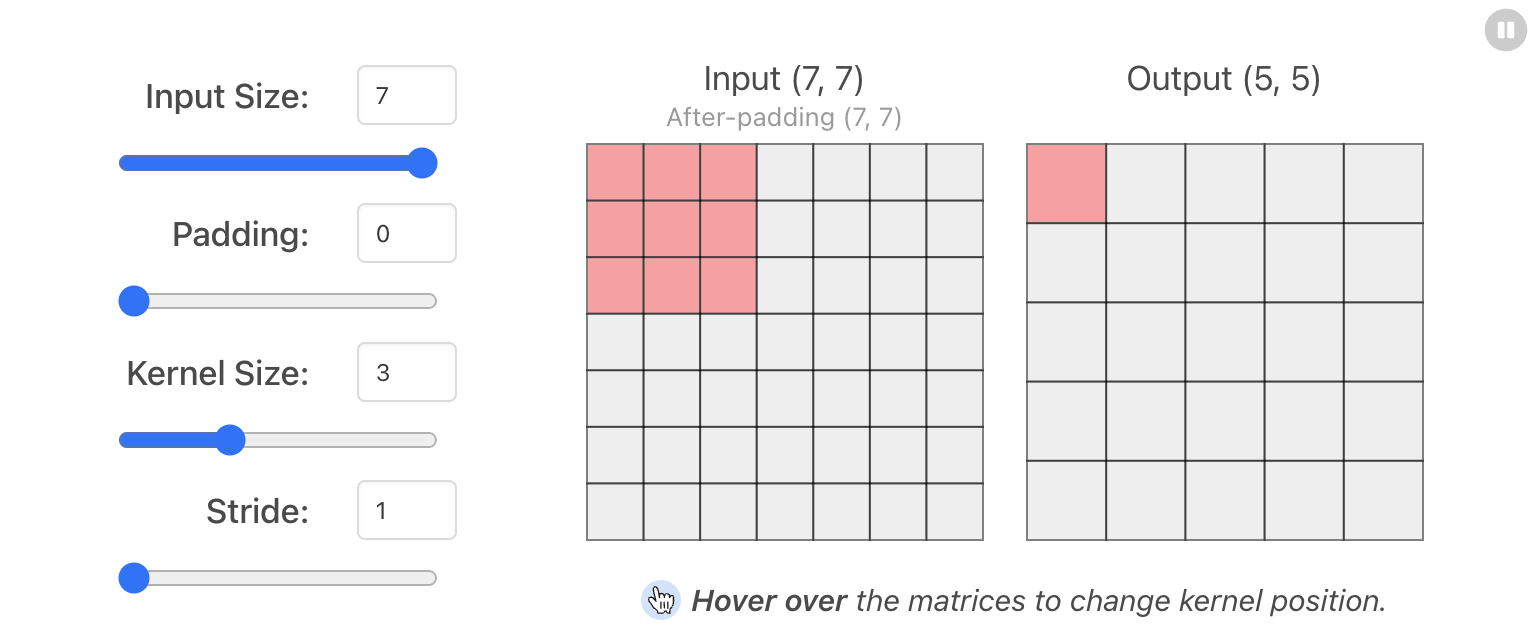
출처: https://poloclub.github.io/cnn-explainer/
🤔 Padding을 사용하는 이유?
이미지가 줄어드는 것을 방지하기 위해 사용하기도 하지만 가장자리 모서리 부분의 특징을 좀 더 학습할 수 있다.
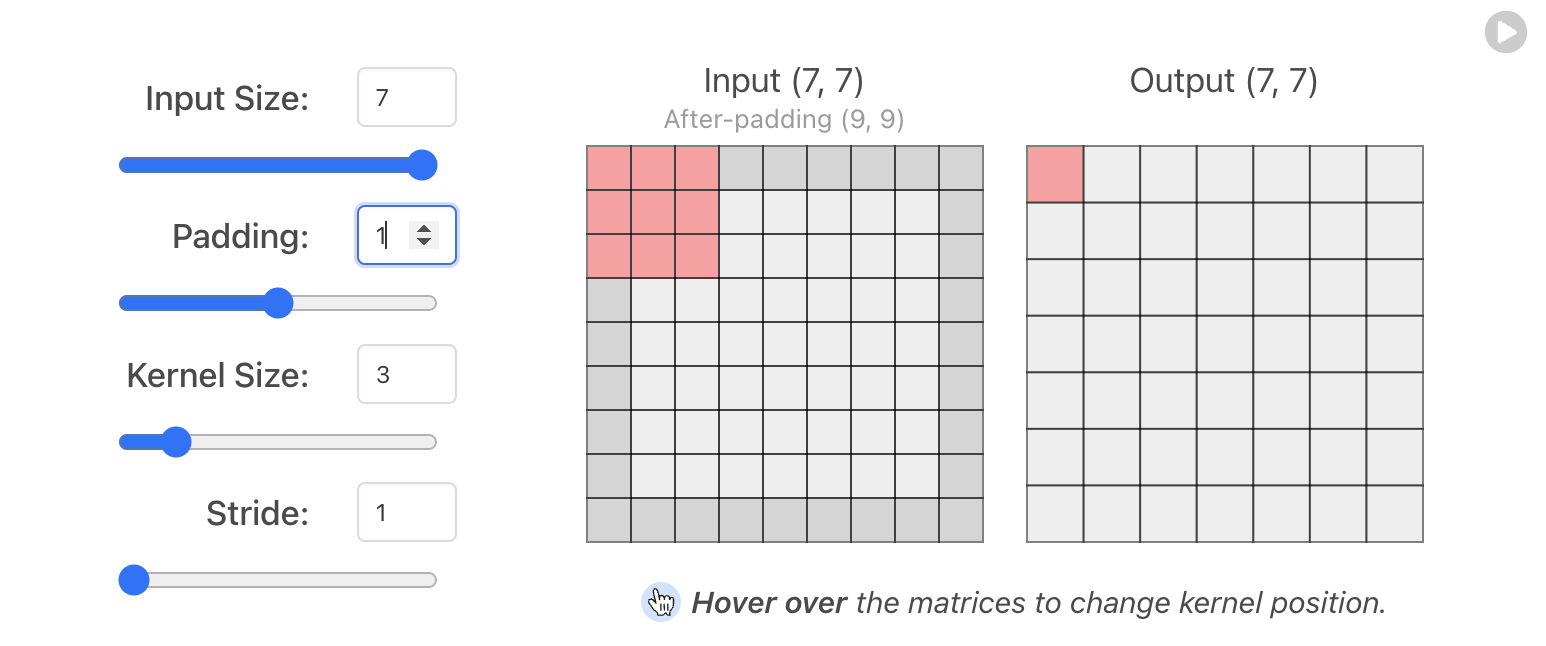
출처: https://poloclub.github.io/cnn-explainer/
- padding: 가장자리에 모서리 추가 (짙은 회색 부분)
입력 데이터의 외각에 지정된 픽셀만큼 특정 값으로 채워 넣으며 보통 0으로 값을 채운다.
padding="valid": padding을 사용하지 않겠다. (=유효한 영역만 출력하여 출력 이미지 사이즈는 입력 사이즈보다 작게 만들고 싶을 때 사용)
padding="same: 출력값이 줄어들지 않고 입력값과 출력값을 같게 출력 - kernel_size: dimensions of the sliding window over the input (핑크색 부분)
- stride: 보폭과 같은 개념
💡 자주 사용되는 하이퍼 파라미터 셋
padding == 1, kernel_size == 3
padding을 1로 kernel_size를 3x3 으로 사용하면 입력과 출력값이 같아진다.
kernel_size는 주로 홀수를 사용한다.
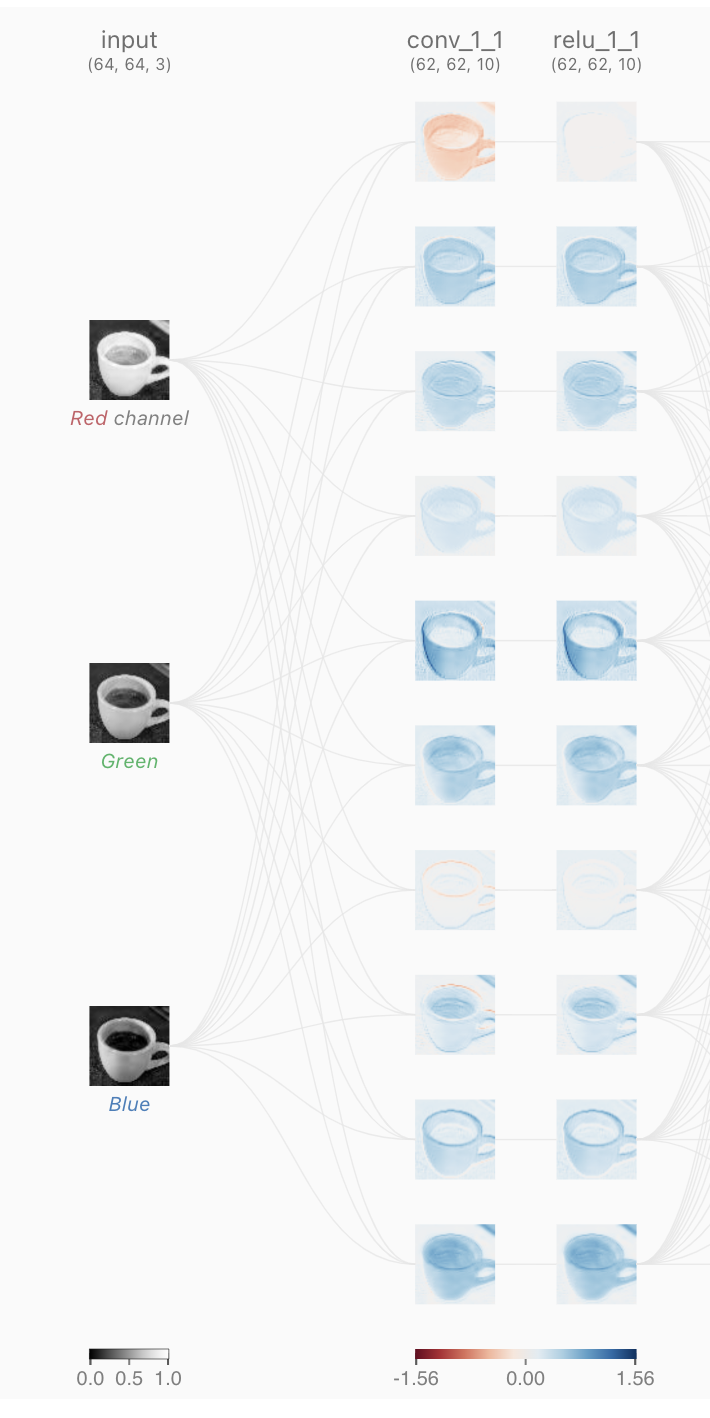
🤔 필터(filters)를 몇 개 사용했을까요?
10개

숫자들의 의미:
(height, width, filters)
3 번째 숫자 == 필터의 개수
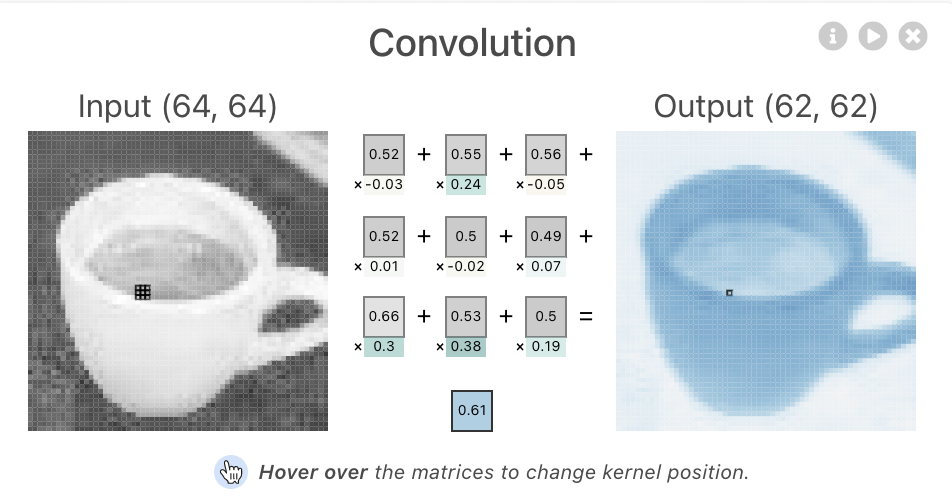
🤔 Convolution한 결과를 무엇이라고 부를까?
피처맵
🤔 피처맵을 만드는 이유?
컨볼루션 필터 크기만큼의 피처맵을 생성하기때문에 입력데이터의 지역 특성을 학습한다. 또한 컨볼루션 필터의 가중치를 공유하기때문에 학습된 특징이 나타나면 위치에 상관없이 인식한다. (학습된 특징에 대한 패턴을 매칭하는 것)
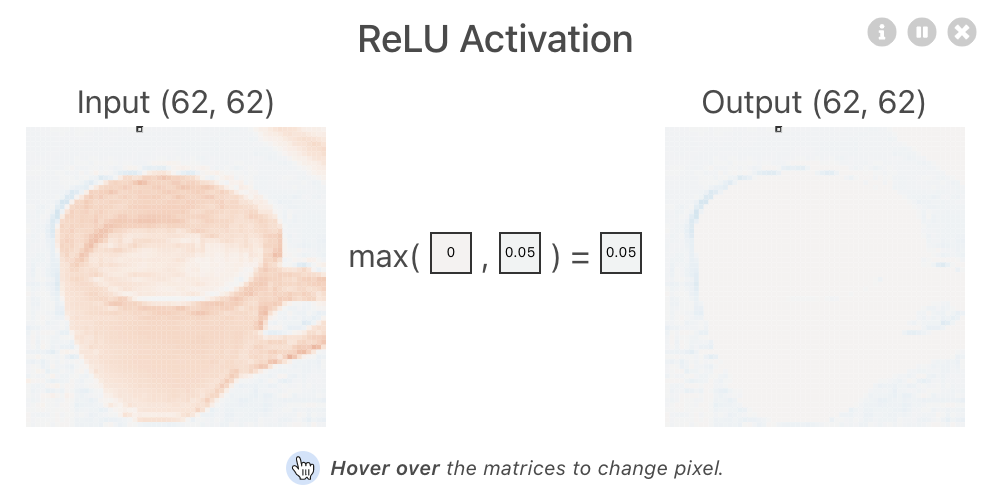
🤔 피처맵이 relu 활성화 함수를 통과한 것은 무엇일까?
활성화 함수를 통과한 것을 액티베이션맵이다.
📌 Pooling
: 합성곱 층에서 받은 최종 출력 데이터(Activation Map)의 이미지 크기를 줄여 이미지를 추상화 해주기 때문에 계산을 효율적으로 하고 데이터를 압축하는 효과가 있기 때문에 오버피팅을 방지
- 데이터의 사이즈를 줄여주며 노이즈를 상쇄시키고, 미세한 부분에서 일관적인 특징을 제공
- 보통은 합성곱 과정에서 만들어진 특징(feature)들의 가장 큰 값들만 가져와 사이즈를 감소 (Max-pooling)
- 대체적으로 컬러이미지에서는 MaxPooling을, 흑백이미지에서는 Min Pooling을 많이 사용하는 편
💡 풀링 레이어를 처리하는 방법:
- MaxPooling: 가장 큰 값을 반환
- AveragePooling: 평균 값 반환
- MinPooling: 최솟값 반환
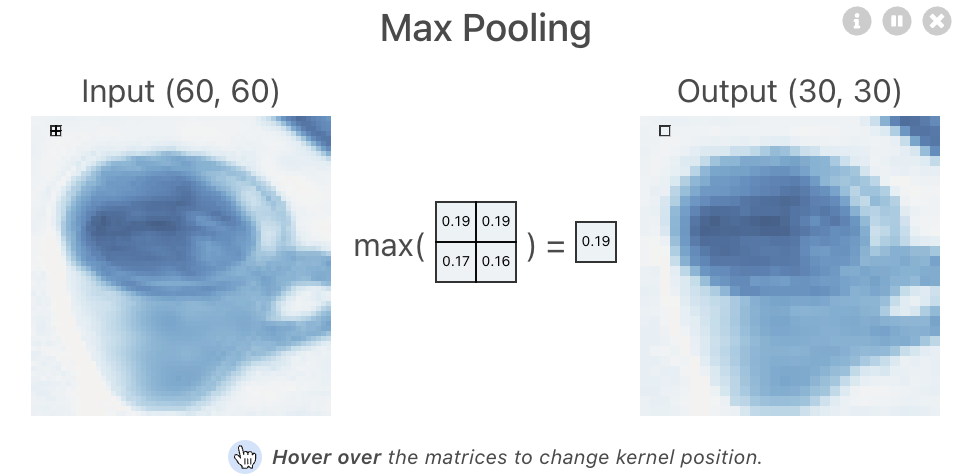
🤔 MaxPooling을 적용하면 어떻게 달라지나?
행렬의 크기가 줄어들고, 해상도가 낮아져 추상화 된다.
🤔 MaxPooling 을 적용하면 어떤 효과가 있을까?
과대적합을 예방하고 계산의 효율성을 높인다.
📌 Summary
1) Convolution 연산을 하면 필터(filters, kernel_size에 해당하는 filters 개수만큼)를 통과시켜서 filters 개수만큼 피처맵을 생성합니다.
=> CNN 의 별명이 피처자동추출기 이기도 합니다. 비정형 이미지를 입력했을 때 이미지를 전처리 하지 않고 그대로 넣어주게 되면 알아서 피처맵을 생성합니다. 피처맵은 피처가 어떤 특징을 갖고 있는지를 나타냅니다. 선이 있는지, ), O, 1, , 다양한 모양을 랜덤하게 생성해서 통과 시키면 해당 특징이 있는지를 학습하게 하는게 Convolution 연산입니다.
2) 피처맵 Output에 Activation Function (활성화함수)을 통과시켜서 액티베이션맵을 생성합니다.
=> relu 등을 사용하게 되면 출력값에 활성화 함수를 적용한 액티베이션맵을 반환합니다.
3) Pooling 에는 Max, Average, Min 등 여러 방법이 있는데, 보통 MaxPooling 을 주로 사용합니다.
Pooling: 이미지 크기를 줄여 계산을 효율적으로 하고 데이터를 압축하는 효과가 있기 때문에 오버피팅을 방지해 주기도 합니다. 이미지를 추상화 해주기 때문에 너무 자세히 학습하지 않도록해서 오버피팅이 방지되게 됩니다.
4) CNN 관련 논문을 보면 이 층을 얼마나 깊게 쌓는지에 대한 논문이 있습니다. VGG16, VGG19 등은 층을 16개, 19개 만큼 깊게 만든 것을 의미합니다. 30~50층까지 쌓기도 하고 100층 정도 쌓기도 합니다. 층의 수를 모델의 이름에 붙이기도 합니다.
=> 과거에 비해 GPU 등의 연산을 더 많이 지원하기 때문에 연산이 빨라진 덕분이기도 합니다.
5) TF API 는 다음의 방법으로 사용합니다.
model.add(layers.Conv2D(filters=64, kernel_size=(3, 3), activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))6) Padding, Stride 등을 사용해서 입력과 출력사이즈를 조정할 수 있습니다. Stride는 필터의 이동 보폭을 조정하기도 합니다.
🤔 DNN을 이미지 데이터에 사용했을 때 단점? (= CNN을 사용하는 이유)
1) flatten() 으로 1차원 벡터 형태로 주입을 해야 하기 때문에 인접 공간에 대한 정보를 잃어버리게 됩니다.
2) 1차원 형태로 주입을 해주게 되면 입력값이 커서 계산이 오래 걸립니다.
3) Conv과 Pooling 연산을 하게 되면 데이터의 공간적인 특징을 학습하여 어떤 패턴이 있는지를 알게 되며
4) Pooling을 통해 데이터를 압축하면 데이터의 용량이 줄어들며, 추상화를 하기 때문에 너무 자세히 학습하지 않게 되어 오버피팅을 방지해 줍니다.
💡 CNN, DNN의 가장 큰 차이점
DNN: 바로 1차원으로 flatten 해서 입력
CNN: Conv, Pooling 연산을 통해 특징을 학습하고 압축한 결과를 flatten 해서 DNN에 입력
🤔 kernel?
커널은 필터의 사이즈를 의미합니다. 똑같은 크기의 집이 몇 개 있냐 그런데 그 집의 크기가 어떻게 되냐와 비슷하다고 보면 됩니다. 커널 사이즈는 합쳐서 보기 보다는 각 개별 필터가 어떤 크기를 가지는지를 보면 됩니다.
💡 미니프로젝트 발표시간에 알게된 점:
-
회귀에서만 label에 스케일링 처리 한다. 분류에는 인코딩한다.
-
round랑 int32로 했을 때 차이가 많이 나는 이유?
round와 int의 차이: round는 반올림, int는 내림방식으로 처리한다.

임계값을 정하고 크고작다로 판단을 해야하는데 astype(int) 는 마지막에 소숫점을 자르고 싶을 때 사용하고 우선 임계값보다 큰지 작은지 판단하는 과정이 누락되었습니다.
🙋🏻♀️ 질문
Q: 멀티클래스 예측값이 나왔을 때 가장 큰 인덱스를 반환하는 넘파이 메서드는 무엇일까요?
A: np.argmax()를 통해 가장 큰 값의 인덱스를 반환받아 해당 클래스의 답으로 사용합니다.
Q: [0.1, 0.1, 0.7, 0.1] 이렇게 예측했다면 np.argmax() 로 반환되는 값은 무엇일까요?
A: 2
Q: softmax와 sigmoid의 차이는 무엇일까요?
A: 소프트 맥스 함수는 다중분류(보통 3개 이상)에 사용되며, 반환된 확률값의 합이 1입니다. 시그모이드는 이진분류에 사용되며, 0과 1 사이의 확률 값을 반환하여 임계값을 기준으로 분류합니다.
2개 중에 하나를 예측할 때는 softmax를 사용할 수도 있기는 하지만 보통 sigmoid를 사용합니다.
Q: learning_rate는 무엇일까요?
A: 학습률을 의미하며, 경사하강법에서 한 발자국 이동하기 위한 step size를 의미합니다. 학습률이 클수록 손실함수의 최솟값을 빨리 찾을 수 있으나 발산의 우려가 있고 너무 작으면 학습이 지나치게 오래걸리는 단점이 있습니다.
Q: CIFAR10(CNN)의 input_shape 가 MNIST(DNN)와 어떻게 달라졌나요?

A: 컬러채널 유무
모니터나, 인쇄매체 어디에 사용하냐에 따라 색상의 표현방식이 달라집니다. 모니터에서는 보통 RGB(red, green, blue) 3원색을 사용합니다.
model.add(layers.Conv2D(filters=32, kernel_size=(3, 3),
activation='relu', input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))Q: 위 코드에서 피처맵은 몇 개 나오나요?
A: 32개 (fillters=32 이기 때문)
Q: 위에서 입력한 이미지의 채널 수는 몇 개 일까요?
A: 3개 (R, G, B)
🦁 질문
Q: 분류에서 출력층 활성함수를 시그모이드로한다면 출력층 유닛은 2로 하면 되나요?
A: sigmoid는 1개로 해주어야 확률값으로 출력을 받아 특정 임계값보다 크냐작냐로 binary값을 만들어서 판단합니다. 분류에서 units이 2개라면 softmax로 반환받는게 맞습니다. 이 때는 둘 중에 확률 값이 높은 값을 선택해서 사용합니다.
Q: 필터와 커널의 차이가 무엇일까요?
A: 필터는 이미지에서 특징을 분리해 내는 기능을 하고, 필터를 이미지에 통과해서 합성곱 연산을 하는데, 이 합성곱에 사용되는 커널의 크기를 kernel_size라고 합니다.
Q: 필터도 결국 가중치를 의미하나요?
A: Conv2D가 하는 일은 이미지-대-이미지 변환입니다.
4D(NHWC) 이미지 텐서를 또 다른 4D 이미지 텐서로 바꿉니다. (합성곱 층이 특성을 추출하는 기능을 가지고 있기 때문에 합성곱 층의 출력을 일반적으로 특성맵(feature map) 이라고 부릅니다.)
하지만 기존과 높이, 너비, 채널 개수는 달라질 수 있습니다. (이름이 conv2D인데 4D 텐서를 다룬다는 것이 이상해 보일 수 도 있지만, 배치차원과 채널차원은 부가적인 부분이라는 것을 유념해야합니다)
좀 더 직관적으로 설명하자면 합성곱 층은 이미지를 흐리게 하거나 선명하게 만드는 간단한 '포토샵 필터 묶음'으로도 이해할 수 있습니다.
이런 효과들은 입력 받은 이미지 위를 작은 픽셀 조각(합성곱 커널 또는 간단히 커널이라고 부릅니다)이 슬라이딩하는 2D 합성곱으로 만들어지게 됩니다. 슬라이딩 위치마다 커널이 입력 이미지의 겹치는 부분과 픽셀별로 곱해집니다. 그리고 이 픽셀별 곱셈이 모두 더해져서 출력 이미지의 한 픽셀이 됩니다.
합성곱 층은 일반적으로 여러 개의 필터를 사용하며 이런 필터를 합쳐서 커널이라 부르게 됩니다. 하지만 종종 필터와 커널, 가중치를 구분하지 않고 혼용해서 사용하기도 합니다.
참고로 합성곱 층에서는 필터마다 하나의 편향을 가지고 있습니다.
✏️ TIL
- 사실(Fact): CNN에 대해 배웠다.
- 느낌(Feeling): 정형데이터보다 비정형데이터를 다루는게 재밌다.
- 교훈(Finding): 새로운 개념들을 많이 배웠으니 복습하자.
