
📌 RFM (Recency, Frequency, Monetary) Analysis
💡 RFM 분석: 가치있는 고객을 추출해내어 이를 기준으로 고객을 분류할 수 있는 분석 방법
- 구매 가능성이 높은 고객을 선정하기 위한 데이터 분석 방법
- 세가지 지표 또는 차원에 따라 각 고객을 분석
Recency - 거래의 최근성: 고객이 얼마나 최근에 구입했는가?
👉🏻 최근에 왔는지를 보기 때문에 값이 작을 수록 높은 점수를 줍니다.
Frequency - 거래빈도: 고객이 얼마나 빈번하게 우리 상품을 구입했나?
👉🏻 자주 왔는지를 보기 때문에 값이 높을 수록 높은 점수를 줍니다.
Monetary - 거래규모: 고객이 구입했던 총 금액은 어느 정도인가?
👉🏻 얼마나 많은 금액을 구매했는지 보기 때문에 값이 높을 수록 높은 점수를 줍니다.
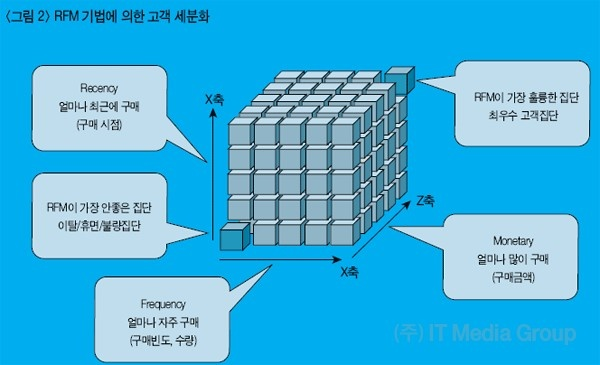
출처: http://www.itdaily.kr/news/articleView.html?idxno=8371
✅ 고객 세분화 항목
- 판매정보: 상품판매 자료 거래 금액, 횟수
- 인구통계락적 정보: 나이, 성별, 직업, 학력, 거주지역, 소득수준
- 라이프스타일 정보: 순차적, 구매 정보, RFM 정보
- 심리 정보: 구매욕구
- 행동 정보: 구매패턴 Life Time Value(LTV)
✅ RFM 모형
Scoring 기법: RFM의 요인을 각각 5등급으로 등간격으로 분류하는 방법이다.
현재 개발된 RFM 모형은 크게 4가지로 분류 할 수 있다.
- 모델1. RFM 각 요소의 20% rule의 적용
- 모델2. 비율 척도에 의한 양적인 정도의 차이에 따른 등간격의 5등급 분류
- 모델3. 상하 20%를 제외한 등간격 척도에 의한 그룹 분류
- 모델4. 군집 분석에 의한 각 요소 별 5개의 그룹 분류
🤔 RFM 기법으로 고객을 같은 간격으로 나누려면 우리가 사용했던 판다스에서 어떤 기능을 사용하면 될까요?
cut: 절대평가 , qcut: 상대평가
🤔 예를 들어 Monetary 를 기준으로 금액의 절대값이 아니라 같은 비율로 나누고자 한다면 cut, qcut? 무엇일까요?
qcut
📌 파레토 법칙
: 상위 고객의 20%가 기업 총 매출의 80%를 차지한다.
80:20 법칙을 고려하면 고객 매출 데이터가 누적됨에 따라 마케팅에 데이터를 활용해 마케팅에 활용할 수 있다.
1202 실습
last_timestamp = df["InvoiceDate"].max() + dt.timedelta(days=1)🤔 last_timestamp 에 1 더해야 하는 이유 한번 더 설명해주실 수 있나요?
최근 영업일과 같은 날에 마지막으로 거래를 했다면 0 으로 될텐데 마지막 거래일자에 거래한 값이 1이 되게 하기 위해서 입니다.
리텐션을 구할 때도 코호트 인덱스 값을 1로 설정한 것 처럼 0부터 시작하지 않고 1부터 시작하도록 1을 더해주었습니다.
💡 groupby 내에서 lambda를 사용하여 익명함수를 사용할 수 있다.
rfm = df.groupby("CustomerID").agg(
{"InvoiceDate" : lambda x:(last_timestamp - x.max()).days,
"InvoiceNo" : "count",
"TotalPrice" : "sum"})Cluster Analysis (군집화 분석)
: 대표적인 비지도 학습 (label 값이 없음). 주어진 데이터들의 특성을 고려해 데이터 집단을 정의하고 (segmentation) 데이터 집단의 대표할 수 있는 대표점을 찾는 데이터 마이닝 방법
📌 Scikit-learn의 클러스터링 알고리즘
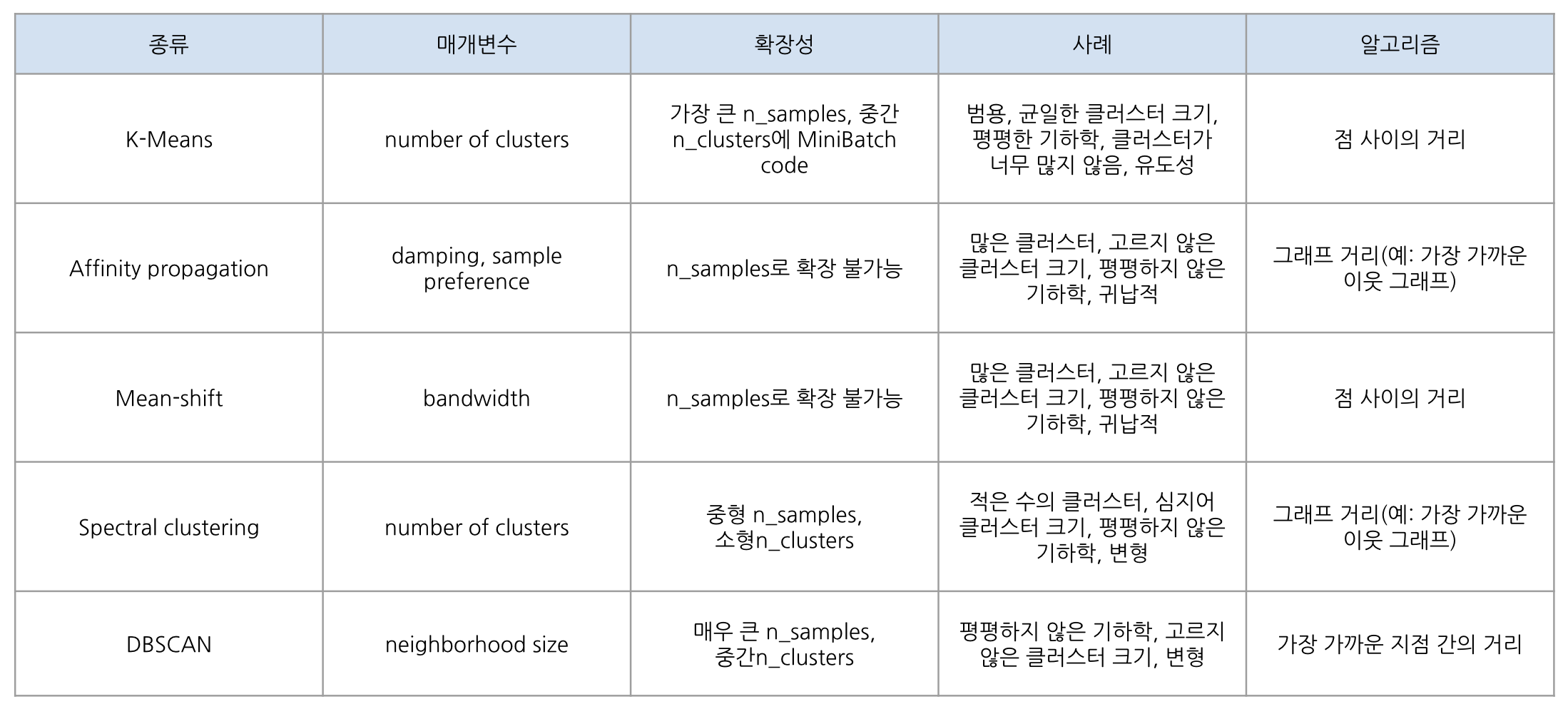
🤔 Normalisation과 Scaling을 해줘야 하는 이유?
거리를 구하기 때문에 군집화 할 때 스케일이 너무 큰 차이가 나지 않게 Log변환을 해서 정규분포 형태로 변경하고 StandardScaler()로 평균을 0, 편차를 1로 만들어줘야 함.
💡
Log 변환 먼저 하고 Scaling하는거 꼭꼭 기억하기
📌 K-Means
-
입력값
- k: 클러스터 수
- D: n 개의 데이터 오브젝트를 포함하는 집합
-
출력값: k 개의 클러스터
-
알고리즘
- 데이터 오브젝트 집합 D에서 k 개의 데이터 오브젝트를 임의로 추출하고, 이 데이터 오브젝트들을 각 클러스터의 중심 (centroid)으로 설정한다. (초기값 설정)
- 집합 D의 각 데이터 오브젝트들에 대해 k 개의 클러스터 중심 오브젝트와의 거리를 각각 구하고, 각 데이터 오브젝트가 어느 중심점 (centroid) 와 가장 유사도가 높은지 알아낸다. 그리고 그렇게 찾아낸 중심점으로 각 데이터 오브젝트들을 할당한다.
- 클러스터의 중심점을 다시 계산한다. 즉, 2에서 재할당된 클러스터들을 기준으로 중심점을 다시 계산한다.
- 각 데이터 오브젝트의 소속 클러스터가 바뀌지 않을 때까지 2, 3 과정을 반복한다.
클러스터의 거리를 계산할 때 같은 클러스터끼리는 가까운 거리에 있어야 하고
다른 클러스터와는 멀리 떨어져 있어야지 잘 군집화가 되었다고 평가할 수 있습니다.
=> Elbow, 실루엣 기법 등을 사용해서 평가하게 됩니다.
✅ Elbow analysis
✅ Silhouette analysis
실루엣 분석은 각 군집 간의 거리가 얼마나 효율적으로 분리돼 있는지를 나타냅니다. 효율적으로 잘 분리됐다는 것은 다른 군집과의 거리는 떨어져 있고 동일 군집끼리의 데이터는 서로 가깝게 잘 뭉쳐 있다는 의미
-
좋은 군집화가 되기 위한 기준 조건
- 전체 실루엣 계수의 평균값, 즉 사이킷런의 silhouette_score() 값은 0~1 사이의 값을 가지며, 1에 가까울수록 좋습니다.
- 하지만 전체 실루엣 계수의 평균값과 더불어 개별 군집의 평균값의 편차가 크지 않아야 합니다. 즉, 개별 군집의 실루엣 계수 평균값이 전체 실루엣 계수의 평균값에서 크게 벗어나지 않는 것이 중요합니다. 만약 전체 실루엣 계수의 평균값은 높지만, 특정 군집의 실루엣 계수 평균값만 유난히 높고 다른 군집들의 실루엣 계수 평균값은 낮으면 좋은 군집화 조건이 아닙니다.
정답 레이블을 모르는 경우 모델 자체를 사용하여 평가를 수행해야 합니다.
-
실루엣 계수( sklearn.metrics.silhouette_score)는 이러한 평가의 한 예이며 실루엣 계수 점수가 높을수록 클러스터가 더 잘 정의된 모델과 관련됩니다. 실루엣 계수는 각 샘플에 대해 정의되며 두 가지 점수로 구성됩니다.
-
a : 샘플과 동일한 클래스의 다른 모든 점 사이의 평균 거리.
-
b : 표본과 다음으로 가장 가까운 군집 의 다른 모든 점 사이의 평균 거리
단일 샘플에 대한 실루엣 계수 s 는 다음과 같이 주어집니다.s = (b-a)/max(a,b)
-
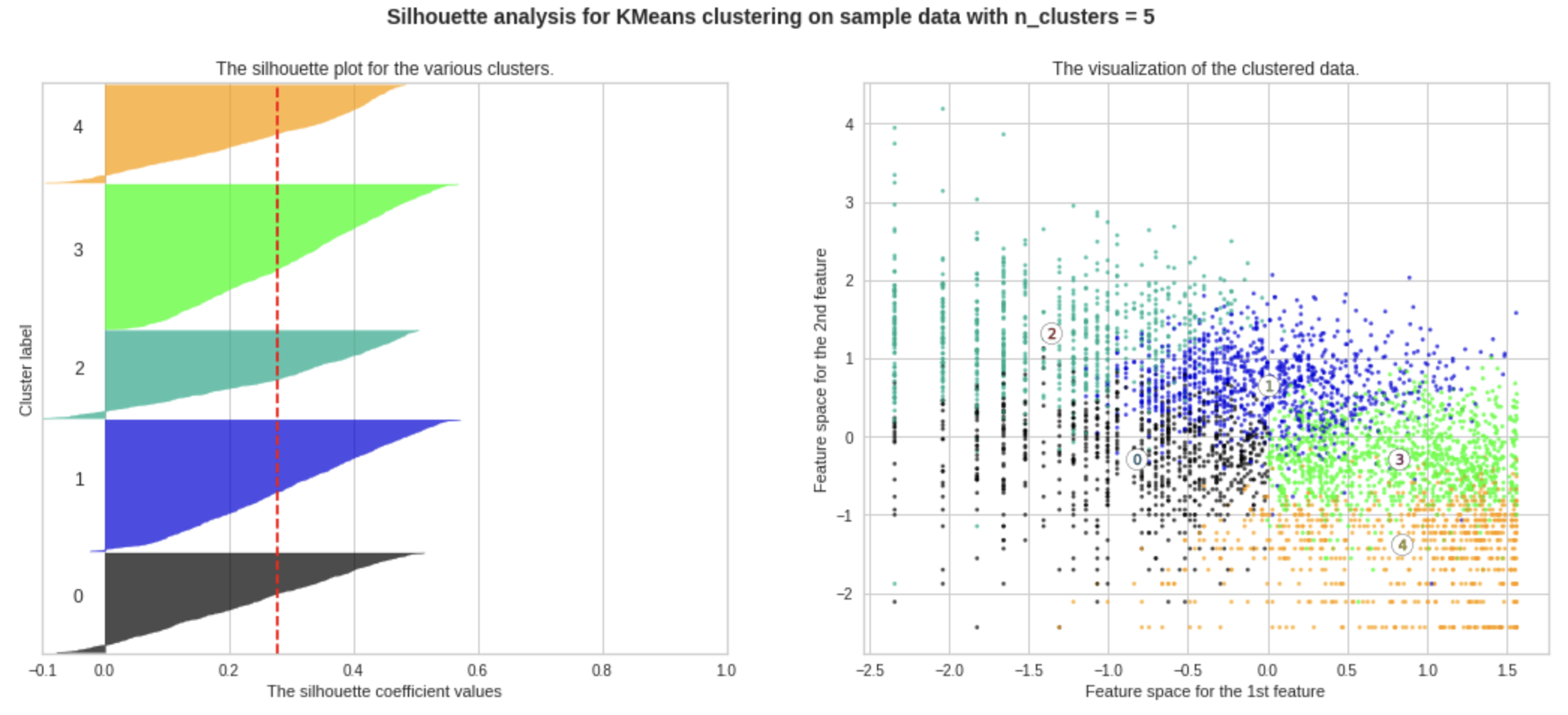
왼쪽 그래프) 1에 가까울 수록 잘 예측한 것인데 -0.1에 가까운 것은 잘 예측이 되지 않은 것으로 볼 수 있다. 빨간 선은 실루엣 계수의 평균을 나타낸다.
왼쪽 그래프가 마이너스 값으로 갈 수록 오른쪽 그래프의 점들이 겹치게 된다.
✅ Hierarchical clustering analysis
✅ DBSCAN (Density-based spatial clustering of applications with noise)
🤔 이상치 탐지에 주로 사용하는 군집화 기법은 무엇일까요?
DBSCAN => 이상치는 군집에 포함시키지 않습니다. 그래서 이상치 탐지에 주로 사용합니다.
추천시스템
추천시스템 실습파일은 13번 부터 시작하고
1) online-retail => movie 데이터로 실습하는 순서로 구성이 되어 있습니다.
2) output 파일을 먼저 실행해 보고 input 에 옮겨적는 스터디를 해봐도 좋겠습니다.
3) 콘텐츠 기반(01 online-retail => 02 movie) => 협업필터링(03 online-retail => 04 movie) 순으로 파일이 되어 있습니다.
SVD => 특잇값 분해 => 이미지 데이터 압축, 텍스트 데이터 차원 축소로 내용은 요약하면서 데이터 용량은 줄일 때
Item2Vec => 문서 유사도를 사용해서 콘텐츠 베이스 추천을 하게 되면 비슷한 문서를 추천해 줄 수 있습니다. 해당 문서와 유사도 값이 높은 문서를 추천해 주게 됩니다.
🤔 OTT 서비스를 오픈했는데 오픈 초기라서 유저의 행동 정보가 없습니다. 어떻게 추천을 해주면 좋을까요?
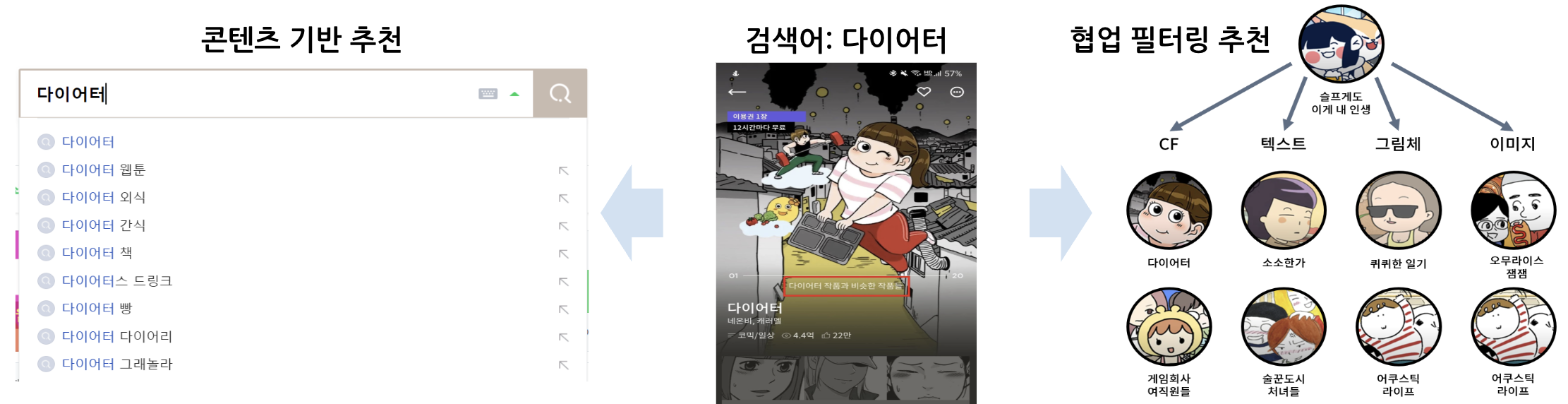
고객이 어떤 작품을 봤다면 해당 작품의 정보를 참고해서 비슷한 작품 설명을 갖고 있는 작품을 추천합니다. 이것이 콘텐츠 기반 추천시스템 입니다.
📌 컨텐츠 기반 추천 - Vector Siliarity
💡 콘텐츠 기반 추천 시스템은 주로 서비스 초반 (고객의 행동정보가 없을 때)에 사용하고, 유저의 정보가 어느정도 쌓이면 협업필터링을 사용하는 하이브리드 추천 방식을 사용
💡 장점:
- 협업필터링은 다른 사용자들의 평점이 필요한 반면에, 콘텐츠 기반 모델은 자신의 평점만을 가지고 추천 시스템을 만들 수 있음
- item 특징을 통해서 추천을 하기에 추천이 된 이유 설명 가능
- 아이템의 속성 (콘텐츠)을 기반으로 추천하기 때문에 이전에 선택 이력이 없는 새로운 아이템도 추천 가능
💡 단점:
- item의 특징을 추출해야하고 이를 통해 추천하기 때문에 제대로 특징을 추출하지 못하면 정확도가 낮아 도메인 지식이 필요
- 해당 고객에 대한 데이터가 부족한 경우 추천 성능 보장이 어려움
- 과도한 특수화 (over specialisation): 이전에 구매 및 선택한 아이템과 비슷한 제품만 추천하는 경향
✅ 유클리디안 유사도
: 텍스트 간의 거리를 구하고 유클리드 공간에서의 최단거리 (직선거리)를 계산한다. 유클리드 거리의 값이 가장 작다는 것은 문서 간의 거리가 가장 가깝다는 것을 의미
💡 장점: 계산하기 쉬움
💡 단점: 결과 값이 1보다 큰 값이 나올 수 있으므로 값을 제한하는 과정이 필요, 분포가 다르거나 범위가 다른 경우에 상관성을 놓침
✅ 코사인 유사도
: 내적 공간 내에서 두 벡터 사이의 코사인 각도를 구하는 방법 (-1~1 사이의 값을 가지며, 1에 가까울수록 유사도가 높음)
💡 장점: 어떤 개수의 차원에도 적용할 수 있지만 흔히 다차원의 양수 공간에서의 유사도 측정에서 자주 이용
💡 단점: 상호 상관관계를 가지는 특성 (키, 몸무게 등)을 갖는 원소들간의 유사도를 계산할 때 성능이 낮음
✅ 피어슨 유사도
: 두 벡터가 주어졌을 때의 상관관계를 계산하며 각 벡터의 표본평균으로 정규화
💡 장점: 양적 변수들의 사이의 선형관계를 확인하기 쉬움. 코사인 유사도의 평점 부분에 각 유저의 평균값을 뺀 값 확인 가능
💡 단점: 코사인 유사도와 마찬가지로 벡터가 지닌 스칼라들의 값의 크기에 대한 고려를 하지 않음
✅ 자카드 유사도
: 두 문장을 각 단어의 집합으로 생성한 뒤, 생성된 집합을 통해 유사도 측정 (고객간 유사도)
- 0, 1 바이너리 데이터로 만든 후, 합집합과 교집합 사이의 비율로 나타냄 (집합의 개념 이용)
- 얼마나 많은 아이템을 동시에 갖고 있는지를 수치로 환산하고, 함께 갖고 있는 아이템이 없다면 0, 아이템 전체가 겹치면 1
💡 장점: 대표적인 이진 평가데 대한 유사도를 측정할 수 있는 지표, 동시 출현빈도 고려
💡 단점: 데이터가 순서나 양을 갖는 집합 데이터라면 낮은 성능을 보임
📌 협업필터링 기반 추천
🤔 online-retail 데이터로 유저-아이템-행렬을 만든다면? 어떻게 만들면 될까요?
행 인덱스가 user, 열이 item 이 되도록 만든다.
🖇 추천자료
💡 린분석 with 레진코믹스
서비스 기획자를 위한 데이터분석 시작하기
토스 리더가 직접 답해드립니다 | PO SESSION Q&A
✏️ TIL
- 사실(Fact): 추천시스템에 대해 배웠다.
- 느낌(Feeling): 추천시스템은 정말 신기하다. 프로젝트에 녹여낼 수 있으면 좋을것 같다. 오늘이 마지막 수업인게 많이 아쉽다..🥹
- 교훈(Finding): 지금까지 배웠던 내용을 내걸로 만들자!
