Project 3: Virtual Memory
키워드
-
Memory Management
- Supplemental Page Table
-
Anonymous Page
- Lazy Loading
-
Stack Growth
-
Memory Mapped Files
- Mmap and Munmap System Call
-
Swap In/Out
-
Anonymous Page - Swap In/Out
-
File-Mapped Page - Swap In/Out
-
Memory Management
기존 pintos 메모리 문제점
-
PML4를 가진 기존의 핀토스는 가상메모리와 물리메모리가 바로 맵핑되어 있다.
-
기존 핀토스 메모리 탑재 과정
- 각 세그먼트 (Stack, Data, BSS, Code)가 물리페이지에 탑재
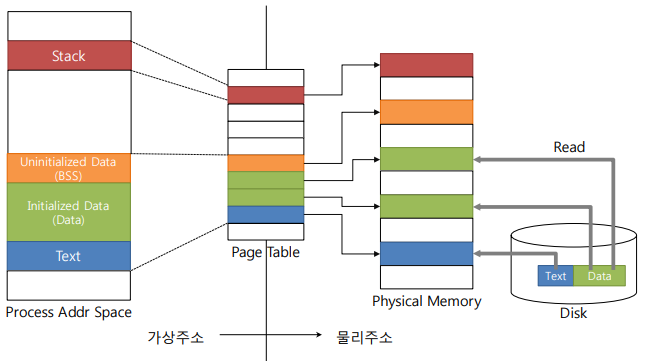
이 페이지 테이블에 맵핑된 물리주소는 다른 프로세스와 같은 곳을 가리킬 수 있고 이럴 때 page fault가 된다. 그리고 한번 맵핑되면 물리메모리에서 항상 공간을 차지하기에 효율적인 메모리 관리가 되지 않는다.
목표
Supplemental Page Table을 추가하고 페이지에 추가적인 정보를 저장하여 효율적인 메모리 관리를 할 수 있게 하는 것이 목표이다.
-
기존의 페이지 테이블을 보완하고 page fault 발생시 가상페이지를 찾고 물리페이지(frame)을 할 당할 수 있게 처리한다.
-
프로세스가 종료될 때 Supplemental Page Table 를 참조하여 해제할 리소스를 결정한다.
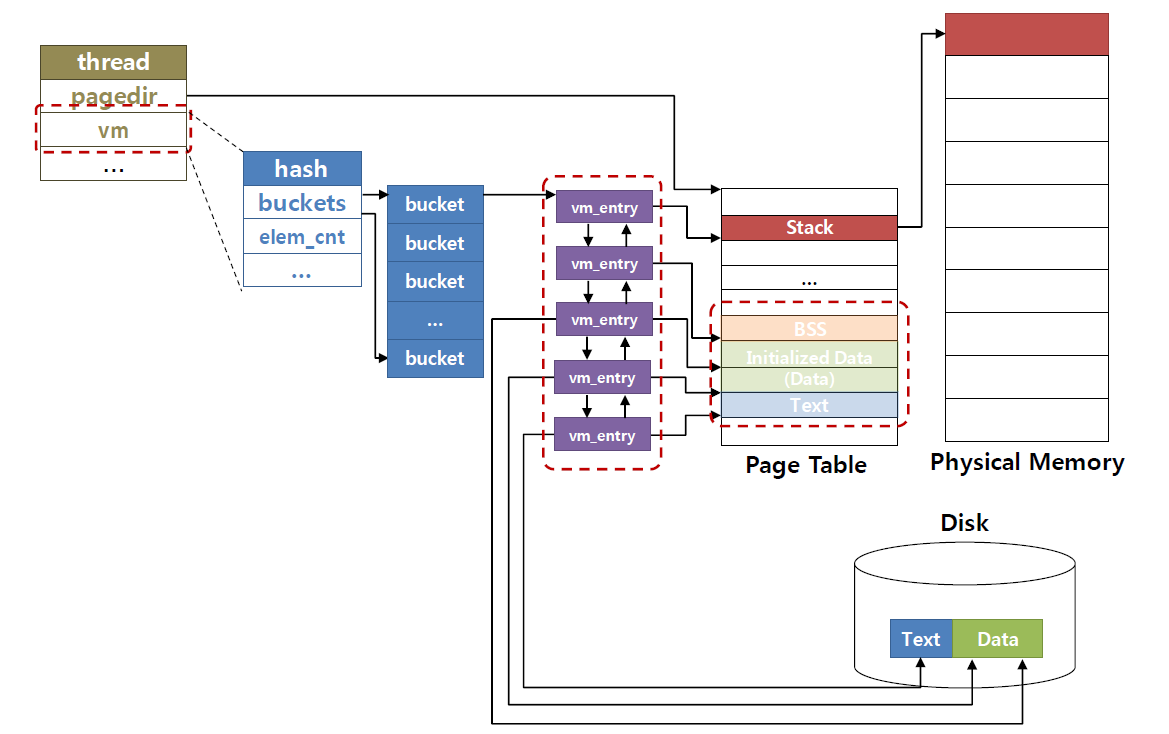
💡 supplemental page table은 process별로 생성되는 별도의 구조체로써, 동일하게 virtual address와 physical address간 mapping을 지원하지만 struct page와 struct frame 구조체들을 이용하여 기존 page table(pml4 table)이 담지 못하는 정보들을 추가적으로 저장하기 위해 사용됩니다. (ex. evicted page. mmaped page, etc...)
Supplemental Page Table (SPT 구현)
자료 구조 선택테이블을 구현하기 위해 자료구조를 먼저 선택한다.
추천하는 자료구조 4가지 중에 Hash Table 선택
Hash table관련 자료 https://mangkyu.tistory.com/102
- 이유
1. 핀토스에서 hash table을 관련 함수를 모두 지원해줌
2. hash table은 key값으로 O(1)의 시간복잡도로 자료를 빠르게 찾을 수 있다.- SPT에서 va(가상주소)에 맞는 page를 찾아야할 때 빠르게 접근할 수 있음
- key 값을 va(가상주소)로 함
- 해시충돌(collision)해결 방법
- 분리 연결법(Separate Chaining)으로 해결
- hash table에 저장되는 buckets을 이중연결리스트로 구현하여 해시 충돌 시 해당 hash index에 연결하여 줌
SPT Table
struct supplemental_page_table {
struct hash hash;
};Page Struct
struct page {
const struct page_operations *operations;
void *va; /* Address in terms of user space */
struct frame *frame; /* Back reference for frame */
/* Your implementation */
struct hash_elem hash_elem;
bool writable;
int mapped_page_cnt;
enum vm_type full_type; // vm_type with markers
/* Per-type data are binded into the union.
* Each function automatically detects the current union */
union {
struct uninit_page uninit;
struct anon_page anon;
struct file_page file;
#ifdef EFILESYS
struct page_cache page_cache;
#endif
};
};-
va키가 되는 가상주소 -
frame물리 주소랑 맵핑되는 frame 저장 -
Union 부분
- page는 3가지 타입을 가진다.
-
uninit_page: 제일 처음 만들어진 페이지의 타입
- page fault가 발생했을 때의 page의 타임이 변화하는데 변화하기 위해 필요한 정보르 가지고 있다.
-
uninit_page 코드
struct uninit_page { /* Initiate the contets of the page */ vm_initializer *init; enum vm_type type; void *aux; /* Initiate the struct page and maps the pa to the va */ bool (*page_initializer) (struct page *, enum vm_type, void *kva); };page fault 시 page_initializer에 저장된 init 함수 호출됨
-
anon_page: 비 디스크 기반 page
-
맵핑되는 파일이나 장치가 없어 디스크에 기록되지 않는다.
-
file_backed_page와 다르게 달리 맵핑된 파일이 없어 익명이라 한다.
-
-
file_backed_page: 파일에 기반한 페이지
-
파일에 기반한 페이지
-
디스크에서 읽어온다.
-
구현 코드
-
spt_find_page : va를 기준으로 hash_table에서 elem을 찾는다.
struct page * spt_find_page (struct supplemental_page_table *spt UNUSED, void *va UNUSED) { struct page *page = NULL; /* TODO: Fill this function. */ page = (struct page *)malloc(sizeof(struct page)); page->va = pg_round_down(va); //va와 동일한 해시 검색 struct hash_elem *e = hash_find(&spt->hash, &page->hash_elem); free(page); //사용을 완료한 페이지 메모리 해제하기 if (e == NULL) { // 없을 경우 return NULL; } return hash_entry(e, struct page, hash_elem); } -
supplemental_page_table_init: SPT init 함수
void supplemental_page_table_init (struct supplemental_page_table *spt UNUSED) { hash_init(&spt->hash, page_hash, page_less, NULL); } -
spt_insert_page
bool spt_insert_page (struct supplemental_page_table *spt UNUSED, struct page *page UNUSED) { int succ = false; /* TODO: Fill this function. */ struct hash_elem *e = hash_insert(&spt->hash, &page->hash_elem); if(e == NULL) { //성공했을 경우 succ = true; } return succ; }
Anonymous Page
Anonymous Page
- 파일으로부터 매핑되지 않은, 커널로부터 할당된 페이지를 뜻한다.
- 익명 페이지는 힙을 거치지 않고 할당받은 메모리 공간
- 스택, 힙과 같은 실행 파일에서 사용됨
Lazy Loading(Demanding Paging)
Lazy loading은 메모리 로딩이 필요한 시점까지 지연되는 디자인
가상 page만 할당해두고 필요한 page를 요청하면 page fault가 발생하고 해당 page를 type에 맞게 초기화하고 frame과 연결하고 user-program 으로 제어권을 넘긴다.
지연로딩 순서
- 커널이 새 page를 요청하면
vm_alloc_page_with_initializer호출 - initializer는 페이지 구조를 할당하고 페이지 type에 따라 적절한 initializer를 할당하고 SPT 페이지에 추가후 user-program 으로 반환함
- 해당 페이지에 access 호출이 오면 내용이 없는 페이지 임으로 page fault가 발생
uninit_initialize를 호출하고 이전에 설정한 initializer를 호출한다.- page를 frame가 연결하고
lazy_load_segment를 호출하여 필요한 데이터를 물리메모리에 올린다.
생명주기
initialize -> (page_fault -> lazy-load -> swap-in -> swap-out-> ...) -> destroy
- Uninitialized Page 구현
vm_alloc_page_with_initializer-
인자로 주어진 type으로 초기화되지 않은 page를 만든다.
-
SPT에 새로 만든 page를 추가하여 준다.
-
제일 처음 만들어지는 페이지는 uninit page이다.
bool vm_alloc_page_with_initializer (enum vm_type type, void *upage, bool writable, vm_initializer *init, void *aux) { ASSERT (VM_TYPE(type) != VM_UNINIT) struct supplemental_page_table *spt = &thread_current ()->spt; /* Check wheter the upage is already occupied or not. */ if (spt_find_page (spt, upage) == NULL) { /* TODO: Create the page, fetch the initialier according to the VM type, * TODO: and then create "uninit" page struct by calling uninit_new. You * TODO: should modify the field after calling the uninit_new. */ struct page * page = (struct page*)malloc(sizeof(struct page)) ; bool (*initializer)(struct page *, enum vm_type, void *) ; switch (VM_TYPE(type)) { //타입에 맞는 초기화 함수 지정 case VM_ANON : initializer = anon_initializer; break; case VM_FILE : initializer = file_backed_initializer; break; default : NOT_REACHED(); break; } uninit_new(page, upage, init, type, aux, initializer); page->writable = writable; page->full_type = type; /* TODO: Insert the page into the spt. */ return spt_insert_page(spt, page); } err: return false; }
- Anonymous Page 구현
ANON Page 타입에 대한 함수를 수정
Anonymous Page에서 중요한 점은 물리메모리와 맵핑될 때 초기화할 때 모든 데이터를 Zeroing 해주어야 한다.
anon_initializer-
기존 page안에 있는 union 안의 uninit_page에 대한 데이터를 모두 0으로 만들어준다.
-
operations을 anon_ops로 변경하고 anon_page에 대한 정보를 바꿔준다.
bool anon_initializer(struct page *page, enum vm_type type, void *kva) { /* page struct 안의 Union 영역은 현재 uninit page이다. ANON page를 초기화해주기 위해 해당 데이터를 모두 0으로 초기화해준다. Q. 이렇게 하면 Union 영역은 모두 다 0으로 초기화되나? -> 맞다. */ struct uninit_page *uninit = &page->uninit; memset(uninit, 0, sizeof(struct uninit_page)); /* Set up the handler */ /* 이제 해당 페이지는 ANON이므로 operations도 anon으로 지정한다. */ page->operations = &anon_ops; struct anon_page *anon_page = &page->anon; anon_page->swap_index = -1; return true; } -
이 부분을 구현할때 생각이 잘 안떠오르는 부분 이였다.
union에 대한 값 초기화와 anon_page에 대한 값을 생각 하기 힘들었다.
- load_segment 구현 (수정)
Project 1,2 까지의 pintos는 디스크에서 실행시킬 파일 전체를 물리메모리에 올리고 페이지 테이블에 맵핑해주었다.
이제는 load_segment 를 수정하여 page를 만들고 file에 대한 정보만을 initializer로 넘겨준다. 디스크에 있는 데이터를 물리메모리에 바로 올리지 않는다.
load_segment-
vm_entry 구조체를 추가하여 file을 load 할때 필요한 file, offset, read_bytes를 저장하고 initializer를 호출하고 aux 인자로 넘겨준다.
-
파일을 page 단위로 끊어서 uninit 페이지로 만들고 file 정보를 page에 저장하고 SPT에 추가한다.
static bool load_segment (struct file *file, off_t ofs, uint8_t *upage, uint32_t read_bytes, uint32_t zero_bytes, bool writable) { ASSERT ((read_bytes + zero_bytes) % PGSIZE == 0); ASSERT (pg_ofs (upage) == 0); ASSERT (ofs % PGSIZE == 0); while (read_bytes > 0 || zero_bytes > 0) { /* Do calculate how to fill this page. * We will read PAGE_READ_BYTES bytes from FILE * and zero the final PAGE_ZERO_BYTES bytes. */ size_t page_read_bytes = read_bytes < PGSIZE ? read_bytes : PGSIZE; size_t page_zero_bytes = PGSIZE - page_read_bytes; /* TODO: Set up aux to pass information to the lazy_load_segment. */ // void *aux = NULL; struct vm_entry *vme = (struct vm_entry *)malloc(sizeof(struct vm_entry)); vme->f = file; vme->offset = ofs; vme->read_bytes = page_read_bytes; vme->zero_bytes = page_zero_bytes; //aux 대신 vme를 넘겨준다. if (!vm_alloc_page_with_initializer(VM_ANON, upage, writable, lazy_load_segment, vme)) { return false; } /* Advance. */ read_bytes -= page_read_bytes; zero_bytes -= page_zero_bytes; upage += PGSIZE; ofs += page_read_bytes; } return true; }
Q. anon 페이지로 모든 page를 만들고 있는데 file에서 올리는 거면 왜 anon 페이지로 만들어 주지?
lazy_load_segmen() 구현
-
프로세스가 uninit_page로 처음 접근하여 page_fault가 발생하면 해당 함수가 호출된다.
-
호출된 page를 frame과 맵핑하고 해당 page에 연결된 물리메모리에 file 정보를 load 해준다.
bool lazy_load_segment (struct page *page, void *aux) { /* TODO: Load the segment from the file */ /* TODO: This called when the first page fault occurs on address VA. */ /* TODO: VA is available when calling this function. */ struct vm_entry *vme = (struct vm_entry *)aux; file_seek(vme->f, vme->offset); if(file_read(vme->f, page->frame->kva, vme->read_bytes) != (int)(vme->read_bytes)) { palloc_free_page(page->frame->kva); return false; } memset(page->frame->kva + vme->read_bytes, 0, vme->zero_bytes); return true; }
setip_stack() 재구현
기존의 setup_stack()를 SPT가 추가된 상황에 맞게 수정한다.
setup_stack은 page를 할당하고 바로 물리 메모리와 맵핑하여 준다. -> page_fault가 발생전에 물리메모리에 바로 할당
-
stack_bottom을 page의 va(가상주소 시작위치)로 할당하기 위해 인자로 넘겨준다.
-
stack_bottom을 추가 할당을 위하여 thread_current에 stack_bottom 저장 변수를 만들고 넣어준다.
bool setup_stack (struct intr_frame *if_) { bool success = false; void *stack_bottom = (void *) (((uint8_t *) USER_STACK) - PGSIZE); /* TODO: Map the stack on stack_bottom and claim the page immediately. * TODO: If success, set the rsp accordingly. * TODO: You should mark the page is stack. */ /* TODO: Your code goes here */ /* Map the stack on stack_bottom and claim the page immediately. You should mark the page is stack. */ if (vm_alloc_page(VM_ANON | VM_MARKER_0, stack_bottom, 1)){ // 스택 페이지 할당에 성공한 후, 해당 가상주소로 할당한 페이지를 찾아서 claim success = vm_claim_page (stack_bottom) ; if (success){ /* TODO: If success, set the rsp accordingly. */ if_->rsp = USER_STACK; thread_current()->stack_bottom = stack_bottom; } } return success; }Q. 왜 스택은 lazy loading을 하지 않고 바로 물리메모리와 맵핑해 주는 것인가?
-
setup_stack 이후 파일 실행에 필요한 argument를 바로 stack에 넣어 주어야한다.
-
stack은 바로 사용하기 때문에 uninit page로 두지 않고 생성 후 바로 frame과 맵핑시켜준다.
/* Set up stack. */ if (!setup_stack (if_)) goto done; /* Start address. */ if_->rip = ehdr.e_entry; /* TODO: Your code goes here. * TODO: Implement argument passing (see project2/argument_passing.html). */ argument_stack(argv, cnt, &if_->rsp);
-
check_address() 수정
- 기존의 check_address는 syscall의 인자로 받은 주소값이 유저의 영역인지 pml4에 있는지를 확인하였고 없다면 exit(-1)로 프로세스를 종료하였다.
- SPT가 추가되면서 유효한 주소이지만 pml4에는 없을 수 있기에 함수를 수정하여 pml4에 없는 경우 프로세스를 바로 종요하지 않게 해야한다.
수정 전
void check_address(void *addr)
{
struct thread *cur = thread_current();
/* 주소 addr이 유저 가상 주소가 아니거나 pml4에 없으면 */
if (addr == NULL || !is_user_vaddr(addr) || pml4_get_page(cur->pml4, addr) == NULL)
{
exit(-1);
}
/* addr이 유저 가상 주소이고 동시에 pml4에 있으면 페이지를 리턴해야 한다. */
}수정 후
void check_address(void *addr)
{
/* 주소 addr이 유저 가상 주소가 아니거나 pml4에 없으면 프로세스 종료 */
if (addr == NULL || !is_user_vaddr(addr))
{
exit(-1);
}
/* 유저 가상 주소면 SPT에서 페이지 찾아서 리턴 */
return spt_find_page(&thread_current()->spt, addr);
}- 유저 가상 주소이면 SPT 에서 찾고 page를 반환하여 주게 수정한다.
check_buffer
Supplemental Page Table - Revisit(fork, exec)
SPT 테이블에 대한 copy와 clean up을 위한 수정이 필요함
child를 만들때 copy, process를 종료할 때 destroy가 필요
supplemental_page_table_copy
- 부모의 STPd의 page는 같게 frame은 다르게 복사한다.
- 부모의 물리메모리에 있는 데이터를 자식에게 복사하여 준다.
구현 요구사항
- src에서 dst로 SPT를 복사한다.
- child가 parent의 실행 컨텍스트를 상속해야 할때 사용된다.
- 각 page를 반복하고 dst의 SPT에 있는 항목의 복사본을 만든다.
- uninit page를 할당하고 claim을 바로한다.
-
구현 코드
bool supplemental_page_table_copy (struct supplemental_page_table *dst, struct supplemental_page_table *src) { struct hash_iterator i; //해시 테이블 내의 위치 hash_first(&i, &src->hash); //i를 해시의 첫번째 요소를 가리키도록 초기화 while (hash_next(&i)) { // 해시의 다음 요소가 있을 때까지 반복 struct page *src_page = hash_entry(hash_cur(&i), struct page, hash_elem); enum vm_type type = src_page->operations->type; void *va = src_page->va; bool writable = src_page->writable; if(type == VM_UNINIT) { //초기화되지 않은 페이지인 경우 vm_alloc_page_with_initializer(page_get_type(src_page), va, writable, src_page->uninit.init, src_page->uninit.aux); } else if(type == VM_FILE) { //파일 타입일 경우 struct vm_entry *vme = (struct vm_entry *)malloc(sizeof(struct vm_entry)); vme->f = src_page->file.file; vme->offset = src_page->file.offset; vme->read_bytes = src_page->file.read_bytes; vme->zero_bytes = src_page->file.zero_bytes; if(!vm_alloc_page_with_initializer(type, va,writable, NULL, vme)) { return false; } struct page *page = spt_find_page(dst, va); file_backed_initializer(page, type, NULL); page->frame = src_page->frame; pml4_set_page(thread_current()->pml4, page->va, src_page->frame->kva, src_page->writable); } else { //익명 페이지일 경우 if(!vm_alloc_page(type, va, writable)) { return false; } if(!vm_claim_page(va)) { return false; } struct page *dst_page = spt_find_page(dst, va); memcpy(dst_page->frame->kva, src_page->frame->kva, PGSIZE); } } return true; }
supplemental_page_kill
- 프로세스가 종료 될 때 함수를 호출하고
SPT에 모든 리소를 해제한다. - 모든 페이지에 대해서
destroy(page)로 리소스 해제
uninit_destroy
- 페이지의 type에 따라 페이지 구조가 보유한 리소스 해제
- 현재까지는 anon_page만 처리하고 나중에 file_backed_page를 정리할 수 있다.
anon_destroy
- 익명 페이지가 보유한 리소스 해제
- page struct를 명시적으로 해제할 필요가 없고 호출자가 수행한다.
Stack Growth
목표
이제까지의 pintos의 stack 단일 페이지 stack으로 되어있었다.
이러한 스택을 적절한 page fault에서 stack을 추가로 할당하는 작업을 구현하는 것이 목표이다.
Q. 적절한 stack page fault 범위 잡는 범위를 rsp에서 4KB를 설정하였는데 왜 4KB인지 잘 모르겠음
- 4KB가 아닌가하는 생각도 드는데 그렇다면 잘못 코드를 작성하고 모든 케이스를 통과 하는 것인가 하는 생각이듬
- rsp에서 - 8 byte
vm_try_handle_fault 수정
-
addr의 범위가 MAX_STACK 보단 크고 USER_STACK 보단 작을때와 USER_STACK 과 addr이 f->rsp-8 보다 크거나 같다.
-
위의 범위가 stack growth에 대한 페이지 폴트 일때의 범위이다.
bool vm_try_handle_fault (struct intr_frame *f UNUSED, void *addr UNUSED, bool user UNUSED, bool write UNUSED, bool not_present UNUSED) { struct supplemental_page_table *spt UNUSED = &thread_current ()->spt; void *page_addr = pg_round_down(addr); // 페이지 사이즈로 내려서 spt_find 해야 하기 때문 uint64_t MAX_STACK = USER_STACK - (1<<20); uint64_t addr_v = (uint64_t)addr; uint64_t rsp = user ? f->rsp : thread_current()->rsp; if (addr == NULL || is_kernel_vaddr(addr)) return false; if (!not_present && write) return false; /* TODO: Validate the fault */ /* TODO: Your code goes here */ struct page *page = spt_find_page(spt, page_addr); if (page == NULL) { if (addr_v > MAX_STACK && addr_v < USER_STACK && addr_v >= rsp - 8) { vm_stack_growth(page_addr); page = spt_find_page(spt, page_addr); } else { return false ; } } return vm_do_claim_page (page); }
vm_stack_growth
-
stack_bottom을 4KB(PGSIZE)만큼 이동한다.
-
VM_ANON으로 page를 할당하고 vm_claim_page를 호출하여 frame과 맵핑시킨다.
-
thread_current의 stack_bottom을 갱신한다.
static void vm_stack_growth (void *addr UNUSED) { struct supplemental_page_table *spt = &thread_current ()->spt; while (!spt_find_page (spt, addr)) { vm_alloc_page (VM_ANON | VM_MARKER_0, addr, true); vm_claim_page (addr); addr += PGSIZE; } }
Memory Mapped files
목표
이번에는 Anonymous Memory가 아닌 File-Backed Memory, 다시 말해 Memory Mapped Page에 대해 구현해보도록 한다.
File-Backed page
File-Backed page는 파일에 기반한 맵핑을 한다. 안에 내용은 디스크에서 존재하고 있는 파일을 복사한것이다. page fault가 발생하면 바로 물리 프레임을 할당하고 파일의 데이터를 물리 메모리에 복사한다. 이때 I/O를 통해 데이터를 복사하는 것이 아닌 DMA 방식으로 디스크에서 파일을 복사한다.
이 때 유저 가상 페이지를 미리 가상주소 공간에 할당 해주는 것이 mmap이고 페이지와 물리 메모리가 연결된 경우 그 연결을 끊어 주는 것을 mnumap이라 한다.
-
mmap() 시스템 콜에 의해 맵핑된 가상 메모리는 스택과 힙 사이의 미할당 공간(스택고 힙도 아닌)에 할당된다.
-
memory mapping page 구현 시에도 lazy loading 방식으로 할당 되어야 한다.
-
vm_alloc_page로 페이지를 할당하고 해당 페이지에 page fault가 발생하였을 때 frame을 맵핑하고 해당 page에 해당하는 file 데이터를 메인 메모리에 올려준다.
mmap 구현
void *mmap(void *addr, size_t lengthm int writable, int fd, off_t offset);
- addr에서 시작하는 연속적인 가상 페이지를 맵핑한다.
- mmap은 페이지 단위로 메모리를 할당받은 시스템 콜
- offset으로 부터 length만큼 fd에 해당하는 파일을 addr에 연결된 물리 메모리에 올린다.
만약 파일의 size가 PGSIZE보다 크면 마지막 페이지에는 남은 공간 만큼의 빈공간이 생긴다. 이 비어 있는 메모리를 0으로 초기화해주고 다시 디스크에 업데이트할 때는 버린다.
- Q. mmap과 malloc의 차이 둘 다 메모리를 할당받는다는 점에서는 같다. mmap이 file-backed 메모리의 경우에만 해당하는 함수라고 오해한다는데, 그렇지 않은 경우도 많다. 그냥 mmap은 페이지 단위로 할당받으므로 malloc에 비해 큰 용량의 메모리를 할당할 수 있다는 것이 차이인것 같다.
Syscall Mmap
-
이 함수에서는 다양한 예외 처리를 해준다. 유저가 입력한 값이 정상적인지 확인한다.
void *mmap (void *addr, size_t length, int writable, int fd, off_t offset) { if(!addr || addr != pg_round_down(addr)) { //addr이 존재하지 않거나 정렬되어 있지 않은 경우 return NULL; } if (offset != pg_round_down(offset)) { //offset이 정렬되어 있지 않은 경우 return NULL; } if (!is_user_vaddr(addr) || !is_user_vaddr(addr + length)) { //사용자 영역에 존재하지 않을 경우 return NULL; } if (spt_find_page(&thread_current()->spt, addr)) { //addr에 할당된 페이지가 존재할 경우 return NULL; } struct file *f = process_get_file(fd); //fd에 파일이 없을 경우 if (f == NULL) { return NULL; } if (file_length(f) == 0 || (int)length <= 0) { //길이가 0이하일 경우 return NULL; } lock_acquire(&filesys_lock); void *success = do_mmap(addr, length, writable, f, offset); lock_release(&filesys_lock); return success; }
do_mmap
-
do_mmap은 load_segment와 매우 유사한 면이 있음.
-
page를 할당할 때 VM_FILE로 하여 할당
-
이렇게 만들어진 page는 page fault가 발생하면 페이지를 초기화 하고 frame과 연결하고 file_page에 저장된 파일의 정보로 물리메모리에 file 데이터를 복사한다.
void * do_mmap (void *addr, size_t length, int writable, struct file *file, off_t offset) { struct file *f = file_reopen(file); void *start_addr = addr; int total_page_count; if(length <= PGSIZE) { //현재 매핑하려는 길이가 페이지 사이즈보다 작을 경우 total_page_count = 1; //한 개의 페이지에 모두 들어간다. } else { //하나 이상의 페이지가 필요할 경우 if(length % PGSIZE != 0) { //나누어떨어지지 않을 경우 페이지 1개 더 필요하다. total_page_count = length / PGSIZE + 1; } else { total_page_count = length / PGSIZE; } } size_t read_bytes = file_length(f) < length ? file_length(f) : length; size_t zero_bytes = PGSIZE - read_bytes % PGSIZE; ASSERT((read_bytes + zero_bytes) % PGSIZE == 0); ASSERT(pg_ofs(addr) == 0); ASSERT(offset % PGSIZE == 0); while(read_bytes > 0 || zero_bytes > 0) { size_t page_read_bytes = read_bytes < PGSIZE ? read_bytes : PGSIZE; size_t page_zero_bytes = PGSIZE - page_read_bytes; struct file_page *file_page = (struct file_page *)malloc(sizeof(struct file_page)); file_page->file = f; file_page->offset = offset; file_page->read_bytes = page_read_bytes; file_page->zero_bytes = page_zero_bytes; if(!vm_alloc_page_with_initializer(VM_FILE, addr, writable, lazy_load_seg, file_page)) { file_close(f); return NULL; } struct page *p = spt_find_page(&thread_current()->spt, start_addr); p->mapped_page_cnt = total_page_count; read_bytes -= page_read_bytes; zero_bytes -= page_zero_bytes; addr += PGSIZE; offset += page_read_bytes; } return start_addr; }
lazy_load_Seg
-
file_backed_page에서 page fault 발생 시 맵핑된 물리 메모리에 파일 데이터를 복사하는 함수
-
file_page의 offset을 aux로 받아온 offset으로 옮기고 물리 메모리에 파일에서 read_bytes만큼 데이터를 복사한다.
-
PGSIZE가 되지 않는 read_bytes인 경우 남은 부분은 0으로 채워준다. memset()
bool lazy_load_seg(struct page *page, void *aux) { struct file_page *file_page = (struct file_page *)aux; page->file = (struct file_page) { .file = file_page->file, .offset = file_page->offset, .read_bytes = file_page->read_bytes, .zero_bytes = file_page->zero_bytes}; file_seek(file_page->file, file_page->offset); if (file_read(file_page->file, page->frame->kva, file_page->read_bytes) != (int)(file_page->read_bytes)) { palloc_free_page(page->frame->kva); return false; } // 3) 다 읽은 지점부터 zero_bytes만큼 0으로 채운다. memset(page->frame->kva + file_page->read_bytes, 0, file_page->zero_bytes); return true; }
munmap(addr)
-
Dirty Bit
-
해당 페이지가 수정되었는지를 저장하는 비트이다. 페이지가 변경될 때마다 이 비트는 1이된다.
-
디스크에 변경 내용을 기록하고 나면 해당 페이지의 더티 비트는 다시 0으로 초기화 된다.
-
💡 ADDR으로부터 연속된 유저 가상 페이지들의 변경 사항을 디스크의 파일에 업데이트하고 맵핑 정보를 지운다. 페이지를 지우는 것이 아닌 Present Bit을 0으로 만들어준다.
-
해당 page의 dirty bit가 1이면 수정사항이 있는 것임으로 file에 물리메모리에 있는 데이터를 write하여 준다. 그리고 해당 페이지의 dirty bit을 0으로 만들어준다.
void do_munmap (void *addr) { struct supplemental_page_table *spt = &thread_current()->spt; struct page *p = spt_find_page(spt, addr); if (p->frame == NULL) { vm_claim_page(addr); } struct file *file = p->file.file; int count = p->mapped_page_cnt; for (int i = 0; i < count; i++) { if(p) { destroy(p); } addr += PGSIZE; p = spt_find_page(spt, addr); } file_close(file); }
Swap In/Out
Anonymous Page
ANON의 경우에는 디스크 안에 해당 페이지에 대한 BACKING STORE가 없다. 이 말은, 디스크로 SWAP OUT 되었을 때 이 페이지를 저장할 공간이 디스크 내에 없다는 뜻이다. 따라서 디스크 내에 별도의 공간 SWAP DISK를 만들어 두고, 이 공간에 SWAP OUT된 ANON 페이지를 저장하도록 한다.
vm_anon_init 과 anon-initializer 를 먼저 수정한다.
struct anon_page 리마인드
만약 ANON 페이지가 디스크로 SWAP OUT 되었을 때, 디스크에 저장된 디스크 섹터 구역을 저장해주는 slot 변수가 존재한다.
맨 처음 ANON 페이지를 초기화하면(UNINIT으로부터) 물리 메모리 위에 있으므로 slot 의 값은 -1로 지정해 둔다.
struct anon_page {
uint32_t slot;
};Swap Table 선언
디스크에서 사용 가능한 swap slot과 사용 불가능한 swap slot을 관리하는 자료구조인 Swap Table을 선언해준다.
스왑 테이블은 가상 메모리에 있는 객체이다.
vm/anon.c
struct list swap_table; //swap slot 사용 여부를 판단하기 위해 사용
disk_sector_t swap_size = disk_size(swap_disk) / 8;여기 스왑 테이블의 경우 각각의 비트는 스왑 슬롯 각각과 매칭된다. 스왑 테이블에서 해당 스왑 슬롯에 해당하는 비트가 1이라는 말은 그에 대응되는 페이지가 swap out되어 디스크의 스왑 공간에 임시적으로 저장되었다는 뜻이다.
디스크 섹터는 하드 드라이브의 최소 기억 단위라고 한다. 마치 가상 메모리 공간을 여러 페이지로 나누어 놓은 것처럼, 디스크 위의 물리적인 저장 공간이라는 것이 중요하다. HDD의 경우에는 512 byte의 고정된 크기를 갖는다. 만약 디스크에 파일이 저장된다고 하면, 파일은 여러 디스크 섹터들을 거쳐서 저장된다. 파일의 크기가 2kb라고 하면 4개의 디스크 섹터에 파일이 나뉘어 저장되는 것이다.
가상 페이지의 크기는 4kb이므로, 하나의 페이지를 저장하기 위해 필요한 디스크 섹터의 개수는 8개가 되겠다.
vm_anon_init() 수정
ANON 페이지를 위한 디스크 내 스왑 영역을 생성해주는 함수이다. 디스크 내에 스왑 영역을 만들어주고 이를 관리하는 스왑 테이블도 만들어준다.
swap_size는 스왑 디스크 안에서 만들 수 있는 스왑 슬롯의 개수를 의미한다.
💡 스왑 디스크 공간 내의 총 스왑 슬롯 개수 = 스왑 공간의 크기 / 1페이지당 필요한 섹터의 개수
이다.
만약 스왑 공간이 4096byte라고 한다면 4096 / 8 = 512개의 페이지에 대한 정보를 저장할 수 있는 512개의 스왑 슬롯을 만들 수 있다.
void
vm_anon_init (void) {
/* TODO: Set up the swap_disk. */
swap_disk = disk_get(1, 1);
list_init(&swap_table);
lock_init(&swap_table_lock);
disk_sector_t swap_size = disk_size(swap_disk) / 8;
for (disk_sector_t i = 0; i < swap_size; i++) {
struct slot *slot = (struct slot *)malloc(sizeof(struct slot));
slot->page = NULL;
slot->slot= i;
lock_acquire(&swap_table_lock);
list_push_back(&swap_table, &slot->swap_elem);
lock_release(&swap_table_lock);
}
}anon_initializer() 수정
slot의 값을 -1로 설정해준다. 페이지 폴트가 떠서 해당 페이지를 물리 메모리로 올리게 되므로, 해당 페이지는 디스크가 아닌 물리 메모리에 있기 때문!
bool
anon_initializer (struct page *page, enum vm_type type, void *kva) {
/* Set up the handler */
page->operations = &anon_ops;
struct anon_page *anon_page = &page->anon;
anon_page->slot = -1;
return true;
}anon_swap_out(page) 구현
💡 ANON 페이지를 스왑 아웃한다. 디스크에 백업 파일이 없으므로, 디스크 상에 스왑 공간을 만들어 그곳에 페이지를 저장한다.
현재 디스크 섹터와 그에 해당하는 페이지 및 스왑 슬롯은 다음과 같다.
disk sector : 1 2 3 4 5 6 7 8 910111213141516 1718192021222324
each page : | 1 2 3 4 5 6 7 8 | 1 2 3 4 5 6 7 8 | 1 2 3 4 5 6 7 8 |
page_no & swap slot : 1 2 3가상 메모리의 스왑 테이블에서 비트가 false인 스왑 슬롯을 찾는다. 비트가 false라는 말은 해당 스왑 슬롯에 swap out된 페이지를 할당할 수 있다는 의미이다.
그 후 해당 스왑 슬롯에 해당하는 디스크의 영역에 가상 주소 공간의 데이터를 페이지의 시작 주소부터 디스크 섹터 크기로 잘라서 저장한다.
그 후 해당 스왑 슬롯에 대응되는 스왑 테이블의 비트를 TRUE로 바꿔주고, ANON 페이지의 slot 멤버에 스왑 슬롯 번호를 저장해서 이 페이지가 디스크의 스왑 영역 중 어디에 swap 되었는지를 확인할 수 있도록 한다.
SWAP OUT된 페이지의 Present Bit의 값은 0으로, 프로세스가 해당 페이지의 데이터에 접근하려 하면 페이지 폴트가 뜨게 된다.
static bool
anon_swap_out (struct page *page) {
if(page == NULL) {
return false;
}
struct anon_page *anon_page = &page->anon;
struct slot *slot;
lock_acquire(&swap_table_lock);
for (struct list_elem *e = list_begin(&swap_table); e != list_end(&swap_table); e = list_next(e)) {
slot = list_entry(e, struct slot, swap_elem);
if(slot->page == NULL) {
for (int i = 0; i < 8; i++) {
disk_write(swap_disk, slot->slot * 8 + i, page->va + DISK_SECTOR_SIZE * i);
}
slot->page = page;
anon_page->slot = slot->slot;
page->frame->page = NULL;
page->frame = NULL;
pml4_clear_page(thread_current()->pml4, page->va);
lock_release(&swap_table_lock);
return true;
}
}
lock_release(&swap_table_lock);
PANIC("insufficient swap space");
}- Swap Table 리스트를 순회하며 swap_elem을 찾고 그 값을 slot 이라는 변수에 저장후 만약 slot->page == NULL일 경우 swap_disk에 쓰기 작업을 진행한다.
- disk_write(swap_disk, sec_no(slot->slot 8 + i), buffer(page->va + DISK_SECTOR_SIZE i)) BUFFER에서부터 데이터를 디스크 D의 섹터 SEC_NO에 써 준다.
anon_swap_in() 구현
SWAP OUT된 페이지에 저장된 slot 값으로 스왑 슬롯을 찾아 해당 슬롯에 저장된 데이터를 다시 페이지로 원복시킨다.
static bool
anon_swap_in (struct page *page, void *kva) {
struct anon_page *anon_page = &page->anon;
disk_sector_t page_slot = anon_page->slot;
struct slot *slot;
lock_acquire(&swap_table_lock);
for (struct list_elem *e = list_begin(&swap_table); e != list_end(&swap_table); e = list_next(e)) {
slot = list_entry(e, struct slot, swap_elem);
if(slot->slot == page_slot) {
for (int i = 0; i < 8; i++) {
disk_read(swap_disk, page_slot * 8 + i, kva + DISK_SECTOR_SIZE * i);
}
slot->page = NULL;
anon_page->slot = -1;
lock_release(&swap_table_lock);
return true;
}
}
lock_release(&swap_table_lock);
return false;
}File-Backed Page
Fil-Backed Page의 경우 디스크에 backed file이 있으므로, swap out될 때 해당 파일에 저장되면 된다.
Swap out되면 해당 페이지의 PTE의 Present Bit은 0이 되고, 해당 페이지에 프로세스가 접근하면 페이지 폴트가 일어나고 디스크의 파일 데이터를 다시 물리 메모리에 올리면서 swap in된다.
file_backed_swap_out() 수정
do_munmap()과 거의 유사하다는 것을 알 수 있다. 단지 do_munmap()은 연속된 가상 메모리 공간에 매핑된 페이지들을 모두 swap out해주는 것이고, file_backed_swap_out()은 한 페이지에 대해 매핑을 해제해준다는 것이 다르다.
static bool
file_backed_swap_out (struct page *page) {
struct file_page *file_page UNUSED = &page->file;
struct thread *t = thread_current();
if(page == NULL)
return false;
if(pml4_is_dirty(t->pml4, page->va)) { //dirty bit = 1일 경우 swap out 가능
lock_acquire(&filesys_lock);
file_write_at(file_page->file, page->va, file_page->read_bytes, file_page->offset); //변경사항을 파일에 저장하기
lock_release(&filesys_lock);
pml4_set_dirty(thread_current()->pml4, page->va, 0); //dirty bit = 0
}
page->frame->page = NULL;
page->frame = NULL;
pml4_clear_page(t->pml4, page->va);
return true;
}file_backed_swap_in() 수정
lazy_load_segment()와 비슷하다는 것을 알 수 있다.
Present Bit이 0으로 세팅되어 있는 File-Backed Page에 프로세스가 접근하게 되면 Supplementary Page Table의 struct page 내에 있는 struct file_page에 접근한다. file_page 구조체의 container 구조체에서 이 가상 페이지와 관련된 디스크의 파일 데이터의 정보를 불러올 수 있다.
이 정보를 토대로 먼저 물리 공간에 프레임을 하나 할당받아 해당 페이지와 매핑해준 다음, 디스크의 파일에서 물리 프레임으로 (vm_do_claim_page() 내 swap_in(page, frame->kva)) 데이터를 다시 복사해온다.
static bool
file_backed_swap_in (struct page *page, void *kva) {
struct file_page *file_page UNUSED = &page->file;
size_t page_read_bytes = file_page->read_bytes;
size_t page_zero_bytes = file_page->zero_bytes;
if (page == NULL)
return false;
// 파일의 내용을 페이지에 입력한다
lock_acquire(&filesys_lock);
if(file_read_at(file_page->file, kva, page_read_bytes, file_page->offset) != (int)page_read_bytes){
// 제대로 입력이 안되면 false 반환
lock_release(&filesys_lock);
return false;
}
lock_release(&filesys_lock);
// 나머지 부분을 0으로 입력
memset(kva + page_read_bytes, 0, page_zero_bytes);
return true;
}Page Replacement Policy
프로세스가 가상 페이지를 통해 물리 메모리에 접근하려 시도할 때, 물리 프레임이 모두 꽉 차 있으면 물리 메모리에서 적당한 하나의 프레임을 골라 디스크로 Swap Out 한다. 이 때 swap out할 적당한 프레임을 고르는 정책을 Page Replacement Policy라고 부른다.
frame_table list 구현 및 수정
앞에서 선언해주었던 struct frame과 frame_table 리스트를 다시 한번 가져와보자. 이 둘의 존재 이유는 물리 프레임들을 관리해주면서 swap out시킬 적당한 프레임을 고르기 편하게 해 주는 데에 있다.
vm/vm.h
struct frame {
void *kva;
struct page *page;
struct list_elem frame_elem;
};vm.c
frame들을 관리하는 frame table 리스트와 해당 리스트에 lock을 걸어주기 위한 frame_table_lock 이라는 변수를 선언해준다.
struct list frame_table; //lru 페이지 교체 기법으로 희생자 선택
struct lock frame_table_lock;vm.c/vm_init()
맨 처음 가상 메모리에 대한 서브 시스템들을 초기화해주는 vm_init() 함수에서 프레임 테이블과 frame_table_lock 변수도 초기화해준다.
void
vm_init (void) {
vm_anon_init ();
vm_file_init ();
#ifdef EFILESYS /* For project 4 */
pagecache_init ();
#endif
register_inspect_intr ();
/* DO NOT MODIFY UPPER LINES. */
/* TODO: Your code goes here. */
list_init(&frame_table);
lock_init(&frame_table_lock);
}- vm_init()은 언제 실행되는가? init.c → main() → vm_init()의 순서로 실행된다. 핀토스의 메인 프로그램이 실행될 때 같이 실행된다.
vm_get_frame() 수정
이제 페이지를 claim할 때 페이지에 해당하는 물리 프레임을 가져오는 vm_get_frame()을 수정한다.
페이지를 물리 메모리 공간에 palloc하여 할당받는 과정에서 아무 것도 받아오지 못했다면, 물리 프레임에 자리가 없어 가져오지 못한 것으로 판단한다. 그렇담 vm_evict_frame()을 호출하여 프레임 하나의 데이터를 swap out해버리고 해당 프레임과 새 페이지를 매핑해줄 것이다.
이 때 프레임을 할당받은 다음에 물리 프레임을 관리하는 struct frame을 페이지 테이블에 insert시켜 관리한다.
static struct frame *
vm_get_frame (void) {
struct frame *frame = NULL;
/* TODO: Fill this function. */
//사용자 풀에서 페이지를 할당받기 - 할당받은 물리 메모리 주소 반환
void *addr = palloc_get_page(PAL_USER);
if(addr == NULL) {
frame = vm_evict_frame();
frame->page = NULL;
return frame;
}
frame = (struct frame *)malloc(sizeof(struct frame));
frame->kva = addr;
frame->page = NULL;
lock_acquire(&frame_table_lock);
list_push_back(&frame_table, &frame->frame_elem);
lock_release(&frame_table_lock);
ASSERT(frame != NULL);
ASSERT (frame->page == NULL);
return frame;
}vm_evict_frame() 구현
이 함수는 vm_get_victim() 함수를 호출하여 프레임 테이블에서 적당한 프레임을 찾아낸 다음, 해당 프레임을 swap out 해주는 함수이다.
static struct frame *
vm_evict_frame (void) {
struct frame *victim UNUSED = vm_get_victim ();
/* TODO: swap out the victim and return the evicted frame. */
if(victim->page) {
swap_out(victim->page);
}
return victim;
}vm_get_victim() 구현
이 함수는 페이지 교체 정책을 실제로 구현하는 함수이다.
vm.c/vm_get_victim()
static struct frame *
vm_get_victim (void) {
struct frame *victim = NULL;
/* TODO: The policy for eviction is up to you. */
struct thread *curr = thread_current();
lock_acquire(&frame_table_lock);
for (struct list_elem *f = list_begin(&frame_table); f != list_end(&frame_table); f = list_next(f)) {
victim = list_entry(f, struct frame, frame_elem);
if(victim->page == NULL) { //현재 프레임에 페이지가 없으므로 희생자로 선택
lock_release(&frame_table_lock);
return victim;
}
//PTE에 접근했는지 여부 판단 : 즉 최근에 접급한 적이 있으면
if (pml4_is_accessed(curr->pml4, victim->page->va)) {
//접근 비트를 0으로 설정
pml4_set_accessed(curr->pml4, victim->page->va, 0);
}
else { //최근에 접근한 적이 없으면 희생자로 선택
lock_release(&frame_table_lock);
return victim;
}
}
lock_release(&frame_table_lock);
return victim;
}