
💡 개념
복잡한 문제를 여러 개의 간단한 문제로 분리하여 부분의 문제들을 해결함으로써 최종적으로 복잡한 문제의 답을 구하는 방법을 뜻한다.
큰 문제를 작은 문제로 나눈 뒤, 기억하여 푸는 방법
📝 DP 기법을 적용시킬 수 있는 조건과 구현 방식
- 큰 문제를 작은 문제로 나눌 수 있어야 한다.
- 작은 문제들이 반복되어 나타나고 사용되며, 이 작은 문제들의 결과값은 항상 같아야 한다.
- 모든 작은 문제들은 한 번만 계산해 DP 테이블에 저장하며, 추후 재사용할 때는 이 DP 테이블을 이용한다. (=Memoization기법)
- 크게 Top-Down과 Bottom-Up 방식으로 나뉜다.
Top-Down(하향식), Memoization
재귀적 호출은 주로 top-down접근 방식을 사용한다. 즉, 큰 문제를 작은 문제로 나누고, 부분 문제들을 해결하기 위해 재귀적으로 동작한다. 이때, 중복되는 계산은 한번만 계산하기 위해 Memoization 기법을 사용하며, 필요한 부분 문제만을 계산하기 때문에 Bottom-Up보다 적은 메모리를 사용한다.
Bottom-Up(상향식), Tabulation
작은 하위 문제들로부터 시작하여 그 모든 결과를 table 방식으로 저장하고, 계산된 값을 캐시에서 꺼내 점진적으로 큰 문제의 해를 구해나가는 방식이다. 이때 이전에 계산한 결과를 저장하기 위해 배열이나 리스트 등의 자료구조가 필요하며, 배열의 크기는 입력의 크기에 비례한다.
두 방식 모두 Memoization을 사용하여 중복 계산을 피하지만, 차이점은 재귀와 for문으로,
Top-down방식은 일반적으로 재귀함수를 이용해 코드의 가독성은 높아지지만, 많은 Stack memory를 사용할 수 있으며, Memoization의 처리 오버헤드가 존재할 수 있다. 하지만 위에서부터 계산하기 때문에 필요 없는 계산은 하지 않아도 된다.
Bottom-up 방식은 과부하로 인한 오류가 생길 일은 없지만, 필요없는 것까지도 계산해야 하며, 코드의 가독성이 낮아진다.
⚖ DP를 적용시킬 수 있는 조건
최적 부분 구조 (Optimal Substructure)
"큰 문제의 최적해"가 "작은 문제의 최적해"를 포함하는 성질. 즉, 작은 문제의 최적해를 구한 후 그것을 이용하여 큰 문제의 최적해를 구할 수 있다
중복 부분 문제 (Overlapping Subproblems)
DP는 기본적으로 문제를 나누고 그 문제의 결과 값을 재활용해서 전체 답을 구한다. 동일한 작은 문제들이 반복하여 나타나는 경우에 사용이 가능하다.
📝 DP 예시
Fibonacci Numbers
D[N] = D[N-1] + D[N-2]
1. 동적 계획법으로 풀 수 있는지 확인하기
fibo[6] = fibo[5] + fibo[4]이다.
즉, 6번째 피보나치 수열을 구하는 문제(큰 문제)는 5번째 피보나치 수열과 4번째 피보나치 수열을 구하는 문제(작은 문제)로 나눌 수 있으며, 이 부분의 문제들은 항상 최적의 답이여야 한다. 즉, 작은 부분의 문제의 최적의 답으로 큰 문제의 최적의 답을 구한다. (Optimal Substructure 조건 충족)
또한, fibo[5], fibo[6]는 이미 진행되었던 연산임에도 불구하고 같은 값으로 재귀되며 반복적으로 연산된다.(Overlapping Subproblems 조건 충족)
여기서 SubProblems란 항상 새로운 부분 문제를 생성해내기 보다는 계속해서 같은 부분 문제가 여러번 재사용되거나 재귀 알고리즘을 통해 해결되는 문제를 가르킨다.
2. 점화식 세우기
점화식을 세울때는 전체 문제와 부분 문제 간의 인과 관계를 파악하며 세워야 한다. 피보나치 수열은 공식 자체가 점화식이므로 D[i] = D[i-1] + D[i-2]가 된다.
3. Memoization 원리 이해하기
부분 문제를 풀었을 때, 이 문제를 DP 테이블에 저장해놓고, 다음에 같은 문제가 나왔을 때, 재계산하지 않고 DP 테이블의 값을 이용하는 것을 말한다.
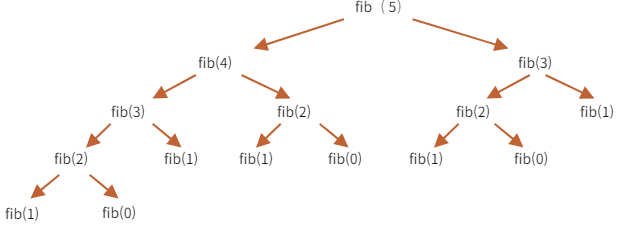
위의 그림에서, 2번째와 3번째 피보나치 수열은 왼쪽 탐색 부분에서 최초로 답이 구해지고, DP 테이블에 값이 저장된다. 이에 따라 나중에 fibo[2]와 fibo[3]값이 필요할 때 재연산을 이용해 구하지 않고, DP 테이블에서 바로 값을 추출한다. Memoization은 불필요한 연산과 탐색이 줄어들어 시간 복잡도 측면에서 많은 이점을 가질 수 있다.
4. Top-down 방식
N = int(input())
seq = [0, 1, 1] + [0] * (N - 2) #Memoization을 위한 리스트 초기화
def fibonacci(x):
if seq[x]:
return seq[x] # 이미 계산된 값이면 그대로 반환
seq[x] = fibonacci(x - 1) + fibonacci(x - 2) #재귀 호출을 통해 값 계산
return seq[x]
print(fibonacci(x))
seq배열을 활용하여 이미 계산된 값을 저장하여, 이를 활용해 재귀 호출 시 중복 계산을 피한다.
5. Bottom-up 방식
N = int(input())
seq = [0, 1, 1] + [0] * (N - 2) # Memoization을 위한 리스트 초기화
def fibonacci(x):
for i in range(3, x+1): #반복문으로 작은 문제부터 계산
seq[i] = seq[i-1] + seq[i-2] # 이전의 두 항의 합으로 현재 항 계산
return seq[x] #최종 결과 방식
print(fibonacci(x))반복문을 사용하여 작은 부분 문제부터 차례대로 계산하며, 그 결과를 테이블에 저장하여 재활용한다.
보통 입력 값이 큰 경우 Bottom - Up 방식이 효율적이며, 입력 값이 작은 경우 Top-Down 방식이 가독성이 높고 구현이 간단하기 때문에 선호된다.
