
0504 실습:
RandomForest 안에 트리의 개수가 100개가 기본값이라면 그 내부에서도 트리를 100개를 만들기 때문에 DecisionTree를 사용할 때보다 속도가 더 걸린다.

: 5 fold 는 cv 조각 5개를 의미하며 5 candidates 는 n_iter를 의미합니다.
💡 Cross validation과 Hold out validation
- cross validation은 속도가 오래걸린다는 단점이 있기도 하지만 validation의 결과에 대한 신뢰가 중요할 때 사용합니다. 예를 들어 사람의 생명을 다루는 암여부를 예측하는 모델을 만든다거나 하면 좀 더 신뢰가 있게 검증을 해야겠죠.
cross validation 이 너무 오래 걸린다면 조각의 수를 줄이면 좀 더 빠르게 결과를 볼 수 있고 신뢰가 중요하다면 조각의 수를 좀 더 크게 만들어 보면 됩니다.- hold-out-validation 은 한번만 나눠서 학습하고 검증하기 때문에 빠르다는 장점이 있습니다. 하지만 신뢰가 떨어지는 단점이 있습니다. hold-out-validation 은 당장 비즈니스에 적용해야 하는 문제에 빠르게 검증해보고 적용해 보기에 좋습니다.
0601 실습: Regression
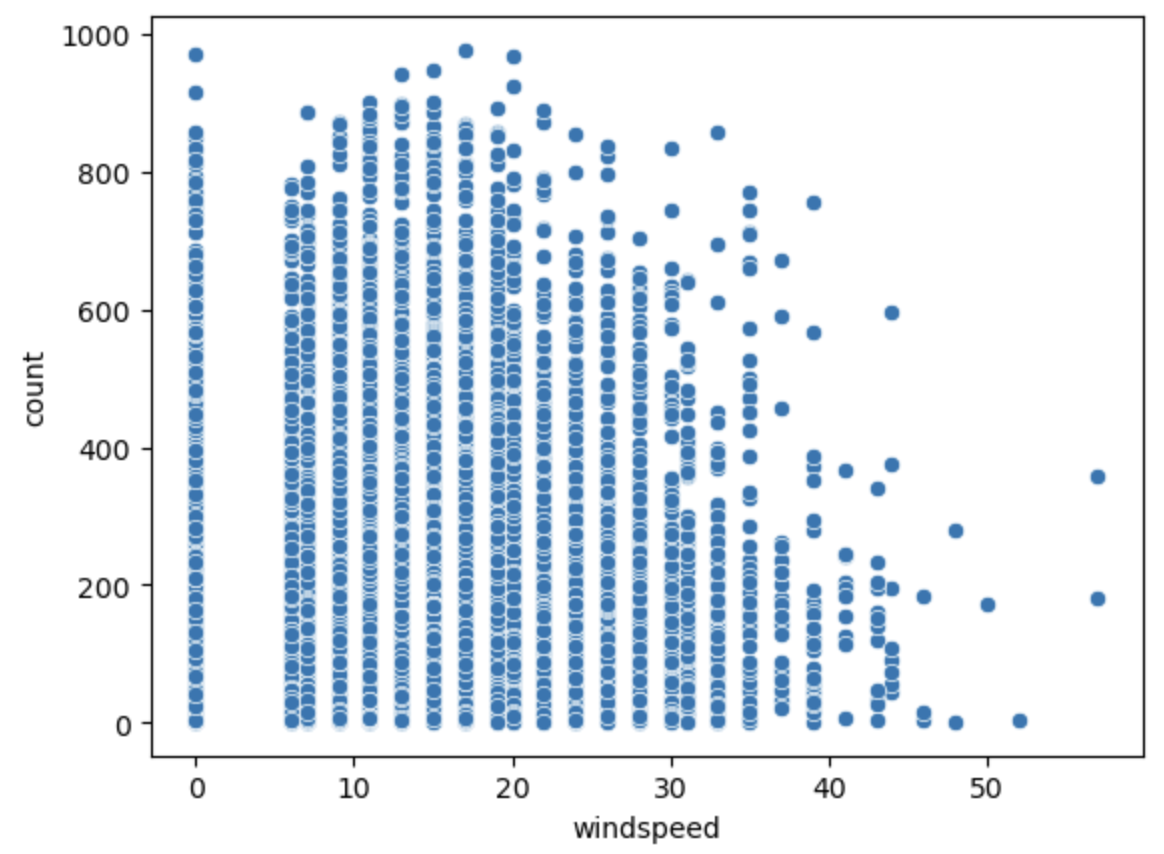
- 0이 많다, 0과 10 사이에 공백이 존재한다. 풍속이 셀수록 대여 수가 줄어는 경향이 있다.
- 범주형 그래프를 보는것 같다. => 소숫점이 있지만 기록구간이 있을 수 있다.
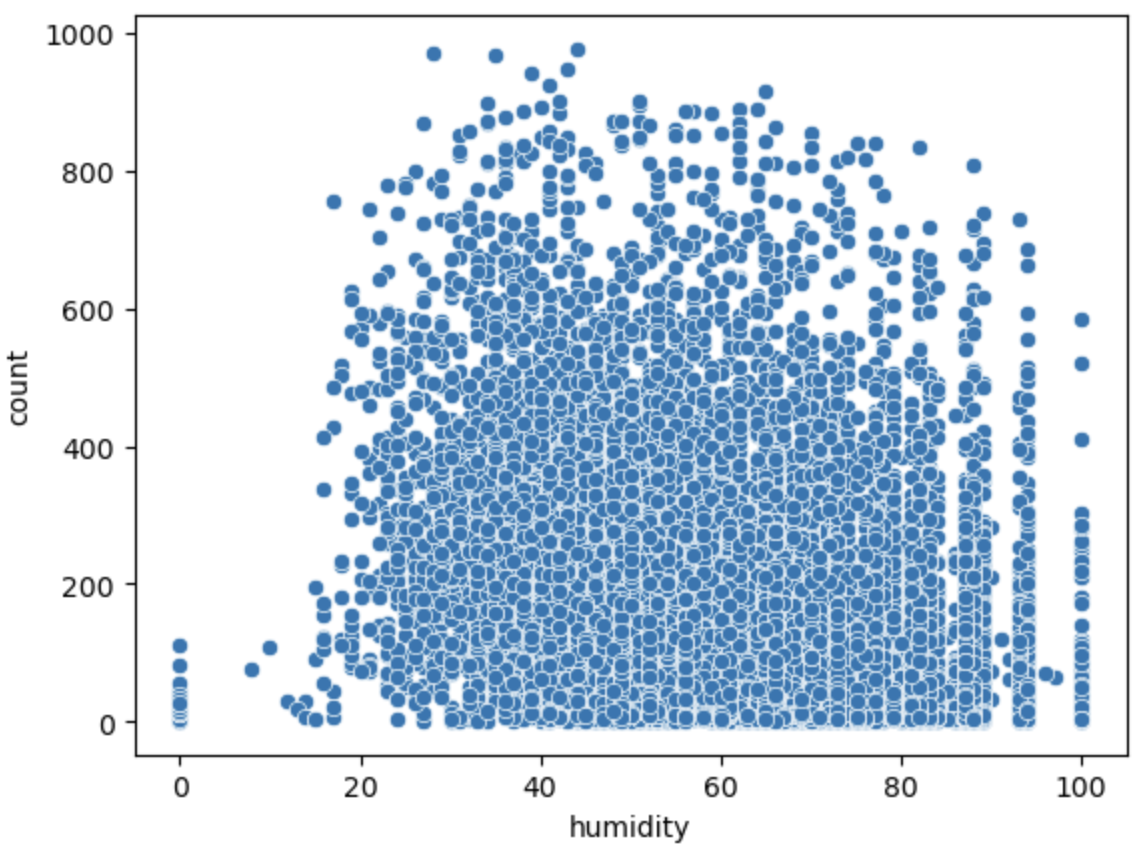
- 상관이 커보인다면 결측치 전처리가 필요하지만, 여기에서는 0으로 된 값이 많아 보이지는 않으며, 습도와 자전거 대여량은 상관이 없어 보인다.
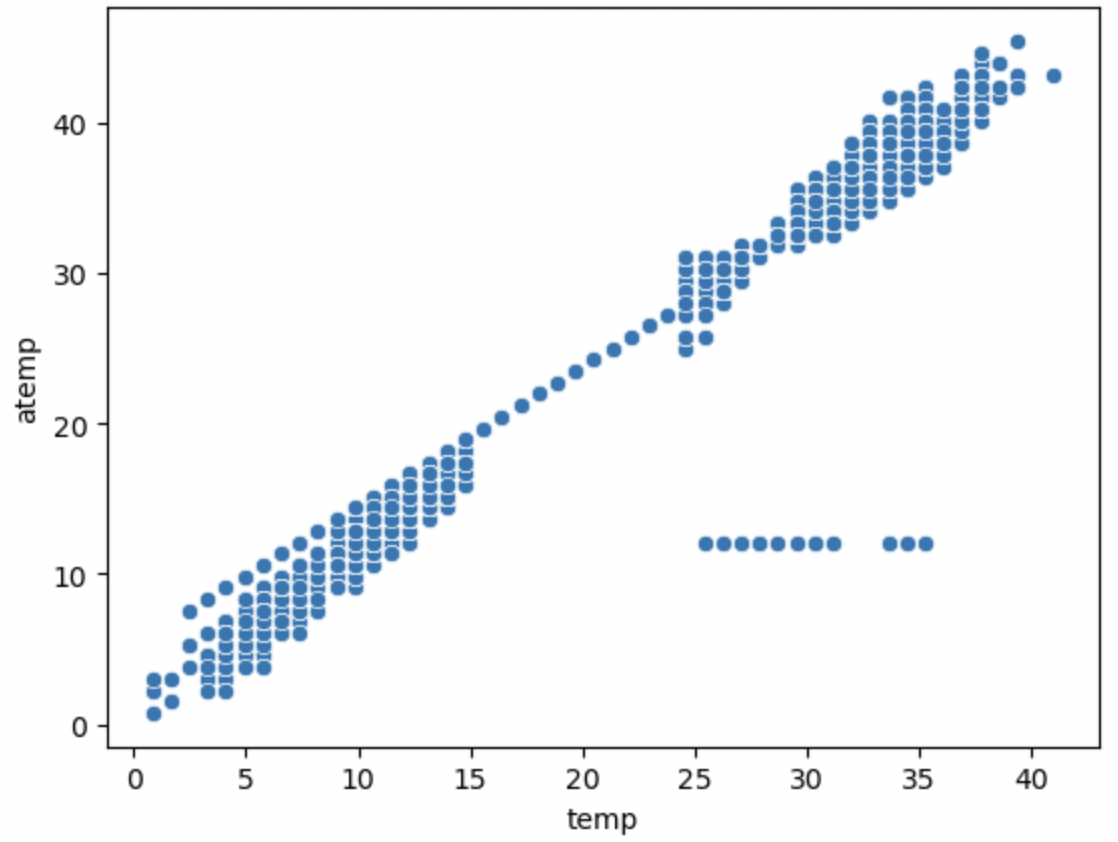
- 강한 양의 상관관계를 가진다. 이상치라기 보다는 오류 데이터에 가까운 10개 정도의 데이터가 있다. (현실세계에서는 오입력이 있을 수도 있다.)
평가
MAE
- 모델의 예측값과 실제 값 차이의 절대값 평균
- 절대값을 취하기 때문에 가장 직관적임
MAE = abs(y_train - y_val_pred).mean()
# scikitlearn에 내장된 함수로도 MSE를 구할 수 있다.
from sklearn.metrics import mean_squared_error
mean_squared_error(y_train, y_val_pred)MSE
- 모델의 예측값과 실제값 차이의 면적의(제곱)합
- 제곱을 하기 때문에 특이치에 민감하다.
MSE = ((y_train - y_val_pred) ** 2).mean()
# scikitlearn에 내장된 함수로도 MSE를 구할 수 있다.
from sklearn.metrics import mean_squared_error
mean_squared_error(y_train, y_val_pred)RMSE
- MSE에 루트를 씌운 값
- RMSE를 사용하면 지표를 실제 값과 유사한 단위로 다시 변환하는 것이기 때문에 MSE보다 해석이 더 쉽다.
- MAE보다 특이치에 Robust(강하다 == 덜 민감하다)
# RMSE는 내장함수가 없다. 아직..
RMSE = np.sqrt(MSE)RMSLE (Root Mean Squared Log Error)
- RMSLE는 예측과 실제값의 "상대적" 에러를 측정한다.
- log를 취하면 skewed값이 덜 skewed 하게 (덜 찌그러지게) 된다. log를 취하면 분포가 좀 더 정규분포에 가까워지기도 한다.
- RMSLE는 RMSE 와 거의 비슷하지만 오차를 구하기 전에 예측값과 실제값에 로그를 취해주는 것만 다르다.
np.sqrt(np.square(np.log(y_train + 1) - np.log(y_val_pred + 1)).mean())
# scikitlearn에 내장된 함수로도 RMSLE를 구할 수 있다.
from sklearn.metrics import mean_squared_log_error
mean_squared_log_error(y_train, y_val_pred) ** 0.5RMSLE 예시
- RMSLE 는 최솟값과 최댓값의 차이가 큰 값에 주로 사용됩니다. 대표적인 예가 부동산 가격 등 이다.
- RMSLE는 실제값보다 예측값이 클때보다, 실제값보다 예측값이 더 작을 때 (Under Estimation) 더 큰 패널티를 부여한다.
- 배달 시간을 예측할때 예측 시간이 20분이었는데 실제로는 30분이 걸렸다면 고객이 화를 낼 수도 있다. 이런 조건과 같은 상황일 때 RMSLE를 적용할 수 있다.
부동산 가격으로 예시를 들면
1) 2억원짜리 집을 4억으로 예측
2) 100억원짜리 집을 110억원으로 예측
- Absolute Error 절대값의 차이로 보면 1) 2억 차이 2) 10억 차이
- Squared Error 제곱의 차이로 보면 1) 4억차이 2) 100억차이
💡 Squared Error 에 root 를 취하면 absolute error 하고 비슷해 집니다.
👉🏻 비율 오류로 봤을 때 1)은 2배 잘못 예측, 2)10% 잘못 예측
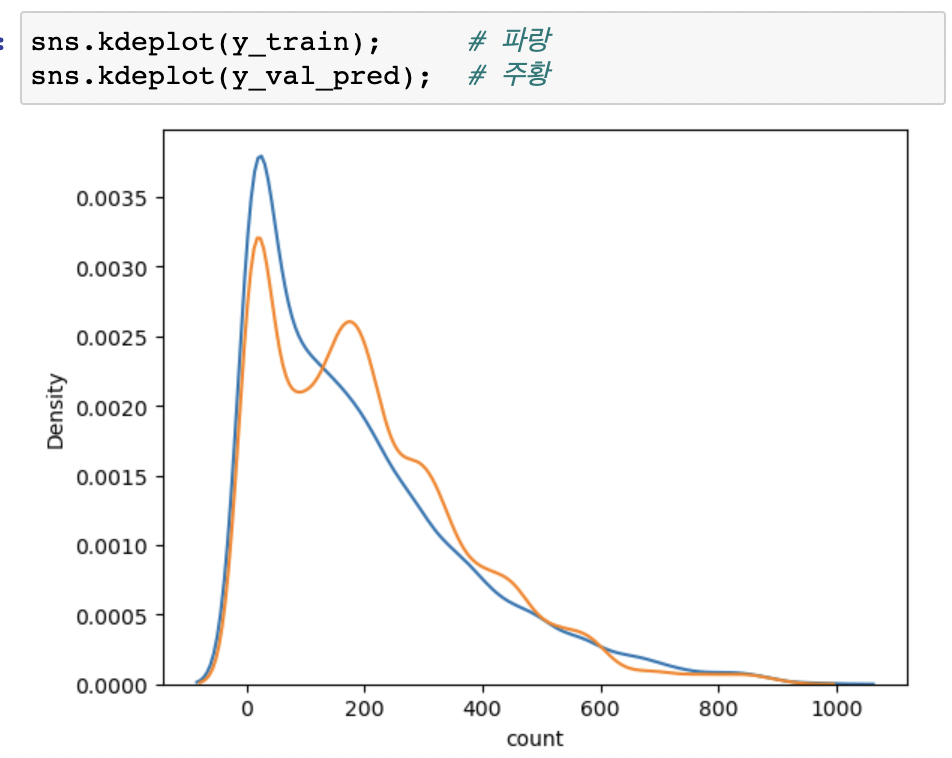
- 자전거 대여수는 대부분 작은 값에 몰려있습니다. 그래서 log를 취하고 계산하게 되면 오차가 큰 값보다 작은값에 더 패널티가 들어가게 됩니다.
- 로그의 기울기를 보면 작은 값에 기울기가 더 가파르고 값이 커질수록 기울기가 완만해 집니다.
🙋🏻♀️ 질문
Q: RMSLE 측정공식은 처음보는 공식인데 어떤 공식과 이름이 비슷할까요?
A: RMSE와 한 글자만 다른데 Log가 중간에 있다.
Q: Bike Sharing Demand는 분류와 회귀 중 어떤 것일까요?
A: 회귀
경진대회 이름에 demand 가 들어가면 대부분 수요예측 문제입니다.
Q: 이 문제는 어떤 것을 예측하는 문제일까요?
A: 시간별 자전거 대여 수요 예측
Q: 이 문제에서 예측해야 하는 정답은 무엇일까요?
A: count
Q: train 을 봤을 때 인상적인 점이 있다면 무엇일까요?
A:
- casual,registered,count 평균값에 비해 max값이 크다 👉🏻 이상치가 있어 보인다.
- 습도와 풍속이 0인 날 👉🏻 중요한 포인트
Q: 왜 1을 더한 후에 로그를 취할까요?
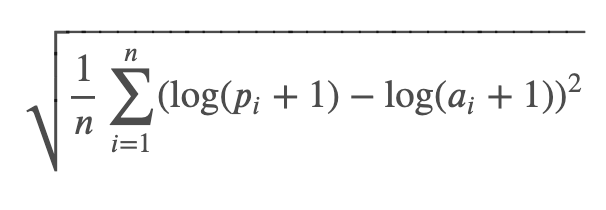
A: x 가 1보다 작으면 음수가 나오기 때문에 1을 더해서 1이하의 값이 나오지 않게 하기위해 == y값을 음수로 나오지 않게 하기위해
Q: 마이너스 값이 나왔는데 MSE를 계산한다면 어떻게 될까요?
A: 의도치 않은 큰 오차가 나올 수 있기 때문에 가장 작은 값이 될 수 있는 0에 1을 더해서 마이너스 값이 나오지 않게 한다. == 모든값을 1만큼 옮겨준다.
💡 로그를 취하기 전에 모든 값에 1을 더해서 가장 작은 값이 될 수 있는 0이 1이 되도록 더해주는 이유:
train 의 최솟값은 1이지만 test 의 예측값이 0이 나올 수도 있기 때문입니다.
Q: 마이너스 값에는 로그를 취할 수 없는데 마이너스값에 로그를 취한다면 어떻게 하면 좋을까요?
A: 가장 작은값이 1이 되도록 전체 값에 더해줍니다.
🦁 질문
Q: cross validation은 반드시 해야 하나요? 모델을 만들 때 트레이닝셋이랑 테스트셋을 7:3 정도로 나누는데 이 자체가 cross validation을 하는 거 아닌가요?
A: 7:3 이나 8:2 로 나누는 과정은 hold-out-validation 입니다. hold-out-validation 은 중요한 데이터가 train:valid 가 7:3이라면 중요한 데이터가 3에만 있어서 제대로 학습되지 못하거나 모든 데이터가 학습에 사용되지도 않습니다. 그래서 모든 데이터가 학습과 검증에 사용하기 위해 cross validation을 합니다.
Q: 이상치 값인지 오류데이터인지 test데이터와 비교해보고 판단을 내려도 되나요?
A: 비교해볼 수 있는 데이터가 있다면 비교해 보고 도메인 지식을 동원해서 오류데이터인지를 판단해 봐야겠습니다.
Q: 코랩에서 진행할때 csv파일이 크면, 왜 데이터를 제대로 읽어내지 못하나요?
A: 업로드를 하면 업로드 과정에서 네트워크 상황에 따라 유실이 발생하기도 하니 마운트(구글 드라이브에 업로드 후 연결)해서 사용하는 것을 추천합니다.
Q: np.log의 밑이 무엇인가요?
A: e
자연상수 (e)는 자연의 연속 성장을 표현하기 위해 고안된 상수입니다.
100%의 성장률을 가지고 1회 연속 성장할 때에 얻게되는 성장량을 의미합니다.
Q: 작은 오차에 패널티를 준다는건, 작은 오차를 과장되게 한다는 걸까요?
A: RMSE 에 비교해서는 Log를 취하기 때문에 작은 값에 더 패널티가 들어갑니다.
RMSE: 오차가 클수록 가중치를 주게 됨 (오차 제곱의 효과)
RMSLE: 오차가 작을수록 가중치를 주게 됨 (로그의 효과)
MAE: 가중치 없음 (제곱, 로그 둘 다 없음)
✏️TIL
- 사실(Fact): 오늘도 평가공식에 대해 배웠다.
- 느낌(Feeling): 평가공식.. 왜 한 번에 이해가 안 될까..?
- 교훈(Finding): 계산이 어떻게 이루어지는지에 대해 조금 더 찬찬히 알아볼 필요가 있겠다.
