
❗ 해당 게시물에서 다루고 있는 코드는 멋쟁이사자처럼 AI SCHOOL 7기에서 제공되었습니다.
네이버 금융 뉴스기사 수집
수집할 url 가져오기
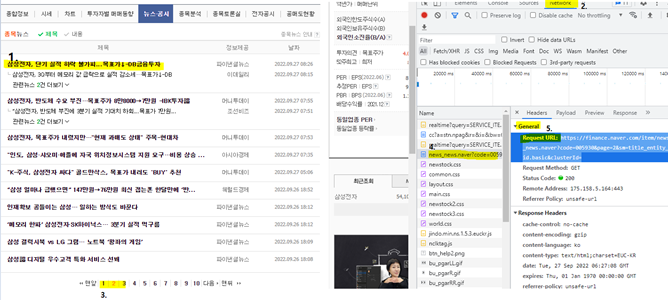
- 웹 사이트에서 오른쪽 클릭 - 검사
- network 탭 클릭
- 페이지 넘기며 생성되는 파일 확인 (❗ 주기적으로 🚫버튼 누르며 파일 생성창 새로고침)
- 원하는 정보를 담고있는 파일 클릭 (Preview 탭에서 내용 확인 가능)
- Headers 탭에서 url 복사
# 수집할 url을 가져옵니다.
item_code = "000660"
item_name = "SK하이닉스"
page_no = 1
url = f"https://finance.naver.com/item/news_news.naver?code{item_code}&page=2&sm=title_entity_id.basic&clusterId="
print(url)read_html로 수집하기
# 네이버 금융의 주가 기사를 read_html로 수집해서 table 이라는 변수에 넣기
table = pd.read_html(url)
table
# 몇개의 테이블을 불러왔는지 확인
len(table)데이터프레임 만들기
# table의 0번째 인덱스 값 (첫번째 테이블)을 df 라는 변수에 담습니다.
df = table[0]
# column 이름 지정 - 알아보기 힘든 column의 이름을 제목, 정보제공, 날짜 등 으로 변경
cols = df.columns
cols반복문으로 데이터 모두 가져오기 - for문 사용
# 수집한 값을 담을 변수 생성
temp_list = []
cols = table[0].columns
# 마지막 테이블은 페이지라 삭제
for news in table[:-1]:
news.columns = cols
temp_list.append(news)
display(news)수집한 데이터 하나의 데이터프레임으로 합치기
concat()
axis=0 행을 기준으로 위아래로 같은 컬럼끼리 값을 이어 붙여 새로운 행을 만듦
axis=1 컬럼을 기준으로 인덱스가 같은 값을 옆으로 붙여 새로운 컬럼을 만듦
dropna(): 결측치 제거
# 데이터프레임 합치기
df_news = pd.concat(temp_list)
# 결측치 제거
df_news = df_news.dropna()수집한 기사 "제목"에 "연관기사"가 들어가는 데이터 제거하기
.str.contains 를 사용하며 조건의 반대에는 앞에 ~ 표시로 표현할 수 있습니다.
~: 비트와이즈 연산으로 값을 반전시킨다; not
drop = True 안 하면 index 하나 더 생성됨
.drop_duplicates(): 중복 값 제거
# 인덱스 번호를 순차로 초기화하고 열 기준으로 합치기
df_news = df_news.reset_index(drop=True)
# "정보제공" column에서 "연관기사"가 들어가는 데이터 ~ 사용해서 제거
# 원본에 영향을 주지 않기 위해 깊은 복사 사용
df_news = df_news[~df_news["정보제공"].str.contains("연관기사")].copy()
# 중복된 데이터가 있다면 제거
df_news = df_news.drop_duplicates()얕은 복사 👉 원본 값이 같이 변경
s1 = pd.Series([1,2,3,4])
s2 = s1
깊은 복사 👉 원본에 영향 없음
s1 = pd.Series([1,2,3,4])
s2 = s1.copy()
함수로 정리
# get_url item_code, page_no 를 넘기면 url 을 반환하는 함수
def get_url(item_code, page_no):
"""
item_code, page_no 를 넘기면 url 을 반환하는 함수
"""
url = f"https://finance.naver.com/item/news_news.naver?code={item_code}&page={page_no}&sm=title_entity_id.basic&clusterId="
return url
item_code = "000660"
page_no = 5
temp_url = get_url(item_code, page_no)
print(temp_url)Summary: 뉴스 한 페이지 수집하기
!pip install -U finance-datareader
import pandas as pd
import numpy as np
# get_one_page_news 함수 만들기
def get_one_page_news(item_code, page_no):
"""
get_url 에 item_code, page_no 를 넘겨 url 을 받아오고
뉴스 한 페이지를 수집하는 함수
1) URL 을 받아옴
2) read_html 로 테이블 정보를 받아옴
3) 데이터프레임 컬럼명을 ["제목", "정보제공", "날짜"]로 변경
4) temp_list 에 데이터프레임을 추가
5) concat 으로 리스트 병합하여 하나의 데이터프레임으로 만들기
6) 결측치 제거
7) 연관기사 제거
8) 중복데이터 제거
9) 데이터프레임 반환
"""
# 1) URL 을 받아옴
url = get_url(item_code, page_no)
# 2) read_html 로 테이블 정보를 받아옴
table = pd.read_html(url, encoding="cp949")
# 3) 데이터프레임 컬럼명을 ["제목", "정보제공", "날짜"]로 변경
# 4) temp_list 에 데이터프레임을 추가
temp_list = []
cols = table[0].columns
for news in table[:-1]:
news.columns = cols
temp_list.append(news)
# 5) concat 으로 리스트 병합하여 하나의 데이터프레임으로 만들기
df_news = pd.concat(temp_list)
# 6) 결측치 제거
df_news = df_news.dropna()
# 7) 연관기사 제거
df_news = df_news.reset_index(drop=True)
df_news = df_news[~df_news["정보제공"].str.contains("연관기사")].copy()
# 8) 중복데이터 제거
df_news = df_news.drop_duplicates()
# 9) 데이터프레임 반환
return df_newsFinanceDataReader로 정보 수집
import FinanceDataReader as fdr
df_krx = fdr.StockListing("KRX")
df_krx.shape
page_no = 1
item_code = df_krx.loc[df_krx["Name"] == "에코프로비엠", "Symbol"].values[0]
temp = get_one_page_news(item_code, page_no)
temp반복문을 사용해 10 페이지 수집하고 저장하기
from tqdm import trange: 오래 걸리는 작업 시 진행상태 표시
time.sleep(): 반복문 사이 쉬어가는 시간 설정 - 웹 스트래핑의 매너
df.to_csv(file_name, index=False): 파일로 저장하기
pd.read_csv(file_name): 파일 읽어오기
import time
# 범위가 정해져 있을 때 사용가능 -- while문에서는 사용하기 힘들다
from tqdm import trange
# 종목명을 변수로 정해 item_code에서 자동으로 종목명을 받아 출력하도록 함
# Symbol은 종목코드
item_name = "에코프로비엠"
item_code = df_krx.loc[df_krx["Name"] == item_name, "Symbol"].values[0]
# 데이터 담을 변수 생성
news_list = []
# 10 페이지 가져오기 -- 페이지 갯수를 정해서 원하는 만큼 불러올 수 있음.
for page_no in trange(1,11):
temp = get_one_page_news(item_code, page_no)
news_list.append(temp)
time.sleep(0.1)
# 데이터프레임 하나로 합치기
df_news = pd.concat(news_list)
# 파일 이름 지정
file_name = f"news_{item_code}_{item_name}.csv"
# 파일 저장
df_news.to_csv(file_name, index = False, encoding="cp949")
# 파일 읽어오기
pd.read_csv(file_name, encoding="cp949")
데이터 분석가가 되기 위한 기록 ✏️