
해당 노트는 Tensorflow101의 자료를 바탕으로 학습하고 정리한 것입니다.
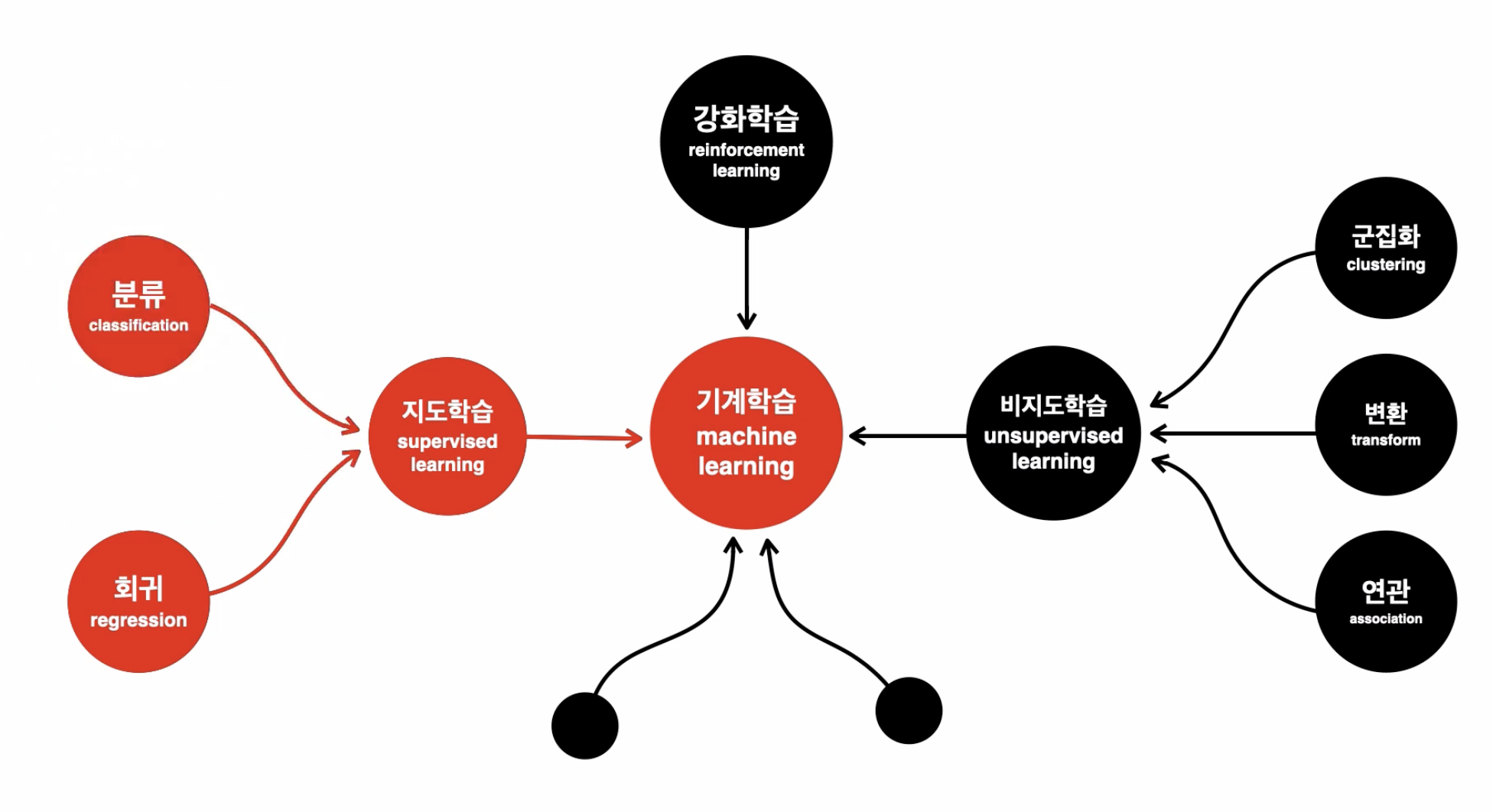
출처: https://opentutorials.org/module/4966
Tensorflow를 이용해 해결할 수 있는 문제는 지도학습의 분류와 회귀가 있다.
분류와 회귀 문제를 풀기 위해 사용되는 머신러닝 알고리즘들이 있는데 그 중 Neural Network에 대해 알아보자.
✅ Neural Network
: 사람의 두뇌가 동작하는 방법을 모방해서 기계가 학습할 수 있도록 고안된 알고리즘
💡 Neural Network == 인공신경망 == Deep learning
✅ 지도학습
-
과거의 데이터를 준비한다. 과거의 데이터 속에서 원인과 결과를 인식 하는 것
원인 == 독립변수, 결과 == 종속변수
-
모델의 구조를 만든다. 원인을 알려주면 결과를 알려주는 모델.
-
데이터로 모델을 학습한다.
-
모델로 예측한다.
📌 Regression
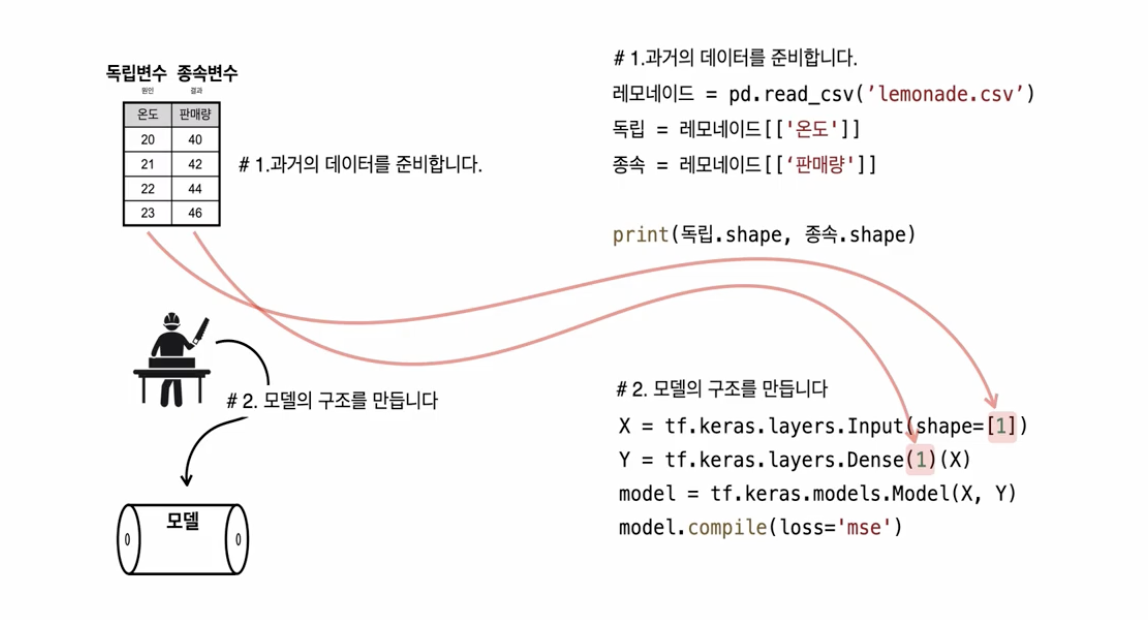
출처: https://opentutorials.org/module/4966
# 종속변수, 독립변수 나누기
독립 = 레모네이드[['온도']]
종속 = 레모네이드[['판매량']]
# 모델 만들기
X = tf.keras.layers.Input(shape=[1])
Y = tf.keras.layers.Dense(1)(X)
model = tf.keras.models.Model(X, Y)
model.compile(loss='mse')
# 모델 학습
model.fit(독립, 종속, epochs=10) # 10번만 돌리니까 loss가 너무 크게 나옴
model.fit(독립, 종속, epochs=1000, verbose=0) # 1000번 log 출력 없이 돌려보자
# log 출력이 없으니까 위 코드의 loss값을 알 수 없으니 다시 10번만 돌려서 loss값 확인
model.fit(독립, 종속, epochs=10)
# 모델을 이용합니다.
print(model.predict(독립))
print(model.predict([[15]]))- X == 독립변수 == "온도" == 위 테이블에서 독립변수는 '온도' 하나 뿐이라 shape=[1]에 1을 넣는다.
- Y도 마찬가지.
- 모델의 구조를 만들 때 숫자 부분을 맞춰서 만들어야 하기 때문에 독립변수와 종속변수가 몇 개인지 살피는 것이 중요하다.
epochs: 전체 데이터를 몇 번 반복하여 학습할 것인지 결정해주는 숫자
✅ Loss
결과값과 예측값의 차이를 loss라고 한다. loss가 0에 가까워 질수록 학습이 잘된 모델이라고 할 수 있다.
이상치: 평균의 대표성을 무너뜨리는 값
중앙값: 이상치로인해 평균이 대표성을 띄지 못하는 경우에 대안으로 사용하는 값
✅ 퍼셉트론 (Perceptron)
# 독립변수 13개
X = tf.keras.layers.Input(shape=[13])
# 13개의 입력으로부터 1개의 출력을 만들어내는 구조 == 아래 수식을 만드는 과정
Y = tf.keras.layers.Dense(1)(X)1개의 출력을 만들어내는 구조를 표현한 수식:
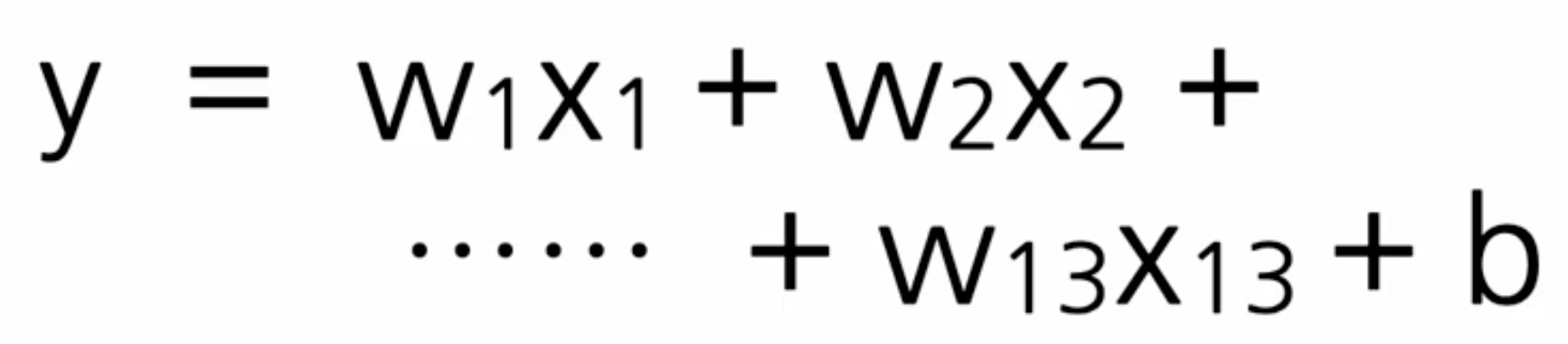
출처: https://opentutorials.org/module/4966
컴퓨터는 학습 과정에서 입력되는 데이터를 보고 이 수식의 값들을 찾는다.
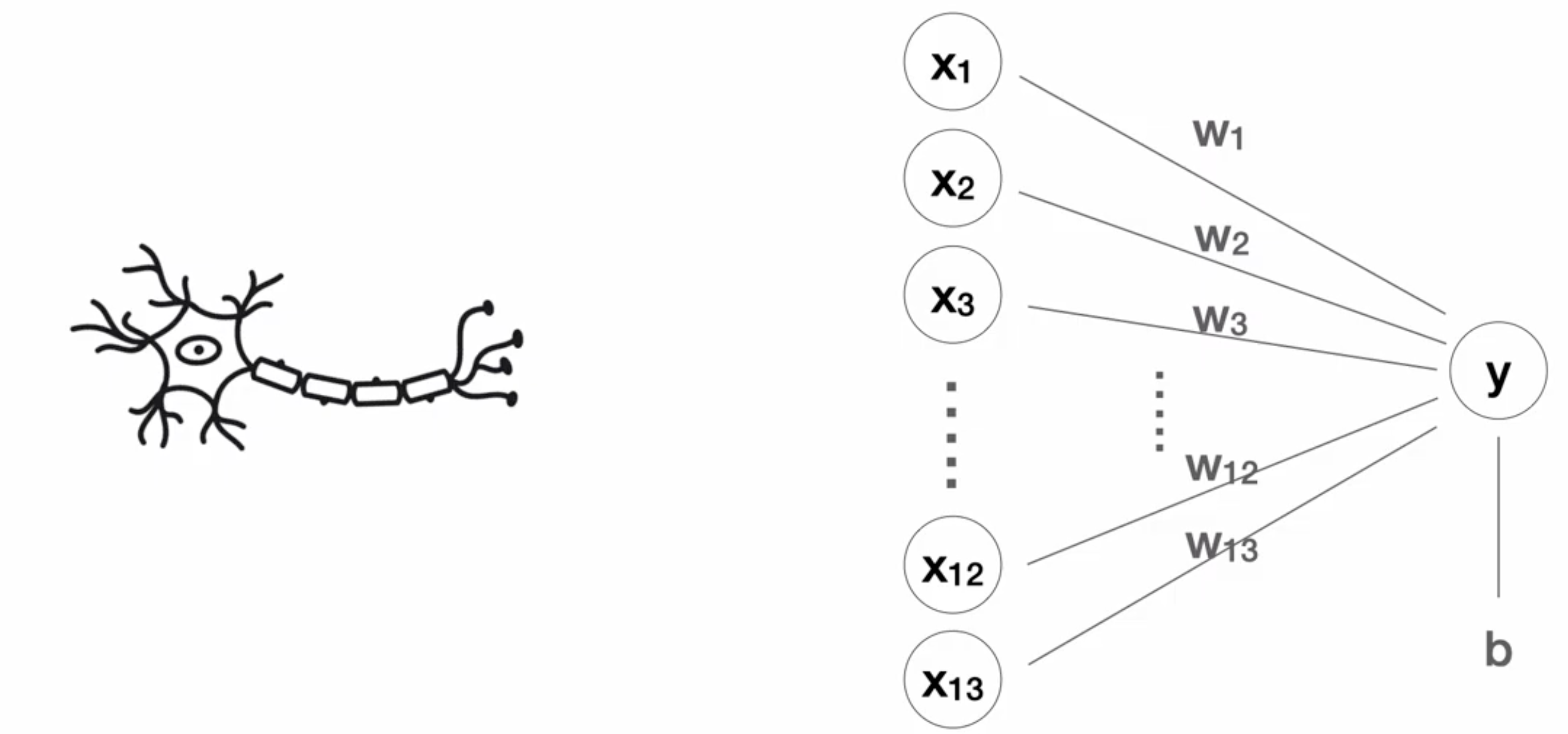
출처: https://opentutorials.org/module/4966
위에서 만든 모델은 뉴런 하나로 이루어져 있다.
딥러닝에서 뉴런의 역학을 하는 것은 모형(=퍼셉트론)과 수식이다.
w == 가중치(weight)
b == 편향(bias)
종속변수(y)가 2개 일 경우, 수식이 2개 필요하다.
# 모델의 수식 확인
print(model.get_weights())# Output
[array([[-0.08674815],
[ 0.07197835],
[-0.0565743 ],
[ 3.170563 ],
[ 2.0723264 ],
[ 4.161017 ],
[ 0.01186026],
[-0.92461 ],
[ 0.14845608],
[-0.0099678 ],
[-0.01967811],
[ 0.01535373],
[-0.5663386 ]], dtype=float32), array([2.3529432], dtype=float32)]위의 output을 이용해서 수식을 작성한다. array([2.3529432])이 b값이 된다.
📌 Classification
✅ One-hot-encoding
y값이 범주형인 경우 수식을 만들 수 없기 때문에 one-hot-encoding으로 수치형 데이터로 변경해준다.
# 원핫인코딩
인코딩 = pd.get_dummies(아이리스)인코딩된 변수의 갯수만큼 수식을 만들어야하고, 컴퓨터는 만들어진 수식의 모든 가중치를 찾아야한다.
✅ Activation (활성화 함수) - Softmax
Softmax: Softmax는 세 개 이상으로 분류하는 다중 클래스 분류에서 사용되는 활성화 함수
- 분류될 클래스가 n개라고 할 때, n차원의 벡터를 입력받아 각 클래스에 속할 확률을 추정
💡 목표: 분류 모델에서는 회귀에서처럼 수식들의 모든 숫자를 예측하는 것이 아닌 0 또는 1을 맞추는 것이다. 즉, y값의 최솟값 == 0, 최댓값 == 1
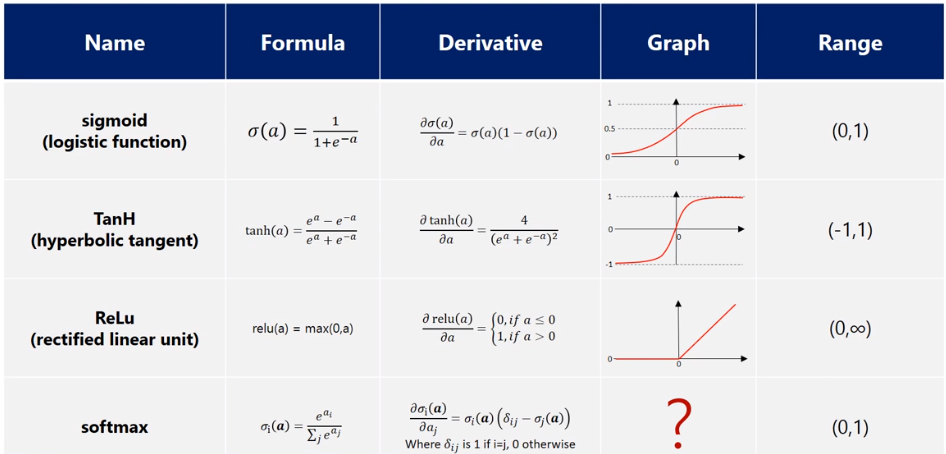
출처: https://jjeongil.tistory.com/977
분류의 퍼셉트론:
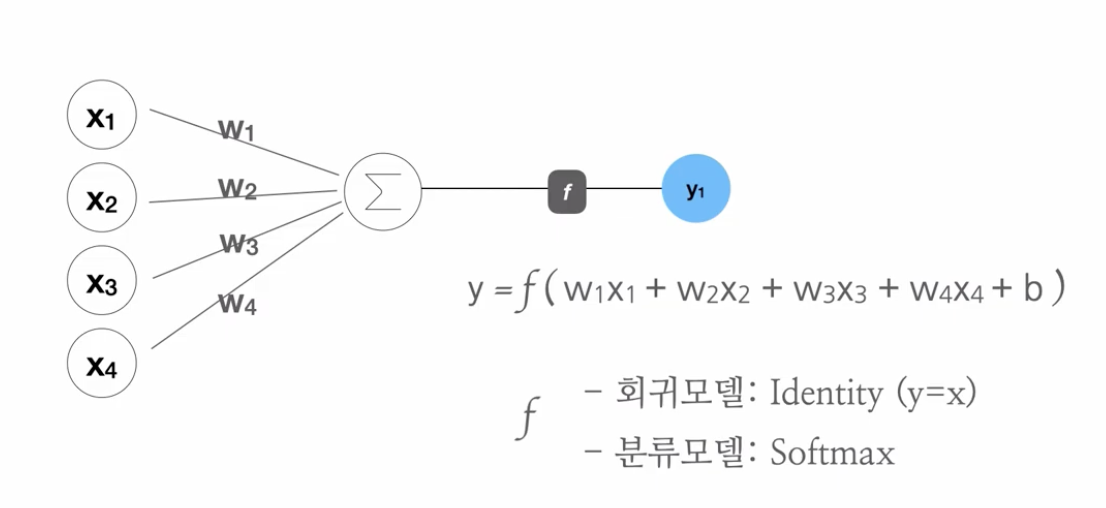
출처: https://opentutorials.org/module/4966
회귀 모델은 숫자를 예측하기 때문에 입력을 그대로 출력으로 만드는 identity 함수가 있다.
# 모델의 구조를 만듭니다
X = tf.keras.layers.Input(shape=[4])
Y = tf.keras.layers.Dense(3, activation='softmax')(X)
model = tf.keras.models.Model(X, Y)
model.compile(loss='categorical_crossentropy',
metrics='accuracy')Accuracy(정확도): 분류 문제에서 loss를 사람이 보기 쉽게 해주는 평가 지표
# weights & bias 출력
print(model.get_weights())# Output
[array([[ 0.853431 , -0.07520917, 0.17264092],
[-0.09274475, 0.86003894, 0.39891034],
[-0.60236025, 0.22760218, 0.24201868],
[ 0.49735856, 0.5480953 , 0.8262374 ]], dtype=float32),
array([ 0.41247246, 0.09746977, -0.38971603], dtype=float32)]✅ Hidden layer (Regression | Classification)
지금까지는 하나의 신경망을 사용했고, 이제부터는 신경망을 여러개 사용해서 깊은 신경망을 만들어 보자.
깊은 신경망을 만드는 법: 기존의 퍼셉트론을 여러개 사용해 연결. 입력과 결과 사이에 퍼셉트론들을 추가.
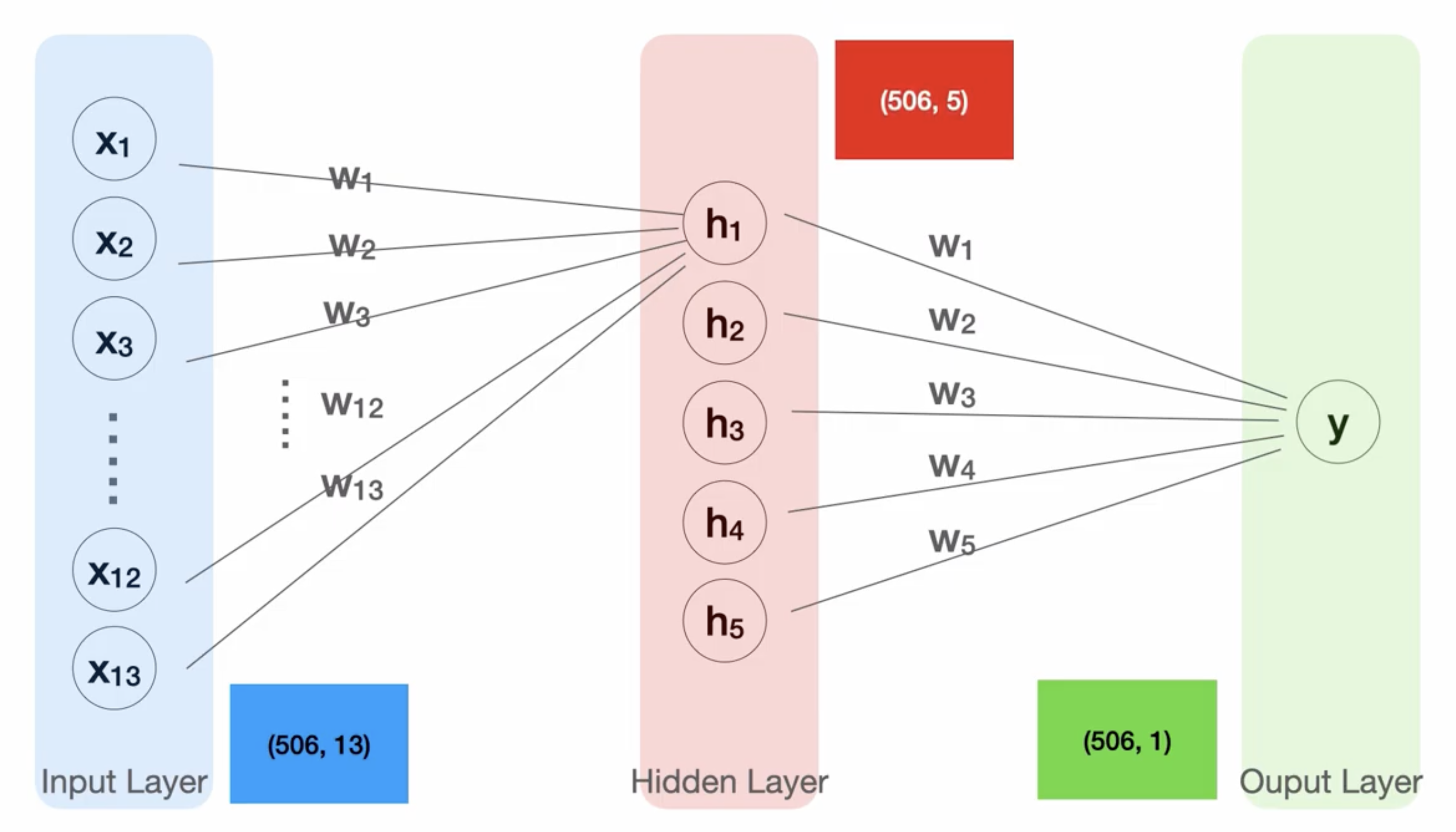
출처: https://opentutorials.org/module/4966
- 결과를 내기 위해서는 hidden layer의 모든 값들을 입력으로 하는 하나의 퍼셉트론이 필요.
- hidden layer의 첫번째 결과를 내기 위해서는 마찬가지로 하나의 퍼셉트론이 필요
- 위 그림에서 hidden layer에 5개의 노드가 있으니 5개의 퍼셉트론이 필요
- input layer -> hidden layer : 13개의 입력을 받고 5개 출력
- hidden layer -> output layer : 5개의 입력을 받고 1개 출력
# 모델의 구조를 만듭니다
X = tf.keras.layers.Input(shape=[13])
# 중간 결과 (노드 10개)를 보여주는 레이어를 추가한 코드
# hidden layer의 활성화 함수 == swish
H = tf.keras.layers.Dense(10, activation='swish')(X)
Y = tf.keras.layers.Dense(1)(H) # X대신 Hidden layer의 H 입력
model = tf.keras.models.Model(X, Y)
model.compile(loss='mse')
# 모델 구조 확인
model.summary()
param (parameter): 가중치의 갯수
✅ 13개의 입력을 받아 10개를 출력하는 hidden layer
✅ 10개의 입력을 받아 1개의 출력을 만드는 output layer
🤔 dense_2의 param (가중치) 갯수가 140인 이유?
수식 항이 13개이고, bias 1개가 추가되어 14개가 되는데 노드 10개를 추가했으니 가중치는 140개가 된다.
🤔 마지막 dense_3의 param 갯수가 11개인 이유?
수식 항이 10개이고, bias 1개가 추가되어 11개의 가중치를 갖게된다.
💡 TIP
여러번 학습을 시켜도 loss가 눈에 띄게 줄어들지 않을 때는 Batch normalisation을 사용하자.
Batch normalisation layer: activation을 dense layer 안에다 정의하지 않고 분리해서 코드 작성.
기존 모델과 batch normalisation layer를 사용한 모델은 같은 수식을 사용하지만
batch normalisation을 사용한 모델의 성능이 눈에 띄게 좋다.
# 기존 모델
X = tf.keras.layers.Input(shape=[13])
H = tf.keras.layers.Dense(8, activation='swish')(X)
Y = tf.keras.layers.Dense(1)(H)
model = tf.keras.models.Model(X, Y)
model.compile(loss='mse')
# 모델의 구조를 BatchNormalization layer를 사용하여 만든다.
X = tf.keras.layers.Input(shape=[13])
H = tf.keras.layers.Dense(8)(X)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation('swish')(H)
H = tf.keras.layers.Dense(8)(H)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation('swish')(H)
H = tf.keras.layers.Dense(8)(H)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation('swish')(H)
Y = tf.keras.layers.Dense(1)(H)
model = tf.keras.models.Model(X, Y)
model.compile(loss='mse')📌 Summary (Regression | Classification)
Regression (loss == usually mse)
# 1) 종속변수, 독립변수 나누기
독립 = 레모네이드[['온도']]
종속 = 레모네이드[['판매량']]
# 2) 모델 생성
X = tf.keras.layers.Input(shape=[1])
Y = tf.keras.layers.Dense(1)(X)
model = tf.keras.models.Model(X, Y)
model.compile(loss='mse')
# 3) 모델 학습
model.fit(독립, 종속, epochs=10)
# 4) 예측
print(model.predict(독립))
# 5) 모델의 수식 확인
print(model.get_weights())Classification (loss == cross entropy)
# 1) 원핫인코딩
인코딩 = pd.get_dummies(아이리스)
# 2) 모델 생성
X = tf.keras.layers.Input(shape=[13])
# 3)중간 결과 (노드 10개)를 보여주는 레이어를 추가한 코드
# hidden layer의 활성화 함수 == swish
H = tf.keras.layers.Dense(10, activation='swish')(X)
Y = tf.keras.layers.Dense(1)(H) # X대신 Hidden layer의 H 입력
model = tf.keras.models.Model(X, Y)
model.compile(loss='mse')
# 4) 모델 구조 확인
model.summary()
# 5) 모델 학습
model.fit(독립, 종속, epochs=10)
# 6) 예측
print(model.predict(독립))
# 7) 모델의 수식 확인
print(model.get_weights())
