
✨ 처음부터 차근차근, 내 페이스 대로 ✨
강의: 부스트코스 - 프로젝트로 배우는 데이터사이언스
데이터셋 출처: Pima Indians Diabetes Database | Kaggle
3. Feature Engineering
3.2 결측치 다루기
결측치를 제거할 수도 있지만 결측치가 너무 많을 경우에서는 채워주는 것이 좋다.
1. 결측치 확인하기
2. describe값 확인하기
3. 결측치 NaN 값으로 변경하기
💡 (새로운 변수를 만들어 기존 변수와 비교하여 값이 잘 변경 됐는지 확인하는 것이 좋다)
df["Insulin_nan"] = df["Insulin"].replace(0, np.nan)
4. Nan값으로 변경한 변수의 결측치 확인 (sum, mean and describe)
# 결측치 처리 한 데이터와 하지 않은 데이터의 평균값과 중앙값 차이 확인하기
df.groupby(["Outcome"])[["Insulin", "Insulin_nan"]].agg(["mean", "median"])
5. 결측치 채우기 (mean / median)
# 해당 실습에서는 결측치를 평균값으로 채워줌
Insulin_mean = df.groupby("Outcome")["Insulin_nan"].mean()
Insulin_mean
df["Insulin_fill"] = df["Insulin_nan"]
df.loc[(df["Outcome"] == 0) & df["Insulin_nan"].isnull(), "Insulin_fill"] = Insulin_mean[0]
df.loc[(df["Outcome"] == 1) & df["Insulin_nan"].isnull(), "Insulin_fill"] = Insulin_mean[1]
df[["Insulin", "Outcome", "Insulin_nan", "Insulin_fill"]].sample(5)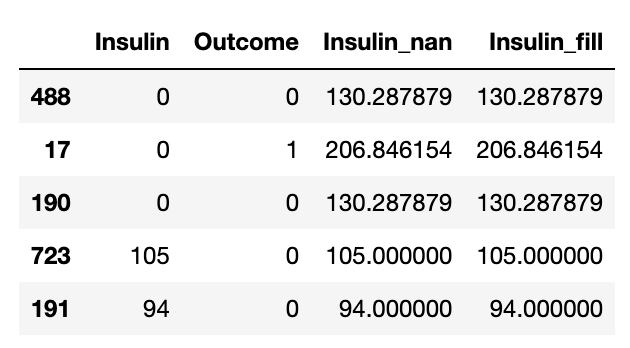
df.loc[조건, "column 이름"] = 변경 값
👉🏻 column에서 조건에 부합하는 데이터를 변경 값으로 변경해줘
3.3 수치형 변수 정규분포 형태로 만들기 (log)
log변환을 하여 전처리 하는 방법- 왜도: 한쪽으로 치우쳐져 있는 정도
- 첨도: 뾰족한 정도
# 왼쪽으로 치우쳐져있고 뾰족하다
sns.distplot(df["Insulin_fill"])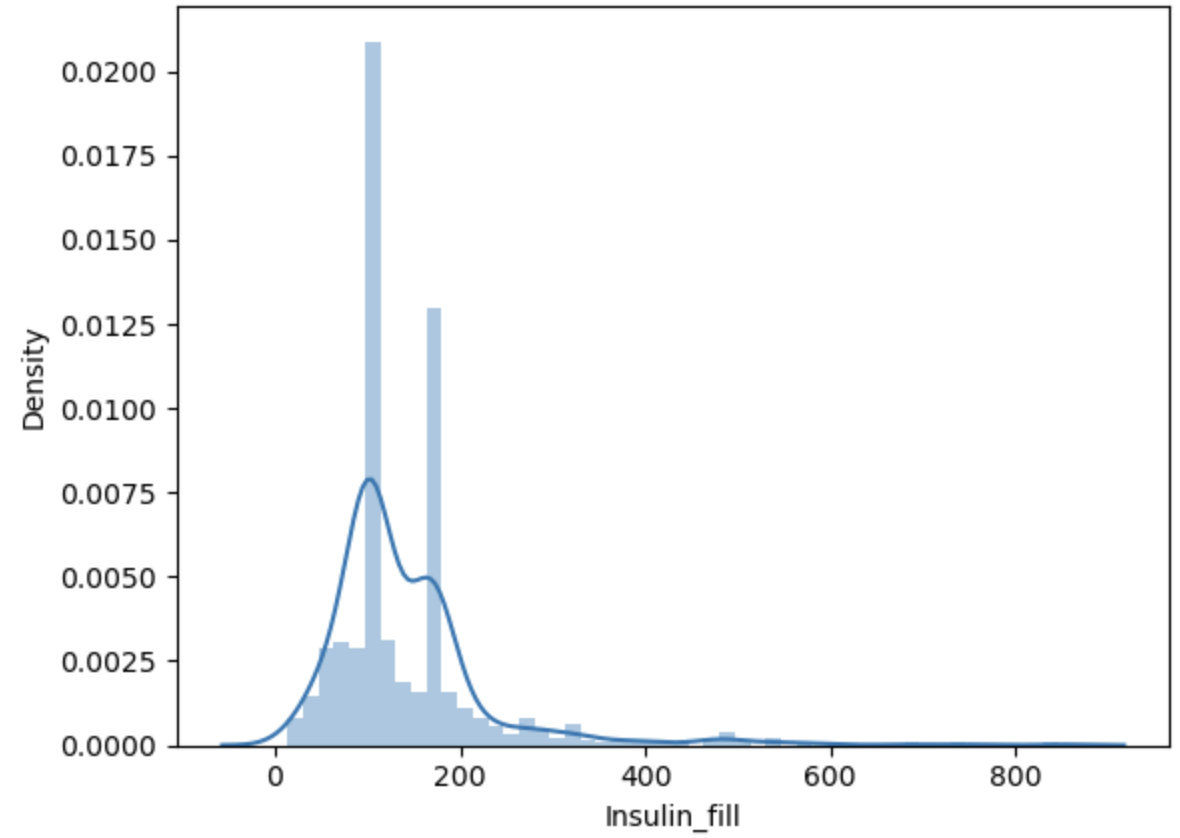
# log 변환으로 정규분포 형태로 만들어주기
df["Insulin_log"] = np.log(df["Insulin_fill"] + 1)
sns.displot(df["Insulin_log"])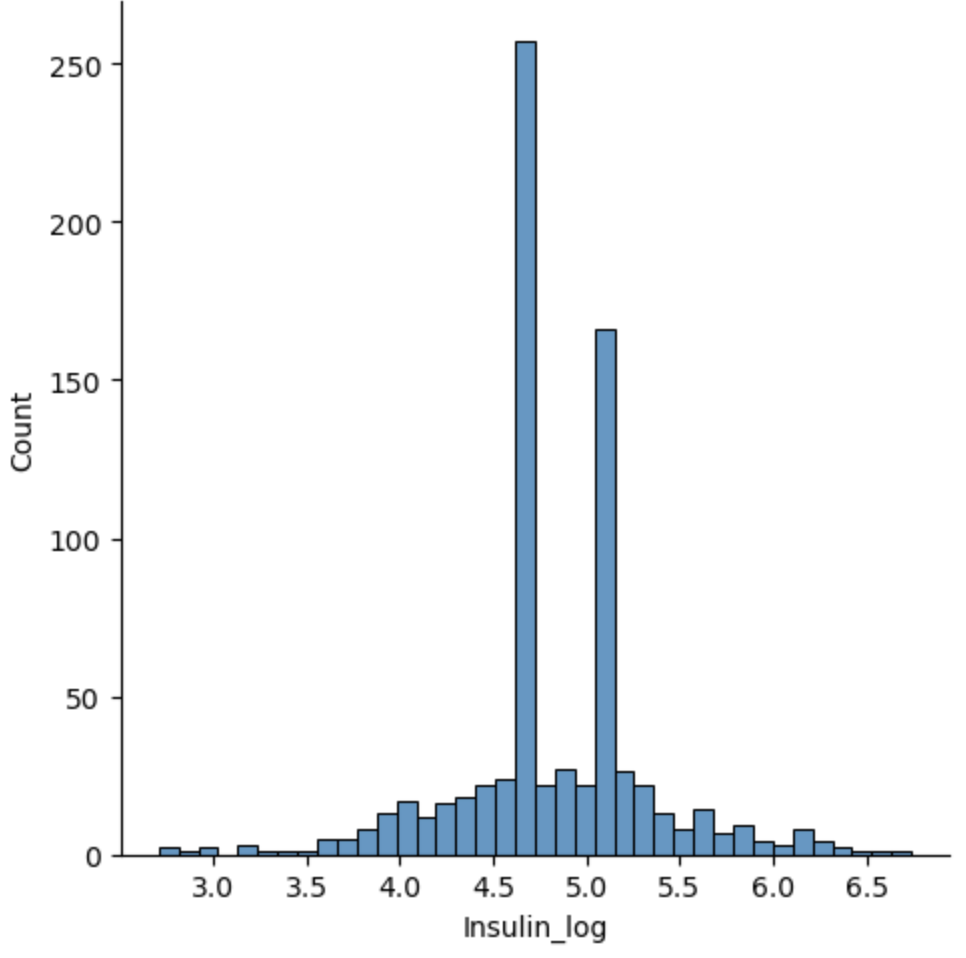
로그를 씌우고 나니 정규분포를 이루는 것을 확인. 머신러닝과 딥러닝은 정규분포를 이루고 있을 때 더 좋은 성능을 낸다.
3.4 상관분석을 통해 새로운 파생변수 생성하기
# Outcome == 0; 인슐린과 글루코스가 100 이하일 때는
# 당뇨병이 발병 수가 현저히 낮기 때문에 이를 이용해 파생변수 생성
sns.lmplot(data=df, x="Insulin_fill", y="Glucose", hue="Outcome")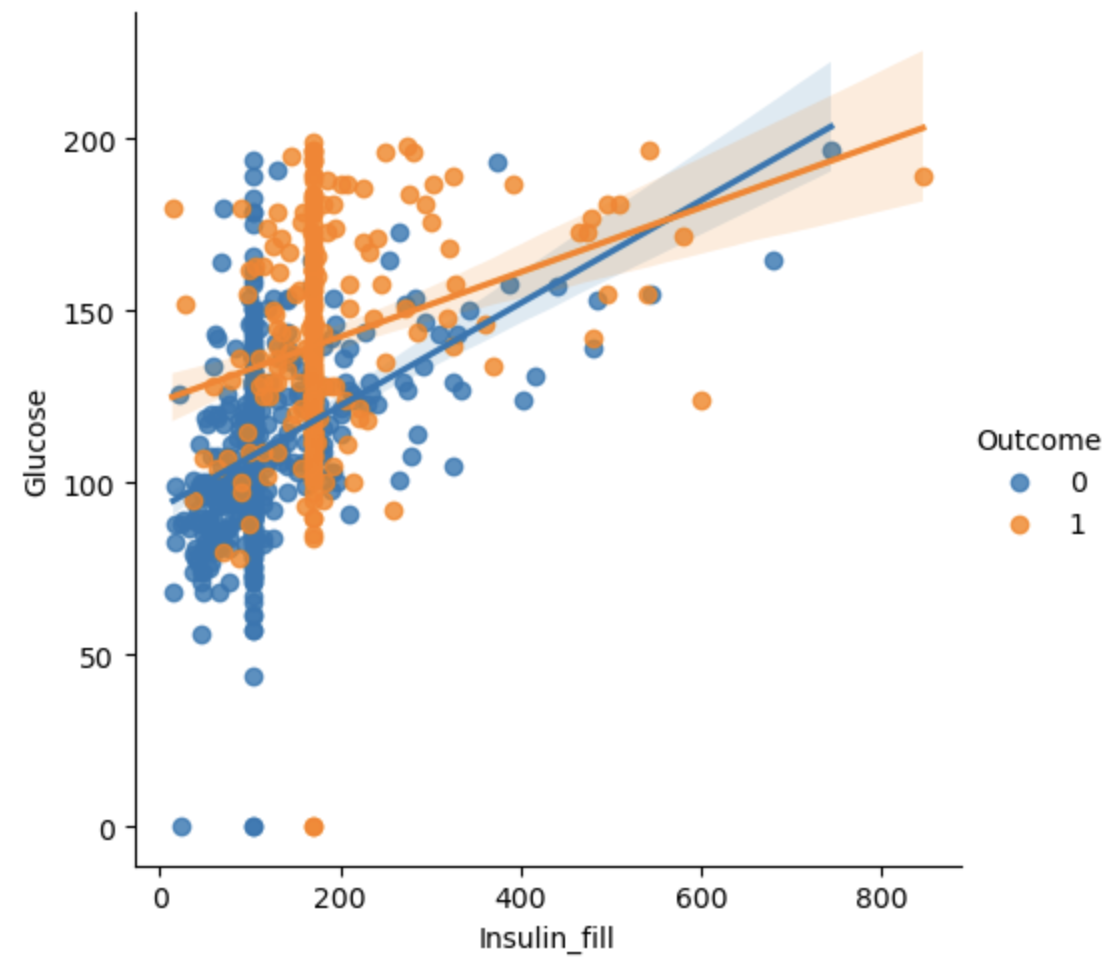
👉🏻 한 줄로 생긴 줄은 중앙값으로 결측치를 채워준 값
# 102는 Outcome이 0일 때 인슐린 결측치로 채워준 중앙값
# 인슐린과 글루코스 상관계수로 파생변수 생성
df["low_glu_insulin"] = (df["Glucose"] < 100) & (df["Insulin_fill"] <= 102.5)
df["low_glu_insulin"].head()pd.crosstab(): 범주형 값에 대한 cross table을 그려주는 기능
# 글루코스와 인슐린 수치가 낮은 사람에 대한 당뇨병 발병 수치 (5)가 낮다
pd.crosstab(df["Outcome"], df["low_glu_insulin"])
3.5 Outlier
1. Boxplot 그리기
plt.figure(figsize=(15, 2))
sns.boxplot(data = df, x=df["Insulin_fill"])
2. describe값 확인
df["Insulin_fill"].describe()
👉🏻 75% 값과 max 값이 굉장히 차이가 많이 나는 것을 확인 할 수 있다
3. Outlier 기준 만들기
IQR3 = df["Insulin_fill"].quantile(0.75)
IQR1 = df["Insulin_fill"].quantile(0.25)
IQR = IQR3 - IQR1
OUT = IQR3 + (IQR * 1.5)
4. Outlier 개수 확인
df[df["Insulin_nan"] > OUT].shape
=> (51, 17) # Outlier == 51개, 모두 제거하기엔 너무 많은 양
# boxplot에서 600이상인 데이터는 3개이기 때문에 이 값들을 제거하기로 결정
df[df["Insulin_nan"] > 600].shape❗️ 이상치를 제거는 train 데이터셋에서만!!!
test 데이터셋은 미래에 들어올 데이터인데 미래에 들어올 데이터는 제거 불가능하기 때문
3.6 Feature Scaling
- 숫자의 범위가 다르면 feature 별로 비중이 다르게 계산될 수 있으므로 스케일링 기법을 사용 => 예측의 정확도를 높일 수 있음
# DiabetesPedigreeFunction와 Glucose의 숫자 범위가 너무 달라 숫자를 변형 시켜주는 작업
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(df[["Glucose", "DiabetesPedigreeFunction"]])
scale = scaler.transform(df[["Glucose", "DiabetesPedigreeFunction"]])전처리는 EDA를 먼저 진행해 인사이트를 얻은 후 진행
✅ 오늘까지 수강 완료한 섹션:
3. 탐색한 데이터를 바탕으로 모델의 성능 개선하기

데이터 분석가가 되기 위한 기록 ✏️