
기존에는 데이터를 나눌 때 섞어서 나누었습니다. 그런데 시계열 데이터에서는 섞어서 나누지 않고 순서를 고려해서 나누게 됩니다.
자연어 텍스트를 시퀀스 인코딩 했던 것처럼 언어도 맥락이 있기 때문에 섞으면 원래 의미를 잃어버릴 수 있습니다. 시계열 데이터에서도 순서가 중요합니다.
예를 들어 지난 일년 간의 데이터를 통해 앞으로 일주일 간의 데이터를 예측한다고 했을 때도 윈도우를 밀어서 앞으로 예측할 일주일 데이터도 일주일치를 한번에 예측하게 하지 않고 그 전날까지의 데이터를 가지고 와서 다음날을 예측하게 합니다.
🤔 시계열 데이터로 예측해 볼 수 있는게 무엇이 있을까요?
주가, 부동산 가격, 판매량, 재고량, 매출액, 신선식품 업체의 유통량, 농수산물가격, 동시접속자수, 서비스이용 고객수, 식물의 성장예측, 트래픽량
1107 실습: RNN 으로 주가예측하기
💡 실습 순서
1) 데이터 로드
2) x,y 데이터셋 나누기
3) 정규화(MinMax)
4) 윈도우 방식으로 ,y 값 만들기
5) 순서를 고려해서 데이터셋 만들기
6) 모델 만들고 예측하기
bike-sharing-demand를 실습했을 때 날짜, 시간 데이터가 있었습니다. 그런데 그 데이터로 시계열 방법을 사용하기 보다는 회귀 방법을 사용했습니다. 시계열을 사용해서 예측해 볼 수도 있기는 합니다.
🤔 왜 시계열 방법을 사용하지 않고 회귀 방법을 사용했었을까요?
시간대별로 binning 이 되어있기는 한데, 지금 주가 데이터도 일자별로 binning 이 되어있는 상태입니다.
이전 시점이 고려되지 않았을 때:
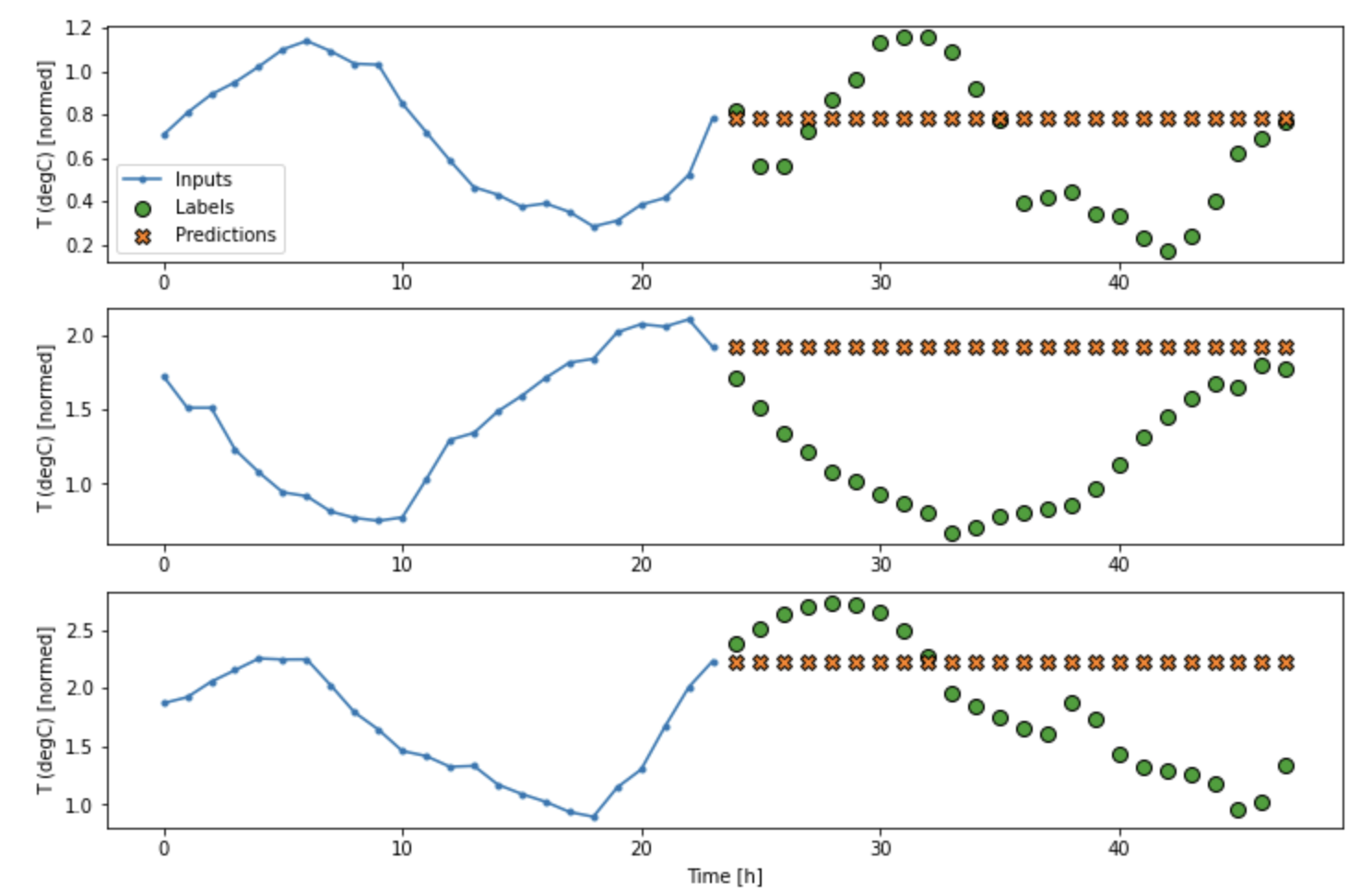
이전 시점이 고려되었을 때:
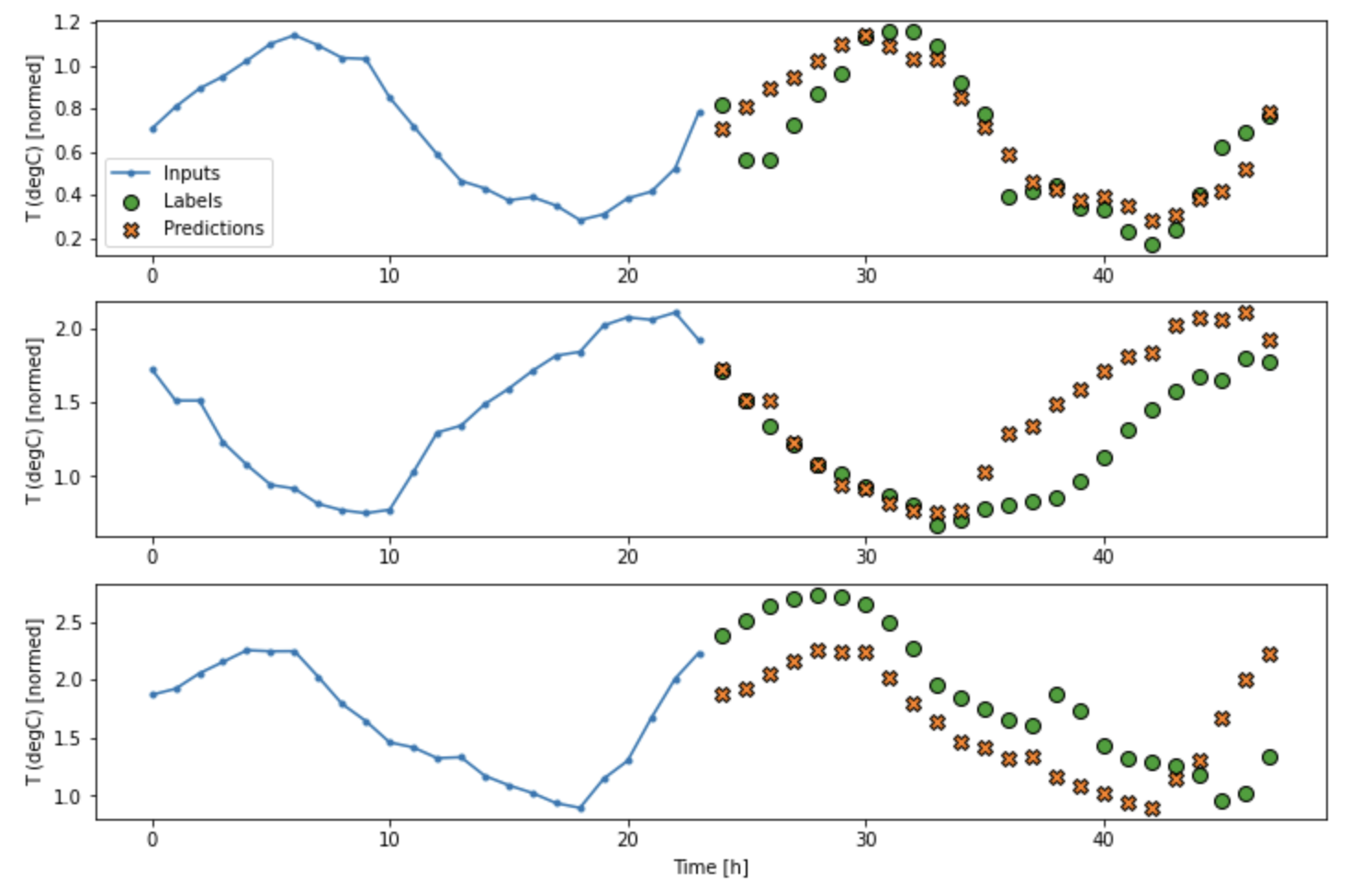
1~9일 사이의 학습데이터로 타겟값 10일로 학습을 합니다.
X : 1~9일
y : 10일
🤔 왜 X 값에 10일까지 넣어주지 않을까요?
과거로 미래를 예측해야하기 떄문에 정형데이터에서 정답을 문제에 포함시키지 않는 것과 동일합니다.
🤔 학습이라는게 예측해서 학습하는건가요 아니면 정답을 외우는느낌인가요?
머신러닝의 학습입니다. 기존의 머신러닝, 딥러닝과 시계열데이터는 데이터를 나눠주는 방법의 차이일 뿐이지 학습, 예측과정은 동일합니다. 정답을 학습 데이터에 넣어주면 그건 데이터 누수입니다.
비즈니스 데이터 분석과 군집화 (비지도 학습)
💡 비즈니스 KPI에 대해 알아보고 해당 데이터를 통해 추천시스템까지 구현해볼 예정

🤔 오거닉은 무슨 의미일까요?
오가닉 트래픽(Organic Traffic)이란 광고나 소셜미디어, 리퍼럴 사이트와 같은 채널을 통해 사이트로 유도되는 트래픽을 제외하고 검색 엔진을 통해 곧바로 유입되거나 동일한 도메인 안에서 유입되는 트래픽을 말한다. (= 돈을 들이지 않고 유입된 트래픽)
📌 AARRR
: 시장 초기 단계에 맞춰서 특정한 지표를 중심으로 서비스의 현주소를 파악할 수 있는 효과적인 방법
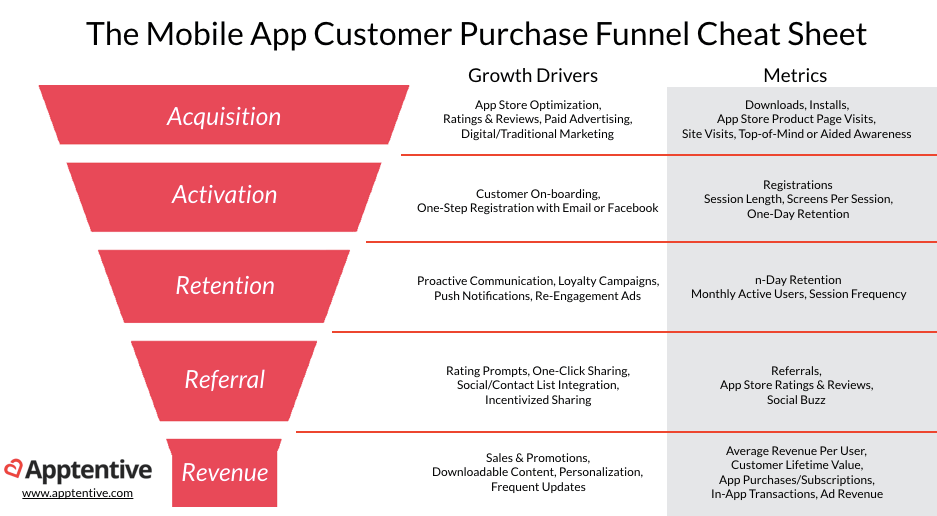
출처: https://www.apptentive.com/blog/app-marketing-metrics-for-pirates/
- Acquisition : 어떻게 우리 서비스를 접하고 있는가
- Activation : 사용자가 처음 서비스를 이용할 때 긍정적인 경험을 제공하는가
- Retention : 이후의 서비스 재사용률은 어떻게 되는가
- Referral : 사용자가 자발적 바이럴, 공유를 일으키고 있는가
- Revenue : 최종 목적(매출)으로 연결되고 있는가
📌 Cohort Analysis
💡 cohort는 ‘특정 기간 동안 공통된 특성이나 경험을 갖는 사용자 집단‘을 의미: 분석 전에 데이터 세트의 데이터를 관련 그룹으로 나누는 일종의 행동 분석
- 시간집단: 특정 기간 동안 제품이나 서비스에 가입한 고객 (서비스 사용 시작 시점 파악)
- 행동집단: 과거에 제품을 구매했거나 서비스에 가입한 고객 (그룹별 니즈에 대한 이해로 맞춤형 서비스 설계에 도움)
가입한 제품 또는 서비스 유형에 따라 고객을 그룹화 => 기본 서비스와 고급 서비스 고객의 요구가 다를 수 있음 - 규모집단: 회사의 제품이나 서비스를 구매하는 다양한 규모의 고객 (특정 기간의 지출 또는 구매한 제품 기반)
📌 Retention rate Analysis (잔존율 분석)
: 고객이 이탈하는 방법과 이유를 이해하기 위해 사용자 메트릭을 분석하는 과정
- 유지 분석은 유지 및 신규 사용자 확보율을 개선하여 수익성 있는 고객 기반을 유지방법 확보
- 일관된 유지 분석을 통해 알 수 있는 항목:
- 고객이 이탈하는 이유
- 고객이 떠날 가능성이 더 높을 때
- 이탈이 수익에 미치는 영향
- 유지 전략을 개선하는 방법
🤔 온라인 강의에서 처음부터 평생 수강권을 주지 않고 30일 수강권을 주고 절반 이상 수강하면 평생 수강할 수 있게 해주고 그 다음에 다른 강의를 수강할 수 있는 쿠폰을 준다?!
회사나 제품마다 측정하는 메트릭이 다 다릅니다. 절반 이상 수강했다면 다른 강의를 수강할 확률이 높아진다? 이런 것들을 데이터 분석을 통해 얻을 수 있겠죠.
=> 데이터 분석을 통해 해당 제품에서 어떤 지표를 볼 것인지를 정하게 되죠. 특정 제품에서 가장 중요시 여기는 지표를 북극성지표라고 부르기도 합니다.
1201 실습
💡 online retail data 실습 순서
1) EDA(리텐션)
2) RFM(segmentation)을 판다스로 구하고
3) 군집화로 고객 세분화(segmentation)
4) 유사도를 통한 추천시스템
style.format("{:,.0f}"): 모든 데이터에 대해 천 단위마다 , 표시를 하고 소숫점은 표시하지 않는다.
🤔 Description 항목을 groupby 에 사용하지 않은 이유?
Description 항목을 groupby 에 사용하면 StockCode 가 같은데도 다른 Description 이라면 함께 집계되지 않습니다. StockCode 기준으로 집계하기 위해 집계 후에 Description 을 구해주었습니다.
🦁 질문
Q: 혹시 2차원으로 만들기 위해서 x_data.extend(x_mm[start:stop]) 이렇게 해도 되나요??
A: 이렇게 하면 원하는 윈도우 형태의 시점을 만들 수 없어요. append 로 해당 시점의 윈도우가 행이 되게 만들어 주어야 합니다.
✏️ TIL
- 사실(Fact): 시계열 데이터와 비즈니스 데이터 분석에 대해 배웠다.
- 느낌(Feeling): 오늘 수업은 몇 달 전의 수업을 복습하는 것 같았다. 그때의 나는 같은 내용을 배우며 힘들었는데 몇 달 새에 많이 성장한 것 같아 뿌듯하다.
- 교훈(Finding): 꾸준히 성장하자!
